 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisCGen: A Framework for Discourse-Informed Counterspeech Generation
Nov 29, 2023



Counterspeech can be an effective method for battling hateful content on social media. Automated counterspeech generation can aid in this process. Generated counterspeech, however, can be viable only when grounded in the context of topic, audience and sensitivity as these factors influence both the efficacy and appropriateness. In this work, we propose a novel framework based on theories of discourse to study the inferential links that connect counter speeches to the hateful comment. Within this framework, we propose: i) a taxonomy of counterspeech derived from discourse frameworks, and ii) discourse-informed prompting strategies for generating contextually-grounded counterspeech. To construct and validate this framework, we present a process for collecting an in-the-wild dataset of counterspeech from Reddit. Using this process, we manually annotate a dataset of 3.9k Reddit comment pairs for the presence of hatespeech and counterspeech. The positive pairs are annotated for 10 classes in our proposed taxonomy. We annotate these pairs with paraphrased counterparts to remove offensiveness and first-person references. We show that by using our dataset and framework, large language models can generate contextually-grounded counterspeech informed by theories of discourse. According to our human evaluation, our approaches can act as a safeguard against critical failures of discourse-agnostic models.
Learning to Generate Equitable Text in Dialogue from Biased Training Data
Jul 10, 2023



The ingrained principles of fairness in a dialogue system's decision-making process and generated responses are crucial for user engagement, satisfaction, and task achievement. Absence of equitable and inclusive principles can hinder the formation of common ground, which in turn negatively impacts the overall performance of the system. For example, misusing pronouns in a user interaction may cause ambiguity about the intended subject. Yet, there is no comprehensive study of equitable text generation in dialogue. Aptly, in this work, we use theories of computational learning to study this problem. We provide formal definitions of equity in text generation, and further, prove formal connections between learning human-likeness and learning equity: algorithms for improving equity ultimately reduce to algorithms for improving human-likeness (on augmented data). With this insight, we also formulate reasonable conditions under which text generation algorithms can learn to generate equitable text without any modifications to the biased training data on which they learn. To exemplify our theory in practice, we look at a group of algorithms for the GuessWhat?! visual dialogue game and, using this example, test our theory empirically. Our theory accurately predicts relative-performance of multiple algorithms in generating equitable text as measured by both human and automated evaluation.
D-CALM: A Dynamic Clustering-based Active Learning Approach for Mitigating Bias
May 26, 2023



Despite recent advancements, NLP models continue to be vulnerable to bias. This bias often originates from the uneven distribution of real-world data and can propagate through the annotation process. Escalated integration of these models in our lives calls for methods to mitigate bias without overbearing annotation costs. While active learning (AL) has shown promise in training models with a small amount of annotated data, AL's reliance on the model's behavior for selective sampling can lead to an accumulation of unwanted bias rather than bias mitigation. However, infusing clustering with AL can overcome the bias issue of both AL and traditional annotation methods while exploiting AL's annotation efficiency. In this paper, we propose a novel adaptive clustering-based active learning algorithm, D-CALM, that dynamically adjusts clustering and annotation efforts in response to an estimated classifier error-rate. Experiments on eight datasets for a diverse set of text classification tasks, including emotion, hatespeech, dialog act, and book type detection, demonstrate that our proposed algorithm significantly outperforms baseline AL approaches with both pretrained transformers and traditional Support Vector Machines. D-CALM showcases robustness against different measures of information gain and, as evident from our analysis of label and error distribution, can significantly reduce unwanted model bias.
How Old is GPT?: The HumBEL Framework for Evaluating Language Models using Human Demographic Data
May 24, 2023



While large pre-trained language models (LMs) find greater use across NLP, existing evaluation protocols do not consider how LM language use aligns with particular human demographic groups, which can be an important consideration in conversational AI applications. To remedy this gap, we consider how LM language skills can be measured and compared to human sub-populations. We suggest clinical techniques from Speech Language Pathology, which has well-established norms for acquisition of language skills, organized by (human) age. We conduct evaluation with a domain expert (i.e., a clinically licensed speech language pathologist), and also propose automated techniques to substitute clinical evaluation at scale. We find LM capability varies widely depending on task with GPT-3.5 mimicking the ability of a typical 6-9 year old at tasks requiring inference about word meanings and simultaneously outperforming a typical 21 year old at memorization. GPT-3.5 (InstructGPT) also has trouble with social language use, exhibiting less than 50\% of the tested pragmatic skills. It shows errors in understanding particular word parts-of-speech and associative word relations, among other lexical features. Ultimately, findings reiterate the importance of considering demographic alignment and conversational goals when using these models as public-facing tools. Our framework will be publicly available via code, data, and a python package.
Multilingual Content Moderation: A Case Study on Reddit
Feb 19, 2023



Content moderation is the process of flagging content based on pre-defined platform rules. There has been a growing need for AI moderators to safeguard users as well as protect the mental health of human moderators from traumatic content. While prior works have focused on identifying hateful/offensive language, they are not adequate for meeting the challenges of content moderation since 1) moderation decisions are based on violation of rules, which subsumes detection of offensive speech, and 2) such rules often differ across communities which entails an adaptive solution. We propose to study the challenges of content moderation by introducing a multilingual dataset of 1.8 Million Reddit comments spanning 56 subreddits in English, German, Spanish and French. We perform extensive experimental analysis to highlight the underlying challenges and suggest related research problems such as cross-lingual transfer, learning under label noise (human biases), transfer of moderation models, and predicting the violated rule. Our dataset and analysis can help better prepare for the challenges and opportunities of auto moderation.
SODA: Million-scale Dialogue Distillation with Social Commonsense Contextualization
Dec 20, 2022



We present SODA: the first publicly available, million-scale high-quality social dialogue dataset. Using SODA, we train COSMO: a generalizable conversation agent outperforming previous best-performing agents on both in- and out-of-domain datasets. In contrast to most existing crowdsourced, small-scale dialogue corpora, we distill 1.5M socially-grounded dialogues from a pre-trained language model (InstructGPT; Ouyang et al., 2022). Dialogues are distilled by contextualizing social commonsense knowledge from a knowledge graph (Atomic10x; West et al., 2022). Human evaluation shows that dialogues in SODA are more consistent, specific, and (surprisingly) natural than prior human-authored datasets - e.g., DailyDialog (Li et al., 2017), BlendedSkillTalk (Smith et al., 2020). In addition, extensive evaluations show that COSMO is significantly more natural and consistent on unseen datasets than best-performing dialogue models - e.g., GODEL (Peng et al., 2022), BlenderBot (Roller et al., 2021), DialoGPT (Zhang et al., 2020). Furthermore, it is sometimes even preferred to the original human-written gold responses. We make our data, models, and code public.
LEATHER: A Framework for Learning to Generate Human-like Text in Dialogue
Oct 14, 2022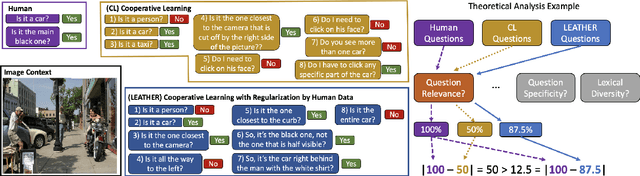

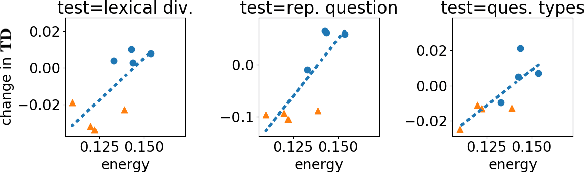
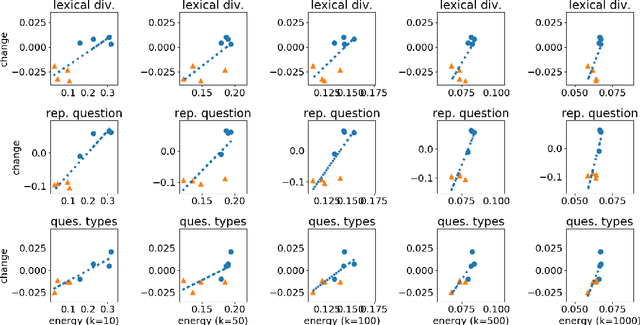
Algorithms for text-generation in dialogue can be misguided. For example, in task-oriented settings, reinforcement learning that optimizes only task-success can lead to abysmal lexical diversity. We hypothesize this is due to poor theoretical understanding of the objectives in text-generation and their relation to the learning process (i.e., model training). To this end, we propose a new theoretical framework for learning to generate text in dialogue. Compared to existing theories of learning, our framework allows for analysis of the multi-faceted goals inherent to text-generation. We use our framework to develop theoretical guarantees for learners that adapt to unseen data. As an example, we apply our theory to study data-shift within a cooperative learning algorithm proposed for the GuessWhat?! visual dialogue game. From this insight, we propose a new algorithm, and empirically, we demonstrate our proposal improves both task-success and human-likeness of the generated text. Finally, we show statistics from our theory are empirically predictive of multiple qualities of the generated dialogue, suggesting our theory is useful for model-selection when human evaluations are not available.
APPDIA: A Discourse-aware Transformer-based Style Transfer Model for Offensive Social Media Conversations
Sep 17, 2022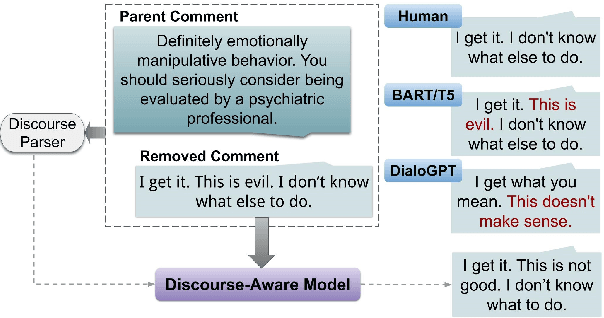
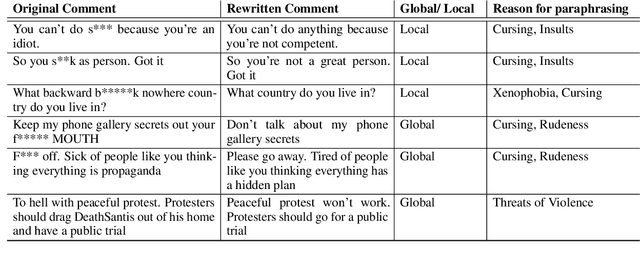
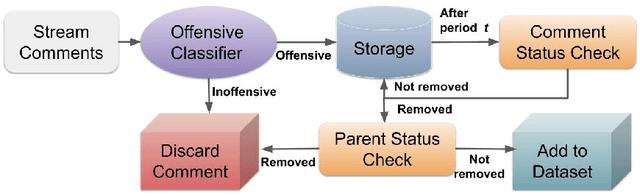
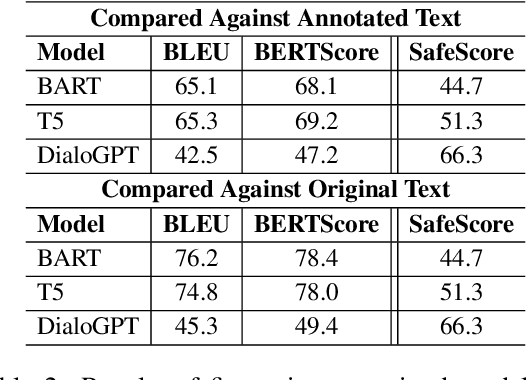
Using style-transfer models to reduce offensiveness of social media comments can help foster a more inclusive environment. However, there are no sizable datasets that contain offensive texts and their inoffensive counterparts, and fine-tuning pretrained models with limited labeled data can lead to the loss of original meaning in the style-transferred text. To address this issue, we provide two major contributions. First, we release the first publicly-available, parallel corpus of offensive Reddit comments and their style-transferred counterparts annotated by expert sociolinguists. Then, we introduce the first discourse-aware style-transfer models that can effectively reduce offensiveness in Reddit text while preserving the meaning of the original text. These models are the first to examine inferential links between the comment and the text it is replying to when transferring the style of offensive Reddit text. We propose two different methods of integrating discourse relations with pretrained transformer models and evaluate them on our dataset of offensive comments from Reddit and their inoffensive counterparts. Improvements over the baseline with respect to both automatic metrics and human evaluation indicate that our discourse-aware models are better at preserving meaning in style-transferred text when compared to the state-of-the-art discourse-agnostic models.
PINEAPPLE: Personifying INanimate Entities by Acquiring Parallel Personification data for Learning Enhanced generation
Sep 16, 2022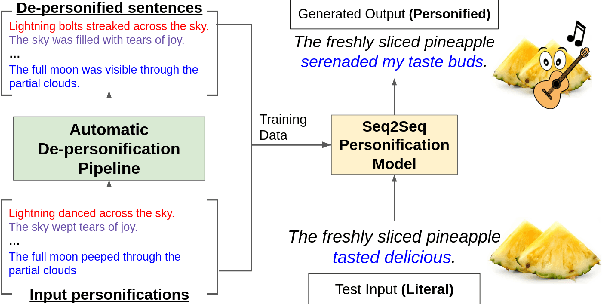
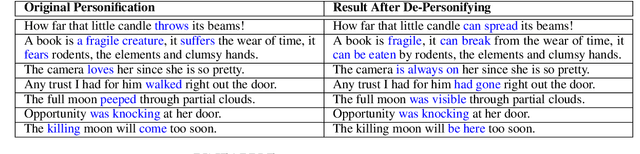
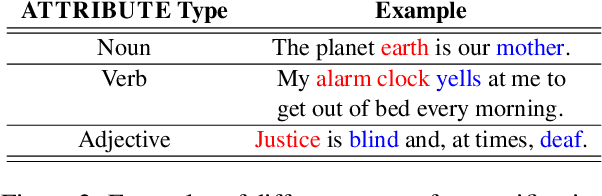
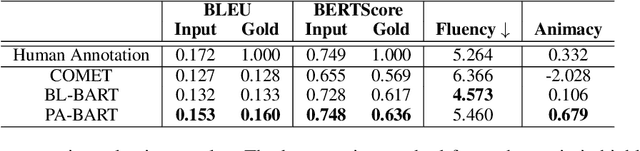
A personification is a figure of speech that endows inanimate entities with properties and actions typically seen as requiring animacy. In this paper, we explore the task of personification generation. To this end, we propose PINEAPPLE: Personifying INanimate Entities by Acquiring Parallel Personification data for Learning Enhanced generation. We curate a corpus of personifications called PersonifCorp, together with automatically generated de-personified literalizations of these personifications. We demonstrate the usefulness of this parallel corpus by training a seq2seq model to personify a given literal input. Both automatic and human evaluations show that fine-tuning with PersonifCorp leads to significant gains in personification-related qualities such as animacy and interestingness. A detailed qualitative analysis also highlights key strengths and imperfections of PINEAPPLE over baselines, demonstrating a strong ability to generate diverse and creative personifications that enhance the overall appeal of a sentence.
Dimensions of Interpersonal Dynamics in Text: Group Membership and Fine-grained Interpersonal Emotion
Sep 14, 2022
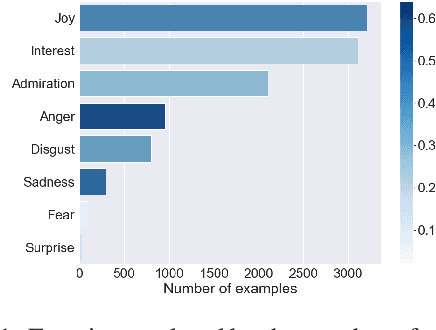
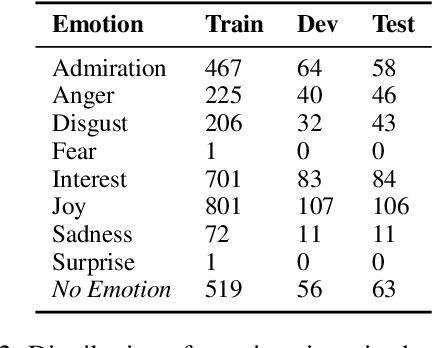
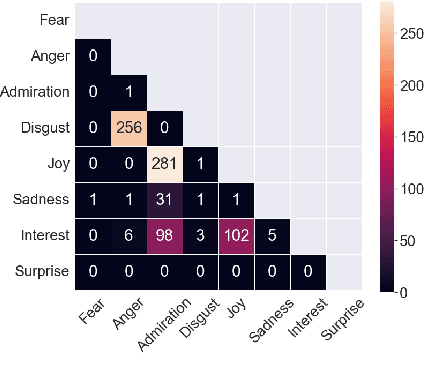
The ability of language to perpetuate inequality is most evident when individuals refer to, or talk about, other individuals in their utterances. While current studies of bias in NLP rely mainly on identifying hate speech or bias towards a specific group, we believe we can reach a more subtle and nuanced understanding of the interaction between bias and language use by modeling the speaker, the text, and the target in the text. In this paper, we introduce a dataset of 3033 English tweets by US Congress members annotated for interpersonal emotion, and `found supervision' for interpersonal group membership labels. We find that negative emotions such as anger and disgust are used predominantly in out-group situations, and directed predominantly at leaders of opposite parties. While humans can perform better than chance at identifying interpersonal group membership given an utterance, neural models perform much better; furthermore, a shared encoding between interpersonal group membership and interpersonal perceived emotion enabled some performance gains in the latter. This work aims to re-align the study of bias in NLP away from specific instances of bias to one which encapsulates the relationship between speaker, text, target and social dynamics. Data and code for this paper are available at https://github.com/venkatasg/Interpersonal-Dynamics