 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
A Human Rights-Based Approach to Responsible AI
Oct 06, 2022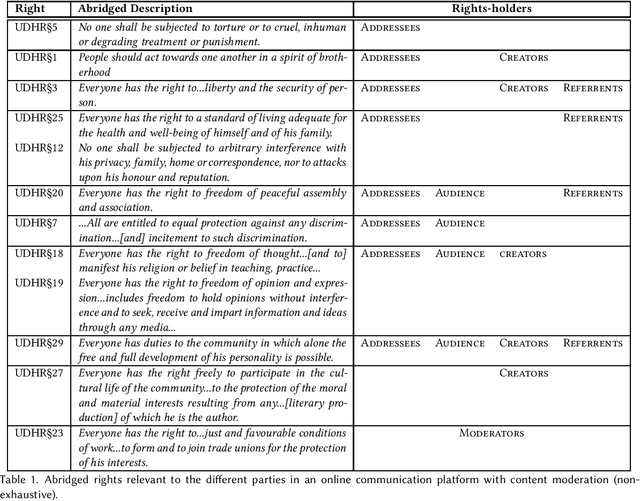
Research on fairness, accountability, transparency and ethics of AI-based interventions in society has gained much-needed momentum in recent years. However it lacks an explicit alignment with a set of normative values and principles that guide this research and interventions. Rather, an implicit consensus is often assumed to hold for the values we impart into our models - something that is at odds with the pluralistic world we live in. In this paper, we put forth the doctrine of universal human rights as a set of globally salient and cross-culturally recognized set of values that can serve as a grounding framework for explicit value alignment in responsible AI - and discuss its efficacy as a framework for civil society partnership and participation. We argue that a human rights framework orients the research in this space away from the machines and the risks of their biases, and towards humans and the risks to their rights, essentially helping to center the conversation around who is harmed, what harms they face, and how those harms may be mitigated.
Evaluate & Evaluation on the Hub: Better Best Practices for Data and Model Measurements
Oct 06, 2022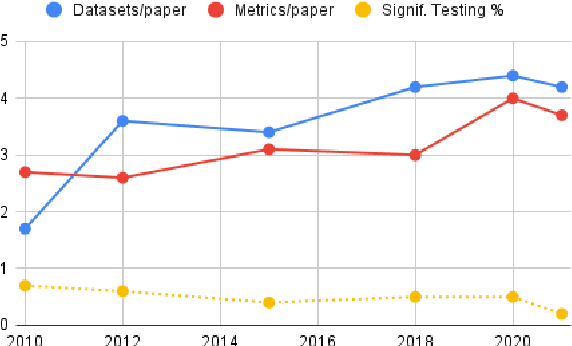
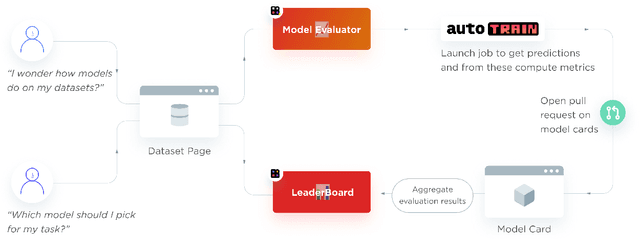
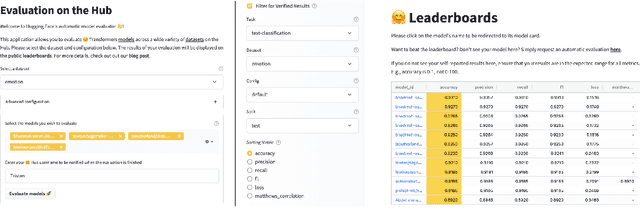
Evaluation is a key part of machine learning (ML), yet there is a lack of support and tooling to enable its informed and systematic practice. We introduce Evaluate and Evaluation on the Hub --a set of tools to facilitate the evaluation of models and datasets in ML. Evaluate is a library to support best practices for measurements, metrics, and comparisons of data and models. Its goal is to support reproducibility of evaluation, centralize and document the evaluation process, and broaden evaluation to cover more facets of model performance. It includes over 50 efficient canonical implementations for a variety of domains and scenarios, interactive documentation, and the ability to easily share implementations and outcomes. The library is available at https://github.com/huggingface/evaluate. In addition, we introduce Evaluation on the Hub, a platform that enables the large-scale evaluation of over 75,000 models and 11,000 datasets on the Hugging Face Hub, for free, at the click of a button. Evaluation on the Hub is available at https://huggingface.co/autoevaluate.
Measuring Model Biases in the Absence of Ground Truth
Mar 05, 2021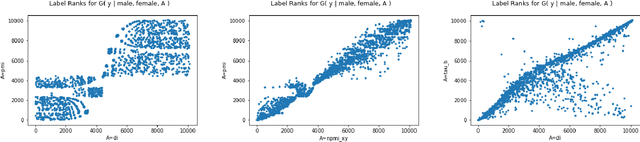
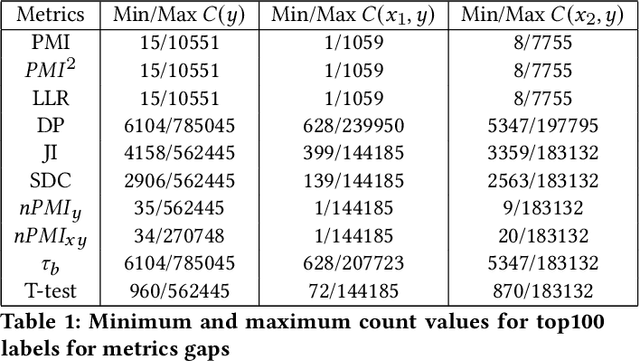
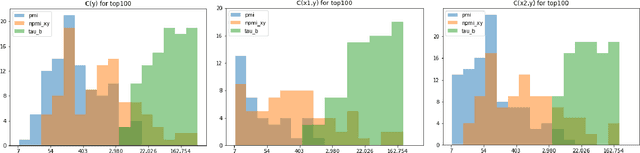
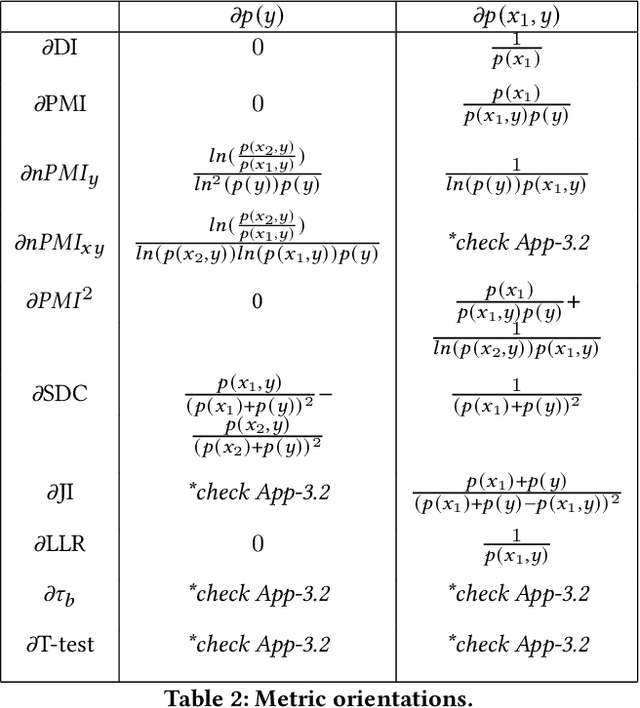
Recent advances in computer vision have led to the development of image classification models that can predict tens of thousands of object classes. Training these models can require millions of examples, leading to a demand of potentially billions of annotations. In practice, however, images are typically sparsely annotated, which can lead to problematic biases in the distribution of ground truth labels that are collected. This potential for annotation bias may then limit the utility of ground truth-dependent fairness metrics (e.g., Equalized Odds). To address this problem, in this work we introduce a new framing to the measurement of fairness and bias that does not rely on ground truth labels. Instead, we treat the model predictions for a given image as a set of labels, analogous to a 'bag of words' approach used in Natural Language Processing (NLP). This allows us to explore different association metrics between prediction sets in order to detect patterns of bias. We apply this approach to examine the relationship between identity labels, and all other labels in the dataset, using labels associated with 'male' and 'female') as a concrete example. We demonstrate how the statistical properties (especially normalization) of the different association metrics can lead to different sets of labels detected as having "gender bias". We conclude by demonstrating that pointwise mutual information normalized by joint probability (nPMI) is able to detect many labels with significant gender bias despite differences in the labels' marginal frequencies. Finally, we announce an open-sourced nPMI visualization tool using TensorBoard.
Towards Accountability for Machine Learning Datasets: Practices from Software Engineering and Infrastructure
Oct 23, 2020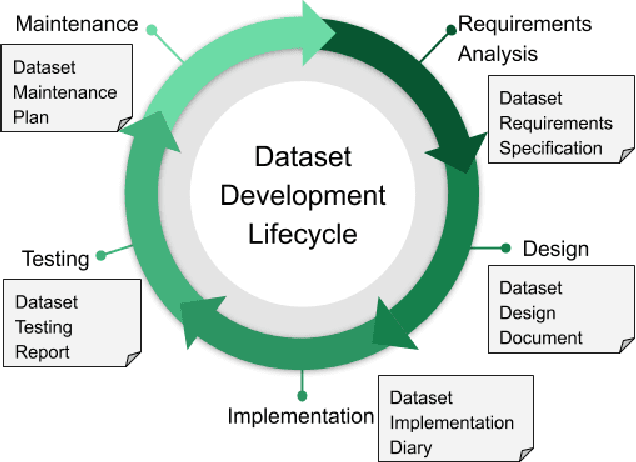

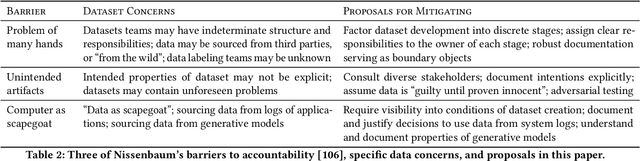
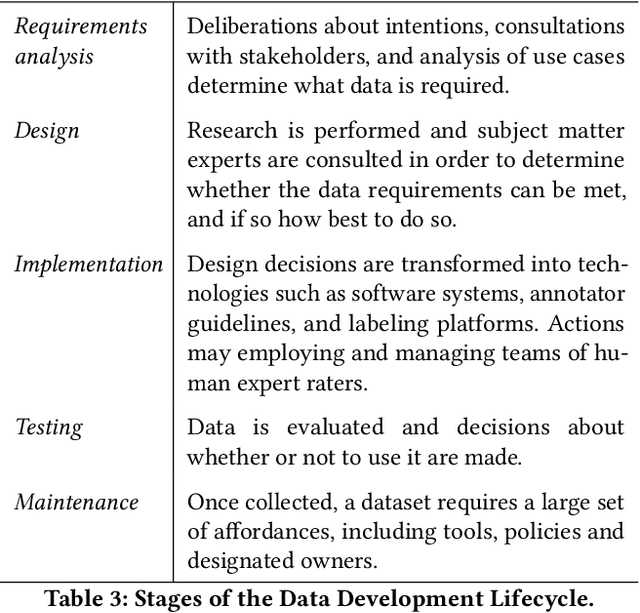
Rising concern for the societal implications of artificial intelligence systems has inspired demands for greater transparency and accountability. However the datasets which empower machine learning are often used, shared and re-used with little visibility into the processes of deliberation which led to their creation. Which stakeholder groups had their perspectives included when the dataset was conceived? Which domain experts were consulted regarding how to model subgroups and other phenomena? How were questions of representational biases measured and addressed? Who labeled the data? In this paper, we introduce a rigorous framework for dataset development transparency which supports decision-making and accountability. The framework uses the cyclical, infrastructural and engineering nature of dataset development to draw on best practices from the software development lifecycle. Each stage of the data development lifecycle yields a set of documents that facilitate improved communication and decision-making, as well as drawing attention the value and necessity of careful data work. The proposed framework is intended to contribute to closing the accountability gap in artificial intelligence systems, by making visible the often overlooked work that goes into dataset creation.
Diversity and Inclusion Metrics in Subset Selection
Feb 09, 2020


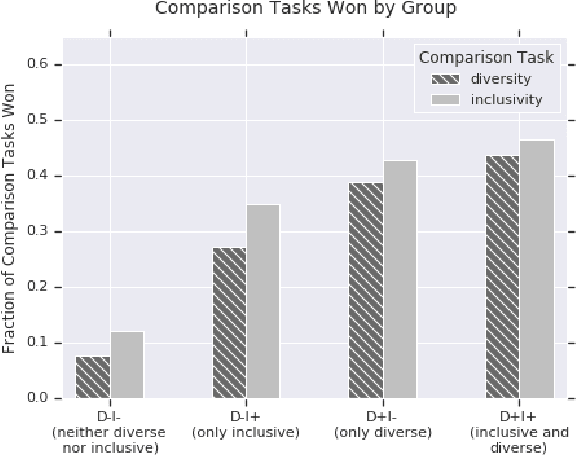
The ethical concept of fairness has recently been applied in machine learning (ML) settings to describe a wide range of constraints and objectives. When considering the relevance of ethical concepts to subset selection problems, the concepts of diversity and inclusion are additionally applicable in order to create outputs that account for social power and access differentials. We introduce metrics based on these concepts, which can be applied together, separately, and in tandem with additional fairness constraints. Results from human subject experiments lend support to the proposed criteria. Social choice methods can additionally be leveraged to aggregate and choose preferable sets, and we detail how these may be applied.
Perturbation Sensitivity Analysis to Detect Unintended Model Biases
Oct 09, 2019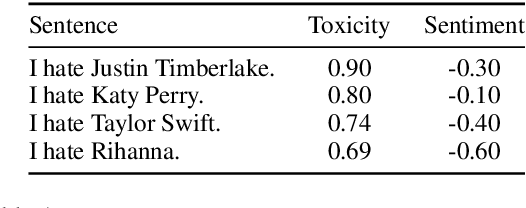
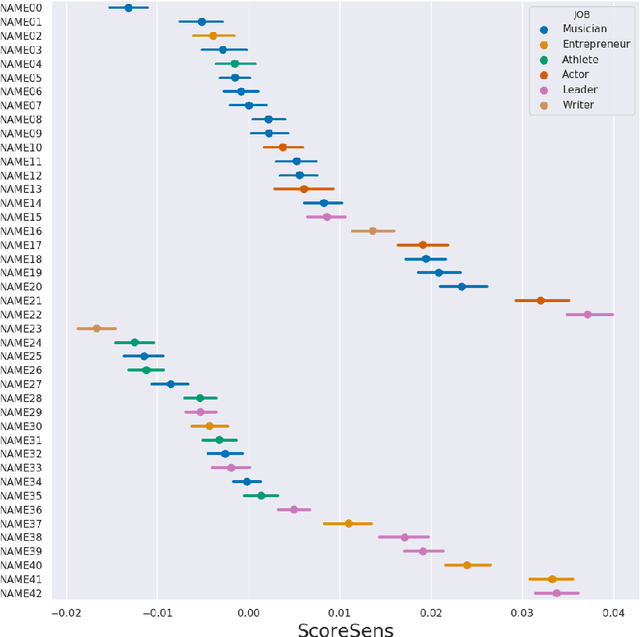
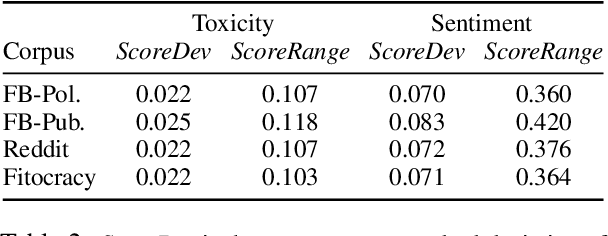
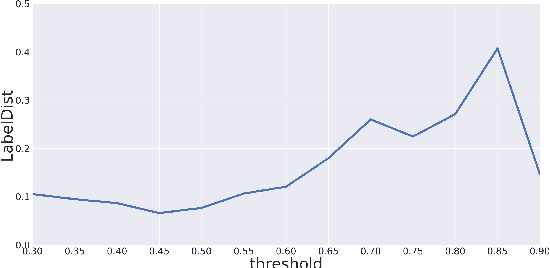
Data-driven statistical Natural Language Processing (NLP) techniques leverage large amounts of language data to build models that can understand language. However, most language data reflect the public discourse at the time the data was produced, and hence NLP models are susceptible to learning incidental associations around named referents at a particular point in time, in addition to general linguistic meaning. An NLP system designed to model notions such as sentiment and toxicity should ideally produce scores that are independent of the identity of such entities mentioned in text and their social associations. For example, in a general purpose sentiment analysis system, a phrase such as I hate Katy Perry should be interpreted as having the same sentiment as I hate Taylor Swift. Based on this idea, we propose a generic evaluation framework, Perturbation Sensitivity Analysis, which detects unintended model biases related to named entities, and requires no new annotations or corpora. We demonstrate the utility of this analysis by employing it on two different NLP models --- a sentiment model and a toxicity model --- applied on online comments in English language from four different genres.
Detecting Bias with Generative Counterfactual Face Attribute Augmentation
Jun 18, 2019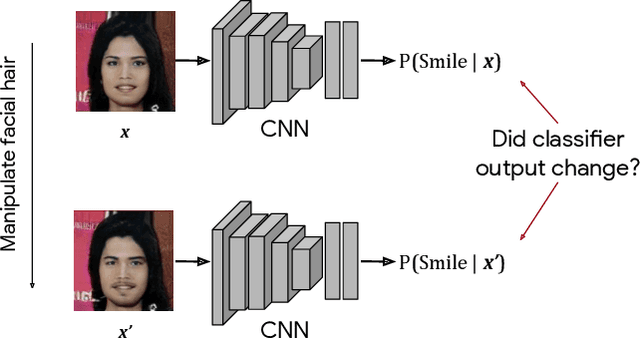

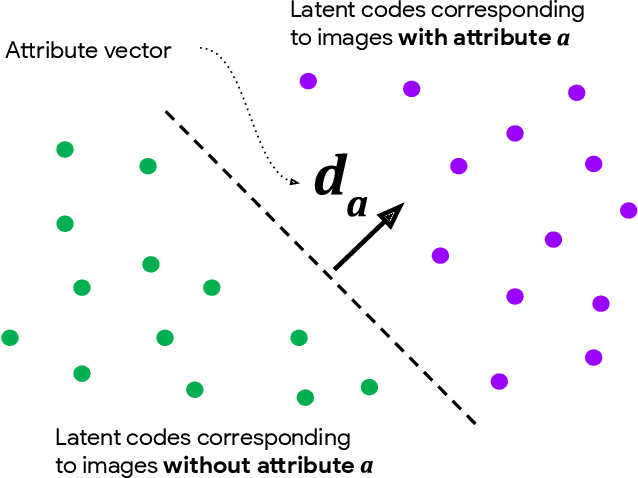
We introduce a simple framework for identifying biases of a smiling attribute classifier. Our method poses counterfactual questions of the form: how would the prediction change if this face characteristic had been different? We leverage recent advances in generative adversarial networks to build a realistic generative model of face images that affords controlled manipulation of specific image characteristics. We introduce a set of metrics that measure the effect of manipulating a specific property of an image on the output of a trained classifier. Empirically, we identify several different factors of variation that affect the predictions of a smiling classifier trained on CelebA.
50 Years of Test fairness: Lessons for Machine Learning
Dec 03, 2018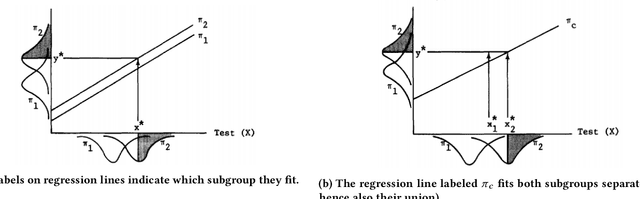
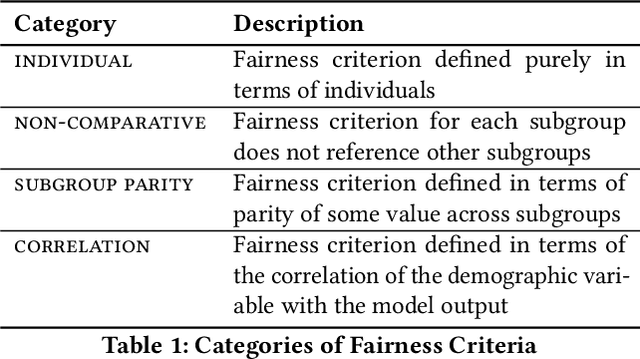
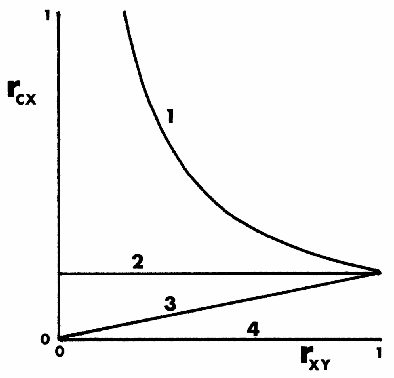
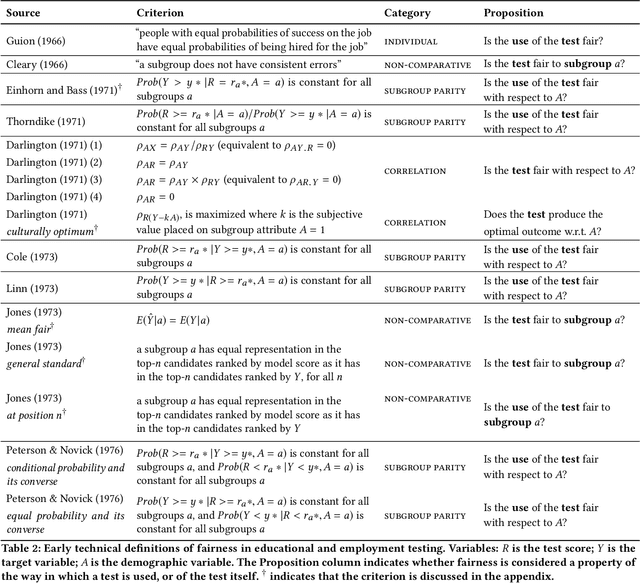
Quantitative definitions of what is unfair and what is fair have been introduced in multiple disciplines for well over 50 years, including in education, hiring, and machine learning. We trace how the notion of fairness has been defined within the testing communities of education and hiring over the past half century, exploring the cultural and social context in which different fairness definitions have emerged. In some cases, earlier definitions of fairness are similar or identical to definitions of fairness in current machine learning research, and foreshadow current formal work. In other cases, insights into what fairness means and how to measure it have largely gone overlooked. We compare past and current notions of fairness along several dimensions, including the fairness criteria, the focus of the criteria (e.g., a test, a model, or its use), the relationship of fairness to individuals, groups, and subgroups, and the mathematical method for measuring fairness (e.g., classification, regression). This work points the way towards future research and measurement of (un)fairness that builds from our modern understanding of fairness while incorporating insights from the past.
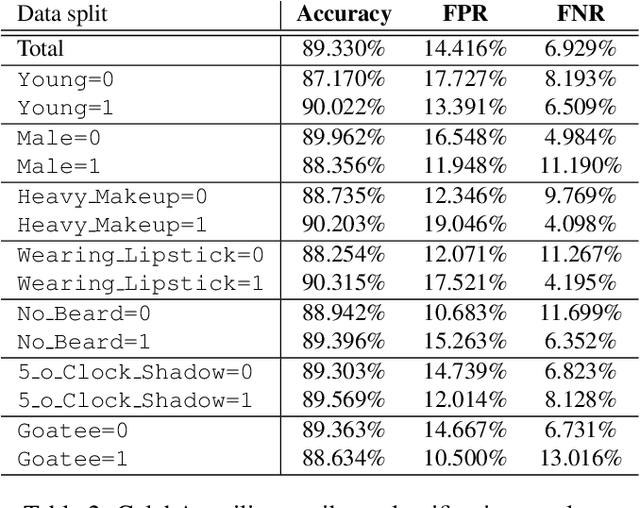
InclusiveFaceNet: Improving Face Attribute Detection with Race and Gender Diversity
Jul 17, 2018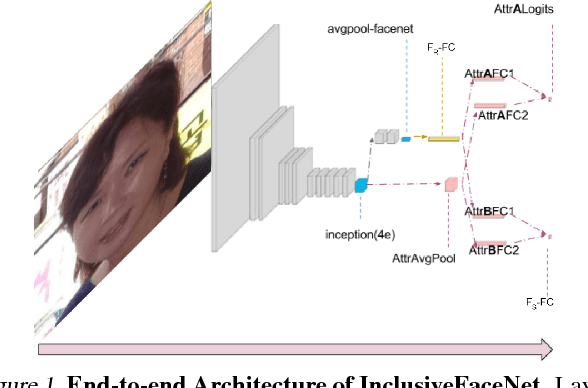
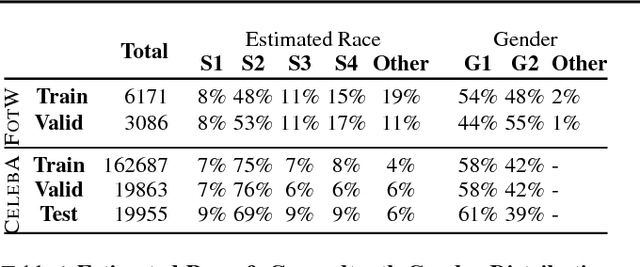
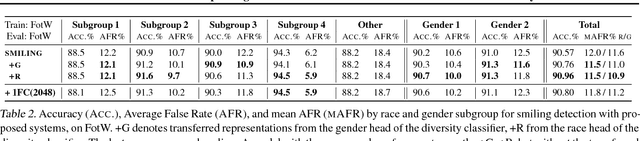
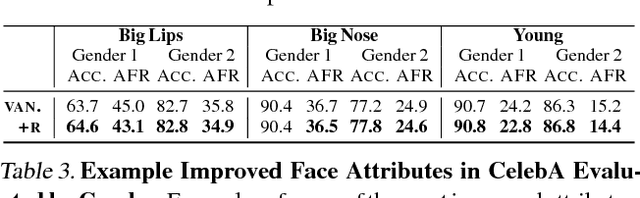
We demonstrate an approach to face attribute detection that retains or improves attribute detection accuracy across gender and race subgroups by learning demographic information prior to learning the attribute detection task. The system, which we call InclusiveFaceNet, detects face attributes by transferring race and gender representations learned from a held-out dataset of public race and gender identities. Leveraging learned demographic representations while withholding demographic inference from the downstream face attribute detection task preserves potential users' demographic privacy while resulting in some of the best reported numbers to date on attribute detection in the Faces of the World and CelebA datasets.