 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient AutoML Pipeline Search with Matrix and Tensor Factorization
Jun 07, 2020

Data scientists seeking a good supervised learning model on a new dataset have many choices to make: they must preprocess the data, select features, possibly reduce the dimension, select an estimation algorithm, and choose hyperparameters for each of these pipeline components. With new pipeline components comes a combinatorial explosion in the number of choices! In this work, we design a new AutoML system to address this challenge: an automated system to design a supervised learning pipeline. Our system uses matrix and tensor factorization as surrogate models to model the combinatorial pipeline search space. Under these models, we develop greedy experiment design protocols to efficiently gather information about a new dataset. Experiments on large corpora of real-world classification problems demonstrate the effectiveness of our approach.
Robust Non-Linear Matrix Factorization for Dictionary Learning, Denoising, and Clustering
May 04, 2020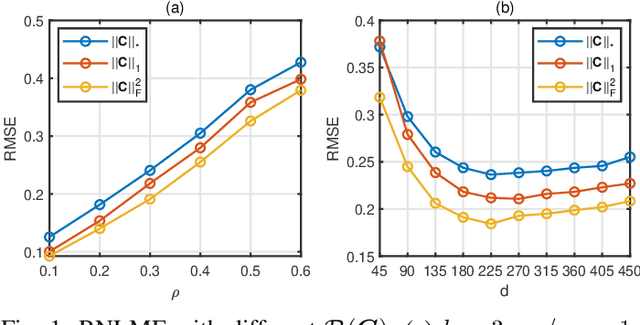
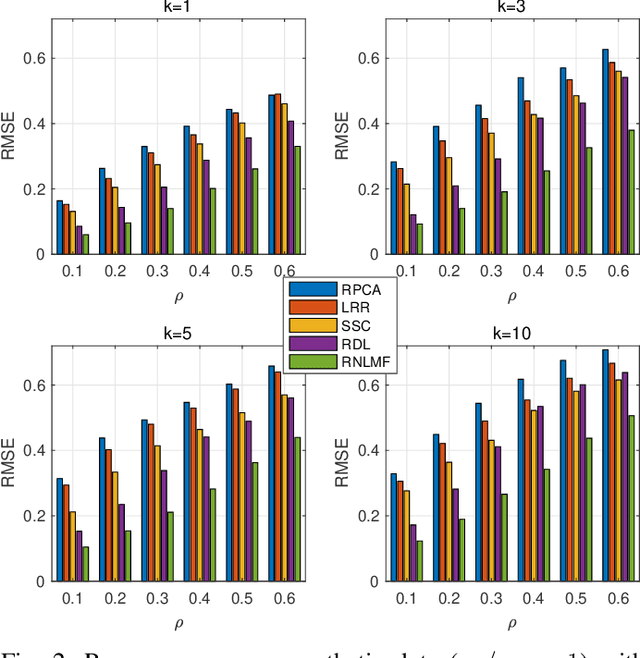
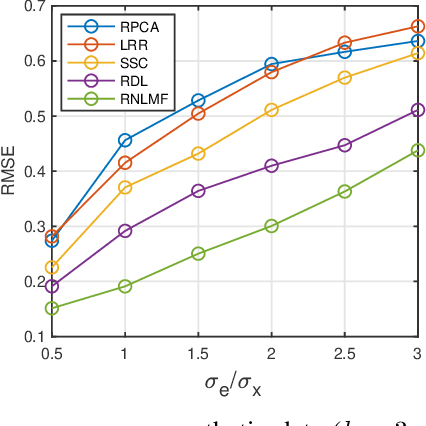
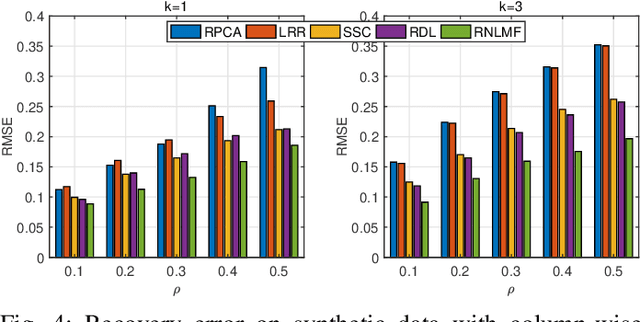
Low dimensional nonlinear structure abounds in datasets across computer vision and machine learning. Kernelized matrix factorization techniques have recently been proposed to learn these nonlinear structures from partially observed data, with impressive empirical performance, by observing that the image of the matrix in a sufficiently large feature space is low-rank. However, these nonlinear methods fail in the presence of noise or outliers. In this work, we propose a new robust nonlinear factorization method called Robust Non-Linear Matrix Factorization (RNLMF). RNLMF constructs a dictionary for the data space by factoring a kernelized feature space; a noisy matrix can then be decomposed as the sum of a sparse noise matrix and a clean data matrix that lies in a low dimensional nonlinear manifold. RNLMF is robust to noise and outliers and scales to matrices with thousands of rows and columns. Empirically, RNLMF achieves noticeable improvements over baseline methods in denoising and clustering.
On the regularity and conditioning of low rank semidefinite programs
Feb 25, 2020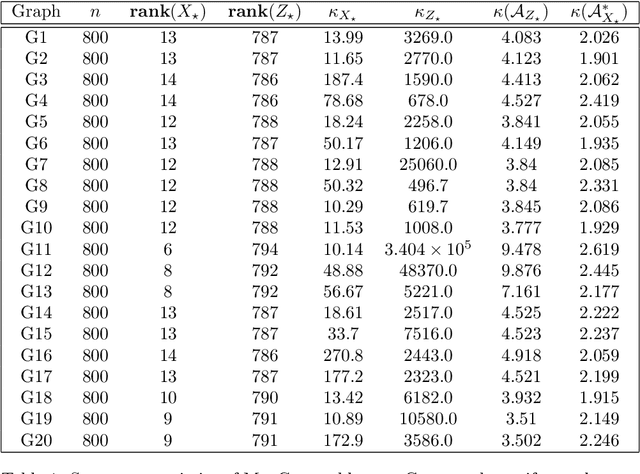
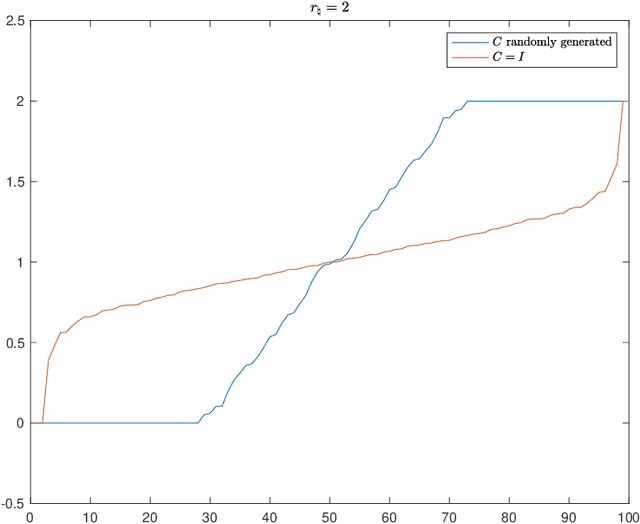
Low rank matrix recovery problems appear widely in statistics, combinatorics, and imaging. One celebrated method for solving these problems is to formulate and solve a semidefinite program (SDP). It is often known that the exact solution to the SDP with perfect data recovers the solution to the original low rank matrix recovery problem. It is more challenging to show that an approximate solution to the SDP formulated with noisy problem data acceptably solves the original problem; arguments are usually ad hoc for each problem setting, and can be complex. In this note, we identify a set of conditions that we call regularity that limit the error due to noisy problem data or incomplete convergence. In this sense, regular SDPs are robust: regular SDPs can be (approximately) solved efficiently at scale; and the resulting approximate solutions, even with noisy data, can be trusted. Moreover, we show that regularity holds generically, and also for many structured low rank matrix recovery problems, including the stochastic block model, $\mathbb{Z}_2$ synchronization, and matrix completion. Formally, we call an SDP regular if it has a surjective constraint map, admits a unique primal and dual solution pair, and satisfies strong duality and strict complementarity. However, regularity is not a panacea: we show the Burer-Monteiro formulation of the SDP may have spurious second-order critical points, even for a regular SDP with a rank 1 solution.
Online high rank matrix completion
Feb 20, 2020
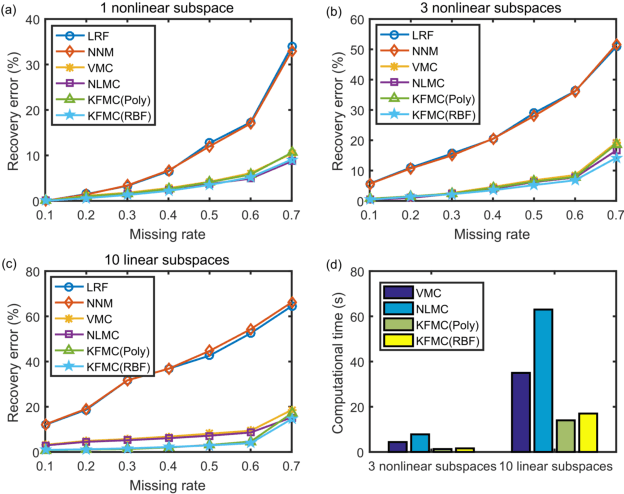
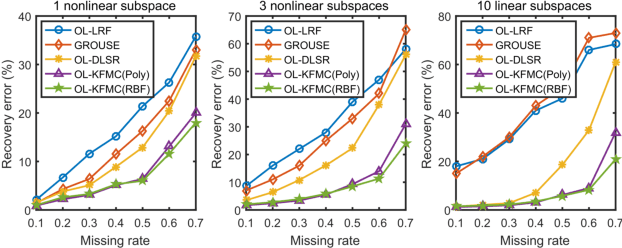
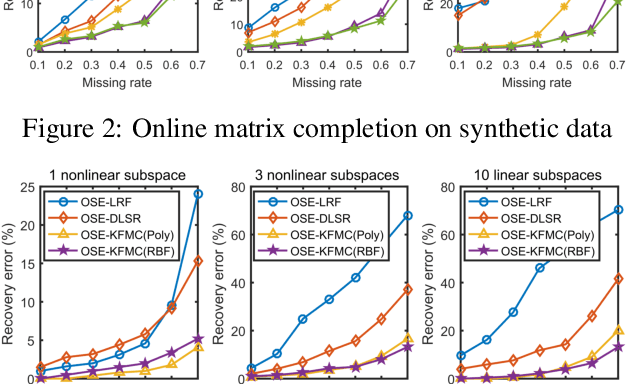
Recent advances in matrix completion enable data imputation in full-rank matrices by exploiting low dimensional (nonlinear) latent structure. In this paper, we develop a new model for high rank matrix completion (HRMC), together with batch and online methods to fit the model and out-of-sample extension to complete new data. The method works by (implicitly) mapping the data into a high dimensional polynomial feature space using the kernel trick; importantly, the data occupies a low dimensional subspace in this feature space, even when the original data matrix is of full-rank. We introduce an explicit parametrization of this low dimensional subspace, and an online fitting procedure, to reduce computational complexity compared to the state of the art. The online method can also handle streaming or sequential data and adapt to non-stationary latent structure. We provide guidance on the sampling rate required these methods to succeed. Experimental results on synthetic data and motion capture data validate the performance of the proposed methods.
Polynomial Matrix Completion for Missing Data Imputation and Transductive Learning
Dec 15, 2019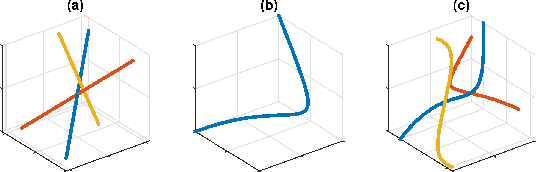
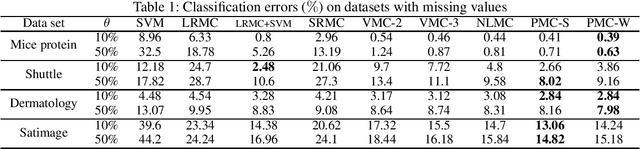
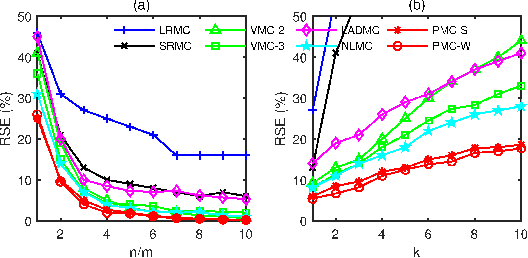
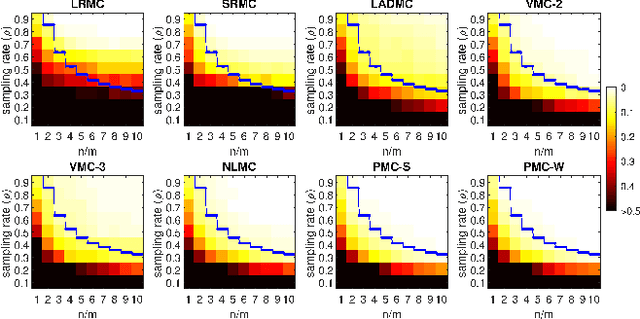
This paper develops new methods to recover the missing entries of a high-rank or even full-rank matrix when the intrinsic dimension of the data is low compared to the ambient dimension. Specifically, we assume that the columns of a matrix are generated by polynomials acting on a low-dimensional intrinsic variable, and wish to recover the missing entries under this assumption. We show that we can identify the complete matrix of minimum intrinsic dimension by minimizing the rank of the matrix in a high dimensional feature space. We develop a new formulation of the resulting problem using the kernel trick together with a new relaxation of the rank objective, and propose an efficient optimization method. We also show how to use our methods to complete data drawn from multiple nonlinear manifolds. Comparative studies on synthetic data, subspace clustering with missing data, motion capture data recovery, and transductive learning verify the superiority of our methods over the state-of-the-art.
Factor Group-Sparse Regularization for Efficient Low-Rank Matrix Recovery
Nov 18, 2019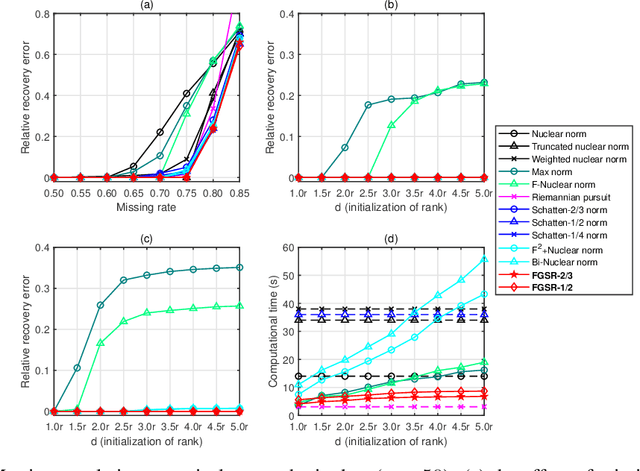
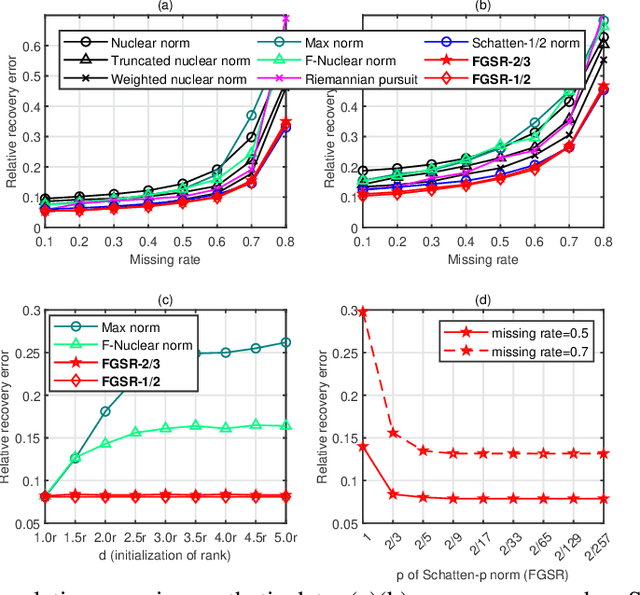
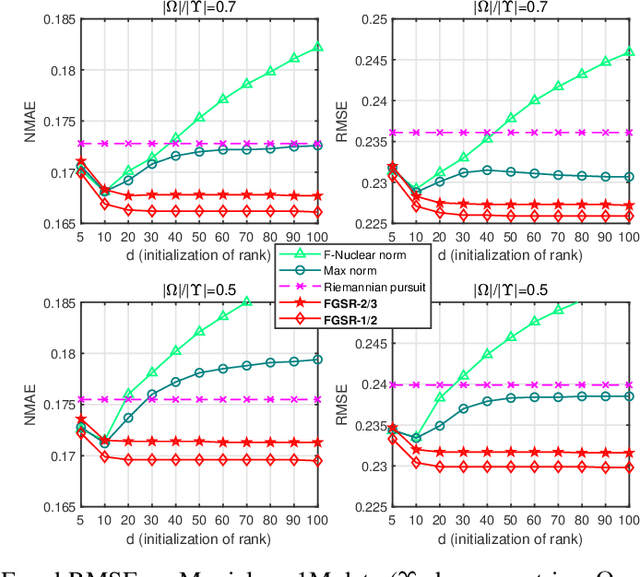
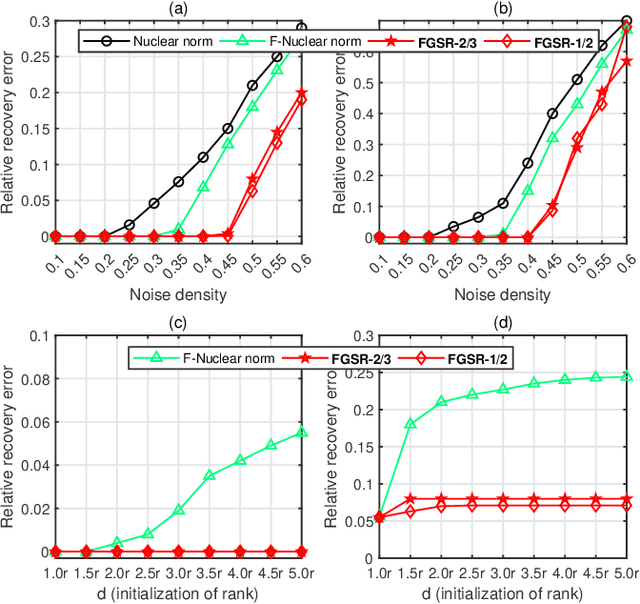
This paper develops a new class of nonconvex regularizers for low-rank matrix recovery. Many regularizers are motivated as convex relaxations of the matrix rank function. Our new factor group-sparse regularizers are motivated as a relaxation of the number of nonzero columns in a factorization of the matrix. These nonconvex regularizers are sharper than the nuclear norm; indeed, we show they are related to Schatten-$p$ norms with arbitrarily small $0 < p \leq 1$. Moreover, these factor group-sparse regularizers can be written in a factored form that enables efficient and effective nonconvex optimization; notably, the method does not use singular value decomposition. We provide generalization error bounds for low-rank matrix completion which show improved upper bounds for Schatten-$p$ norm reglarization as $p$ decreases. Compared to the max norm and the factored formulation of the nuclear norm, factor group-sparse regularizers are more efficient, accurate, and robust to the initial guess of rank. Experiments show promising performance of factor group-sparse regularization for low-rank matrix completion and robust principal component analysis.
AutoML using Metadata Language Embeddings
Oct 08, 2019
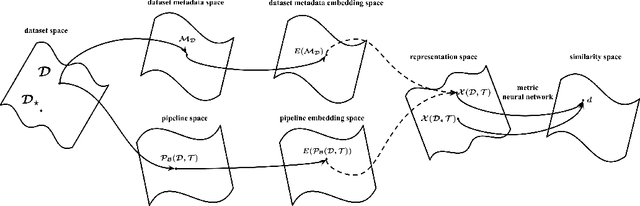
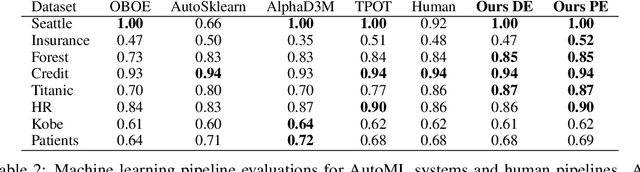
As a human choosing a supervised learning algorithm, it is natural to begin by reading a text description of the dataset and documentation for the algorithms you might use. We demonstrate that the same idea improves the performance of automated machine learning methods. We use language embeddings from modern NLP to improve state-of-the-art AutoML systems by augmenting their recommendations with vector embeddings of datasets and of algorithms. We use these embeddings in a neural architecture to learn the distance between best-performing pipelines. The resulting (meta-)AutoML framework improves on the performance of existing AutoML frameworks. Our zero-shot AutoML system using dataset metadata embeddings provides good solutions instantaneously, running in under one second of computation. Performance is competitive with AutoML systems OBOE, AutoSklearn, AlphaD3M, and TPOT when each framework is allocated a minute of computation. We make our data, models, and code publicly available.
"Why Should You Trust My Explanation?" Understanding Uncertainty in LIME Explanations
Jun 04, 2019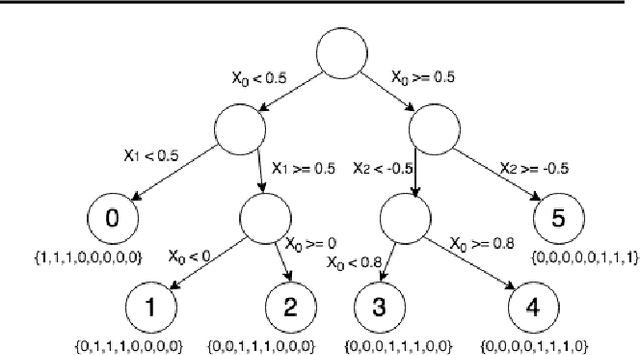
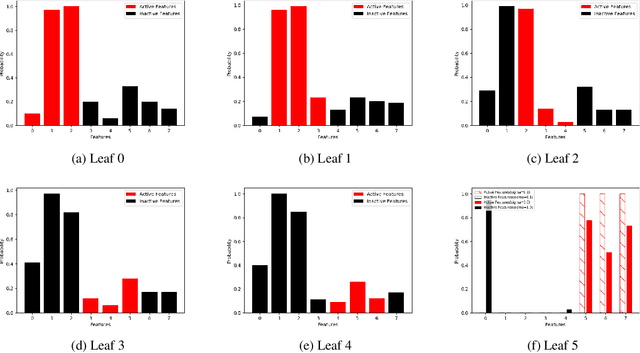
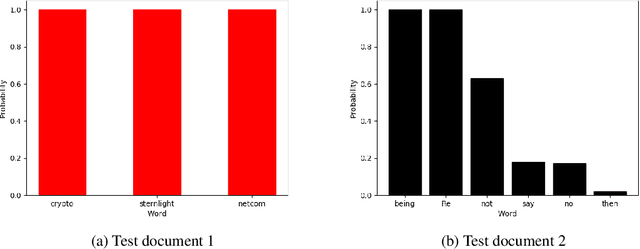
Methods for interpreting machine learning black-box models increase the outcomes' transparency and in turn generates insight into the reliability and fairness of the algorithms. However, the interpretations themselves could contain significant uncertainty that undermines the trust in the outcomes and raises concern about the model's reliability. Focusing on the method "Local Interpretable Model-agnostic Explanations" (LIME), we demonstrate the presence of two sources of uncertainty, namely the randomness in its sampling procedure and the variation of interpretation quality across different input data points. Such uncertainty is present even in models with high training and test accuracy. We apply LIME to synthetic data and two public data sets, text classification in 20 Newsgroup and recidivism risk-scoring in COMPAS, to support our argument.
SysML: The New Frontier of Machine Learning Systems
May 01, 2019Machine learning (ML) techniques are enjoying rapidly increasing adoption. However, designing and implementing the systems that support ML models in real-world deployments remains a significant obstacle, in large part due to the radically different development and deployment profile of modern ML methods, and the range of practical concerns that come with broader adoption. We propose to foster a new systems machine learning research community at the intersection of the traditional systems and ML communities, focused on topics such as hardware systems for ML, software systems for ML, and ML optimized for metrics beyond predictive accuracy. To do this, we describe a new conference, SysML, that explicitly targets research at the intersection of systems and machine learning with a program committee split evenly between experts in systems and ML, and an explicit focus on topics at the intersection of the two.
Low-Rank Tucker Approximation of a Tensor From Streaming Data
Apr 24, 2019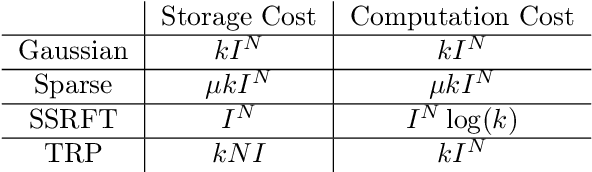
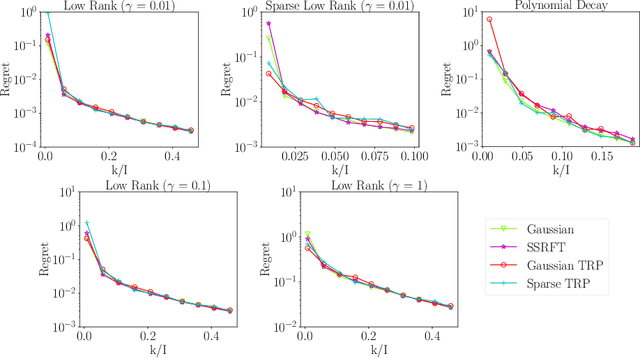
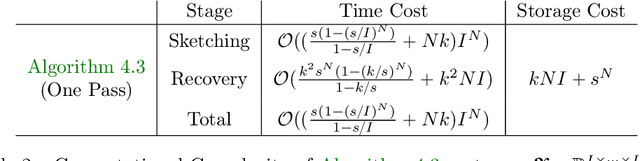
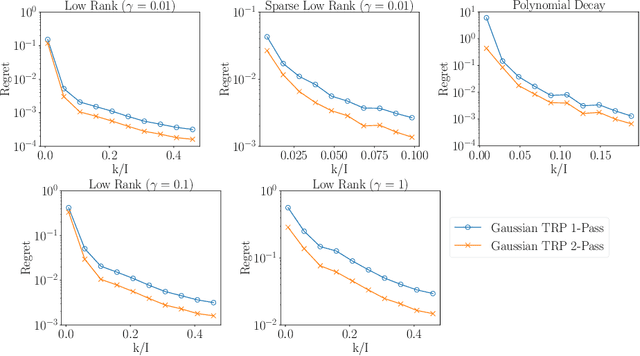
This paper describes a new algorithm for computing a low-Tucker-rank approximation of a tensor. The method applies a randomized linear map to the tensor to obtain a sketch that captures the important directions within each mode, as well as the interactions among the modes. The sketch can be extracted from streaming or distributed data or with a single pass over the tensor, and it uses storage proportional to the degrees of freedom in the output Tucker approximation. The algorithm does not require a second pass over the tensor, although it can exploit another view to compute a superior approximation. The paper provides a rigorous theoretical guarantee on the approximation error. Extensive numerical experiments show that that the algorithm produces useful results that improve on the state of the art for streaming Tucker decomposition.