 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Robustness and Transferability of Convolutional Neural Networks
Jul 16, 2020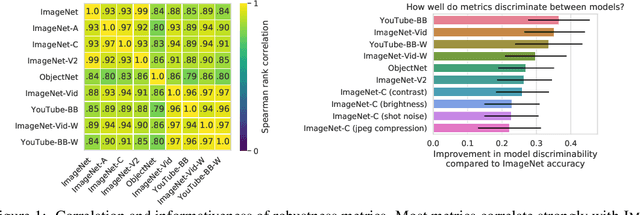

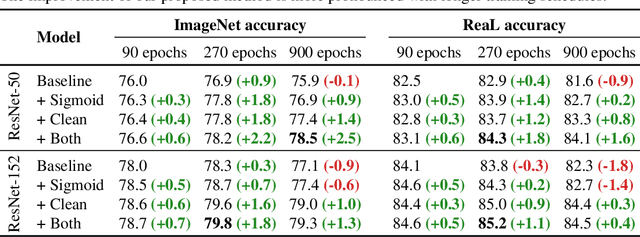
Modern deep convolutional networks (CNNs) are often criticized for not generalizing under distributional shifts. However, several recent breakthroughs in transfer learning suggest that these networks can cope with severe distribution shifts and successfully adapt to new tasks from a few training examples. In this work we revisit the out-of-distribution and transfer performance of modern image classification CNNs and investigate the impact of the pre-training data size, the model scale, and the data preprocessing pipeline. We find that increasing both the training set and model sizes significantly improve the distributional shift robustness. Furthermore, we show that, perhaps surprisingly, simple changes in the preprocessing such as modifying the image resolution can significantly mitigate robustness issues in some cases. Finally, we outline the shortcomings of existing robustness evaluation datasets and introduce a synthetic dataset we use for a systematic analysis across common factors of variation. \end{abstract}
Are we done with ImageNet?
Jun 12, 2020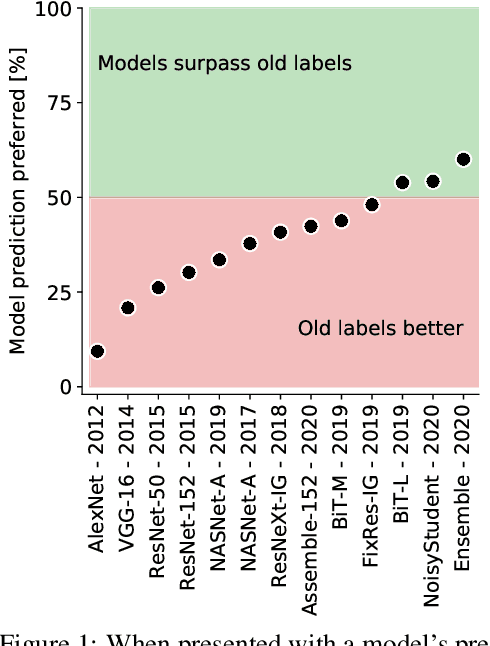
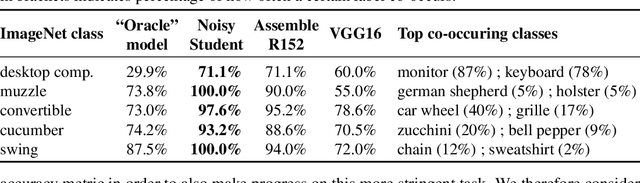
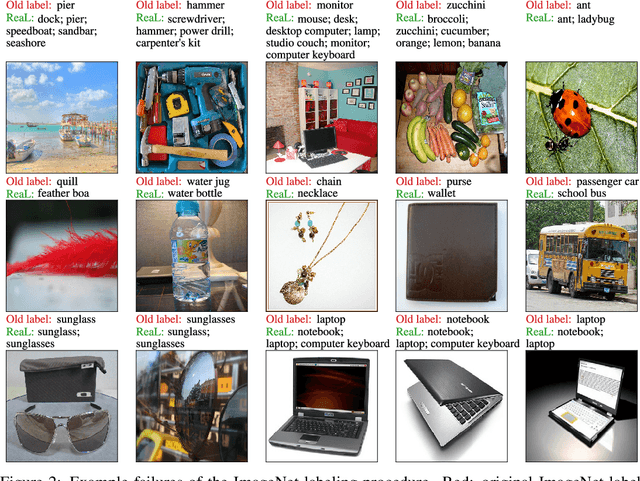
Yes, and no. We ask whether recent progress on the ImageNet classification benchmark continues to represent meaningful generalization, or whether the community has started to overfit to the idiosyncrasies of its labeling procedure. We therefore develop a significantly more robust procedure for collecting human annotations of the ImageNet validation set. Using these new labels, we reassess the accuracy of recently proposed ImageNet classifiers, and find their gains to be substantially smaller than those reported on the original labels. Furthermore, we find the original ImageNet labels to no longer be the best predictors of this independently-collected set, indicating that their usefulness in evaluating vision models may be nearing an end. Nevertheless, we find our annotation procedure to have largely remedied the errors in the original labels, reinforcing ImageNet as a powerful benchmark for future research in visual recognition.
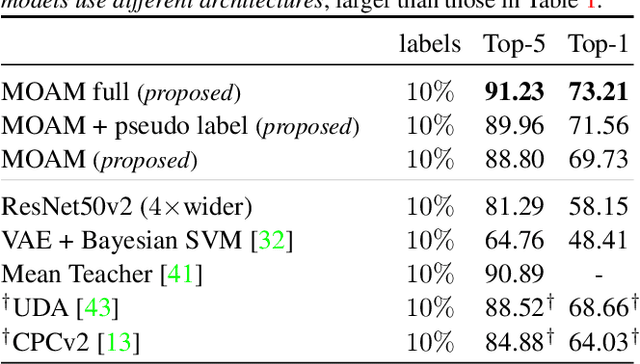
Large Scale Learning of General Visual Representations for Transfer
Dec 24, 2019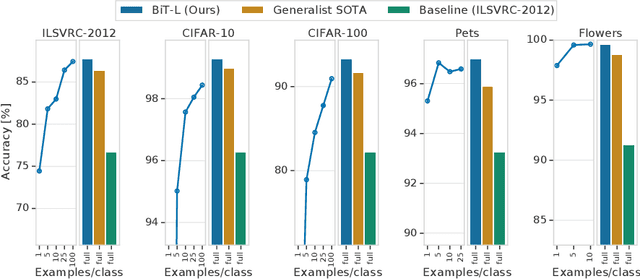

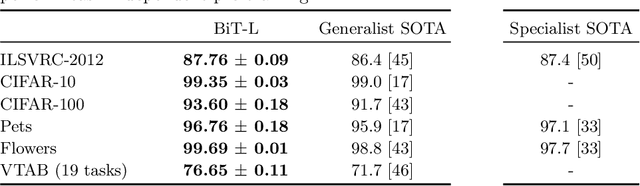
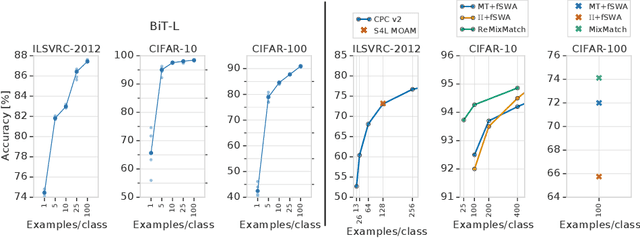
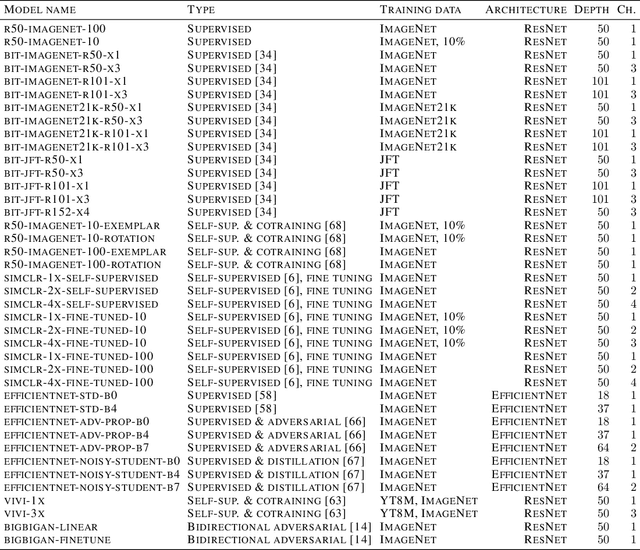
Transfer of pre-trained representations improves sample efficiency and simplifies hyperparameter tuning when training deep neural networks for vision. We revisit the paradigm of pre-training on large supervised datasets and fine-tuning the weights on the target task. We scale up pre-training, and create a simple recipe that we call Big Transfer (BiT). By combining a few carefully selected components, and transferring using a simple heuristic, we achieve strong performance on over 20 datasets. BiT performs well across a surprisingly wide range of data regimes - from 10 to 1M labeled examples. BiT achieves 87.8% top-1 accuracy on ILSVRC-2012, 99.3% on CIFAR-10, and 76.7% on the Visual Task Adaptation Benchmark (which includes 19 tasks). On small datasets, BiT attains 86.4% on ILSVRC-2012 with 25 examples per class, and 97.6% on CIFAR-10 with 10 examples per class. We conduct detailed analysis of the main components that lead to high transfer performance.
The Visual Task Adaptation Benchmark
Oct 01, 2019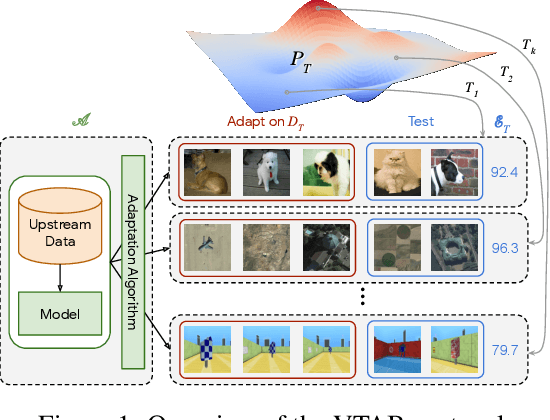
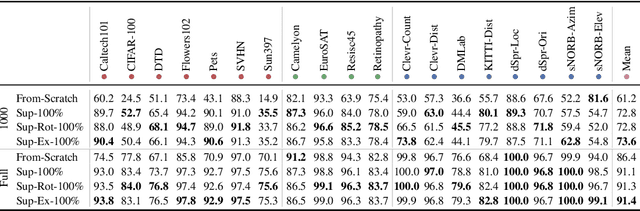
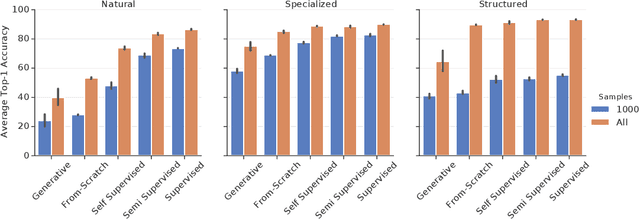
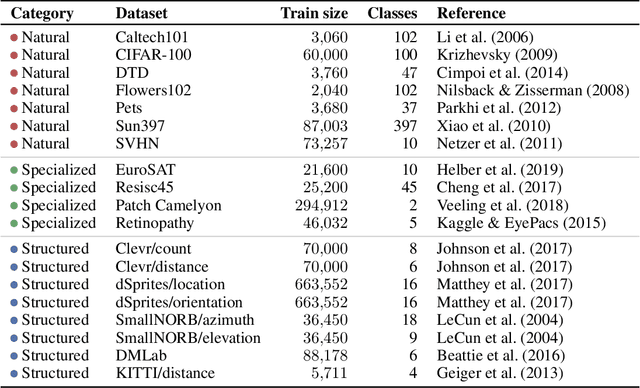
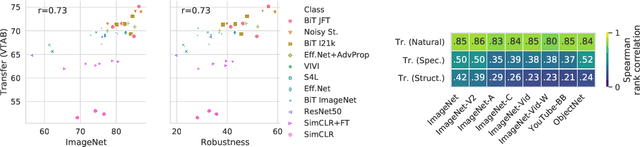
Representation learning promises to unlock deep learning for the long tail of vision tasks without expansive labelled datasets. Yet, the absence of a unified yardstick to evaluate general visual representations hinders progress. Many sub-fields promise representations, but each has different evaluation protocols that are either too constrained (linear classification), limited in scope (ImageNet, CIFAR, Pascal-VOC), or only loosely related to representation quality (generation). We present the Visual Task Adaptation Benchmark (VTAB): a diverse, realistic, and challenging benchmark to evaluate representations. VTAB embodies one principle: good representations adapt to unseen tasks with few examples. We run a large VTAB study of popular algorithms, answering questions like: How effective are ImageNet representation on non-standard datasets? Are generative models competitive? Is self-supervision useful if one already has labels?
MULEX: Disentangling Exploitation from Exploration in Deep RL
Jul 01, 2019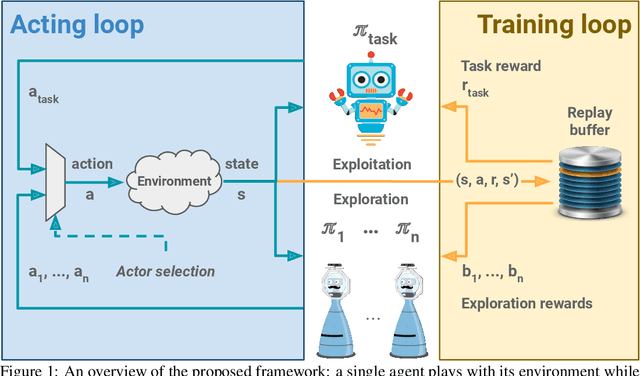
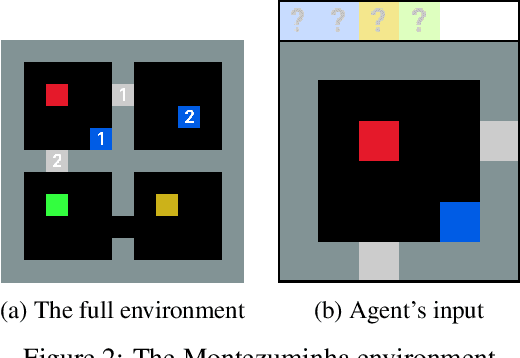
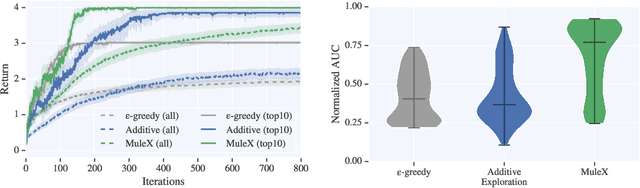
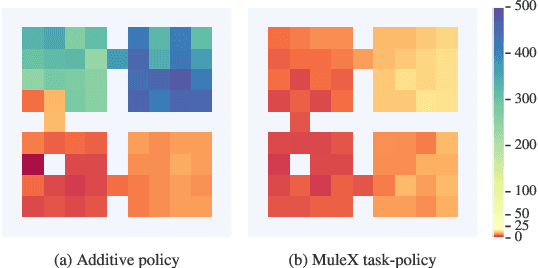
An agent learning through interactions should balance its action selection process between probing the environment to discover new rewards and using the information acquired in the past to adopt useful behaviour. This trade-off is usually obtained by perturbing either the agent's actions (e.g., e-greedy or Gibbs sampling) or the agent's parameters (e.g., NoisyNet), or by modifying the reward it receives (e.g., exploration bonus, intrinsic motivation, or hand-shaped rewards). Here, we adopt a disruptive but simple and generic perspective, where we explicitly disentangle exploration and exploitation. Different losses are optimized in parallel, one of them coming from the true objective (maximizing cumulative rewards from the environment) and others being related to exploration. Every loss is used in turn to learn a policy that generates transitions, all shared in a single replay buffer. Off-policy methods are then applied to these transitions to optimize each loss. We showcase our approach on a hard-exploration environment, show its sample-efficiency and robustness, and discuss further implications.
Deep multi-class learning from label proportions
May 30, 2019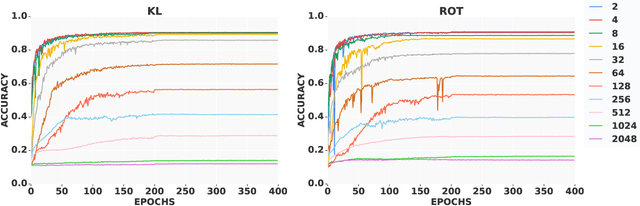
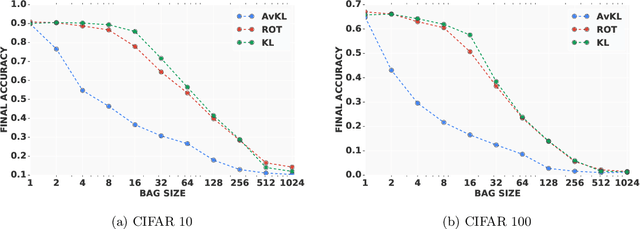
We propose a learning algorithm capable of learning from label proportions instead of direct data labels. In this scenario, our data are arranged into various bags of a certain size, and only the proportions of each label within a given bag are known. This is a common situation in cases where per-data labeling is lengthy, but a more general label is easily accessible. Several approaches have been proposed to learn in this setting with linear models in the multiclass setting, or with nonlinear models in the binary classification setting. Here we investigate the more general nonlinear multiclass setting, and compare two differentiable loss functions to train end-to-end deep neural networks from bags with label proportions. We illustrate the relevance of our methods on an image classification benchmark, and demonstrate the possibility to learn accurate image classifiers from bags of images.
S$^\mathbf{4}$L: Self-Supervised Semi-Supervised Learning
May 09, 2019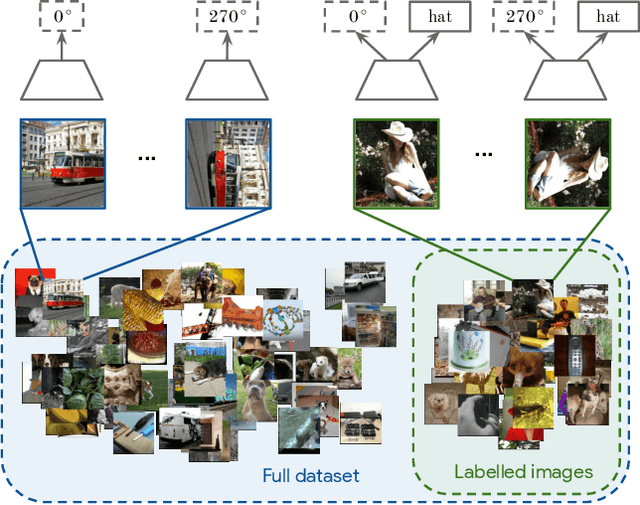
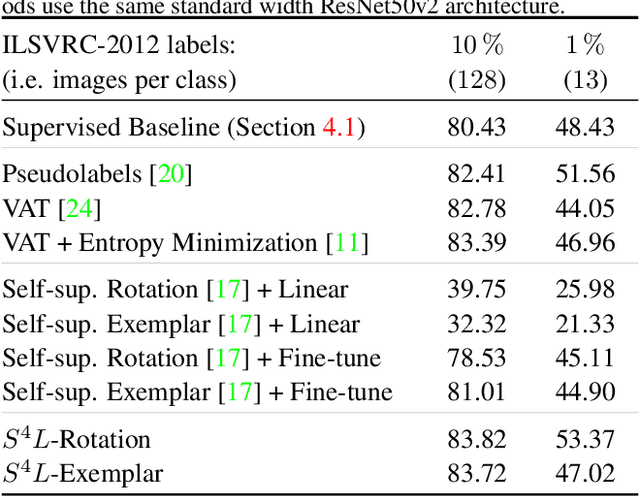
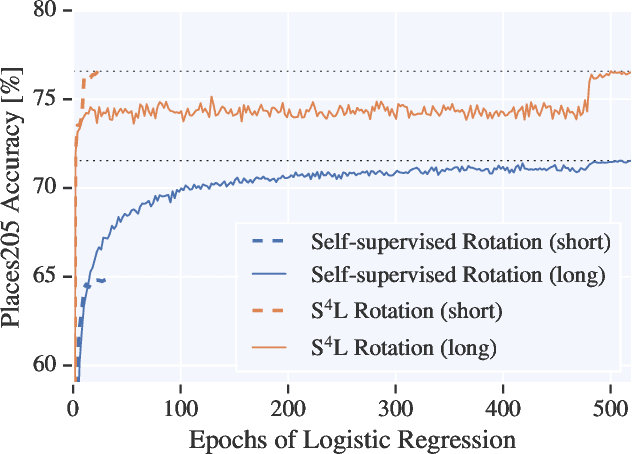
This work tackles the problem of semi-supervised learning of image classifiers. Our main insight is that the field of semi-supervised learning can benefit from the quickly advancing field of self-supervised visual representation learning. Unifying these two approaches, we propose the framework of self-supervised semi-supervised learning ($S^4L$) and use it to derive two novel semi-supervised image classification methods. We demonstrate the effectiveness of these methods in comparison to both carefully tuned baselines, and existing semi-supervised learning methods. We then show that $S^4L$ and existing semi-supervised methods can be jointly trained, yielding a new state-of-the-art result on semi-supervised ILSVRC-2012 with 10% of labels.
Revisiting Self-Supervised Visual Representation Learning
Jan 25, 2019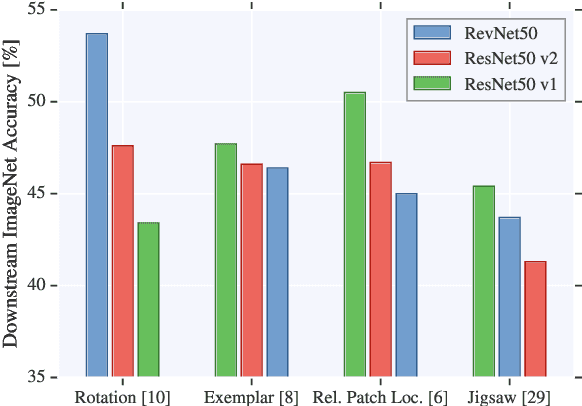
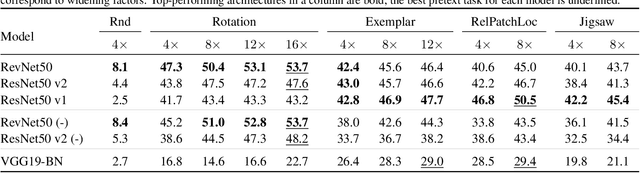
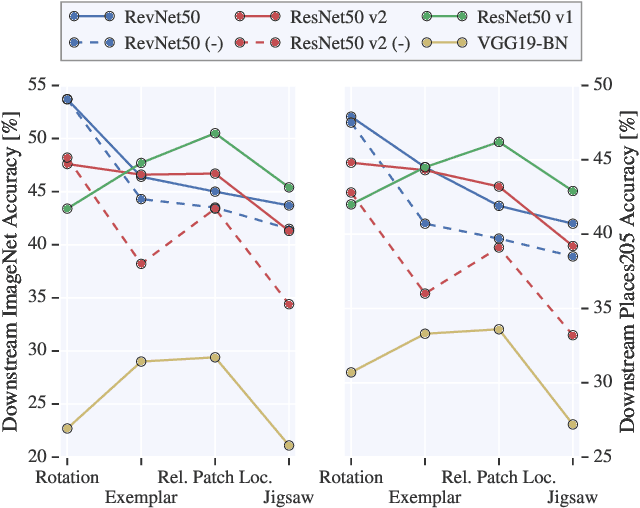
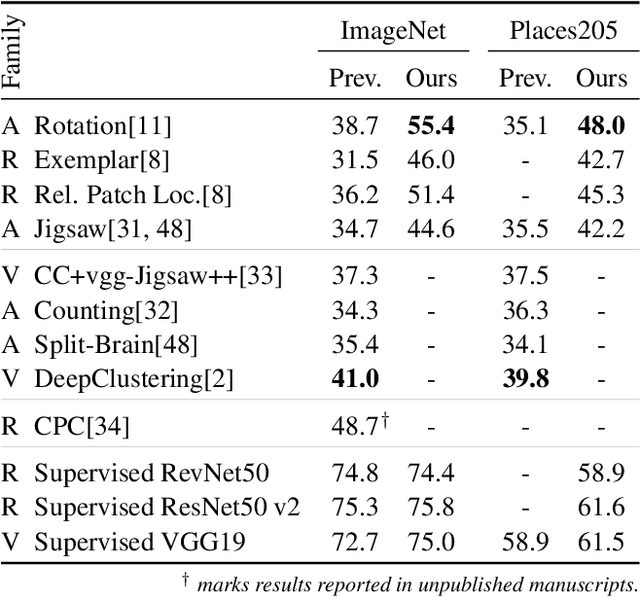
Unsupervised visual representation learning remains a largely unsolved problem in computer vision research. Among a big body of recently proposed approaches for unsupervised learning of visual representations, a class of self-supervised techniques achieves superior performance on many challenging benchmarks. A large number of the pretext tasks for self-supervised learning have been studied, but other important aspects, such as the choice of convolutional neural networks (CNN), has not received equal attention. Therefore, we revisit numerous previously proposed self-supervised models, conduct a thorough large scale study and, as a result, uncover multiple crucial insights. We challenge a number of common practices in selfsupervised visual representation learning and observe that standard recipes for CNN design do not always translate to self-supervised representation learning. As part of our study, we drastically boost the performance of previously proposed techniques and outperform previously published state-of-the-art results by a large margin.
Detection-Tracking for Efficient Person Analysis: The DetTA Pipeline
Jul 28, 2018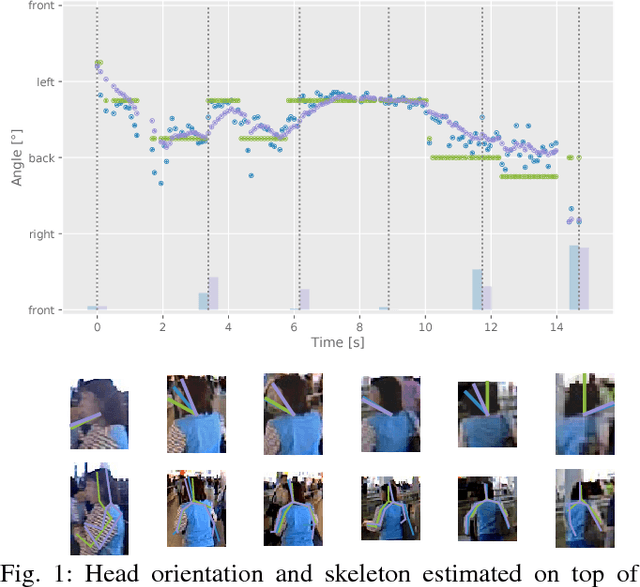
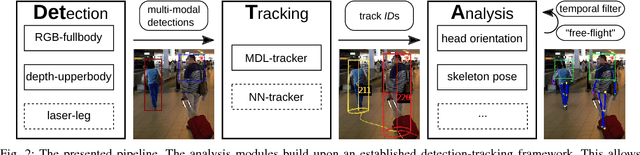
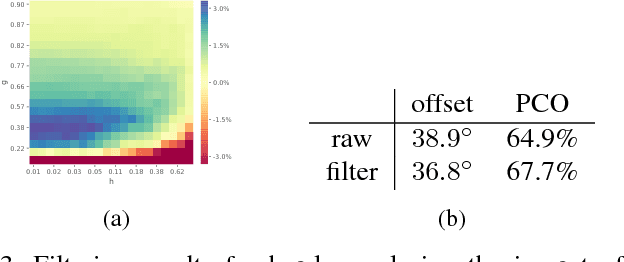
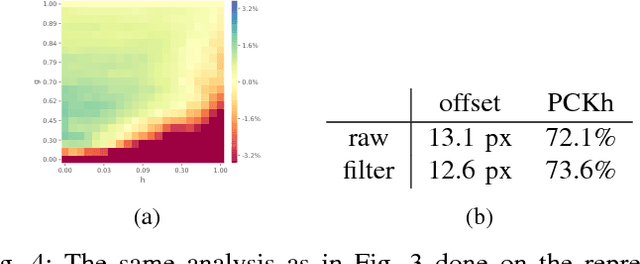
In the past decade many robots were deployed in the wild, and people detection and tracking is an important component of such deployments. On top of that, one often needs to run modules which analyze persons and extract higher level attributes such as age and gender, or dynamic information like gaze and pose. The latter ones are especially necessary for building a reactive, social robot-person interaction. In this paper, we combine those components in a fully modular detection-tracking-analysis pipeline, called DetTA. We investigate the benefits of such an integration on the example of head and skeleton pose, by using the consistent track ID for a temporal filtering of the analysis modules' observations, showing a slight improvement in a challenging real-world scenario. We also study the potential of a so-called "free-flight" mode, where the analysis of a person attribute only relies on the filter's predictions for certain frames. Here, our study shows that this boosts the runtime dramatically, while the prediction quality remains stable. This insight is especially important for reducing power consumption and sharing precious (GPU-)memory when running many analysis components on a mobile platform, especially so in the era of expensive deep learning methods.
Deep Person Detection in 2D Range Data
Apr 06, 2018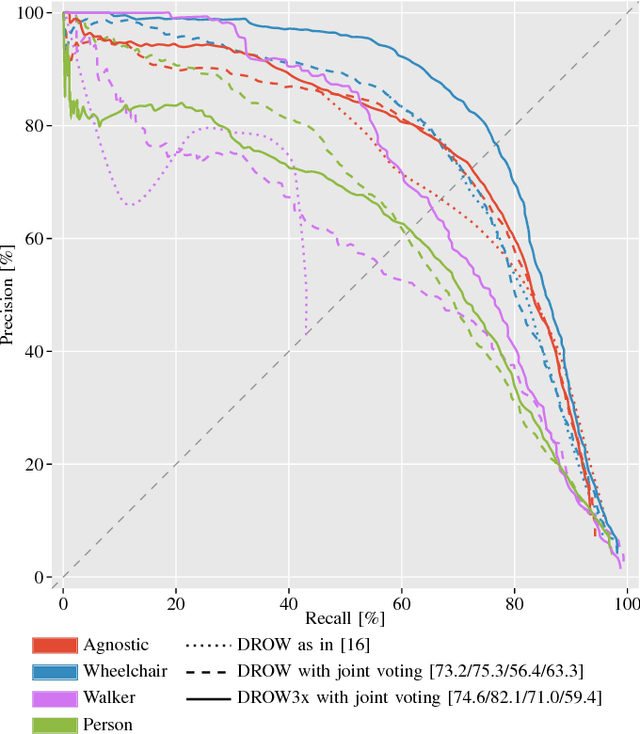
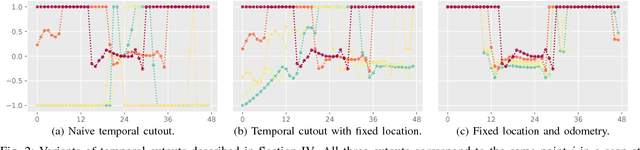
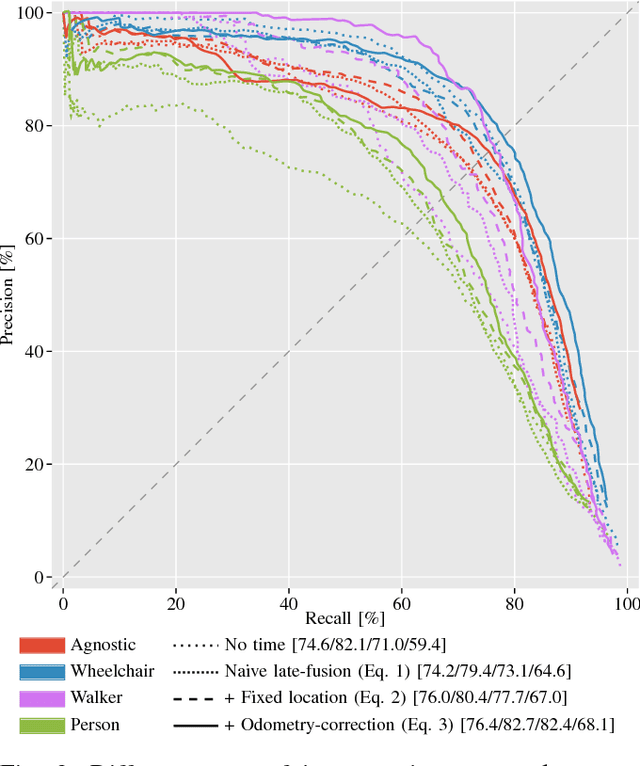
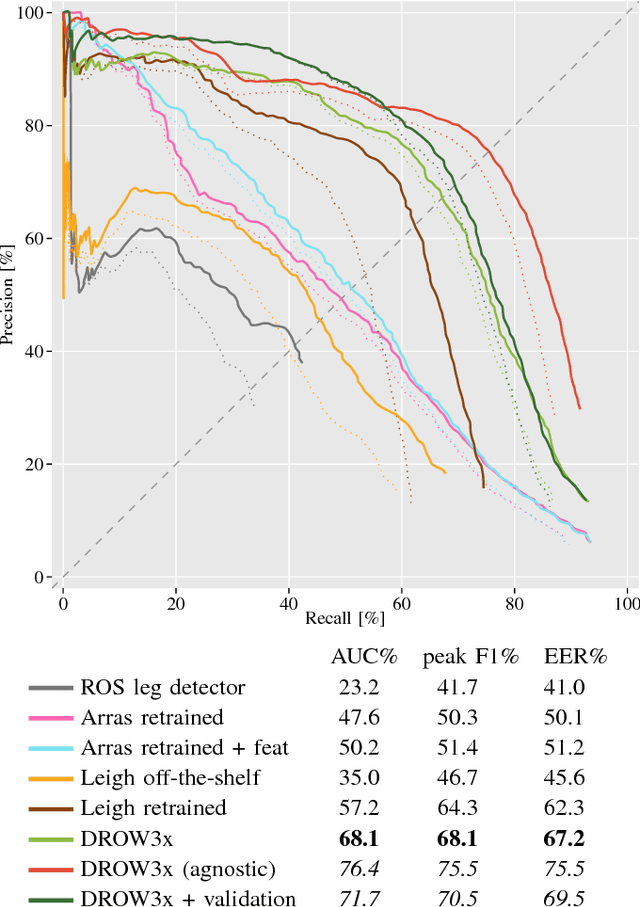
Detecting humans is a key skill for mobile robots and intelligent vehicles in a large variety of applications. While the problem is well studied for certain sensory modalities such as image data, few works exist that address this detection task using 2D range data. However, a widespread sensory setup for many mobile robots in service and domestic applications contains a horizontally mounted 2D laser scanner. Detecting people from 2D range data is challenging due to the speed and dynamics of human leg motion and the high levels of occlusion and self-occlusion particularly in crowds of people. While previous approaches mostly relied on handcrafted features, we recently developed the deep learning based wheelchair and walker detector DROW. In this paper, we show the generalization to people, including small modifications that significantly boost DROW's performance. Additionally, by providing a small, fully online temporal window in our network, we further boost our score. We extend the DROW dataset with person annotations, making this the largest dataset of person annotations in 2D range data, recorded during several days in a real-world environment with high diversity. Extensive experiments with three current baseline methods indicate it is a challenging dataset, on which our improved DROW detector beats the current state-of-the-art.