 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLOOM+1: Adding Language Support to BLOOM for Zero-Shot Prompting
Dec 19, 2022



The BLOOM model is a large open-source multilingual language model capable of zero-shot learning, but its pretraining was limited to 46 languages. To improve its zero-shot performance on unseen languages, it is desirable to adapt BLOOM, but previous works have only explored adapting small language models. In this work, we apply existing language adaptation strategies to BLOOM and benchmark its zero-shot prompting performance on eight new languages. We find language adaptation to be effective at improving zero-shot performance in new languages. Surprisingly, adapter-based finetuning is more effective than continued pretraining for large models. In addition, we discover that prompting performance is not significantly affected by language specifics, such as the writing system. It is primarily determined by the size of the language adaptation data. We also add new languages to BLOOMZ, which is a multitask finetuned version of BLOOM capable of following task instructions zero-shot. We find including a new language in the multitask fine-tuning mixture to be the most effective method to teach BLOOMZ a new language. We conclude that with sufficient training data language adaptation can generalize well to diverse languages. Our code is available at \url{https://github.com/bigscience-workshop/multilingual-modeling/}.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
What Language Model to Train if You Have One Million GPU Hours?
Nov 08, 2022



The crystallization of modeling methods around the Transformer architecture has been a boon for practitioners. Simple, well-motivated architectural variations can transfer across tasks and scale, increasing the impact of modeling research. However, with the emergence of state-of-the-art 100B+ parameters models, large language models are increasingly expensive to accurately design and train. Notably, it can be difficult to evaluate how modeling decisions may impact emergent capabilities, given that these capabilities arise mainly from sheer scale alone. In the process of building BLOOM--the Big Science Large Open-science Open-access Multilingual language model--our goal is to identify an architecture and training setup that makes the best use of our 1,000,000 A100-GPU-hours budget. Specifically, we perform an ablation study at the billion-parameter scale comparing different modeling practices and their impact on zero-shot generalization. In addition, we study the impact of various popular pre-training corpora on zero-shot generalization. We also study the performance of a multilingual model and how it compares to the English-only one. Finally, we consider the scaling behaviour of Transformers to choose the target model size, shape, and training setup. All our models and code are open-sourced at https://huggingface.co/bigscience .
Crosslingual Generalization through Multitask Finetuning
Nov 03, 2022Multitask prompted finetuning (MTF) has been shown to help large language models generalize to new tasks in a zero-shot setting, but so far explorations of MTF have focused on English data and models. We apply MTF to the pretrained multilingual BLOOM and mT5 model families to produce finetuned variants called BLOOMZ and mT0. We find finetuning large multilingual language models on English tasks with English prompts allows for task generalization to non-English languages that appear only in the pretraining corpus. Finetuning on multilingual tasks with English prompts further improves performance on English and non-English tasks leading to various state-of-the-art zero-shot results. We also investigate finetuning on multilingual tasks with prompts that have been machine-translated from English to match the language of each dataset. We find training on these machine-translated prompts leads to better performance on human-written prompts in the respective languages. Surprisingly, we find models are capable of zero-shot generalization to tasks in languages they have never intentionally seen. We conjecture that the models are learning higher-level capabilities that are both task- and language-agnostic. In addition, we introduce xP3, a composite of supervised datasets in 46 languages with English and machine-translated prompts. Our code, datasets and models are publicly available at https://github.com/bigscience-workshop/xmtf.
PromptSource: An Integrated Development Environment and Repository for Natural Language Prompts
Feb 02, 2022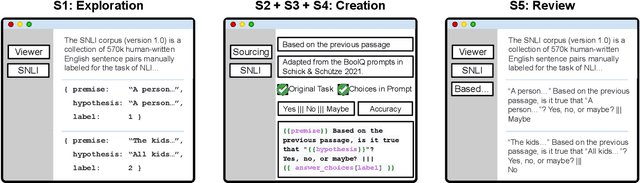
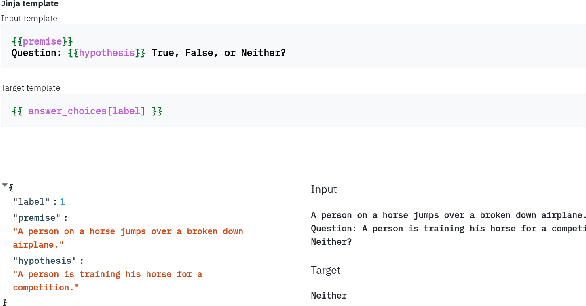

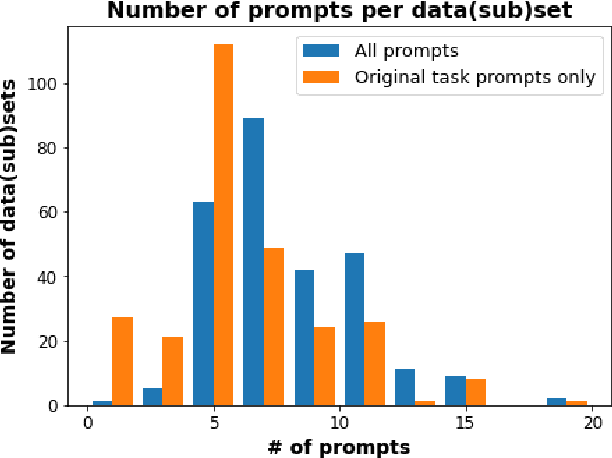
PromptSource is a system for creating, sharing, and using natural language prompts. Prompts are functions that map an example from a dataset to a natural language input and target output. Using prompts to train and query language models is an emerging area in NLP that requires new tools that let users develop and refine these prompts collaboratively. PromptSource addresses the emergent challenges in this new setting with (1) a templating language for defining data-linked prompts, (2) an interface that lets users quickly iterate on prompt development by observing outputs of their prompts on many examples, and (3) a community-driven set of guidelines for contributing new prompts to a common pool. Over 2,000 prompts for roughly 170 datasets are already available in PromptSource. PromptSource is available at https://github.com/bigscience-workshop/promptsource.
Multitask Prompted Training Enables Zero-Shot Task Generalization
Oct 15, 2021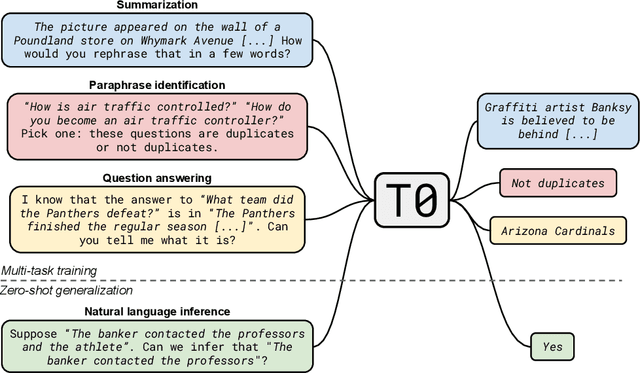

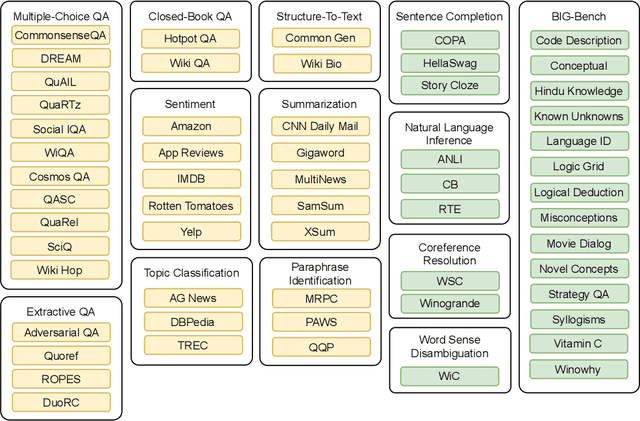

Large language models have recently been shown to attain reasonable zero-shot generalization on a diverse set of tasks. It has been hypothesized that this is a consequence of implicit multitask learning in language model training. Can zero-shot generalization instead be directly induced by explicit multitask learning? To test this question at scale, we develop a system for easily mapping general natural language tasks into a human-readable prompted form. We convert a large set of supervised datasets, each with multiple prompts using varying natural language. These prompted datasets allow for benchmarking the ability of a model to perform completely unseen tasks specified in natural language. We fine-tune a pretrained encoder-decoder model on this multitask mixture covering a wide variety of tasks. The model attains strong zero-shot performance on several standard datasets, often outperforming models 16x its size. Further, our approach attains strong performance on a subset of tasks from the BIG-Bench benchmark, outperforming models 6x its size. All prompts and trained models are available at github.com/bigscience-workshop/promptsource/.
Nearest Neighbour Few-Shot Learning for Cross-lingual Classification
Sep 06, 2021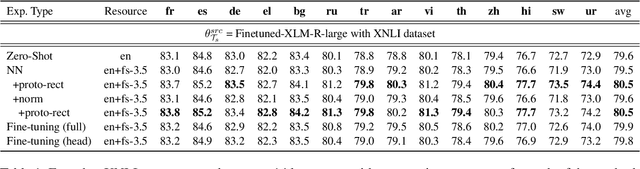
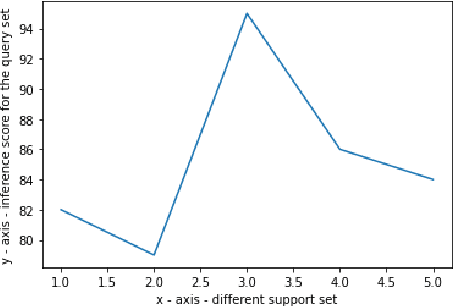
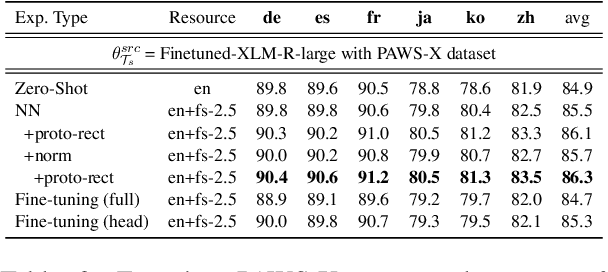
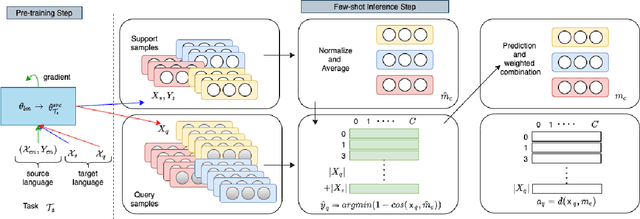
Even though large pre-trained multilingual models (e.g. mBERT, XLM-R) have led to significant performance gains on a wide range of cross-lingual NLP tasks, success on many downstream tasks still relies on the availability of sufficient annotated data. Traditional fine-tuning of pre-trained models using only a few target samples can cause over-fitting. This can be quite limiting as most languages in the world are under-resourced. In this work, we investigate cross-lingual adaptation using a simple nearest neighbor few-shot (<15 samples) inference technique for classification tasks. We experiment using a total of 16 distinct languages across two NLP tasks- XNLI and PAWS-X. Our approach consistently improves traditional fine-tuning using only a handful of labeled samples in target locales. We also demonstrate its generalization capability across tasks.
AUGVIC: Exploiting BiText Vicinity for Low-Resource NMT
Jun 09, 2021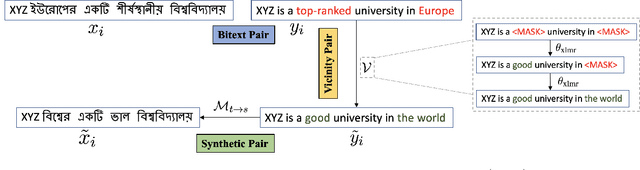

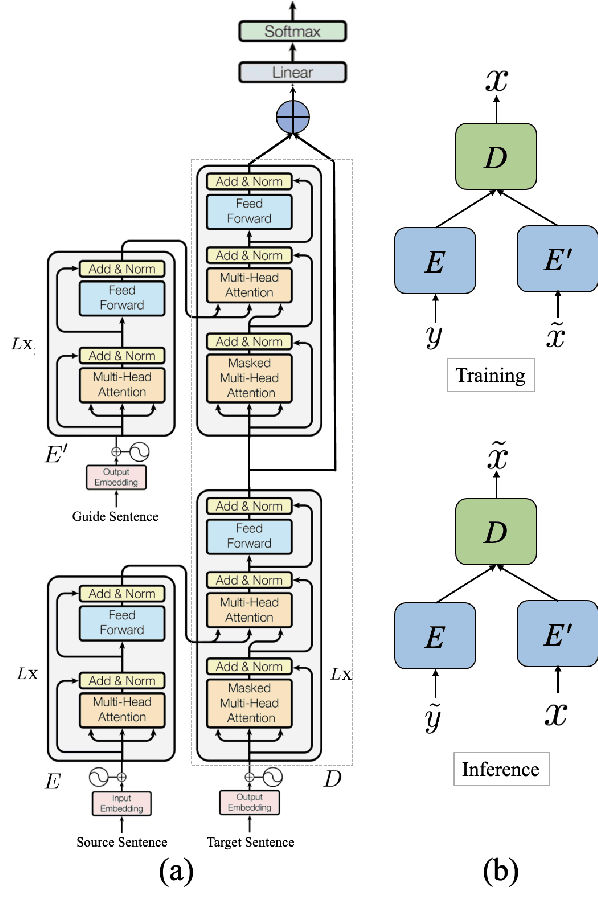
The success of Neural Machine Translation (NMT) largely depends on the availability of large bitext training corpora. Due to the lack of such large corpora in low-resource language pairs, NMT systems often exhibit poor performance. Extra relevant monolingual data often helps, but acquiring it could be quite expensive, especially for low-resource languages. Moreover, domain mismatch between bitext (train/test) and monolingual data might degrade the performance. To alleviate such issues, we propose AUGVIC, a novel data augmentation framework for low-resource NMT which exploits the vicinal samples of the given bitext without using any extra monolingual data explicitly. It can diversify the in-domain bitext data with finer level control. Through extensive experiments on four low-resource language pairs comprising data from different domains, we have shown that our method is comparable to the traditional back-translation that uses extra in-domain monolingual data. When we combine the synthetic parallel data generated from AUGVIC with the ones from the extra monolingual data, we achieve further improvements. We show that AUGVIC helps to attenuate the discrepancies between relevant and distant-domain monolingual data in traditional back-translation. To understand the contributions of different components of AUGVIC, we perform an in-depth framework analysis.
LNMap: Departures from Isomorphic Assumption in Bilingual Lexicon Induction Through Non-Linear Mapping in Latent Space
Apr 28, 2020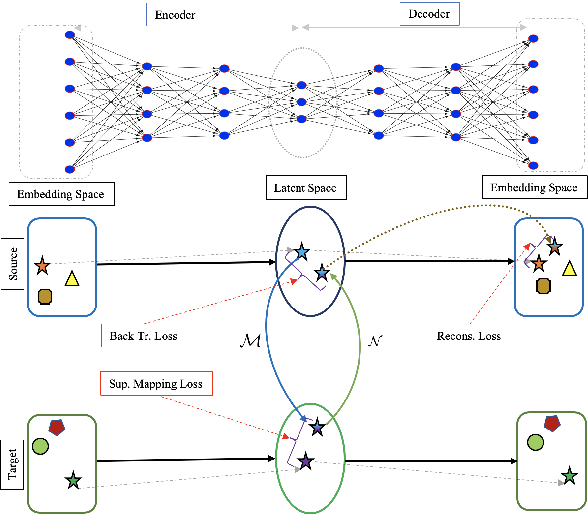
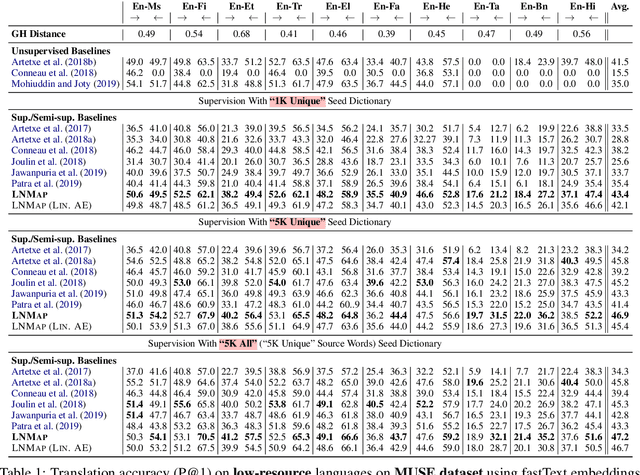
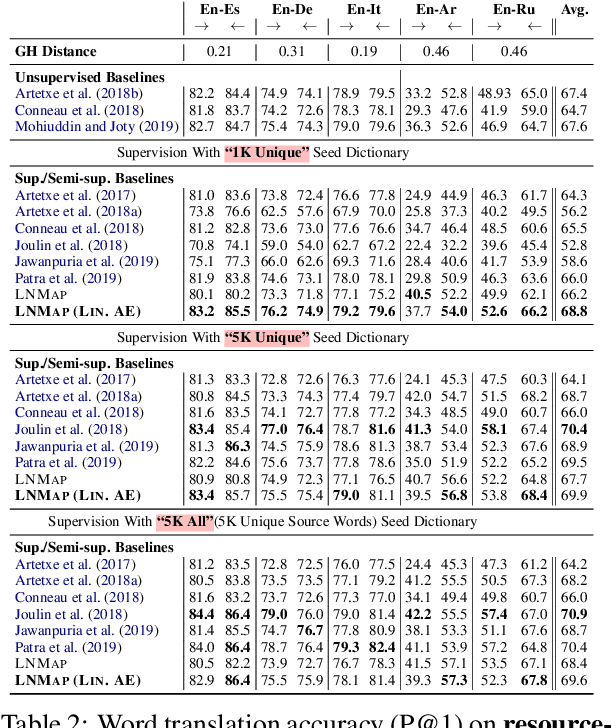
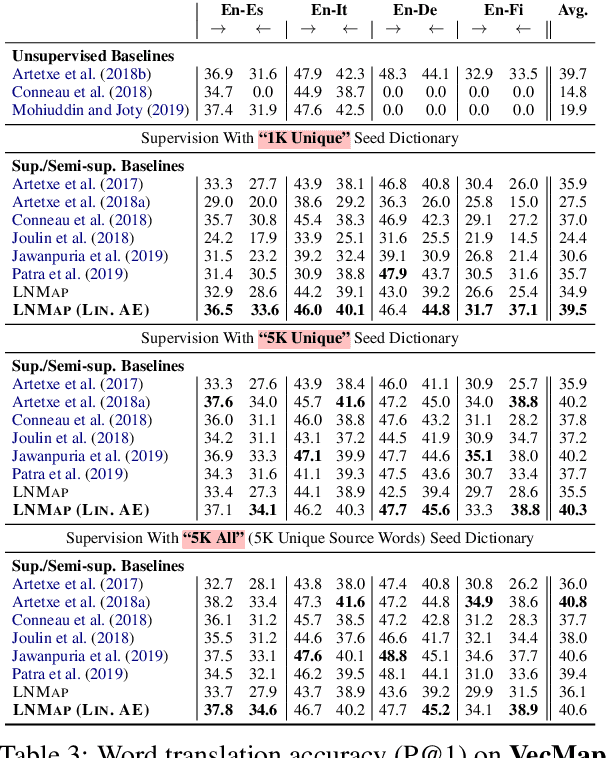
Most of the successful and predominant methods for bilingual lexicon induction (BLI) are mapping-based, where a linear mapping function is learned with the assumption that the word embedding spaces of different languages exhibit similar geometric structures (i.e., approximately isomorphic). However, several recent studies have criticized this simplified assumption showing that it does not hold in general even for closely related languages. In this work, we propose a novel semi-supervised method to learn cross-lingual word embeddings for BLI. Our model is independent of the isomorphic assumption and uses nonlinear mapping in the latent space of two independently trained auto-encoders. Through extensive experiments on fifteen (15) different language pairs (in both directions) comprising resource-rich and low-resource languages from two different datasets, we demonstrate that our method outperforms existing models by a good margin. Ablation studies show the importance of different model components and the necessity of non-linear mapping.
MultiMix: A Robust Data Augmentation Strategy for Cross-Lingual NLP
Apr 28, 2020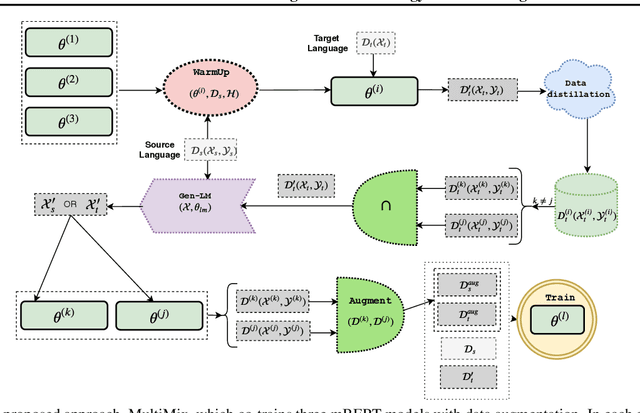
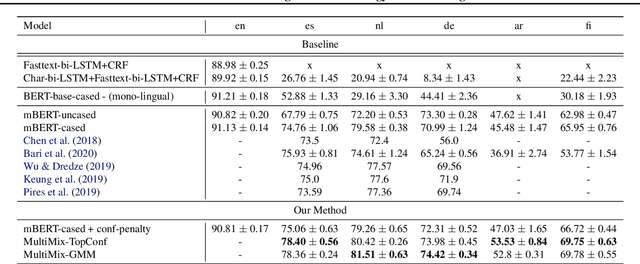
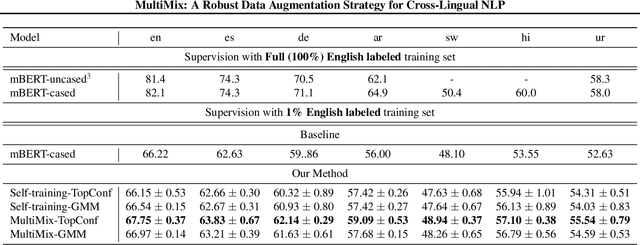
Transfer learning has yielded state-of-the-art results in many supervised natural language processing tasks. However, annotated data for every target task in every target language is rare, especially for low-resource languages. In this work, we propose MultiMix, a novel data augmentation method for semi-supervised learning in zero-shot transfer learning scenarios. In particular, MultiMix targets to solve cross-lingual adaptation problems from a source (language) distribution to an unknown target (language) distribution assuming it has no training labels in the target language task. In its heart, MultiMix performs simultaneous self-training with data augmentation and unsupervised sample selection. To show its effectiveness, we have performed extensive experiments on zero-shot transfers for cross-lingual named entity recognition (XNER) and natural language inference (XNLI). Our experiments show sizeable improvements in both tasks outperforming the baselines by a good margin.