 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrivePTS: A Progressive Learning Framework with Textual and Structural Enhancement for Driving Scene Generation
Feb 26, 2026Synthesis of diverse driving scenes serves as a crucial data augmentation technique for validating the robustness and generalizability of autonomous driving systems. Current methods aggregate high-definition (HD) maps and 3D bounding boxes as geometric conditions in diffusion models for conditional scene generation. However, implicit inter-condition dependency causes generation failures when control conditions change independently. Additionally, these methods suffer from insufficient details in both semantic and structural aspects. Specifically, brief and view-invariant captions restrict semantic contexts, resulting in weak background modeling. Meanwhile, the standard denoising loss with uniform spatial weighting neglects foreground structural details, causing visual distortions and blurriness. To address these challenges, we propose DrivePTS, which incorporates three key innovations. Firstly, our framework adopts a progressive learning strategy to mitigate inter-dependency between geometric conditions, reinforced by an explicit mutual information constraint. Secondly, a Vision-Language Model is utilized to generate multi-view hierarchical descriptions across six semantic aspects, providing fine-grained textual guidance. Thirdly, a frequency-guided structure loss is introduced to strengthen the model's sensitivity to high-frequency elements, improving foreground structural fidelity. Extensive experiments demonstrate that our DrivePTS achieves state-of-the-art fidelity and controllability in generating diverse driving scenes. Notably, DrivePTS successfully generates rare scenes where prior methods fail, highlighting its strong generalization ability.
UniInst: Unique Representation for End-to-End Instance Segmentation
May 26, 2022

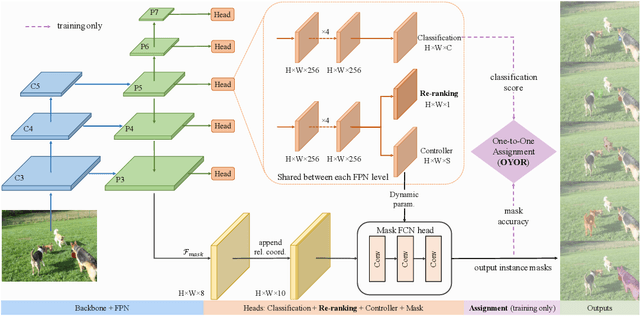

Existing instance segmentation methods have achieved impressive performance but still suffer from a common dilemma: redundant representations (e.g., multiple boxes, grids, and anchor points) are inferred for one instance, which leads to multiple duplicated predictions. Thus, mainstream methods usually rely on a hand-designed non-maximum suppression (NMS) post-processing step to select the optimal prediction result, which hinders end-to-end training. To address this issue, we propose a box-free and NMS-free end-to-end instance segmentation framework, termed UniInst, that yields only one unique representation for each instance. Specifically, we design an instance-aware one-to-one assignment scheme, namely Only Yield One Representation (OYOR), which dynamically assigns one unique representation to each instance according to the matching quality between predictions and ground truths. Then, a novel prediction re-ranking strategy is elegantly integrated into the framework to address the misalignment between the classification score and the mask quality, enabling the learned representation to be more discriminative. With these techniques, our UniInst, the first FCN-based end-to-end instance segmentation framework, achieves competitive performance, e.g., 39.0 mask AP using ResNet-50-FPN and 40.2 mask AP using ResNet-101-FPN, against mainstream methods on COCO test-dev. Moreover, the proposed instance-aware method is robust to occlusion scenes, outperforming common baselines by remarkable mask AP on the heavily-occluded OCHuman benchmark. Our codes will be available upon publication.
Implicit Feature Refinement for Instance Segmentation
Dec 09, 2021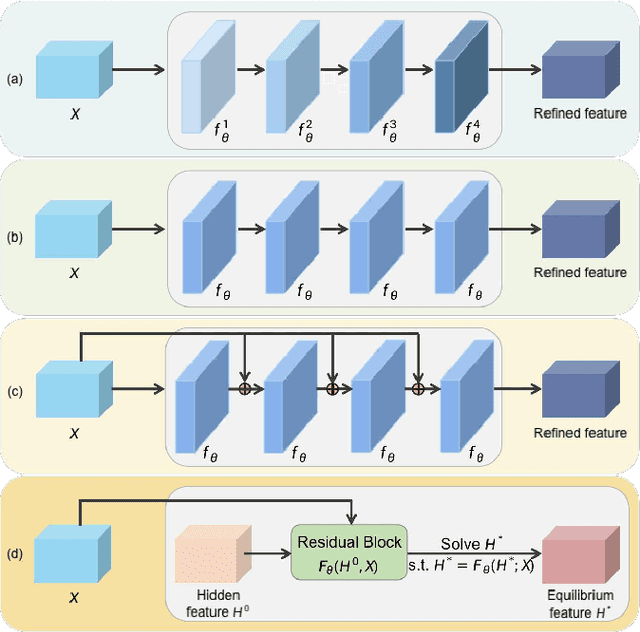

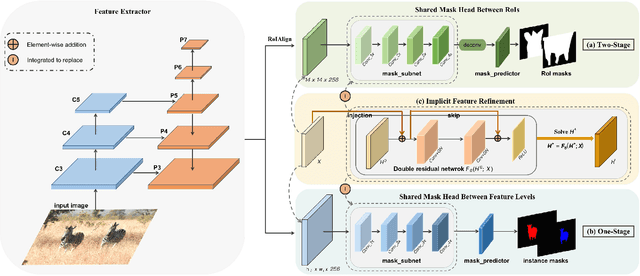
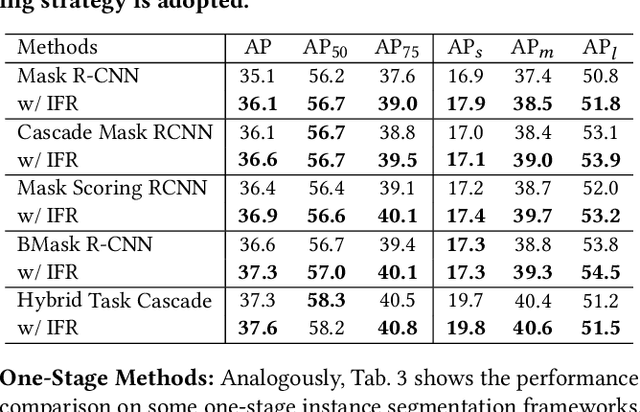
We propose a novel implicit feature refinement module for high-quality instance segmentation. Existing image/video instance segmentation methods rely on explicitly stacked convolutions to refine instance features before the final prediction. In this paper, we first give an empirical comparison of different refinement strategies,which reveals that the widely-used four consecutive convolutions are not necessary. As an alternative, weight-sharing convolution blocks provides competitive performance. When such block is iterated for infinite times, the block output will eventually convergeto an equilibrium state. Based on this observation, the implicit feature refinement (IFR) is developed by constructing an implicit function. The equilibrium state of instance features can be obtained by fixed-point iteration via a simulated infinite-depth network. Our IFR enjoys several advantages: 1) simulates an infinite-depth refinement network while only requiring parameters of single residual block; 2) produces high-level equilibrium instance features of global receptive field; 3) serves as a plug-and-play general module easily extended to most object recognition frameworks. Experiments on the COCO and YouTube-VIS benchmarks show that our IFR achieves improved performance on state-of-the-art image/video instance segmentation frameworks, while reducing the parameter burden (e.g.1% AP improvement on Mask R-CNN with only 30.0% parameters in mask head). Code is made available at https://github.com/lufanma/IFR.git