 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-guided Skill Learning with Temporal Variational Inference
Feb 26, 2024



We present an algorithm for skill discovery from expert demonstrations. The algorithm first utilizes Large Language Models (LLMs) to propose an initial segmentation of the trajectories. Following that, a hierarchical variational inference framework incorporates the LLM-generated segmentation information to discover reusable skills by merging trajectory segments. To further control the trade-off between compression and reusability, we introduce a novel auxiliary objective based on the Minimum Description Length principle that helps guide this skill discovery process. Our results demonstrate that agents equipped with our method are able to discover skills that help accelerate learning and outperform baseline skill learning approaches on new long-horizon tasks in BabyAI, a grid world navigation environment, as well as ALFRED, a household simulation environment.
Policy Improvement using Language Feedback Models
Feb 25, 2024



We introduce Language Feedback Models (LFMs) that identify desirable behaviour - actions that help achieve tasks specified in the instruction - for imitation learning in instruction following. To train LFMs, we obtain feedback from Large Language Models (LLMs) on visual trajectories verbalized to language descriptions. First, by using LFMs to identify desirable behaviour to imitate, we improve in task-completion rate over strong behavioural cloning baselines on three distinct language grounding environments (Touchdown, ScienceWorld, and ALFWorld). Second, LFMs outperform using LLMs as experts to directly predict actions, when controlling for the number of LLM output tokens. Third, LFMs generalize to unseen environments, improving task-completion rate by 3.5-12.0% through one round of adaptation. Finally, LFM can be modified to provide human-interpretable feedback without performance loss, allowing human verification of desirable behaviour for imitation learning.
Deep Language Networks: Joint Prompt Training of Stacked LLMs using Variational Inference
Jun 21, 2023



We view large language models (LLMs) as stochastic \emph{language layers} in a network, where the learnable parameters are the natural language \emph{prompts} at each layer. We stack two such layers, feeding the output of one layer to the next. We call the stacked architecture a \emph{Deep Language Network} (DLN). We first show how to effectively perform prompt optimization for a 1-Layer language network (DLN-1). We then show how to train 2-layer DLNs (DLN-2), where two prompts must be learnt. We consider the output of the first layer as a latent variable to marginalize, and devise a variational inference algorithm for joint prompt training. A DLN-2 reaches higher performance than a single layer, sometimes comparable to few-shot GPT-4 even when each LLM in the network is smaller and less powerful. The DLN code is open source: https://github.com/microsoft/deep-language-networks .
ByteSized32: A Corpus and Challenge Task for Generating Task-Specific World Models Expressed as Text Games
May 24, 2023



In this work we examine the ability of language models to generate explicit world models of scientific and common-sense reasoning tasks by framing this as a problem of generating text-based games. To support this, we introduce ByteSized32, a corpus of 32 highly-templated text games written in Python totaling 24k lines of code, each centered around a particular task, and paired with a set of 16 unseen text game specifications for evaluation. We propose a suite of automatic and manual metrics for assessing simulation validity, compliance with task specifications, playability, winnability, and alignment with the physical world. In a single-shot evaluation of GPT-4 on this simulation-as-code-generation task, we find it capable of producing runnable games in 27% of cases, highlighting the difficulty of this challenge task. We discuss areas of future improvement, including GPT-4's apparent capacity to perform well at simulating near canonical task solutions, with performance dropping off as simulations include distractors or deviate from canonical solutions in the action space.
Augmenting Autotelic Agents with Large Language Models
May 21, 2023Humans learn to master open-ended repertoires of skills by imagining and practicing their own goals. This autotelic learning process, literally the pursuit of self-generated (auto) goals (telos), becomes more and more open-ended as the goals become more diverse, abstract and creative. The resulting exploration of the space of possible skills is supported by an inter-individual exploration: goal representations are culturally evolved and transmitted across individuals, in particular using language. Current artificial agents mostly rely on predefined goal representations corresponding to goal spaces that are either bounded (e.g. list of instructions), or unbounded (e.g. the space of possible visual inputs) but are rarely endowed with the ability to reshape their goal representations, to form new abstractions or to imagine creative goals. In this paper, we introduce a language model augmented autotelic agent (LMA3) that leverages a pretrained language model (LM) to support the representation, generation and learning of diverse, abstract, human-relevant goals. The LM is used as an imperfect model of human cultural transmission; an attempt to capture aspects of humans' common-sense, intuitive physics and overall interests. Specifically, it supports three key components of the autotelic architecture: 1)~a relabeler that describes the goals achieved in the agent's trajectories, 2)~a goal generator that suggests new high-level goals along with their decomposition into subgoals the agent already masters, and 3)~reward functions for each of these goals. Without relying on any hand-coded goal representations, reward functions or curriculum, we show that LMA3 agents learn to master a large diversity of skills in a task-agnostic text-based environment.
A Song of Ice and Fire: Analyzing Textual Autotelic Agents in ScienceWorld
Feb 24, 2023



Building open-ended agents that can autonomously discover a diversity of behaviours is one of the long-standing goals of artificial intelligence. This challenge can be studied in the framework of autotelic RL agents, i.e. agents that learn by selecting and pursuing their own goals, self-organizing a learning curriculum. Recent work identified language as a key dimension of autotelic learning, in particular because it enables abstract goal sampling and guidance from social peers for hindsight relabelling. Within this perspective, we study the following open scientific questions: What is the impact of hindsight feedback from a social peer (e.g. selective vs. exhaustive)? How can the agent learn from very rare language goal examples in its experience replay? How can multiple forms of exploration be combined, and take advantage of easier goals as stepping stones to reach harder ones? To address these questions, we use ScienceWorld, a textual environment with rich abstract and combinatorial physics. We show the importance of selectivity from the social peer's feedback; that experience replay needs to over-sample examples of rare goals; and that following self-generated goal sequences where the agent's competence is intermediate leads to significant improvements in final performance.
Collecting Interactive Multi-modal Datasets for Grounded Language Understanding
Nov 18, 2022


Human intelligence can remarkably adapt quickly to new tasks and environments. Starting from a very young age, humans acquire new skills and learn how to solve new tasks either by imitating the behavior of others or by following provided natural language instructions. To facilitate research which can enable similar capabilities in machines, we made the following contributions (1) formalized the collaborative embodied agent using natural language task; (2) developed a tool for extensive and scalable data collection; and (3) collected the first dataset for interactive grounded language understanding.
Learning to Solve Voxel Building Embodied Tasks from Pixels and Natural Language Instructions
Nov 01, 2022The adoption of pre-trained language models to generate action plans for embodied agents is a promising research strategy. However, execution of instructions in real or simulated environments requires verification of the feasibility of actions as well as their relevance to the completion of a goal. We propose a new method that combines a language model and reinforcement learning for the task of building objects in a Minecraft-like environment according to the natural language instructions. Our method first generates a set of consistently achievable sub-goals from the instructions and then completes associated sub-tasks with a pre-trained RL policy. The proposed method formed the RL baseline at the IGLU 2022 competition.
Behavior Cloned Transformers are Neurosymbolic Reasoners
Oct 13, 2022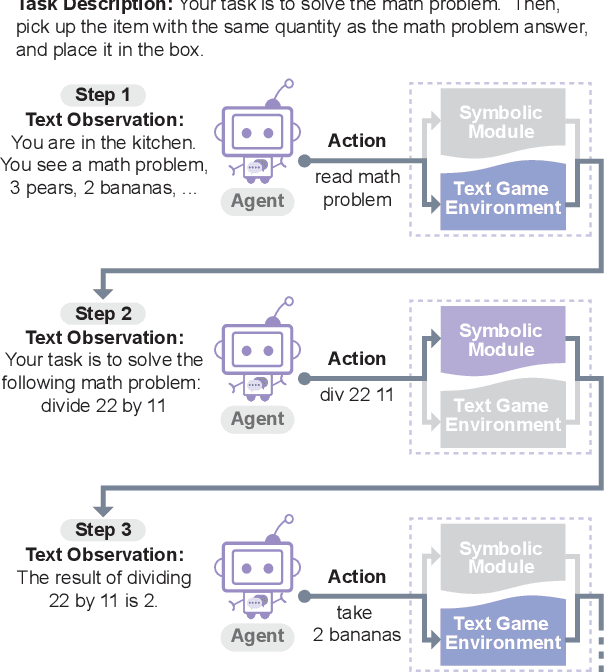

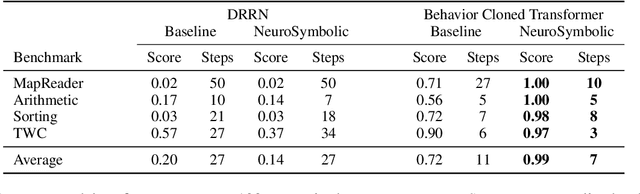
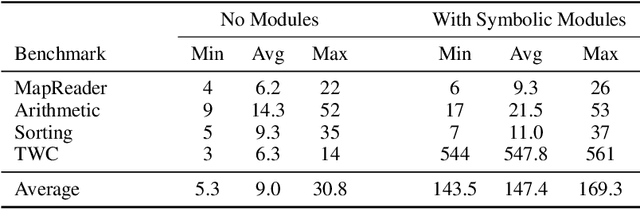
In this work, we explore techniques for augmenting interactive agents with information from symbolic modules, much like humans use tools like calculators and GPS systems to assist with arithmetic and navigation. We test our agent's abilities in text games -- challenging benchmarks for evaluating the multi-step reasoning abilities of game agents in grounded, language-based environments. Our experimental study indicates that injecting the actions from these symbolic modules into the action space of a behavior cloned transformer agent increases performance on four text game benchmarks that test arithmetic, navigation, sorting, and common sense reasoning by an average of 22%, allowing an agent to reach the highest possible performance on unseen games. This action injection technique is easily extended to new agents, environments, and symbolic modules.
TextWorldExpress: Simulating Text Games at One Million Steps Per Second
Aug 01, 2022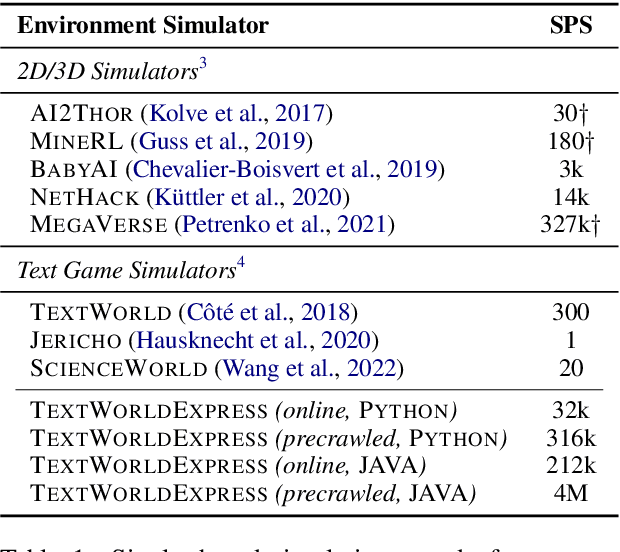
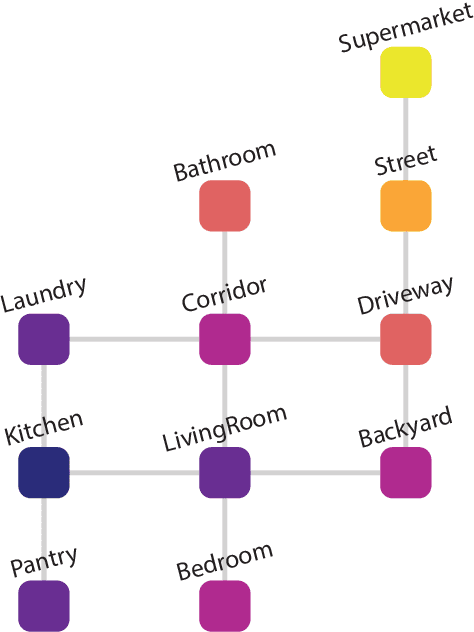


Text-based games offer a challenging test bed to evaluate virtual agents at language understanding, multi-step problem-solving, and common-sense reasoning. However, speed is a major limitation of current text-based games, capping at 300 steps per second, mainly due to the use of legacy tooling. In this work we present TextWorldExpress, a high-performance implementation of three common text game benchmarks that increases simulation throughput by approximately three orders of magnitude, reaching over one million steps per second on common desktop hardware. This significantly reduces experiment runtime, enabling billion-step-scale experiments in about one day.