 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmenters at SemEval-2023 Task 1: Enhancing CLIP in Handling Compositionality and Ambiguity for Zero-Shot Visual WSD through Prompt Augmentation and Text-To-Image Diffusion
Jul 09, 2023



This paper describes our zero-shot approaches for the Visual Word Sense Disambiguation (VWSD) Task in English. Our preliminary study shows that the simple approach of matching candidate images with the phrase using CLIP suffers from the many-to-many nature of image-text pairs. We find that the CLIP text encoder may have limited abilities in capturing the compositionality in natural language. Conversely, the descriptive focus of the phrase varies from instance to instance. We address these issues in our two systems, Augment-CLIP and Stable Diffusion Sampling (SD Sampling). Augment-CLIP augments the text prompt by generating sentences that contain the context phrase with the help of large language models (LLMs). We further explore CLIP models in other languages, as the an ambiguous word may be translated into an unambiguous one in the other language. SD Sampling uses text-to-image Stable Diffusion to generate multiple images from the given phrase, increasing the likelihood that a subset of images match the one that paired with the text.
Cold Diffusion: Inverting Arbitrary Image Transforms Without Noise
Aug 19, 2022



Standard diffusion models involve an image transform -- adding Gaussian noise -- and an image restoration operator that inverts this degradation. We observe that the generative behavior of diffusion models is not strongly dependent on the choice of image degradation, and in fact an entire family of generative models can be constructed by varying this choice. Even when using completely deterministic degradations (e.g., blur, masking, and more), the training and test-time update rules that underlie diffusion models can be easily generalized to create generative models. The success of these fully deterministic models calls into question the community's understanding of diffusion models, which relies on noise in either gradient Langevin dynamics or variational inference, and paves the way for generalized diffusion models that invert arbitrary processes. Our code is available at https://github.com/arpitbansal297/Cold-Diffusion-Models
AutoML using Metadata Language Embeddings
Oct 08, 2019
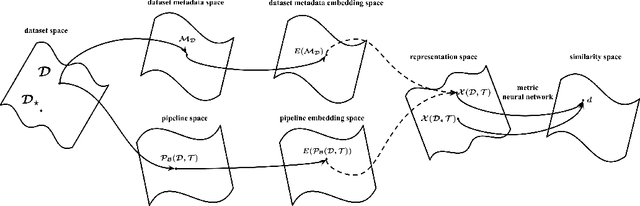
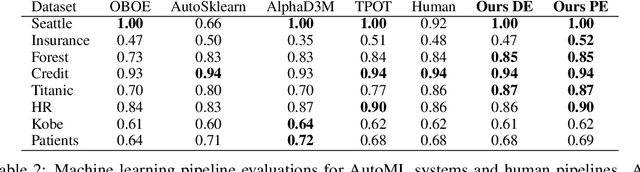
As a human choosing a supervised learning algorithm, it is natural to begin by reading a text description of the dataset and documentation for the algorithms you might use. We demonstrate that the same idea improves the performance of automated machine learning methods. We use language embeddings from modern NLP to improve state-of-the-art AutoML systems by augmenting their recommendations with vector embeddings of datasets and of algorithms. We use these embeddings in a neural architecture to learn the distance between best-performing pipelines. The resulting (meta-)AutoML framework improves on the performance of existing AutoML frameworks. Our zero-shot AutoML system using dataset metadata embeddings provides good solutions instantaneously, running in under one second of computation. Performance is competitive with AutoML systems OBOE, AutoSklearn, AlphaD3M, and TPOT when each framework is allocated a minute of computation. We make our data, models, and code publicly available.