 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLlama 2: Open Foundation and Fine-Tuned Chat Models
Jul 19, 2023



In this work, we develop and release Llama 2, a collection of pretrained and fine-tuned large language models (LLMs) ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama 2-Chat, are optimized for dialogue use cases. Our models outperform open-source chat models on most benchmarks we tested, and based on our human evaluations for helpfulness and safety, may be a suitable substitute for closed-source models. We provide a detailed description of our approach to fine-tuning and safety improvements of Llama 2-Chat in order to enable the community to build on our work and contribute to the responsible development of LLMs.
Multilingual End to End Entity Linking
Jun 15, 2023



Entity Linking is one of the most common Natural Language Processing tasks in practical applications, but so far efficient end-to-end solutions with multilingual coverage have been lacking, leading to complex model stacks. To fill this gap, we release and open source BELA, the first fully end-to-end multilingual entity linking model that efficiently detects and links entities in texts in any of 97 languages. We provide here a detailed description of the model and report BELA's performance on four entity linking datasets covering high- and low-resource languages.
Polar Ducks and Where to Find Them: Enhancing Entity Linking with Duck Typing and Polar Box Embeddings
May 19, 2023



Entity linking methods based on dense retrieval are an efficient and widely used solution in large-scale applications, but they fall short of the performance of generative models, as they are sensitive to the structure of the embedding space. In order to address this issue, this paper introduces DUCK, an approach to infusing structural information in the space of entity representations, using prior knowledge of entity types. Inspired by duck typing in programming languages, we propose to define the type of an entity based on the relations that it has with other entities in a knowledge graph. Then, porting the concept of box embeddings to spherical polar coordinates, we propose to represent relations as boxes on the hypersphere. We optimize the model to cluster entities of similar type by placing them inside the boxes corresponding to their relations. Our experiments show that our method sets new state-of-the-art results on standard entity-disambiguation benchmarks, it improves the performance of the model by up to 7.9 F1 points, outperforms other type-aware approaches, and matches the results of generative models with 18 times more parameters.
Entity Tagging: Extracting Entities in Text Without Mention Supervision
Sep 13, 2022
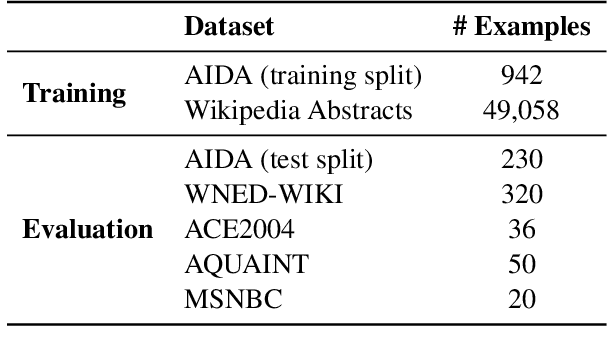

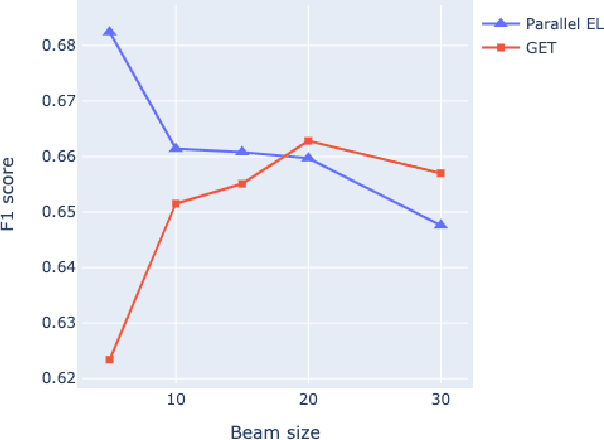
Detection and disambiguation of all entities in text is a crucial task for a wide range of applications. The typical formulation of the problem involves two stages: detect mention boundaries and link all mentions to a knowledge base. For a long time, mention detection has been considered as a necessary step for extracting all entities in a piece of text, even if the information about mention spans is ignored by some downstream applications that merely focus on the set of extracted entities. In this paper we show that, in such cases, detection of mention boundaries does not bring any considerable performance gain in extracting entities, and therefore can be skipped. To conduct our analysis, we propose an "Entity Tagging" formulation of the problem, where models are evaluated purely on the set of extracted entities without considering mentions. We compare a state-of-the-art mention-aware entity linking solution against GET, a mention-agnostic sequence-to-sequence model that simply outputs a list of disambiguated entities given an input context. We find that these models achieve comparable performance when trained both on a fully and partially annotated dataset across multiple benchmarks, demonstrating that GET can extract disambiguated entities with strong performance without explicit mention boundaries supervision.
Efficient Large Scale Language Modeling with Mixtures of Experts
Dec 20, 2021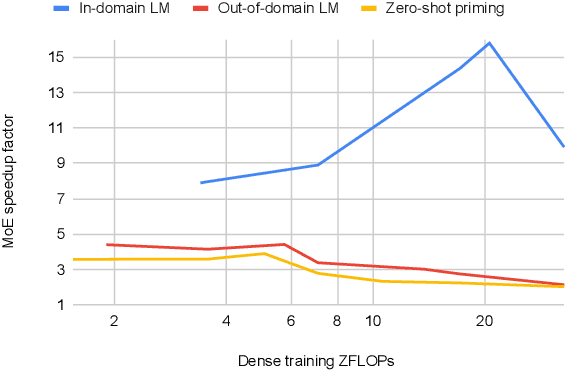
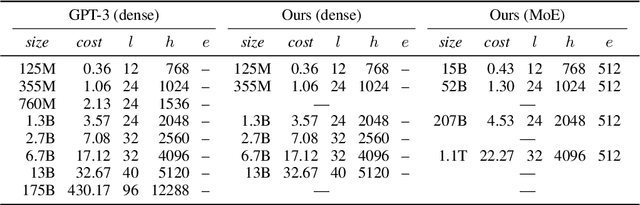
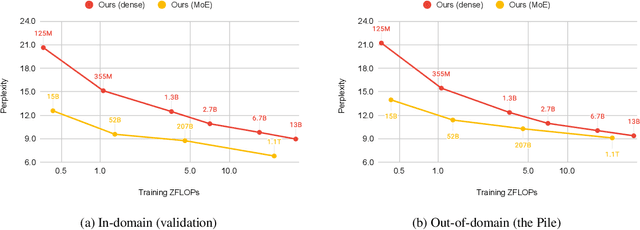
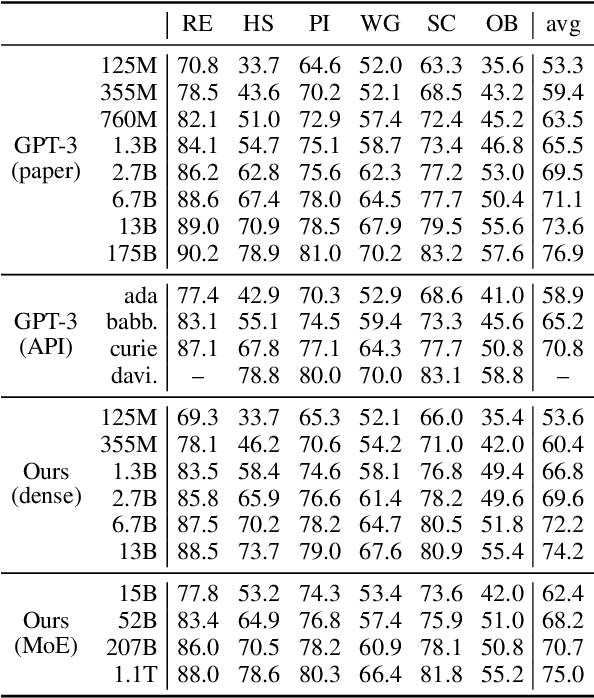
Mixture of Experts layers (MoEs) enable efficient scaling of language models through conditional computation. This paper presents a detailed empirical study of how autoregressive MoE language models scale in comparison with dense models in a wide range of settings: in- and out-of-domain language modeling, zero- and few-shot priming, and full fine-tuning. With the exception of fine-tuning, we find MoEs to be substantially more compute efficient. At more modest training budgets, MoEs can match the performance of dense models using $\sim$4 times less compute. This gap narrows at scale, but our largest MoE model (1.1T parameters) consistently outperforms a compute-equivalent dense model (6.7B parameters). Overall, this performance gap varies greatly across tasks and domains, suggesting that MoE and dense models generalize differently in ways that are worthy of future study. We make our code and models publicly available for research use.
Rethinking Automatic Evaluation in Sentence Simplification
Apr 16, 2021
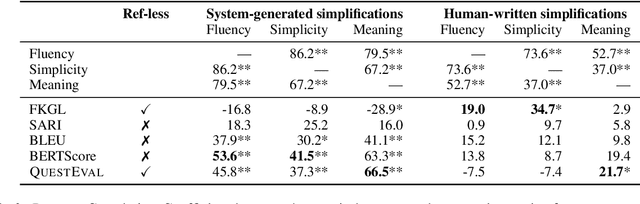
Automatic evaluation remains an open research question in Natural Language Generation. In the context of Sentence Simplification, this is particularly challenging: the task requires by nature to replace complex words with simpler ones that shares the same meaning. This limits the effectiveness of n-gram based metrics like BLEU. Going hand in hand with the recent advances in NLG, new metrics have been proposed, such as BERTScore for Machine Translation. In summarization, the QuestEval metric proposes to automatically compare two texts by questioning them. In this paper, we first propose a simple modification of QuestEval allowing it to tackle Sentence Simplification. We then extensively evaluate the correlations w.r.t. human judgement for several metrics including the recent BERTScore and QuestEval, and show that the latter obtain state-of-the-art correlations, outperforming standard metrics like BLEU and SARI. More importantly, we also show that a large part of the correlations are actually spurious for all the metrics. To investigate this phenomenon further, we release a new corpus of evaluated simplifications, this time not generated by systems but instead, written by humans. This allows us to remove the spurious correlations and draw very different conclusions from the original ones, resulting in a better understanding of these metrics. In particular, we raise concerns about very low correlations for most of traditional metrics. Our results show that the only significant measure of the Meaning Preservation is our adaptation of QuestEval.
ASSET: A Dataset for Tuning and Evaluation of Sentence Simplification Models with Multiple Rewriting Transformations
May 01, 2020
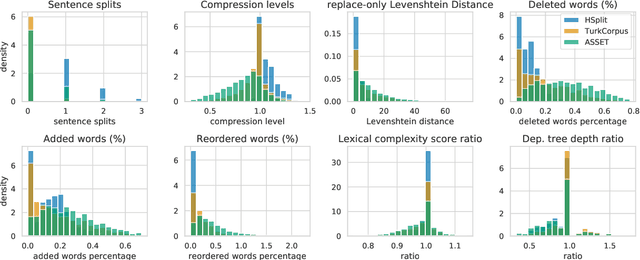
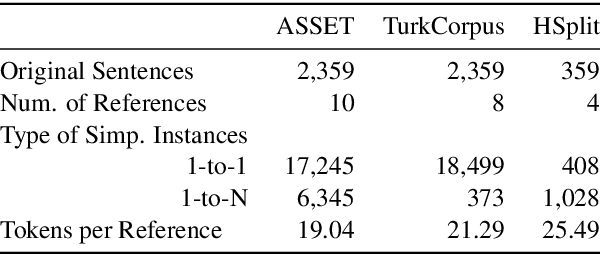
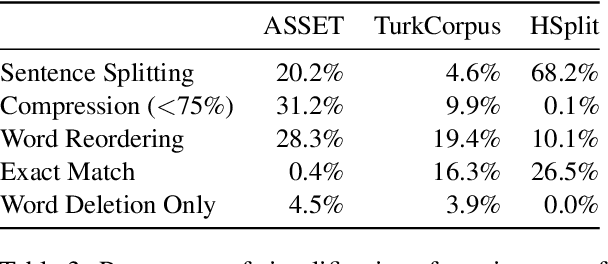
In order to simplify a sentence, human editors perform multiple rewriting transformations: they split it into several shorter sentences, paraphrase words (i.e. replacing complex words or phrases by simpler synonyms), reorder components, and/or delete information deemed unnecessary. Despite these varied range of possible text alterations, current models for automatic sentence simplification are evaluated using datasets that are focused on a single transformation, such as lexical paraphrasing or splitting. This makes it impossible to understand the ability of simplification models in more realistic settings. To alleviate this limitation, this paper introduces ASSET, a new dataset for assessing sentence simplification in English. ASSET is a crowdsourced multi-reference corpus where each simplification was produced by executing several rewriting transformations. Through quantitative and qualitative experiments, we show that simplifications in ASSET are better at capturing characteristics of simplicity when compared to other standard evaluation datasets for the task. Furthermore, we motivate the need for developing better methods for automatic evaluation using ASSET, since we show that current popular metrics may not be suitable when multiple simplification transformations are performed.
Multilingual Unsupervised Sentence Simplification
May 01, 2020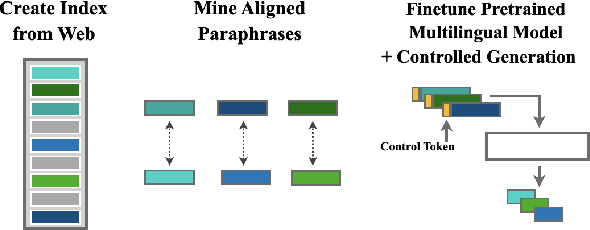

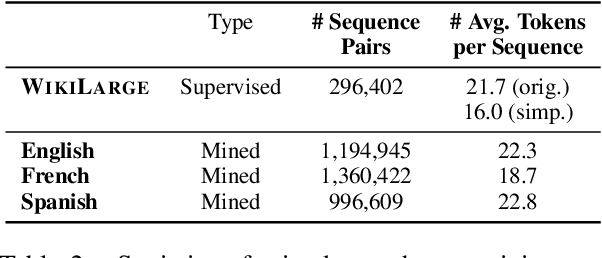
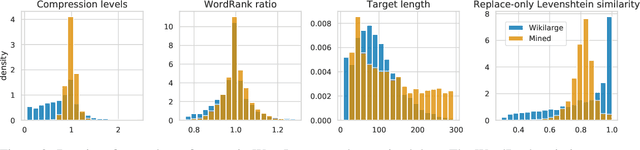
Progress in Sentence Simplification has been hindered by the lack of supervised data, particularly in languages other than English. Previous work has aligned sentences from original and simplified corpora such as English Wikipedia and Simple English Wikipedia, but this limits corpus size, domain, and language. In this work, we propose using unsupervised mining techniques to automatically create training corpora for simplification in multiple languages from raw Common Crawl web data. When coupled with a controllable generation mechanism that can flexibly adjust attributes such as length and lexical complexity, these mined paraphrase corpora can be used to train simplification systems in any language. We further incorporate multilingual unsupervised pretraining methods to create even stronger models and show that by training on mined data rather than supervised corpora, we outperform the previous best results. We evaluate our approach on English, French, and Spanish simplification benchmarks and reach state-of-the-art performance with a totally unsupervised approach. We will release our models and code to mine the data in any language included in Common Crawl.
CamemBERT: a Tasty French Language Model
Nov 10, 2019


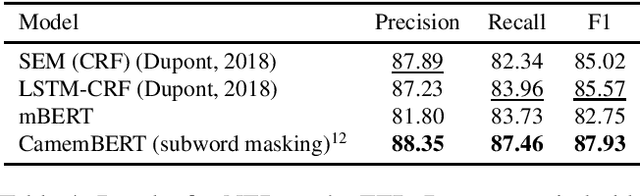
Pretrained language models are now ubiquitous in Natural Language Processing. Despite their success, most available models have either been trained on English data or on the concatenation of data in multiple languages. This makes practical use of such models --in all languages except English-- very limited. Aiming to address this issue for French, we release CamemBERT, a French version of the Bi-directional Encoders for Transformers (BERT). We measure the performance of CamemBERT compared to multilingual models in multiple downstream tasks, namely part-of-speech tagging, dependency parsing, named-entity recognition, and natural language inference. CamemBERT improves the state of the art for most of the tasks considered. We release the pretrained model for CamemBERT hoping to foster research and downstream applications for French NLP.
Controllable Sentence Simplification
Oct 16, 2019
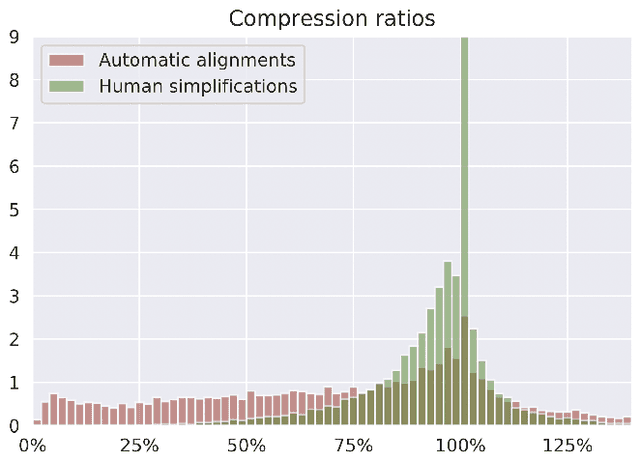

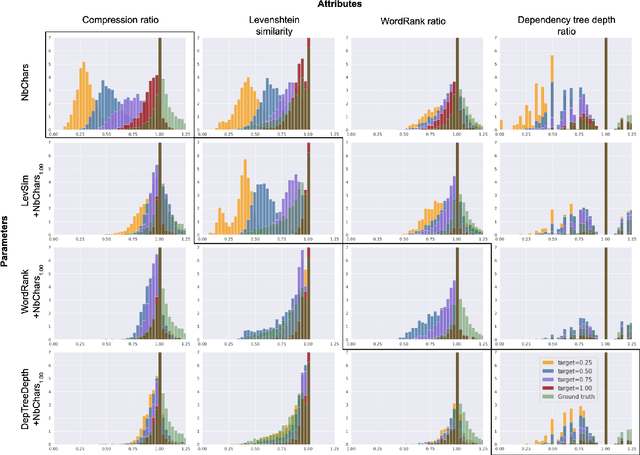
Text simplification aims at making a text easier to read and understand by simplifying grammar and structure while keeping the underlying information identical. It is often considered an all-purpose generic task where the same simplification is suitable for all; however multiple audiences can benefit from simplified text in different ways. We adapt a discrete parametrization mechanism that provides explicit control on simplification systems based on Sequence-to-Sequence models. As a result, users can condition the simplifications returned by a model on parameters such as length, amount of paraphrasing, lexical complexity and syntactic complexity. We also show that carefully chosen values of these parameters allow out-of-the-box Sequence-to-Sequence models to outperform their standard counterparts on simplification benchmarks. Our model, which we call ACCESS (as shorthand for AudienCe-CEntric Sentence Simplification), increases the state of the art to 41.87 SARI on the WikiLarge test set, a +1.42 gain over previously reported scores.