 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Introspective Agent: Interdependence of Strategy, Physiology, and Sensing for Embodied Agents
Jan 02, 2022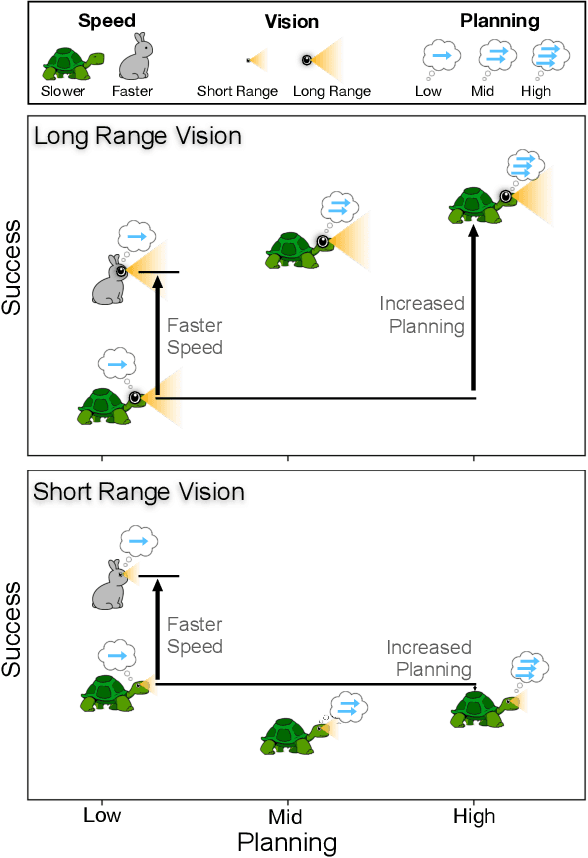
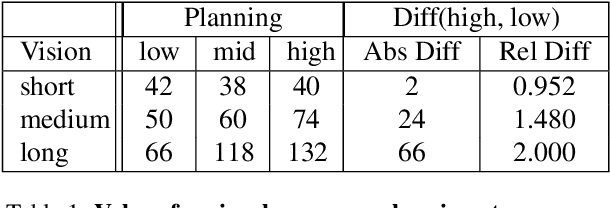

The last few years have witnessed substantial progress in the field of embodied AI where artificial agents, mirroring biological counterparts, are now able to learn from interaction to accomplish complex tasks. Despite this success, biological organisms still hold one large advantage over these simulated agents: adaptation. While both living and simulated agents make decisions to achieve goals (strategy), biological organisms have evolved to understand their environment (sensing) and respond to it (physiology). The net gain of these factors depends on the environment, and organisms have adapted accordingly. For example, in a low vision aquatic environment some fish have evolved specific neurons which offer a predictable, but incredibly rapid, strategy to escape from predators. Mammals have lost these reactive systems, but they have a much larger fields of view and brain circuitry capable of understanding many future possibilities. While traditional embodied agents manipulate an environment to best achieve a goal, we argue for an introspective agent, which considers its own abilities in the context of its environment. We show that different environments yield vastly different optimal designs, and increasing long-term planning is often far less beneficial than other improvements, such as increased physical ability. We present these findings to broaden the definition of improvement in embodied AI passed increasingly complex models. Just as in nature, we hope to reframe strategy as one tool, among many, to succeed in an environment. Code is available at: https://github.com/sarahpratt/introspective.
Towards Disturbance-Free Visual Mobile Manipulation
Dec 17, 2021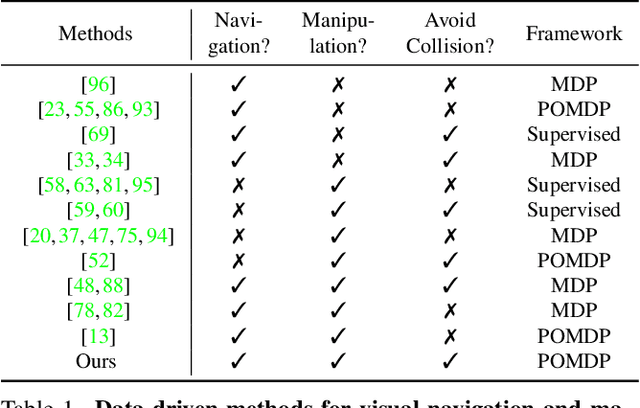
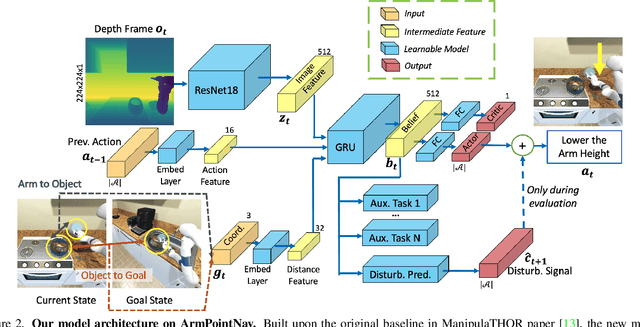
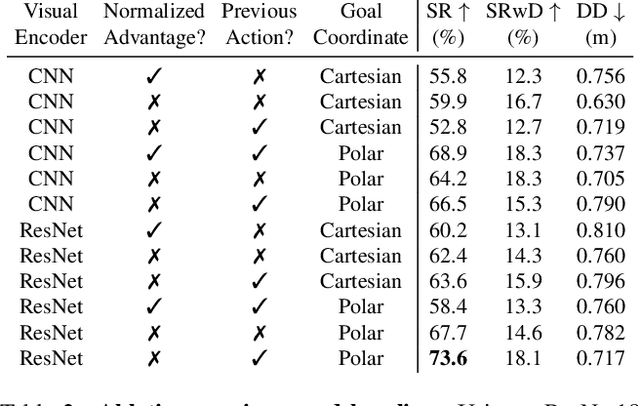
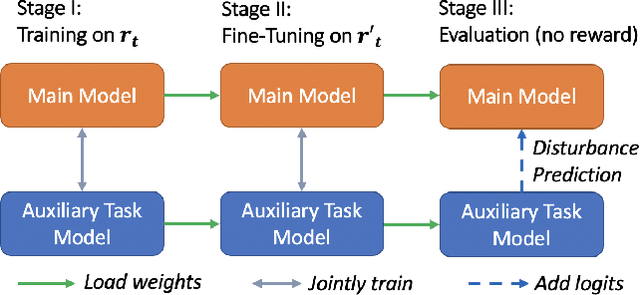
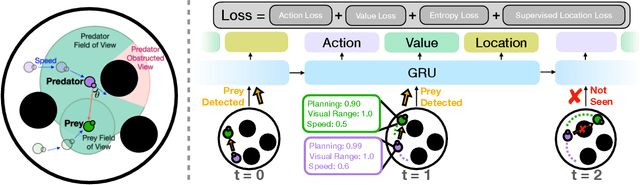
Embodied AI has shown promising results on an abundance of robotic tasks in simulation, including visual navigation and manipulation. The prior work generally pursues high success rates with shortest paths while largely ignoring the problems caused by collision during interaction. This lack of prioritization is understandable: in simulated environments there is no inherent cost to breaking virtual objects. As a result, well-trained agents frequently have catastrophic collision with objects despite final success. In the robotics community, where the cost of collision is large, collision avoidance is a long-standing and crucial topic to ensure that robots can be safely deployed in the real world. In this work, we take the first step towards collision/disturbance-free embodied AI agents for visual mobile manipulation, facilitating safe deployment in real robots. We develop a new disturbance-avoidance methodology at the heart of which is the auxiliary task of disturbance prediction. When combined with a disturbance penalty, our auxiliary task greatly enhances sample efficiency and final performance by knowledge distillation of disturbance into the agent. Our experiments on ManipulaTHOR show that, on testing scenes with novel objects, our method improves the success rate from 61.7% to 85.6% and the success rate without disturbance from 29.8% to 50.2% over the original baseline. Extensive ablation studies show the value of our pipelined approach. Project site is at https://sites.google.com/view/disturb-free
Simple but Effective: CLIP Embeddings for Embodied AI
Nov 18, 2021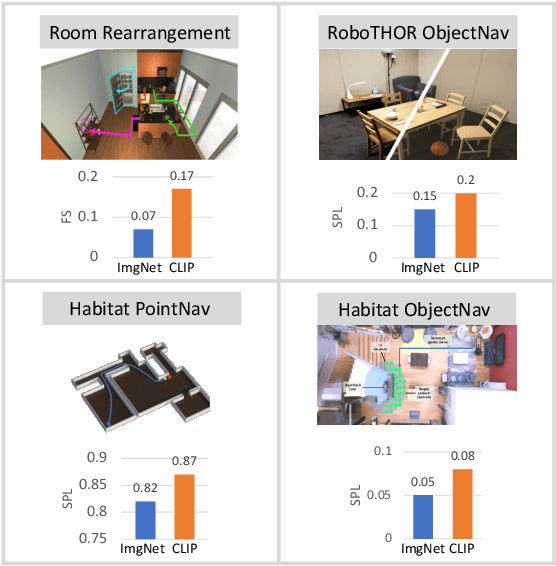
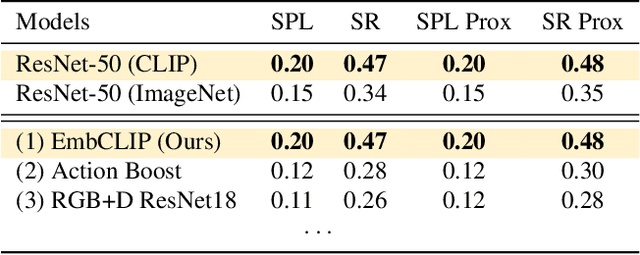
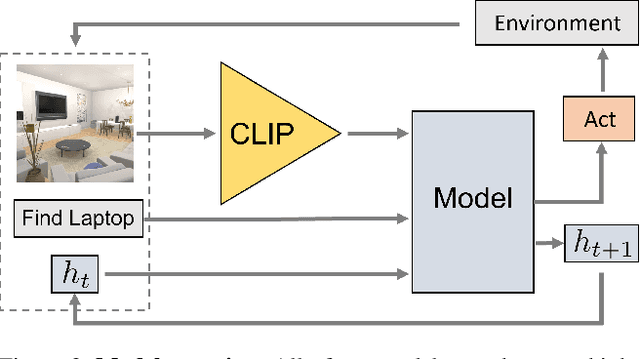
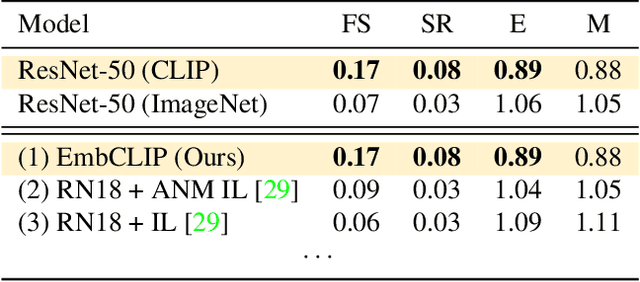
Contrastive language image pretraining (CLIP) encoders have been shown to be beneficial for a range of visual tasks from classification and detection to captioning and image manipulation. We investigate the effectiveness of CLIP visual backbones for embodied AI tasks. We build incredibly simple baselines, named EmbCLIP, with no task specific architectures, inductive biases (such as the use of semantic maps), auxiliary tasks during training, or depth maps -- yet we find that our improved baselines perform very well across a range of tasks and simulators. EmbCLIP tops the RoboTHOR ObjectNav leaderboard by a huge margin of 20 pts (Success Rate). It tops the iTHOR 1-Phase Rearrangement leaderboard, beating the next best submission, which employs Active Neural Mapping, and more than doubling the % Fixed Strict metric (0.08 to 0.17). It also beats the winners of the 2021 Habitat ObjectNav Challenge, which employ auxiliary tasks, depth maps, and human demonstrations, and those of the 2019 Habitat PointNav Challenge. We evaluate the ability of CLIP's visual representations at capturing semantic information about input observations -- primitives that are useful for navigation-heavy embodied tasks -- and find that CLIP's representations encode these primitives more effectively than ImageNet-pretrained backbones. Finally, we extend one of our baselines, producing an agent capable of zero-shot object navigation that can navigate to objects that were not used as targets during training.
Pushing it out of the Way: Interactive Visual Navigation
May 02, 2021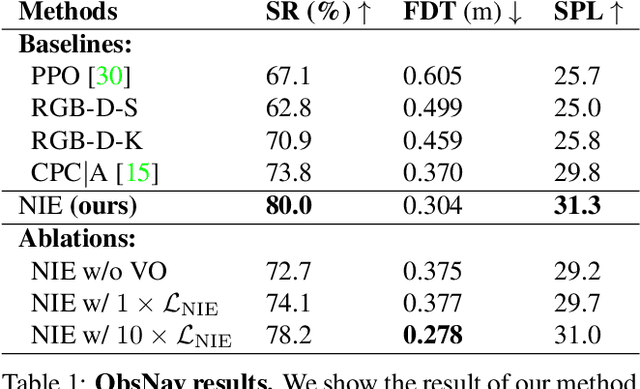
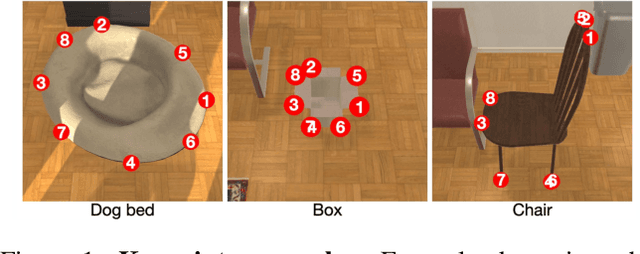
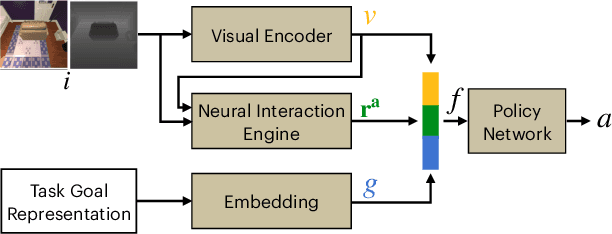
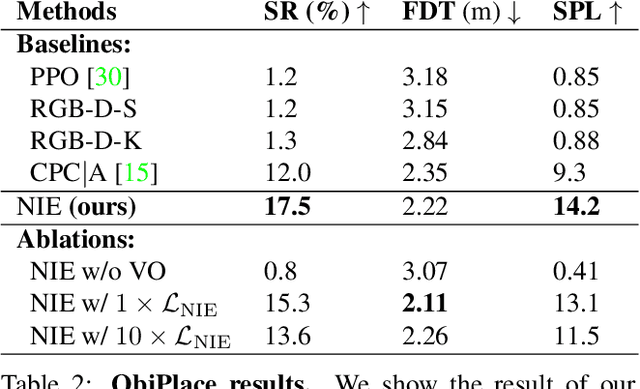
We have observed significant progress in visual navigation for embodied agents. A common assumption in studying visual navigation is that the environments are static; this is a limiting assumption. Intelligent navigation may involve interacting with the environment beyond just moving forward/backward and turning left/right. Sometimes, the best way to navigate is to push something out of the way. In this paper, we study the problem of interactive navigation where agents learn to change the environment to navigate more efficiently to their goals. To this end, we introduce the Neural Interaction Engine (NIE) to explicitly predict the change in the environment caused by the agent's actions. By modeling the changes while planning, we find that agents exhibit significant improvements in their navigational capabilities. More specifically, we consider two downstream tasks in the physics-enabled, visually rich, AI2-THOR environment: (1) reaching a target while the path to the target is blocked (2) moving an object to a target location by pushing it. For both tasks, agents equipped with an NIE significantly outperform agents without the understanding of the effect of the actions indicating the benefits of our approach.
ManipulaTHOR: A Framework for Visual Object Manipulation
Apr 22, 2021
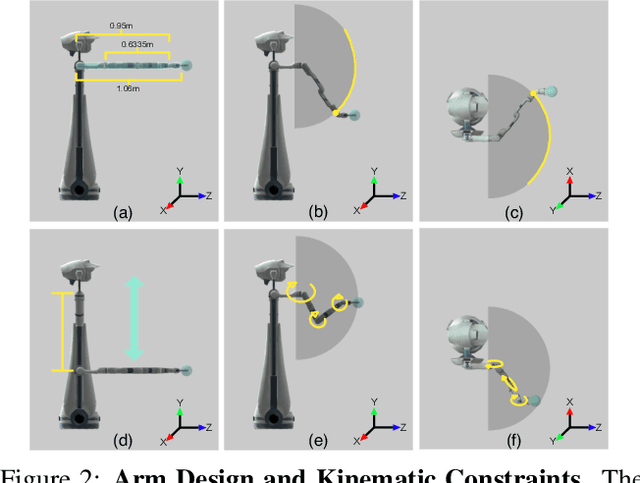
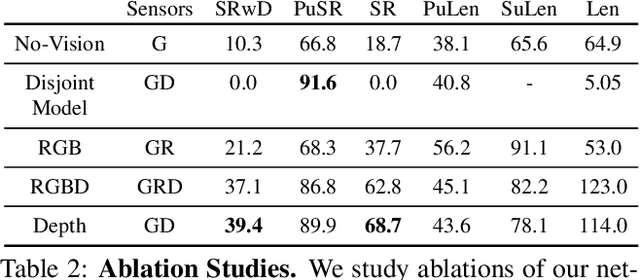

The domain of Embodied AI has recently witnessed substantial progress, particularly in navigating agents within their environments. These early successes have laid the building blocks for the community to tackle tasks that require agents to actively interact with objects in their environment. Object manipulation is an established research domain within the robotics community and poses several challenges including manipulator motion, grasping and long-horizon planning, particularly when dealing with oft-overlooked practical setups involving visually rich and complex scenes, manipulation using mobile agents (as opposed to tabletop manipulation), and generalization to unseen environments and objects. We propose a framework for object manipulation built upon the physics-enabled, visually rich AI2-THOR framework and present a new challenge to the Embodied AI community known as ArmPointNav. This task extends the popular point navigation task to object manipulation and offers new challenges including 3D obstacle avoidance, manipulating objects in the presence of occlusion, and multi-object manipulation that necessitates long term planning. Popular learning paradigms that are successful on PointNav challenges show promise, but leave a large room for improvement.
GridToPix: Training Embodied Agents with Minimal Supervision
Apr 14, 2021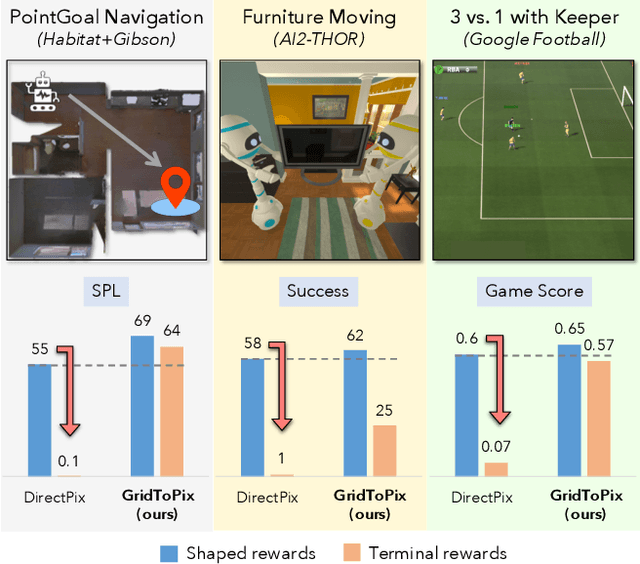

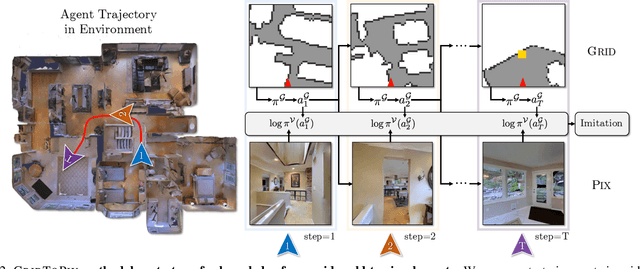

While deep reinforcement learning (RL) promises freedom from hand-labeled data, great successes, especially for Embodied AI, require significant work to create supervision via carefully shaped rewards. Indeed, without shaped rewards, i.e., with only terminal rewards, present-day Embodied AI results degrade significantly across Embodied AI problems from single-agent Habitat-based PointGoal Navigation (SPL drops from 55 to 0) and two-agent AI2-THOR-based Furniture Moving (success drops from 58% to 1%) to three-agent Google Football-based 3 vs. 1 with Keeper (game score drops from 0.6 to 0.1). As training from shaped rewards doesn't scale to more realistic tasks, the community needs to improve the success of training with terminal rewards. For this we propose GridToPix: 1) train agents with terminal rewards in gridworlds that generically mirror Embodied AI environments, i.e., they are independent of the task; 2) distill the learned policy into agents that reside in complex visual worlds. Despite learning from only terminal rewards with identical models and RL algorithms, GridToPix significantly improves results across tasks: from PointGoal Navigation (SPL improves from 0 to 64) and Furniture Moving (success improves from 1% to 25%) to football gameplay (game score improves from 0.1 to 0.6). GridToPix even helps to improve the results of shaped reward training.
Visual Room Rearrangement
Mar 30, 2021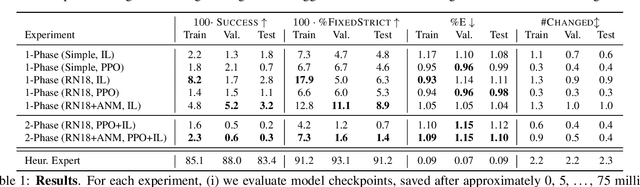
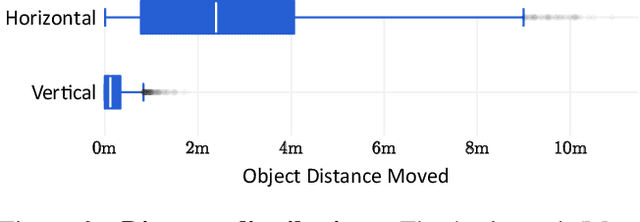
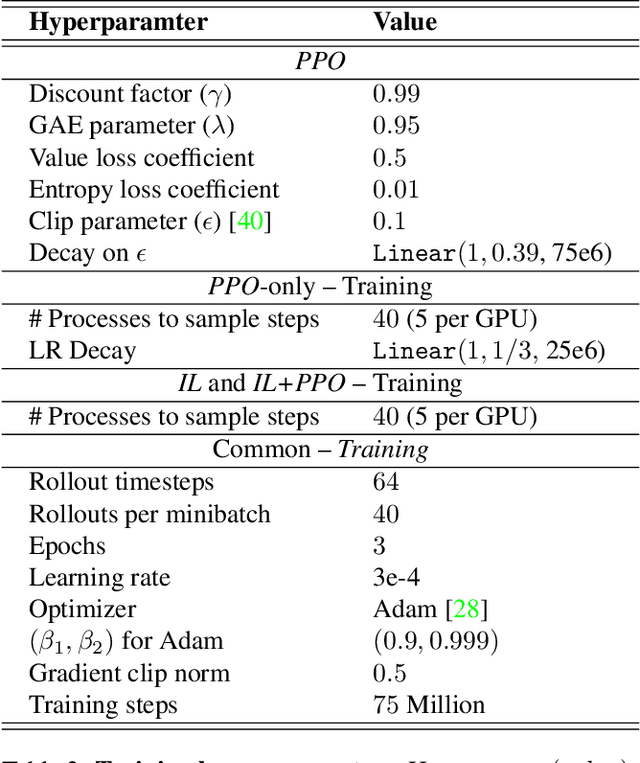
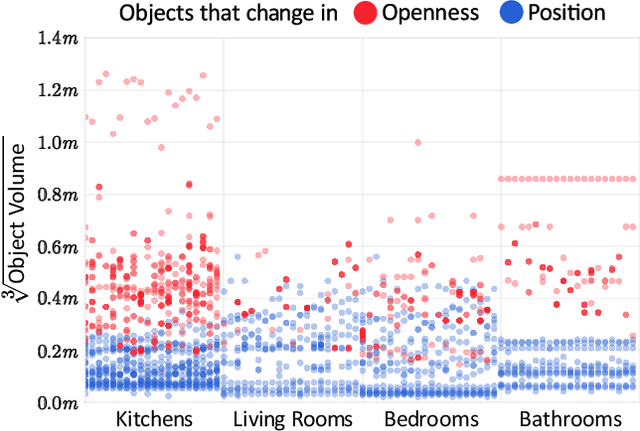
There has been a significant recent progress in the field of Embodied AI with researchers developing models and algorithms enabling embodied agents to navigate and interact within completely unseen environments. In this paper, we propose a new dataset and baseline models for the task of Rearrangement. We particularly focus on the task of Room Rearrangement: an agent begins by exploring a room and recording objects' initial configurations. We then remove the agent and change the poses and states (e.g., open/closed) of some objects in the room. The agent must restore the initial configurations of all objects in the room. Our dataset, named RoomR, includes 6,000 distinct rearrangement settings involving 72 different object types in 120 scenes. Our experiments show that solving this challenging interactive task that involves navigation and object interaction is beyond the capabilities of the current state-of-the-art techniques for embodied tasks and we are still very far from achieving perfect performance on these types of tasks. The code and the dataset are available at: https://ai2thor.allenai.org/rearrangement
AllenAct: A Framework for Embodied AI Research
Aug 28, 2020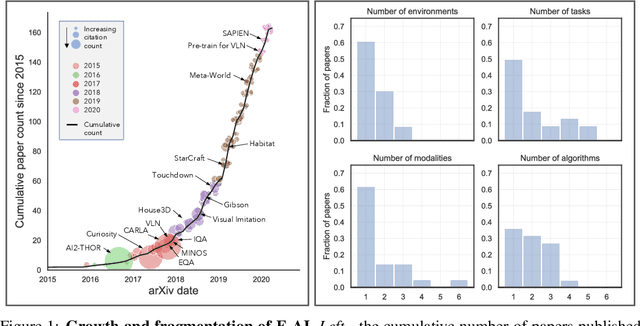

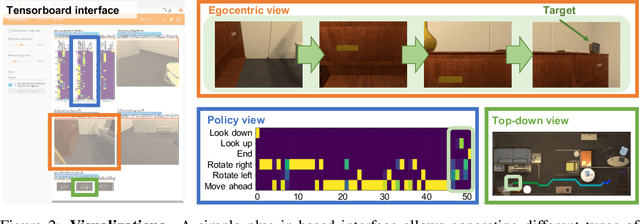
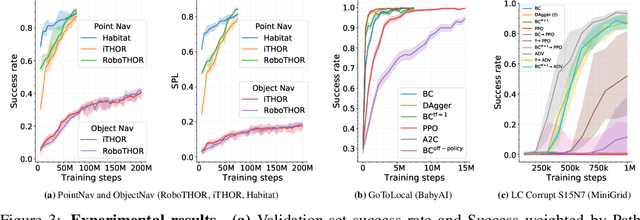
The domain of Embodied AI, in which agents learn to complete tasks through interaction with their environment from egocentric observations, has experienced substantial growth with the advent of deep reinforcement learning and increased interest from the computer vision, NLP, and robotics communities. This growth has been facilitated by the creation of a large number of simulated environments (such as AI2-THOR, Habitat and CARLA), tasks (like point navigation, instruction following, and embodied question answering), and associated leaderboards. While this diversity has been beneficial and organic, it has also fragmented the community: a huge amount of effort is required to do something as simple as taking a model trained in one environment and testing it in another. This discourages good science. We introduce AllenAct, a modular and flexible learning framework designed with a focus on the unique requirements of Embodied AI research. AllenAct provides first-class support for a growing collection of embodied environments, tasks and algorithms, provides reproductions of state-of-the-art models and includes extensive documentation, tutorials, start-up code, and pre-trained models. We hope that our framework makes Embodied AI more accessible and encourages new researchers to join this exciting area. The framework can be accessed at: https://allenact.org/
Bridging the Imitation Gap by Adaptive Insubordination
Jul 23, 2020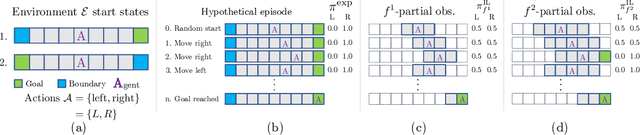
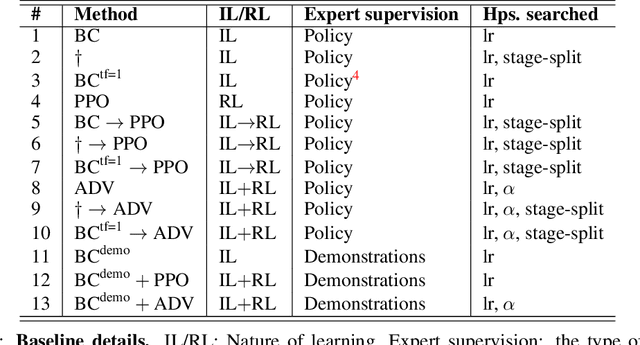
Why do agents often obtain better reinforcement learning policies when imitating a worse expert? We show that privileged information used by the expert is marginalized in the learned agent policy, resulting in an "imitation gap." Prior work bridges this gap via a progression from imitation learning to reinforcement learning. While often successful, gradual progression fails for tasks that require frequent switches between exploration and memorization skills. To better address these tasks and alleviate the imitation gap we propose 'Adaptive Insubordination' (ADVISOR), which dynamically reweights imitation and reward-based reinforcement learning losses during training, enabling switching between imitation and exploration. On a suite of challenging tasks, we show that ADVISOR outperforms pure imitation, pure reinforcement learning, as well as sequential combinations of these approaches.
A Cordial Sync: Going Beyond Marginal Policies for Multi-Agent Embodied Tasks
Jul 09, 2020
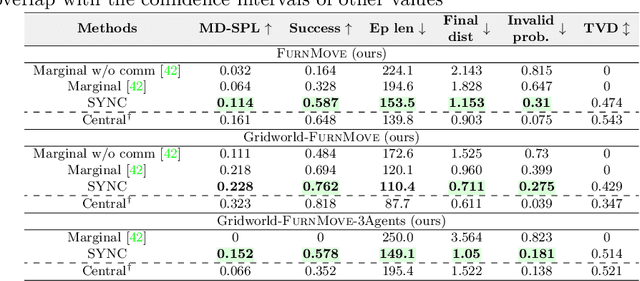
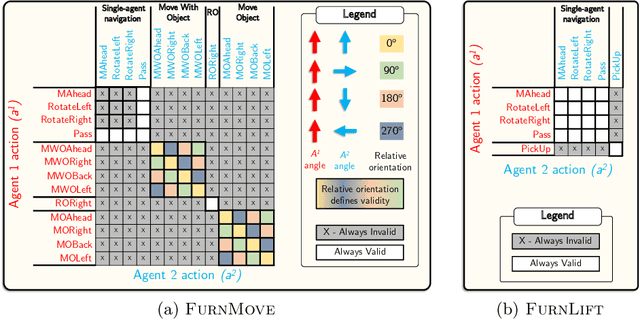

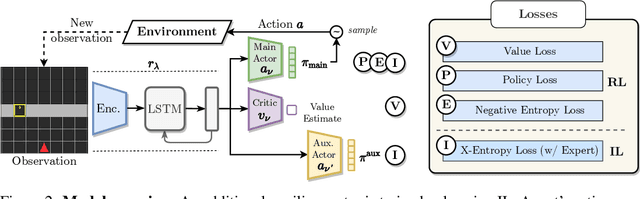
Autonomous agents must learn to collaborate. It is not scalable to develop a new centralized agent every time a task's difficulty outpaces a single agent's abilities. While multi-agent collaboration research has flourished in gridworld-like environments, relatively little work has considered visually rich domains. Addressing this, we introduce the novel task FurnMove in which agents work together to move a piece of furniture through a living room to a goal. Unlike existing tasks, FurnMove requires agents to coordinate at every timestep. We identify two challenges when training agents to complete FurnMove: existing decentralized action sampling procedures do not permit expressive joint action policies and, in tasks requiring close coordination, the number of failed actions dominates successful actions. To confront these challenges we introduce SYNC-policies (synchronize your actions coherently) and CORDIAL (coordination loss). Using SYNC-policies and CORDIAL, our agents achieve a 58% completion rate on FurnMove, an impressive absolute gain of 25 percentage points over competitive decentralized baselines. Our dataset, code, and pretrained models are available at https://unnat.github.io/cordial-sync .