 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSenteCon: Leveraging Lexicons to Learn Human-Interpretable Language Representations
May 24, 2023



Although deep language representations have become the dominant form of language featurization in recent years, in many settings it is important to understand a model's decision-making process. This necessitates not only an interpretable model but also interpretable features. In particular, language must be featurized in a way that is interpretable while still characterizing the original text well. We present SenteCon, a method for introducing human interpretability in deep language representations. Given a passage of text, SenteCon encodes the text as a layer of interpretable categories in which each dimension corresponds to the relevance of a specific category. Our empirical evaluations indicate that encoding language with SenteCon provides high-level interpretability at little to no cost to predictive performance on downstream tasks. Moreover, we find that SenteCon outperforms existing interpretable language representations with respect to both its downstream performance and its agreement with human characterizations of the text.
Counterfactual Augmentation for Multimodal Learning Under Presentation Bias
May 23, 2023In real-world machine learning systems, labels are often derived from user behaviors that the system wishes to encourage. Over time, new models must be trained as new training examples and features become available. However, feedback loops between users and models can bias future user behavior, inducing a presentation bias in the labels that compromises the ability to train new models. In this paper, we propose counterfactual augmentation, a novel causal method for correcting presentation bias using generated counterfactual labels. Our empirical evaluations demonstrate that counterfactual augmentation yields better downstream performance compared to both uncorrected models and existing bias-correction methods. Model analyses further indicate that the generated counterfactuals align closely with true counterfactuals in an oracle setting.
Difference-Masking: Choosing What to Mask in Continued Pretraining
May 23, 2023



Self-supervised learning (SSL) and the objective of masking-and-predicting in particular have led to promising SSL performance on a variety of downstream tasks. However, while most approaches randomly mask tokens, there is strong intuition from the field of education that deciding what to mask can substantially improve learning outcomes. We introduce Difference-Masking, an approach that automatically chooses what to mask during continued pretraining by considering what makes an unlabelled target domain different from the pretraining domain. Empirically, we find that Difference-Masking outperforms baselines on continued pretraining settings across four diverse language and multimodal video tasks. The cross-task applicability of Difference-Masking supports the effectiveness of our framework for SSL pretraining in language, vision, and other domains.
Expanding the Role of Affective Phenomena in Multimodal Interaction Research
May 18, 2023



In recent decades, the field of affective computing has made substantial progress in advancing the ability of AI systems to recognize and express affective phenomena, such as affect and emotions, during human-human and human-machine interactions. This paper describes our examination of research at the intersection of multimodal interaction and affective computing, with the objective of observing trends and identifying understudied areas. We examined over 16,000 papers from selected conferences in multimodal interaction, affective computing, and natural language processing: ACM International Conference on Multimodal Interaction, AAAC International Conference on Affective Computing and Intelligent Interaction, Annual Meeting of the Association for Computational Linguistics, and Conference on Empirical Methods in Natural Language Processing. We identified 910 affect-related papers and present our analysis of the role of affective phenomena in these papers. We find that this body of research has primarily focused on enabling machines to recognize and express affect and emotion. However, we find limited research on how affect and emotion predictions might be used by AI systems to enhance machine understanding of human social behaviors and cognitive states. Based on our analysis, we discuss directions to expand the role of affective phenomena in multimodal interaction research.
Quantifying & Modeling Feature Interactions: An Information Decomposition Framework
Feb 23, 2023The recent explosion of interest in multimodal applications has resulted in a wide selection of datasets and methods for representing and integrating information from different signals. Despite these empirical advances, there remain fundamental research questions: how can we quantify the nature of interactions that exist among input features? Subsequently, how can we capture these interactions using suitable data-driven methods? To answer this question, we propose an information-theoretic approach to quantify the degree of redundancy, uniqueness, and synergy across input features, which we term the PID statistics of a multimodal distribution. Using 2 newly proposed estimators that scale to high-dimensional distributions, we demonstrate their usefulness in quantifying the interactions within multimodal datasets, the nature of interactions captured by multimodal models, and principled approaches for model selection. We conduct extensive experiments on both synthetic datasets where the PID statistics are known and on large-scale multimodal benchmarks where PID estimation was previously impossible. Finally, to demonstrate the real-world applicability of our approach, we present three case studies in pathology, mood prediction, and robotic perception where our framework accurately recommends strong multimodal models for each application.
Cross-modal Attention Congruence Regularization for Vision-Language Relation Alignment
Dec 20, 2022



Despite recent progress towards scaling up multimodal vision-language models, these models are still known to struggle on compositional generalization benchmarks such as Winoground. We find that a critical component lacking from current vision-language models is relation-level alignment: the ability to match directional semantic relations in text (e.g., "mug in grass") with spatial relationships in the image (e.g., the position of the mug relative to the grass). To tackle this problem, we show that relation alignment can be enforced by encouraging the directed language attention from 'mug' to 'grass' (capturing the semantic relation 'in') to match the directed visual attention from the mug to the grass. Tokens and their corresponding objects are softly identified using the cross-modal attention. We prove that this notion of soft relation alignment is equivalent to enforcing congruence between vision and language attention matrices under a 'change of basis' provided by the cross-modal attention matrix. Intuitively, our approach projects visual attention into the language attention space to calculate its divergence from the actual language attention, and vice versa. We apply our Cross-modal Attention Congruence Regularization (CACR) loss to UNITER and improve on the state-of-the-art approach to Winoground.
SeedBERT: Recovering Annotator Rating Distributions from an Aggregated Label
Nov 23, 2022



Many machine learning tasks -- particularly those in affective computing -- are inherently subjective. When asked to classify facial expressions or to rate an individual's attractiveness, humans may disagree with one another, and no single answer may be objectively correct. However, machine learning datasets commonly have just one "ground truth" label for each sample, so models trained on these labels may not perform well on tasks that are subjective in nature. Though allowing models to learn from the individual annotators' ratings may help, most datasets do not provide annotator-specific labels for each sample. To address this issue, we propose SeedBERT, a method for recovering annotator rating distributions from a single label by inducing pre-trained models to attend to different portions of the input. Our human evaluations indicate that SeedBERT's attention mechanism is consistent with human sources of annotator disagreement. Moreover, in our empirical evaluations using large language models, SeedBERT demonstrates substantial gains in performance on downstream subjective tasks compared both to standard deep learning models and to other current models that account explicitly for annotator disagreement.
Nano: Nested Human-in-the-Loop Reward Learning for Few-shot Language Model Control
Nov 10, 2022



Pretrained language models have demonstrated extraordinary capabilities in language generation. However, real-world tasks often require controlling the distribution of generated text in order to mitigate bias, promote fairness, and achieve personalization. Existing techniques for controlling the distribution of generated text only work with quantified distributions, which require pre-defined categories, proportions of the distribution, or an existing corpus following the desired distributions. However, many important distributions, such as personal preferences, are unquantified. In this work, we tackle the problem of generating text following arbitrary distributions (quantified and unquantified) by proposing Nano, a few-shot human-in-the-loop training algorithm that continuously learns from human feedback. Nano achieves state-of-the-art results on single topic/attribute as well as quantified distribution control compared to previous works. We also show that Nano is able to learn unquantified distributions, achieves personalization, and captures differences between different individuals' personal preferences with high sample efficiency.
Uncertainty Quantification with Pre-trained Language Models: A Large-Scale Empirical Analysis
Oct 10, 2022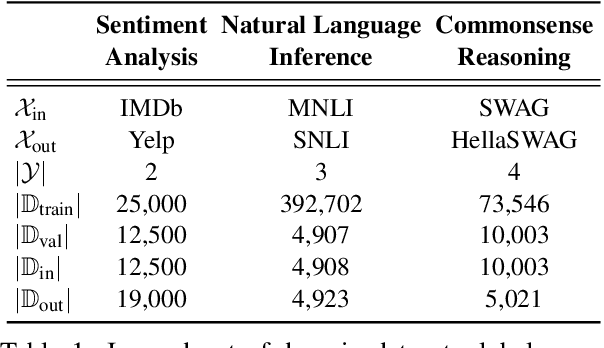
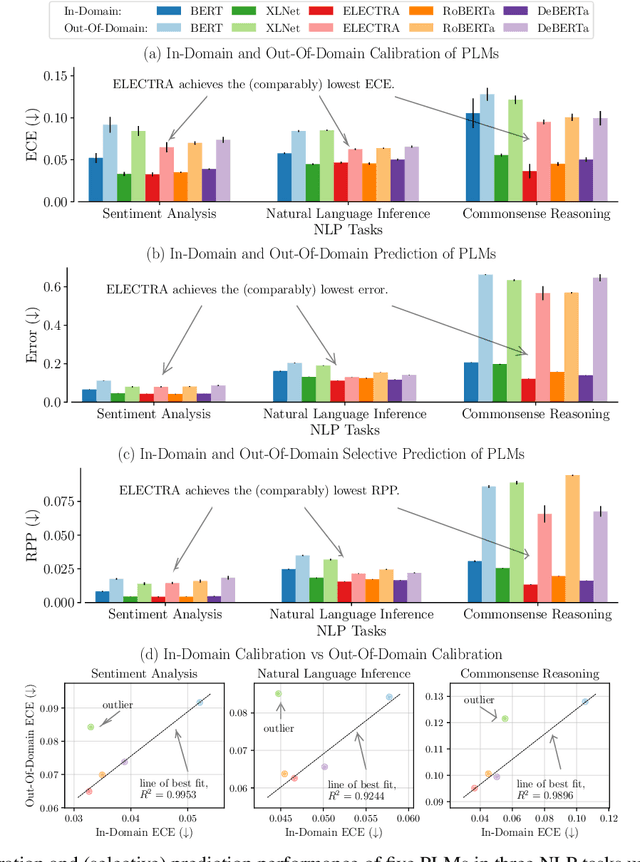
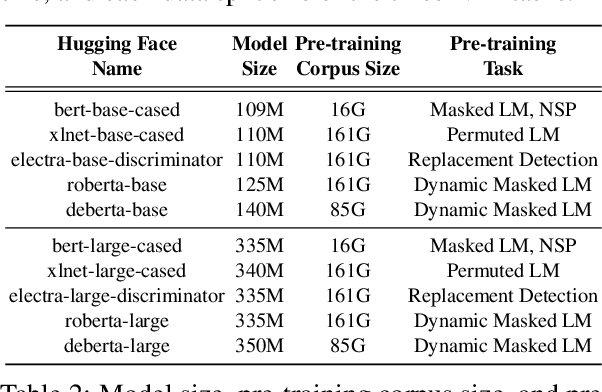
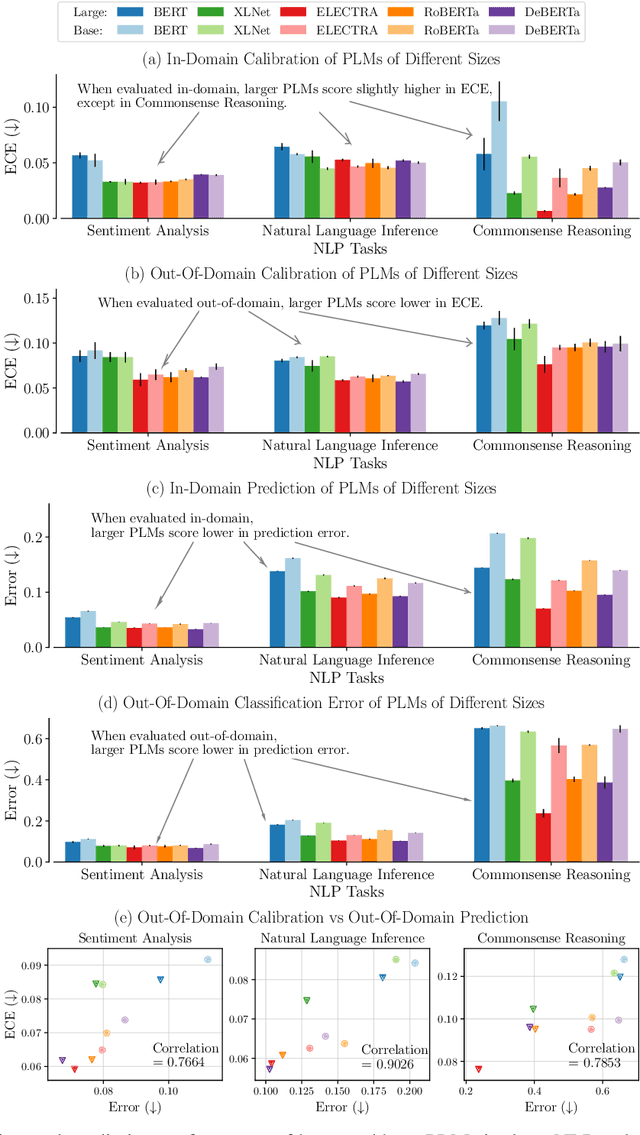
Pre-trained language models (PLMs) have gained increasing popularity due to their compelling prediction performance in diverse natural language processing (NLP) tasks. When formulating a PLM-based prediction pipeline for NLP tasks, it is also crucial for the pipeline to minimize the calibration error, especially in safety-critical applications. That is, the pipeline should reliably indicate when we can trust its predictions. In particular, there are various considerations behind the pipeline: (1) the choice and (2) the size of PLM, (3) the choice of uncertainty quantifier, (4) the choice of fine-tuning loss, and many more. Although prior work has looked into some of these considerations, they usually draw conclusions based on a limited scope of empirical studies. There still lacks a holistic analysis on how to compose a well-calibrated PLM-based prediction pipeline. To fill this void, we compare a wide range of popular options for each consideration based on three prevalent NLP classification tasks and the setting of domain shift. In response, we recommend the following: (1) use ELECTRA for PLM encoding, (2) use larger PLMs if possible, (3) use Temp Scaling as the uncertainty quantifier, and (4) use Focal Loss for fine-tuning.
Paraphrasing Is All You Need for Novel Object Captioning
Sep 25, 2022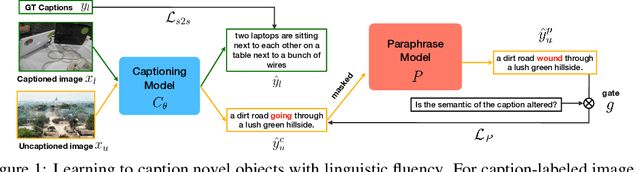
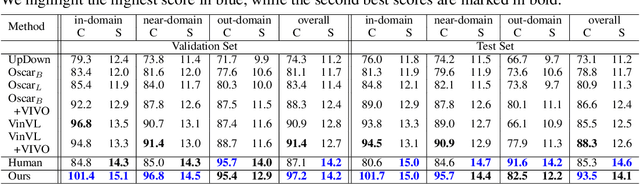
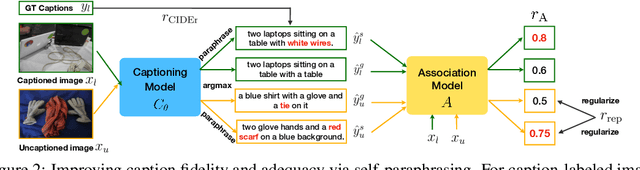
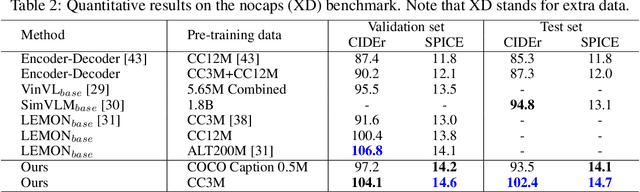
Novel object captioning (NOC) aims to describe images containing objects without observing their ground truth captions during training. Due to the absence of caption annotation, captioning models cannot be directly optimized via sequence-to-sequence training or CIDEr optimization. As a result, we present Paraphrasing-to-Captioning (P2C), a two-stage learning framework for NOC, which would heuristically optimize the output captions via paraphrasing. With P2C, the captioning model first learns paraphrasing from a language model pre-trained on text-only corpus, allowing expansion of the word bank for improving linguistic fluency. To further enforce the output caption sufficiently describing the visual content of the input image, we perform self-paraphrasing for the captioning model with fidelity and adequacy objectives introduced. Since no ground truth captions are available for novel object images during training, our P2C leverages cross-modality (image-text) association modules to ensure the above caption characteristics can be properly preserved. In the experiments, we not only show that our P2C achieves state-of-the-art performances on nocaps and COCO Caption datasets, we also verify the effectiveness and flexibility of our learning framework by replacing language and cross-modality association models for NOC. Implementation details and code are available in the supplementary materials.