 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterfactual Reward Model Training for Bias Mitigation in Multimodal Reinforcement Learning
Aug 27, 2025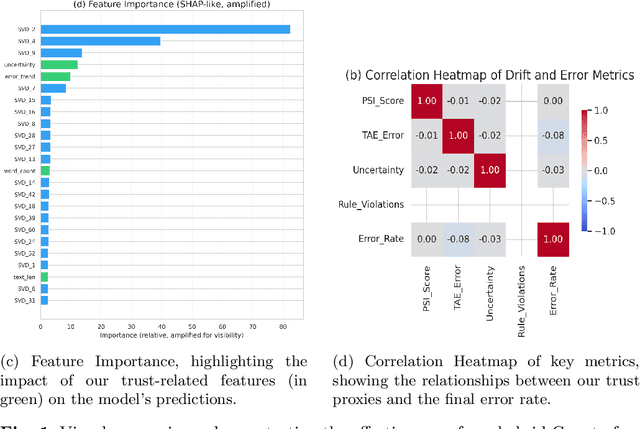
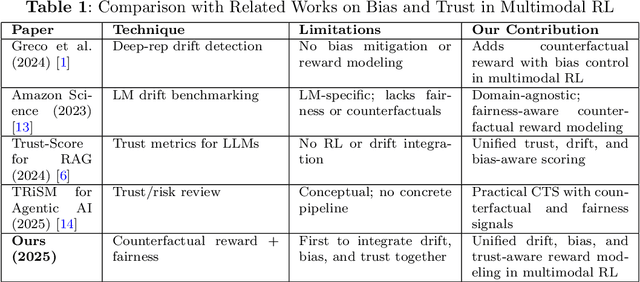
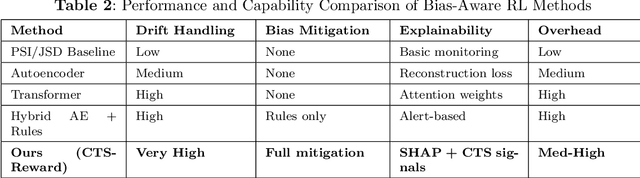
In reinforcement learning with human feedback (RLHF), reward models can efficiently learn and amplify latent biases within multimodal datasets, which can lead to imperfect policy optimization through flawed reward signals and decreased fairness. Bias mitigation studies have often applied passive constraints, which can fail under causal confounding. Here, we present a counterfactual reward model that introduces causal inference with multimodal representation learning to provide an unsupervised, bias-resilient reward signal. The heart of our contribution is the Counterfactual Trust Score, an aggregated score consisting of four components: (1) counterfactual shifts that decompose political framing bias from topical bias; (2) reconstruction uncertainty during counterfactual perturbations; (3) demonstrable violations of fairness rules for each protected attribute; and (4) temporal reward shifts aligned with dynamic trust measures. We evaluated the framework on a multimodal fake versus true news dataset, which exhibits framing bias, class imbalance, and distributional drift. Following methodologies similar to unsupervised drift detection from representation-based distances [1] and temporal robustness benchmarking in language models [2], we also inject synthetic bias across sequential batches to test robustness. The resulting system achieved an accuracy of 89.12% in fake news detection, outperforming the baseline reward models. More importantly, it reduced spurious correlations and unfair reinforcement signals. This pipeline outlines a robust and interpretable approach to fairness-aware RLHF, offering tunable bias reduction thresholds and increasing reliability in dynamic real-time policy making.
VinaBench: Benchmark for Faithful and Consistent Visual Narratives
Mar 26, 2025



Visual narrative generation transforms textual narratives into sequences of images illustrating the content of the text. However, generating visual narratives that are faithful to the input text and self-consistent across generated images remains an open challenge, due to the lack of knowledge constraints used for planning the stories. In this work, we propose a new benchmark, VinaBench, to address this challenge. Our benchmark annotates the underlying commonsense and discourse constraints in visual narrative samples, offering systematic scaffolds for learning the implicit strategies of visual storytelling. Based on the incorporated narrative constraints, we further propose novel metrics to closely evaluate the consistency of generated narrative images and the alignment of generations with the input textual narrative. Our results across three generative vision models demonstrate that learning with VinaBench's knowledge constraints effectively improves the faithfulness and cohesion of generated visual narratives.
Multimodal Fusion with LLMs for Engagement Prediction in Natural Conversation
Sep 13, 2024Over the past decade, wearable computing devices (``smart glasses'') have undergone remarkable advancements in sensor technology, design, and processing power, ushering in a new era of opportunity for high-density human behavior data. Equipped with wearable cameras, these glasses offer a unique opportunity to analyze non-verbal behavior in natural settings as individuals interact. Our focus lies in predicting engagement in dyadic interactions by scrutinizing verbal and non-verbal cues, aiming to detect signs of disinterest or confusion. Leveraging such analyses may revolutionize our understanding of human communication, foster more effective collaboration in professional environments, provide better mental health support through empathetic virtual interactions, and enhance accessibility for those with communication barriers. In this work, we collect a dataset featuring 34 participants engaged in casual dyadic conversations, each providing self-reported engagement ratings at the end of each conversation. We introduce a novel fusion strategy using Large Language Models (LLMs) to integrate multiple behavior modalities into a ``multimodal transcript'' that can be processed by an LLM for behavioral reasoning tasks. Remarkably, this method achieves performance comparable to established fusion techniques even in its preliminary implementation, indicating strong potential for further research and optimization. This fusion method is one of the first to approach ``reasoning'' about real-world human behavior through a language model. Smart glasses provide us the ability to unobtrusively gather high-density multimodal data on human behavior, paving the way for new approaches to understanding and improving human communication with the potential for important societal benefits. The features and data collected during the studies will be made publicly available to promote further research.
Difference-Masking: Choosing What to Mask in Continued Pretraining
May 23, 2023



Self-supervised learning (SSL) and the objective of masking-and-predicting in particular have led to promising SSL performance on a variety of downstream tasks. However, while most approaches randomly mask tokens, there is strong intuition from the field of education that deciding what to mask can substantially improve learning outcomes. We introduce Difference-Masking, an approach that automatically chooses what to mask during continued pretraining by considering what makes an unlabelled target domain different from the pretraining domain. Empirically, we find that Difference-Masking outperforms baselines on continued pretraining settings across four diverse language and multimodal video tasks. The cross-task applicability of Difference-Masking supports the effectiveness of our framework for SSL pretraining in language, vision, and other domains.
Human activity recognition using deep learning approaches and single frame cnn and convolutional lstm
Apr 18, 2023



Human activity recognition is one of the most important tasks in computer vision and has proved useful in different fields such as healthcare, sports training and security. There are a number of approaches that have been explored to solve this task, some of them involving sensor data, and some involving video data. In this paper, we aim to explore two deep learning-based approaches, namely single frame Convolutional Neural Networks (CNNs) and convolutional Long Short-Term Memory to recognise human actions from videos. Using a convolutional neural networks-based method is advantageous as CNNs can extract features automatically and Long Short-Term Memory networks are great when it comes to working on sequence data such as video. The two models were trained and evaluated on a benchmark action recognition dataset, UCF50, and another dataset that was created for the experimentation. Though both models exhibit good accuracies, the single frame CNN model outperforms the Convolutional LSTM model by having an accuracy of 99.8% with the UCF50 dataset.