 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Cross-modality Information Bottleneck Representation for Heterogeneous Person Re-Identification
Aug 29, 2023



Visible-Infrared person re-identification (VI-ReID) is an important and challenging task in intelligent video surveillance. Existing methods mainly focus on learning a shared feature space to reduce the modality discrepancy between visible and infrared modalities, which still leave two problems underexplored: information redundancy and modality complementarity. To this end, properly eliminating the identity-irrelevant information as well as making up for the modality-specific information are critical and remains a challenging endeavor. To tackle the above problems, we present a novel mutual information and modality consensus network, namely CMInfoNet, to extract modality-invariant identity features with the most representative information and reduce the redundancies. The key insight of our method is to find an optimal representation to capture more identity-relevant information and compress the irrelevant parts by optimizing a mutual information bottleneck trade-off. Besides, we propose an automatically search strategy to find the most prominent parts that identify the pedestrians. To eliminate the cross- and intra-modality variations, we also devise a modality consensus module to align the visible and infrared modalities for task-specific guidance. Moreover, the global-local feature representations can also be acquired for key parts discrimination. Experimental results on four benchmarks, i.e., SYSU-MM01, RegDB, Occluded-DukeMTMC, Occluded-REID, Partial-REID and Partial\_iLIDS dataset, have demonstrated the effectiveness of CMInfoNet.
ScoreMix: A Scalable Augmentation Strategy for Training GANs with Limited Data
Nov 04, 2022



Generative Adversarial Networks (GANs) typically suffer from overfitting when limited training data is available. To facilitate GAN training, current methods propose to use data-specific augmentation techniques. Despite the effectiveness, it is difficult for these methods to scale to practical applications. In this work, we present ScoreMix, a novel and scalable data augmentation approach for various image synthesis tasks. We first produce augmented samples using the convex combinations of the real samples. Then, we optimize the augmented samples by minimizing the norms of the data scores, i.e., the gradients of the log-density functions. This procedure enforces the augmented samples close to the data manifold. To estimate the scores, we train a deep estimation network with multi-scale score matching. For different image synthesis tasks, we train the score estimation network using different data. We do not require the tuning of the hyperparameters or modifications to the network architecture. The ScoreMix method effectively increases the diversity of data and reduces the overfitting problem. Moreover, it can be easily incorporated into existing GAN models with minor modifications. Experimental results on numerous tasks demonstrate that GAN models equipped with the ScoreMix method achieve significant improvements.
Heterogeneous Face Recognition via Face Synthesis with Identity-Attribute Disentanglement
Jun 10, 2022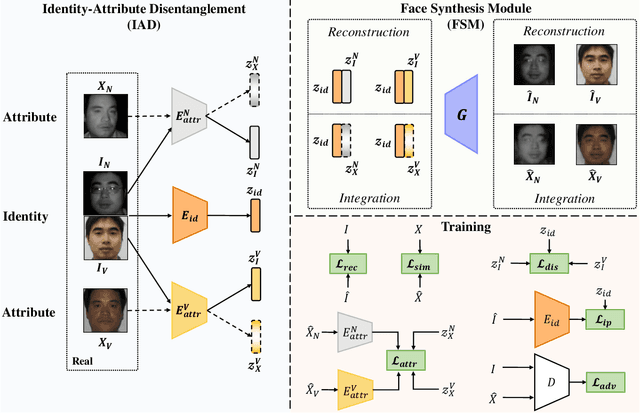


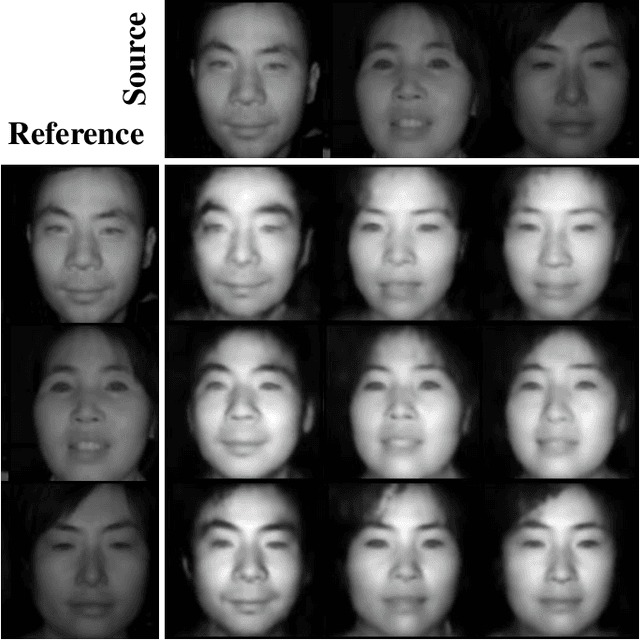
Heterogeneous Face Recognition (HFR) aims to match faces across different domains (e.g., visible to near-infrared images), which has been widely applied in authentication and forensics scenarios. However, HFR is a challenging problem because of the large cross-domain discrepancy, limited heterogeneous data pairs, and large variation of facial attributes. To address these challenges, we propose a new HFR method from the perspective of heterogeneous data augmentation, named Face Synthesis with Identity-Attribute Disentanglement (FSIAD). Firstly, the identity-attribute disentanglement (IAD) decouples face images into identity-related representations and identity-unrelated representations (called attributes), and then decreases the correlation between identities and attributes. Secondly, we devise a face synthesis module (FSM) to generate a large number of images with stochastic combinations of disentangled identities and attributes for enriching the attribute diversity of synthetic images. Both the original images and the synthetic ones are utilized to train the HFR network for tackling the challenges and improving the performance of HFR. Extensive experiments on five HFR databases validate that FSIAD obtains superior performance than previous HFR approaches. Particularly, FSIAD obtains 4.8% improvement over state of the art in terms of VR@FAR=0.01% on LAMP-HQ, the largest HFR database so far.
* Accepted for publication in IEEE Transactions on Information Forensics and Security (TIFS)
Unsupervised Contrastive Photo-to-Caricature Translation based on Auto-distortion
Nov 10, 2020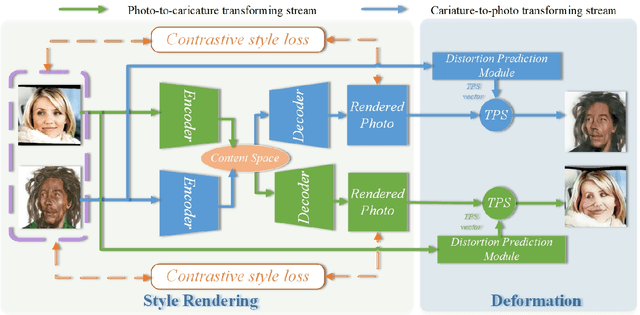
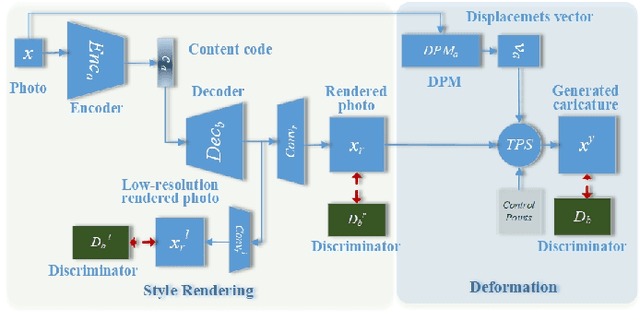

Photo-to-caricature translation aims to synthesize the caricature as a rendered image exaggerating the features through sketching, pencil strokes, or other artistic drawings. Style rendering and geometry deformation are the most important aspects in photo-to-caricature translation task. To take both into consideration, we propose an unsupervised contrastive photo-to-caricature translation architecture. Considering the intuitive artifacts in the existing methods, we propose a contrastive style loss for style rendering to enforce the similarity between the style of rendered photo and the caricature, and simultaneously enhance its discrepancy to the photos. To obtain an exaggerating deformation in an unpaired/unsupervised fashion, we propose a Distortion Prediction Module (DPM) to predict a set of displacements vectors for each input image while fixing some controlling points, followed by the thin plate spline interpolation for warping. The model is trained on unpaired photo and caricature while can offer bidirectional synthesizing via inputting either a photo or a caricature. Extensive experiments demonstrate that the proposed model is effective to generate hand-drawn like caricatures compared with existing competitors.
Deep Audio-Visual Learning: A Survey
Jan 14, 2020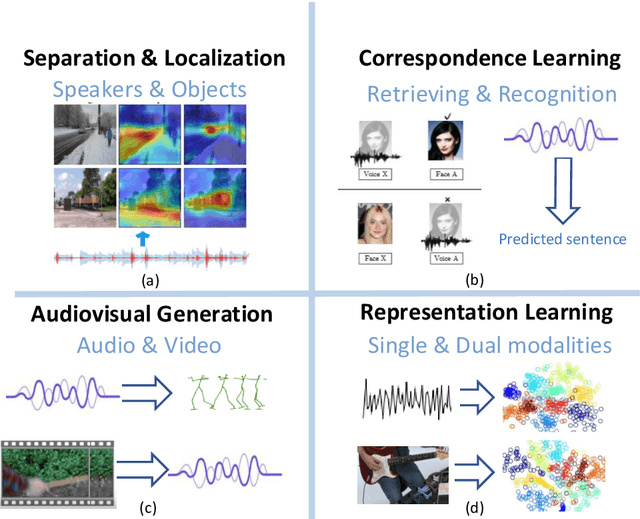
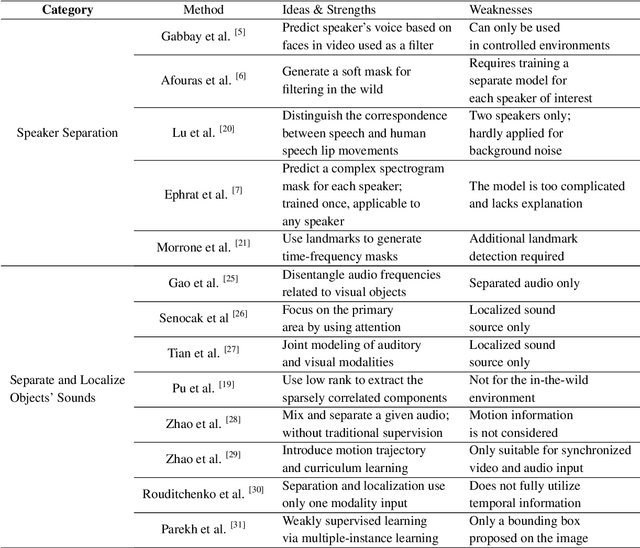
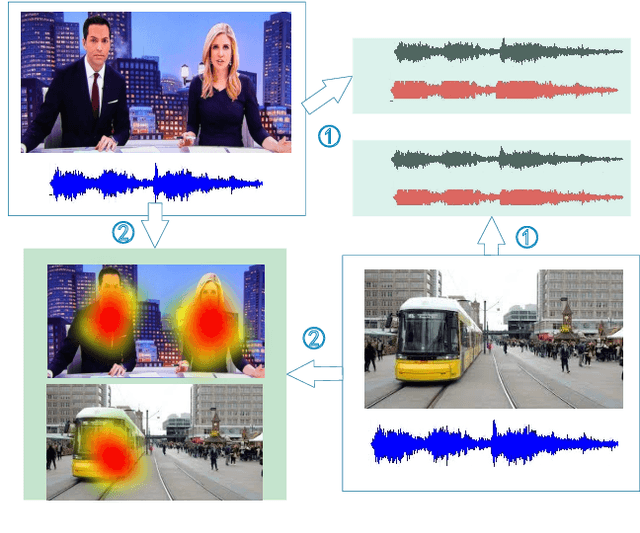
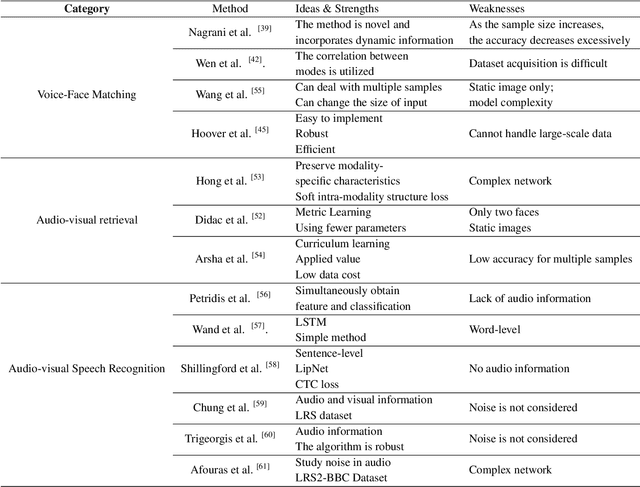
Audio-visual learning, aimed at exploiting the relationship between audio and visual modalities, has drawn considerable attention since deep learning started to be used successfully. Researchers tend to leverage these two modalities either to improve the performance of previously considered single-modality tasks or to address new challenging problems. In this paper, we provide a comprehensive survey of recent audio-visual learning development. We divide the current audio-visual learning tasks into four different subfields: audio-visual separation and localization, audio-visual correspondence learning, audio-visual generation, and audio-visual representation learning. State-of-the-art methods as well as the remaining challenges of each subfield are further discussed. Finally, we summarize the commonly used datasets and performance metrics.
Style-based Variational Autoencoder for Real-World Super-Resolution
Dec 21, 2019
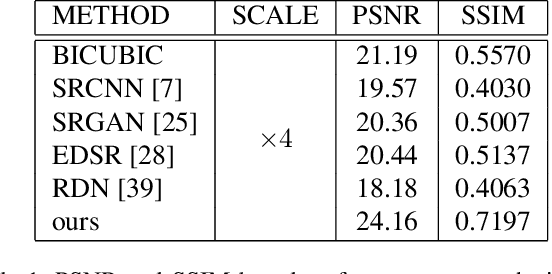
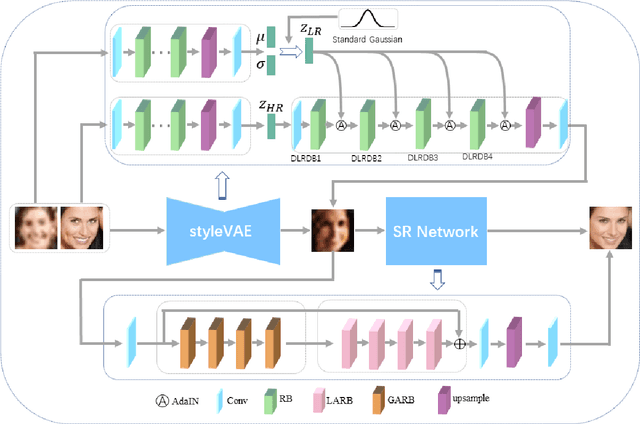
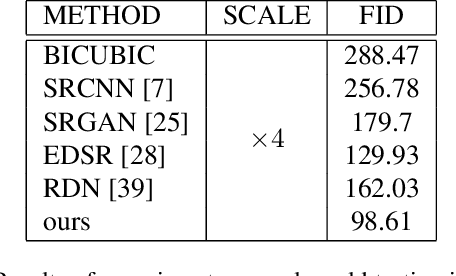
Real-world image super-resolution is a challenging image translation problem. Low-resolution (LR) images are often generated by various unknown transformations rather than by applying simple bilinear down-sampling on HR images. To address this issue, this paper proposes a novel Style-based Super-Resolution Variational Autoencoder network (SSRVAE) that contains a style Variational Autoencoder (styleVAE) and a SR Network. To get realistic real-world low-quality images paired with the HR images, we design a styleVAE to transfer the complex nuisance factors in real-world LR images to the generated LR images. We also use mutual information estimation (MI) to get better style information. For our SR network, we firstly propose a global attention residual block to learn long-range dependencies in images. Then another local attention residual block is proposed to enforce the attention of SR network moves to local areas of images in which texture detail will be filled. It is worth noticing that styleVAE is presented in a plug-and-play manner and thus can help to promote the generalization and robustness of our SR method as well as other SR methods. Extensive experiments demonstrate that our SSRVAE surpasses the state-of-the-art methods, both quantitatively and qualitatively.