 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Passage Retrieval with Zero-Shot Question Generation
Apr 15, 2022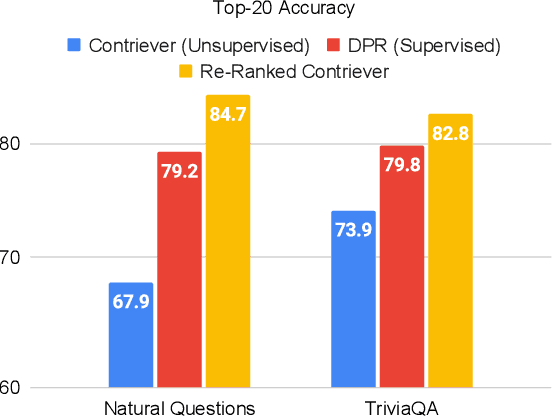
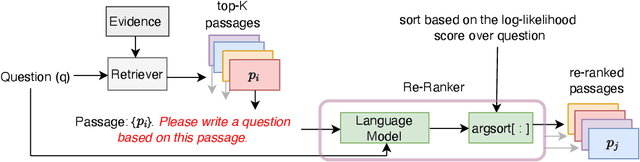
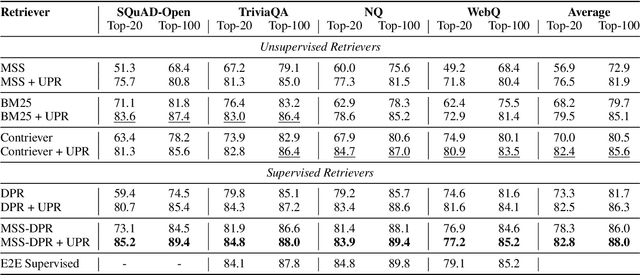
We propose a simple and effective re-ranking method for improving passage retrieval in open question answering. The re-ranker re-scores retrieved passages with a zero-shot question generation model, which uses a pre-trained language model to compute the probability of the input question conditioned on a retrieved passage. This approach can be applied on top of any retrieval method (e.g. neural or keyword-based), does not require any domain- or task-specific training (and therefore is expected to generalize better to data distribution shifts), and provides rich cross-attention between query and passage (i.e. it must explain every token in the question). When evaluated on a number of open-domain retrieval datasets, our re-ranker improves strong unsupervised retrieval models by 6%-18% absolute and strong supervised models by up to 12% in terms of top-20 passage retrieval accuracy. We also obtain new state-of-the-art results on full open-domain question answering by simply adding the new re-ranker to existing models with no further changes.
CM3: A Causal Masked Multimodal Model of the Internet
Jan 19, 2022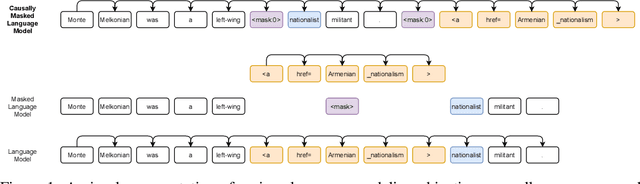
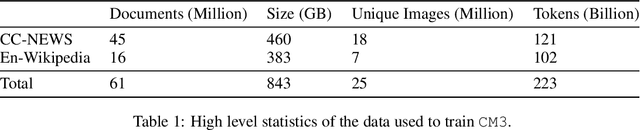
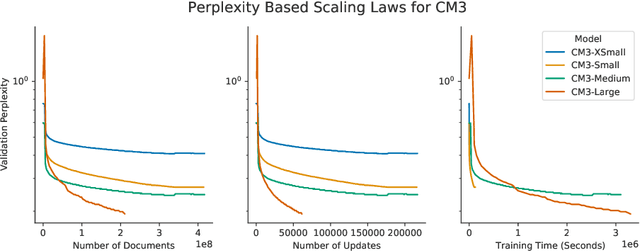
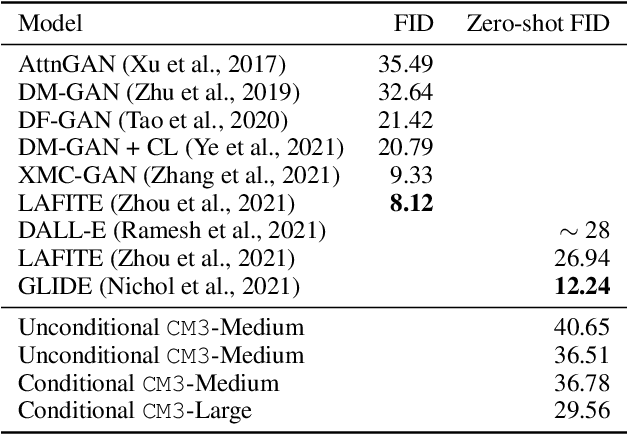
We introduce CM3, a family of causally masked generative models trained over a large corpus of structured multi-modal documents that can contain both text and image tokens. Our new causally masked approach generates tokens left to right while also masking out a small number of long token spans that are generated at the end of the string, instead of their original positions. The casual masking object provides a type of hybrid of the more common causal and masked language models, by enabling full generative modeling while also providing bidirectional context when generating the masked spans. We train causally masked language-image models on large-scale web and Wikipedia articles, where each document contains all of the text, hypertext markup, hyperlinks, and image tokens (from a VQVAE-GAN), provided in the order they appear in the original HTML source (before masking). The resulting CM3 models can generate rich structured, multi-modal outputs while conditioning on arbitrary masked document contexts, and thereby implicitly learn a wide range of text, image, and cross modal tasks. They can be prompted to recover, in a zero-shot fashion, the functionality of models such as DALL-E, GENRE, and HTLM. We set the new state-of-the-art in zero-shot summarization, entity linking, and entity disambiguation while maintaining competitive performance in the fine-tuning setting. We can generate images unconditionally, conditioned on text (like DALL-E) and do captioning all in a zero-shot setting with a single model.
HTLM: Hyper-Text Pre-Training and Prompting of Language Models
Jul 14, 2021



We introduce HTLM, a hyper-text language model trained on a large-scale web crawl. Modeling hyper-text has a number of advantages: (1) it is easily gathered at scale, (2) it provides rich document-level and end-task-adjacent supervision (e.g. class and id attributes often encode document category information), and (3) it allows for new structured prompting that follows the established semantics of HTML (e.g. to do zero-shot summarization by infilling title tags for a webpage that contains the input text). We show that pretraining with a BART-style denoising loss directly on simplified HTML provides highly effective transfer for a wide range of end tasks and supervision levels. HTLM matches or exceeds the performance of comparably sized text-only LMs for zero-shot prompting and fine-tuning for classification benchmarks, while also setting new state-of-the-art performance levels for zero-shot summarization. We also find that hyper-text prompts provide more value to HTLM, in terms of data efficiency, than plain text prompts do for existing LMs, and that HTLM is highly effective at auto-prompting itself, by simply generating the most likely hyper-text formatting for any available training data. We will release all code and models to support future HTLM research.
DESCGEN: A Distantly Supervised Dataset for Generating Abstractive Entity Descriptions
Jun 16, 2021
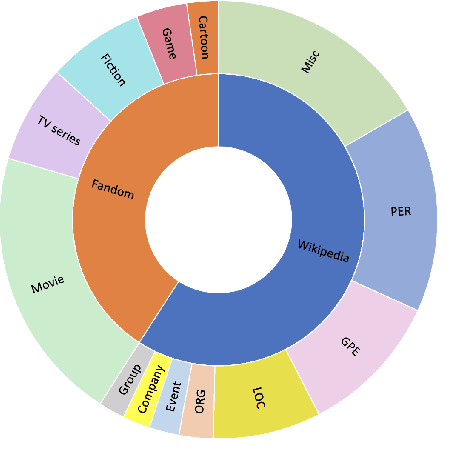

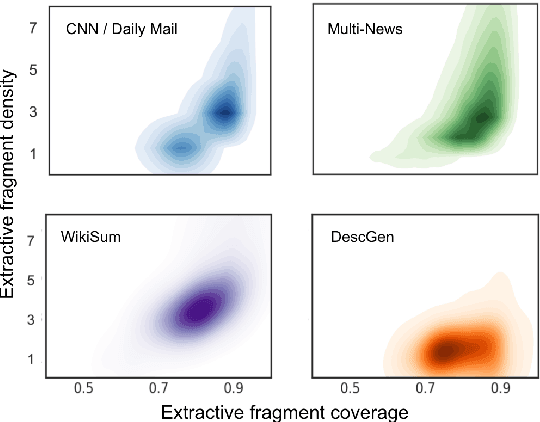
Short textual descriptions of entities provide summaries of their key attributes and have been shown to be useful sources of background knowledge for tasks such as entity linking and question answering. However, generating entity descriptions, especially for new and long-tail entities, can be challenging since relevant information is often scattered across multiple sources with varied content and style. We introduce DESCGEN: given mentions spread over multiple documents, the goal is to generate an entity summary description. DESCGEN consists of 37K entity descriptions from Wikipedia and Fandom, each paired with nine evidence documents on average. The documents were collected using a combination of entity linking and hyperlinks to the Wikipedia and Fandom entity pages, which together provide high-quality distant supervision. The resulting summaries are more abstractive than those found in existing datasets and provide a better proxy for the challenge of describing new and emerging entities. We also propose a two-stage extract-then-generate baseline and show that there exists a large gap (19.9% in ROUGE-L) between state-of-the-art models and human performance, suggesting that the data will support significant future work.
Realistic Evaluation Principles for Cross-document Coreference Resolution
Jun 08, 2021
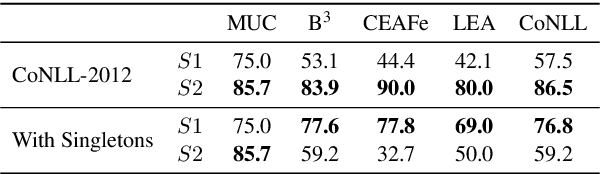
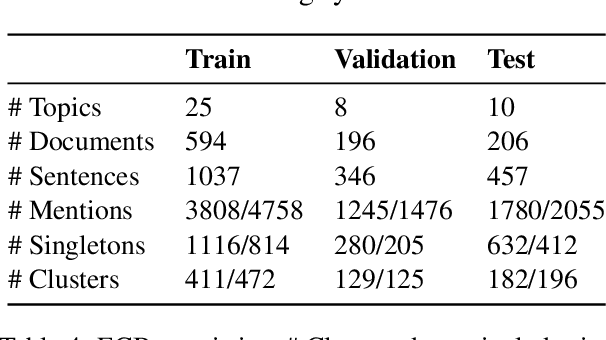
We point out that common evaluation practices for cross-document coreference resolution have been unrealistically permissive in their assumed settings, yielding inflated results. We propose addressing this issue via two evaluation methodology principles. First, as in other tasks, models should be evaluated on predicted mentions rather than on gold mentions. Doing this raises a subtle issue regarding singleton coreference clusters, which we address by decoupling the evaluation of mention detection from that of coreference linking. Second, we argue that models should not exploit the synthetic topic structure of the standard ECB+ dataset, forcing models to confront the lexical ambiguity challenge, as intended by the dataset creators. We demonstrate empirically the drastic impact of our more realistic evaluation principles on a competitive model, yielding a score which is 33 F1 lower compared to evaluating by prior lenient practices.
Cross-document Coreference Resolution over Predicted Mentions
Jun 02, 2021
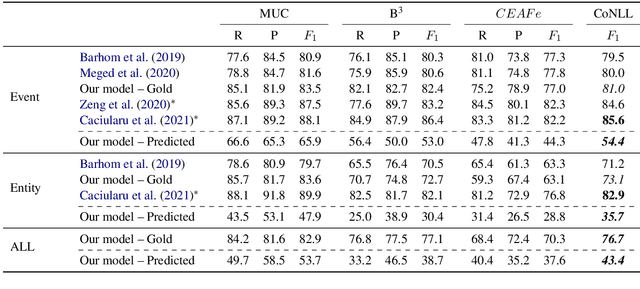
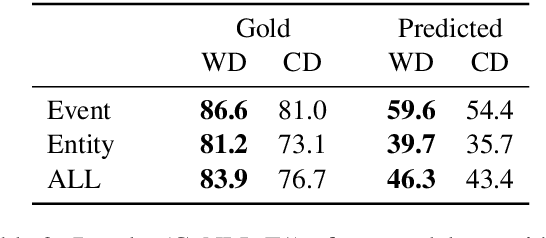

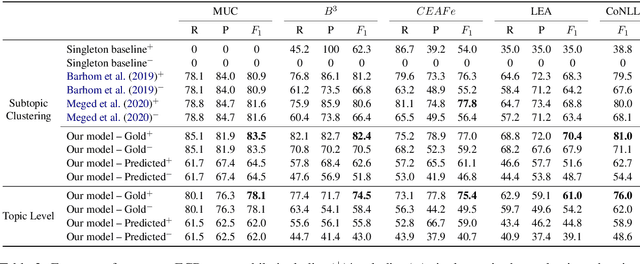
Coreference resolution has been mostly investigated within a single document scope, showing impressive progress in recent years based on end-to-end models. However, the more challenging task of cross-document (CD) coreference resolution remained relatively under-explored, with the few recent models applied only to gold mentions. Here, we introduce the first end-to-end model for CD coreference resolution from raw text, which extends the prominent model for within-document coreference to the CD setting. Our model achieves competitive results for event and entity coreference resolution on gold mentions. More importantly, we set first baseline results, on the standard ECB+ dataset, for CD coreference resolution over predicted mentions. Further, our model is simpler and more efficient than recent CD coreference resolution systems, while not using any external resources.
FEWS: Large-Scale, Low-Shot Word Sense Disambiguation with the Dictionary
Feb 16, 2021
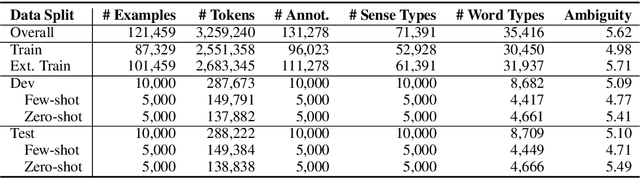
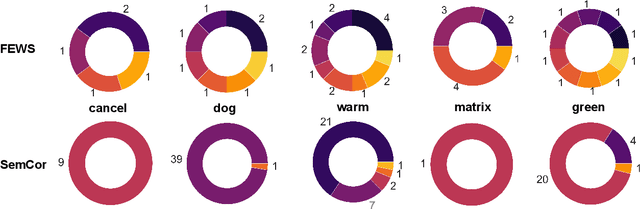
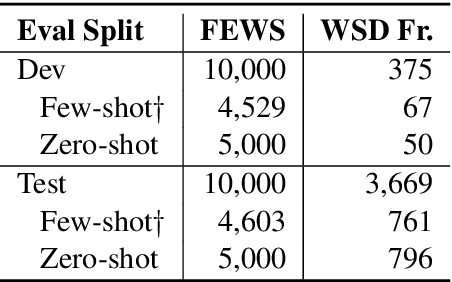
Current models for Word Sense Disambiguation (WSD) struggle to disambiguate rare senses, despite reaching human performance on global WSD metrics. This stems from a lack of data for both modeling and evaluating rare senses in existing WSD datasets. In this paper, we introduce FEWS (Few-shot Examples of Word Senses), a new low-shot WSD dataset automatically extracted from example sentences in Wiktionary. FEWS has high sense coverage across different natural language domains and provides: (1) a large training set that covers many more senses than previous datasets and (2) a comprehensive evaluation set containing few- and zero-shot examples of a wide variety of senses. We establish baselines on FEWS with knowledge-based and neural WSD approaches and present transfer learning experiments demonstrating that models additionally trained with FEWS better capture rare senses in existing WSD datasets. Finally, we find humans outperform the best baseline models on FEWS, indicating that FEWS will support significant future work on low-shot WSD.
Streamlining Cross-Document Coreference Resolution: Evaluation and Modeling
Sep 23, 2020

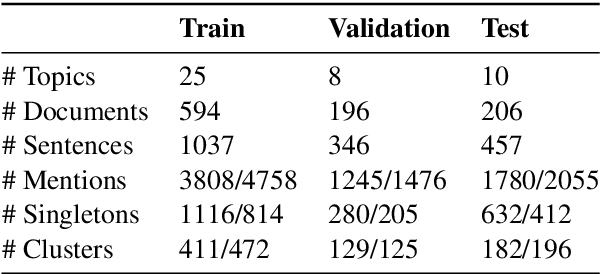
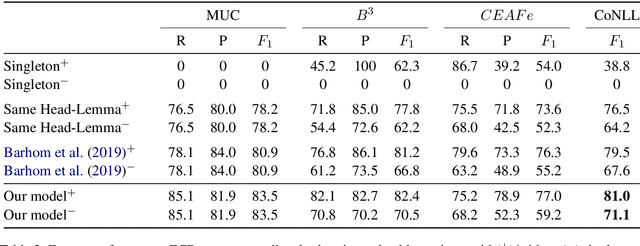
Recent evaluation protocols for Cross-document (CD) coreference resolution have often been inconsistent or lenient, leading to incomparable results across works and overestimation of performance. To facilitate proper future research on this task, our primary contribution is proposing a pragmatic evaluation methodology which assumes access to only raw text -- rather than assuming gold mentions, disregards singleton prediction, and addresses typical targeted settings in CD coreference resolution. Aiming to set baseline results for future research that would follow our evaluation methodology, we build the first end-to-end model for this task. Our model adapts and extends recent neural models for within-document coreference resolution to address the CD coreference setting, which outperforms state-of-the-art results by a significant margin.
An Information Bottleneck Approach for Controlling Conciseness in Rationale Extraction
May 01, 2020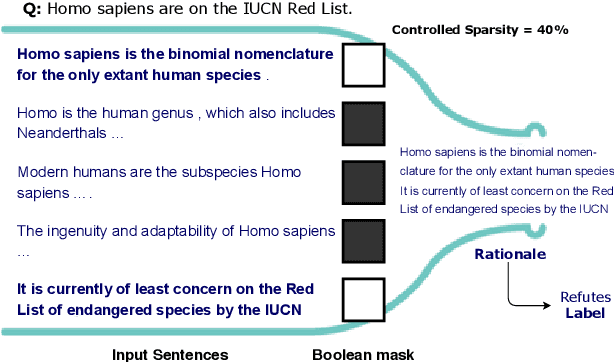
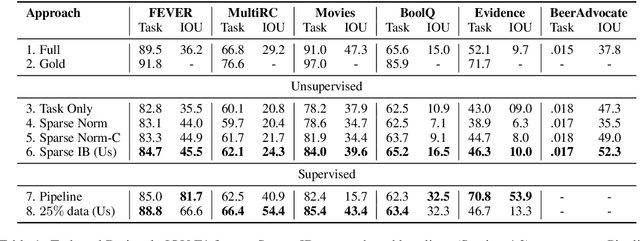
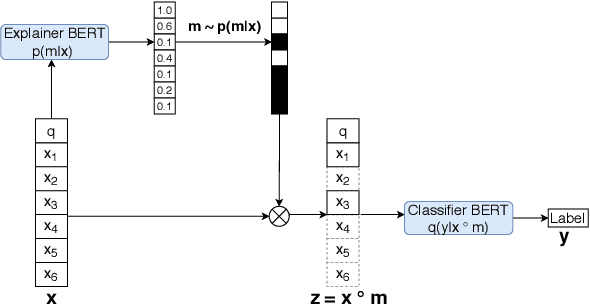
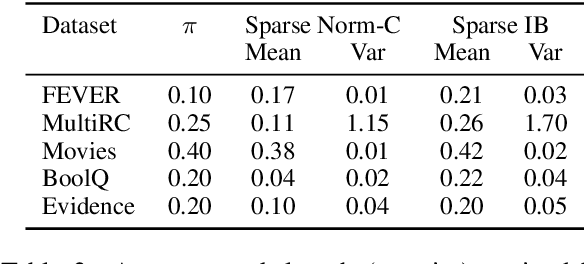
Decisions of complex language understanding models can be rationalized by limiting their inputs to a relevant subsequence of the original text. A rationale should be as concise as possible without significantly degrading task performance, but this balance can be difficult to achieve in practice. In this paper, we show that it is possible to better manage this trade-off by optimizing a bound on the Information Bottleneck (IB) objective. Our fully unsupervised approach jointly learns an explainer that predicts sparse binary masks over sentences, and an end-task predictor that considers only the extracted rationale. Using IB, we derive a learning objective that allows direct control of mask sparsity levels through a tunable sparse prior. Experiments on ERASER benchmark tasks demonstrate significant gains over norm-minimization techniques for both task performance and agreement with human rationales. Furthermore, we find that in the semi-supervised setting, a modest amount of gold rationales (25% of training examples) closes the gap with a model that uses the full input. Code: https://github.com/bhargaviparanjape/explainable_qa
Contextualized Representations Using Textual Encyclopedic Knowledge
Apr 24, 2020
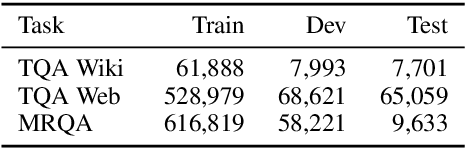

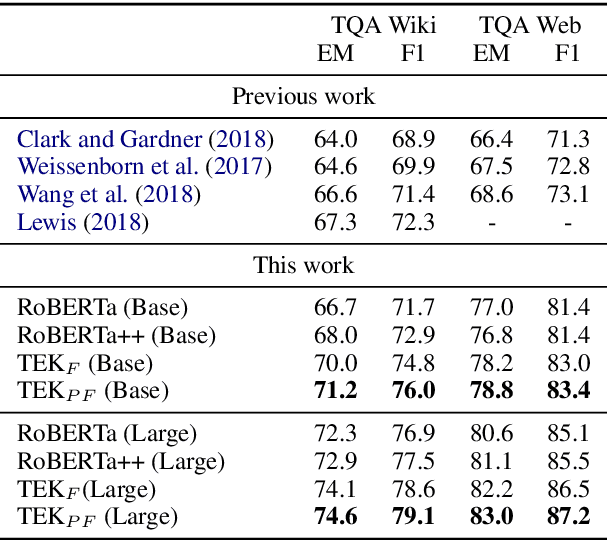
We present a method to represent input texts by contextualizing them jointly with dynamically retrieved textual encyclopedic background knowledge from multiple documents. We apply our method to reading comprehension tasks by encoding questions and passages together with background sentences about the entities they mention. We show that integrating background knowledge from text is effective for tasks focusing on factual reasoning and allows direct reuse of powerful pretrained BERT-style encoders. Moreover, knowledge integration can be further improved with suitable pretraining via a self-supervised masked language model objective over words in background-augmented input text. On TriviaQA, our approach obtains improvements of 1.6 to 3.1 F1 over comparable RoBERTa models which do not integrate background knowledge dynamically. On MRQA, a large collection of diverse QA datasets, we see consistent gains in-domain along with large improvements out-of-domain on BioASQ (2.1 to 4.2 F1), TextbookQA (1.6 to 2.0 F1), and DuoRC (1.1 to 2.0 F1).