 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Importance of Hyperparameter Optimization for Model-based Reinforcement Learning
Feb 26, 2021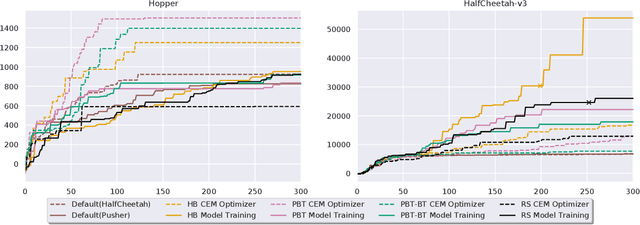
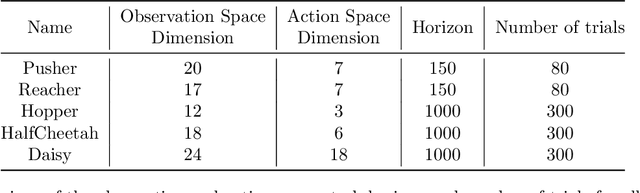
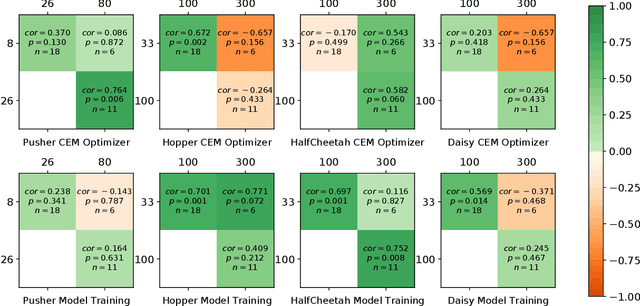
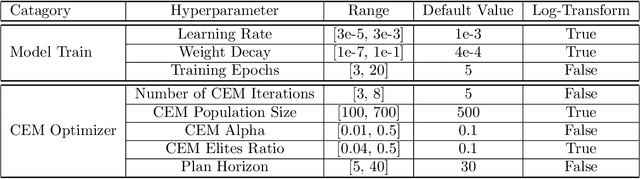
Model-based Reinforcement Learning (MBRL) is a promising framework for learning control in a data-efficient manner. MBRL algorithms can be fairly complex due to the separate dynamics modeling and the subsequent planning algorithm, and as a result, they often possess tens of hyperparameters and architectural choices. For this reason, MBRL typically requires significant human expertise before it can be applied to new problems and domains. To alleviate this problem, we propose to use automatic hyperparameter optimization (HPO). We demonstrate that this problem can be tackled effectively with automated HPO, which we demonstrate to yield significantly improved performance compared to human experts. In addition, we show that tuning of several MBRL hyperparameters dynamically, i.e. during the training itself, further improves the performance compared to using static hyperparameters which are kept fixed for the whole training. Finally, our experiments provide valuable insights into the effects of several hyperparameters, such as plan horizon or learning rate and their influence on the stability of training and resulting rewards.
Active MR k-space Sampling with Reinforcement Learning
Jul 20, 2020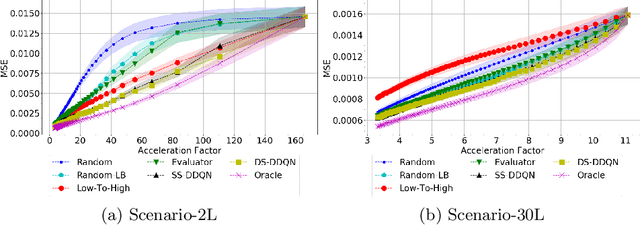
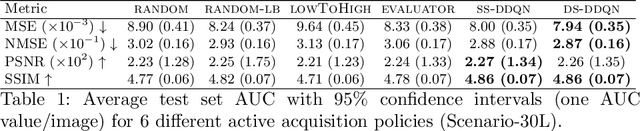
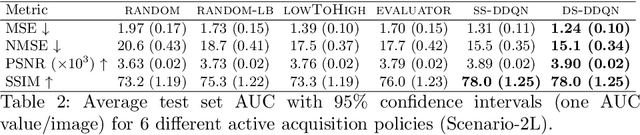
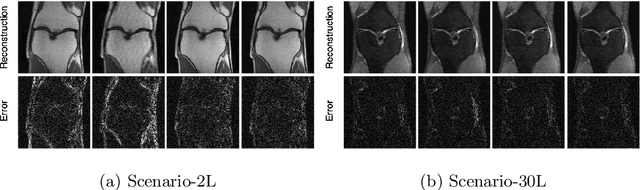
Deep learning approaches have recently shown great promise in accelerating magnetic resonance image (MRI) acquisition. The majority of existing work have focused on designing better reconstruction models given a pre-determined acquisition trajectory, ignoring the question of trajectory optimization. In this paper, we focus on learning acquisition trajectories given a fixed image reconstruction model. We formulate the problem as a sequential decision process and propose the use of reinforcement learning to solve it. Experiments on a large scale public MRI dataset of knees show that our proposed models significantly outperform the state-of-the-art in active MRI acquisition, over a large range of acceleration factors.
On the Evaluation of Conditional GANs
Jul 11, 2019

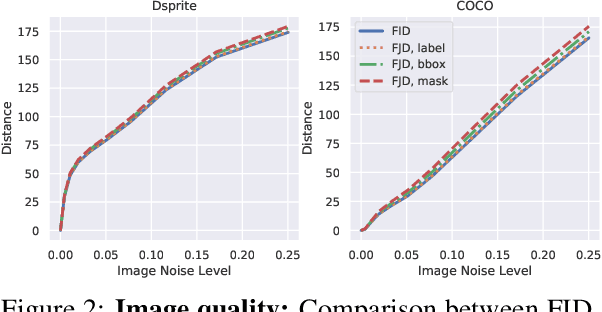
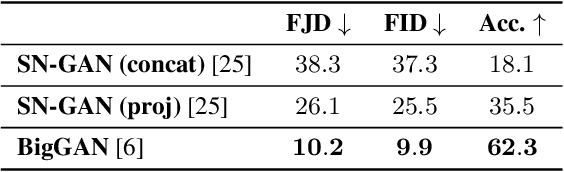
Conditional Generative Adversarial Networks (cGANs) are finding increasingly widespread use in many application domains. Despite outstanding progress, quantitative evaluation of such models often involves multiple distinct metrics to assess different desirable properties such as image quality, intra-conditioning diversity, and conditional consistency, making model benchmarking challenging. In this paper, we propose the Frechet Joint Distance (FJD), which implicitly captures the above mentioned properties in a single metric. FJD is defined as the Frechet Distance of the joint distribution of images and conditionings, making it less sensitive to the often limited per-conditioning sample size. As a result, it scales more gracefully to stronger forms of conditioning such as pixel-wise or multi-modal conditioning. We evaluate FJD on a modified version of the dSprite dataset as well as on the large scale COCO-Stuff dataset, and consistently highlight its benefits when compared to currently established metrics. Moreover, we use the newly introduced metric to compare existing cGAN-based models, with varying conditioning strengths, and show that FJD can be used as a promising single metric for model benchmarking.
Learning Causal State Representations of Partially Observable Environments
Jun 25, 2019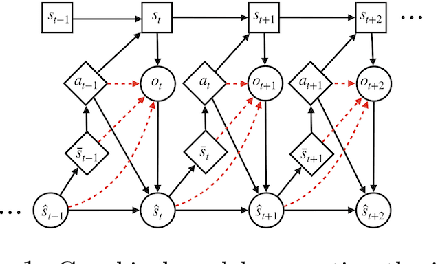
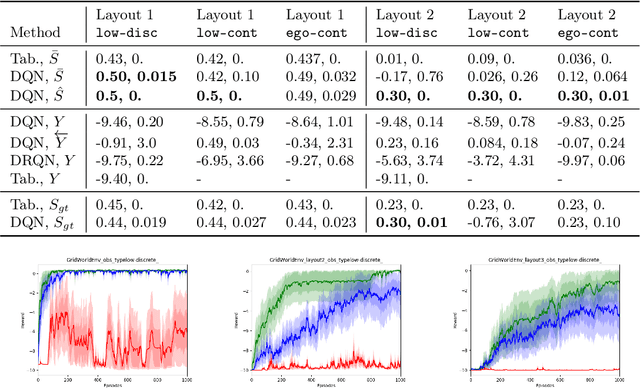

Intelligent agents can cope with sensory-rich environments by learning task-agnostic state abstractions. In this paper, we propose mechanisms to approximate causal states, which optimally compress the joint history of actions and observations in partially-observable Markov decision processes. Our proposed algorithm extracts causal state representations from RNNs that are trained to predict subsequent observations given the history. We demonstrate that these learned task-agnostic state abstractions can be used to efficiently learn policies for reinforcement learning problems with rich observation spaces. We evaluate agents using multiple partially observable navigation tasks with both discrete (GridWorld) and continuous (VizDoom, ALE) observation processes that cannot be solved by traditional memory-limited methods. Our experiments demonstrate systematic improvement of the DQN and tabular models using approximate causal state representations with respect to recurrent-DQN baselines trained with raw inputs.
Elucidating image-to-set prediction: An analysis of models, losses and datasets
Apr 11, 2019
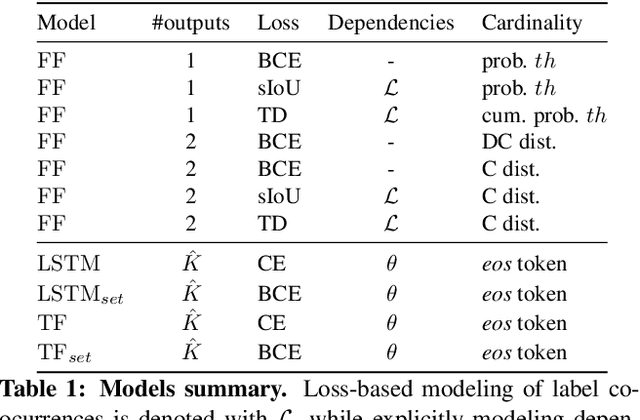
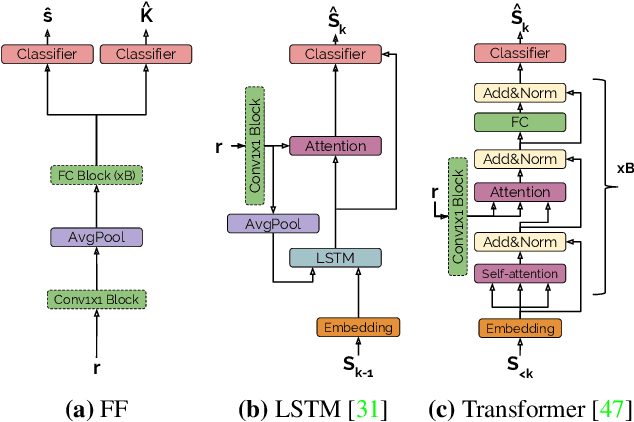
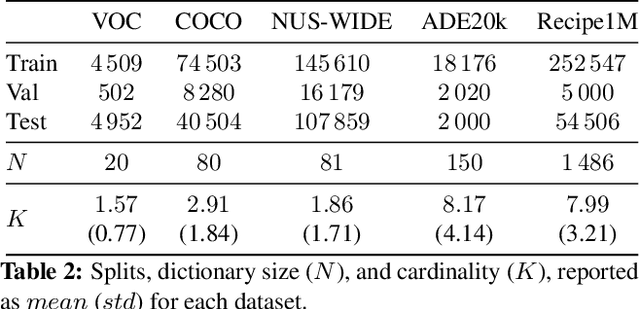
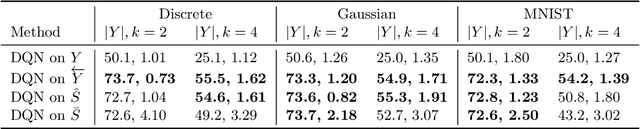
In recent years, we have experienced a flurry of contributions in the multi-label classification literature. This problem has been framed under different perspectives, from predicting independent labels, to modeling label co-occurrences via architectural and/or loss function design. Despite great progress, it is still unclear which modeling choices are best suited to address this task, partially due to the lack of well defined benchmarks. Therefore, in this paper, we provide an in-depth analysis on five different computer vision datasets of increasing task complexity that are suitable for multi-label clasification (VOC, COCO, NUS-WIDE, ADE20k and Recipe1M). Our results show that (1) modeling label co-occurrences and predicting the number of labels that appear in the image is important, especially in high-dimensional output spaces; (2) carefully tuning hyper-parameters for very simple baselines leads to significant improvements, comparable to previously reported results; and (3) as a consequence of our analysis, we achieve state-of-the-art results on 3 datasets for which a fair comparison to previously published methods is feasible.
Planning in Stochastic Environments with Goal Uncertainty
Oct 18, 2018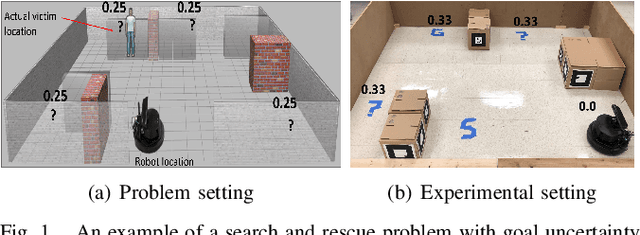

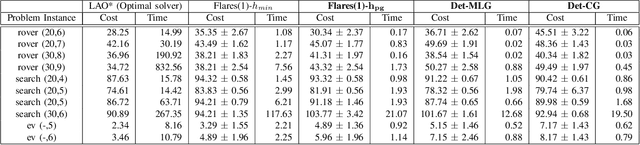
We present the Goal Uncertain Stochastic Shortest Path (GUSSP) problem --- a general framework to model stochastic environments with goal uncertainty. The model is an extension of the stochastic shortest path (SSP) framework to dynamic environments in which it is impossible to determine the exact goal states ahead of plan execution. GUSSPs introduce flexibility in goal specification by allowing a belief over possible goal configurations. The partial observability is restricted to goals, facilitating the reduction to an SSP. We formally define a GUSSP and discuss its theoretical properties. We then propose an admissible heuristic that reduces the planning time of FLARES --- a start-of-the-art probabilistic planner. We also propose a determinization approach for solving this class of problems. Finally, we present empirical results using a mobile robot and three other problem domains.
Generalizing the Role of Determinization in Probabilistic Planning
Jul 29, 2017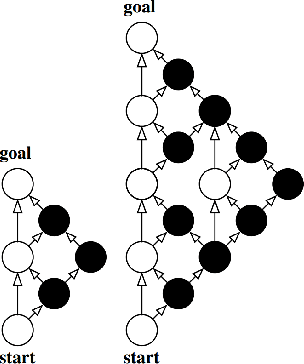
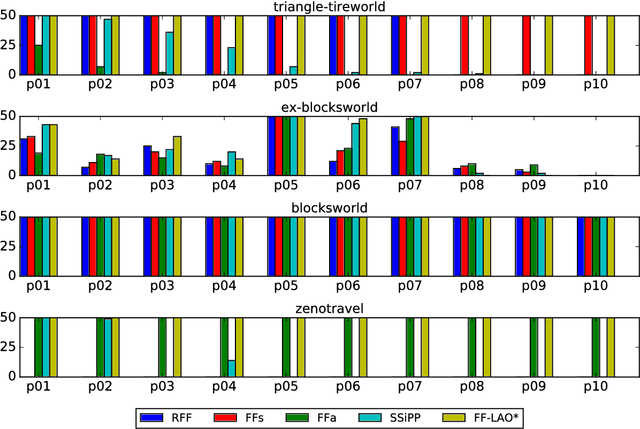
The stochastic shortest path problem (SSP) is a highly expressive model for probabilistic planning. The computational hardness of SSPs has sparked interest in determinization-based planners that can quickly solve large problems. However, existing methods employ a simplistic approach to determinization. In particular, they ignore the possibility of tailoring the determinization to the specific characteristics of the target domain. In this work we examine this question, by showing that learning a good determinization for a planning domain can be done efficiently and can improve performance. Moreover, we show how to directly incorporate probabilistic reasoning into the planning problem when a good determinization is not sufficient by itself. Based on these insights, we introduce a planner, FF-LAO*, that outperforms state-of-the-art probabilistic planners on several well-known competition benchmarks.