 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Unsupervised Learning for Plankton Images
Sep 14, 2022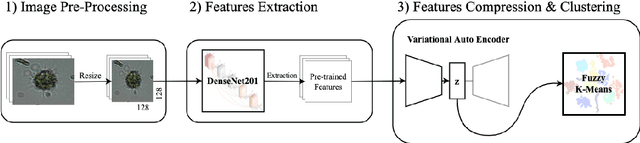

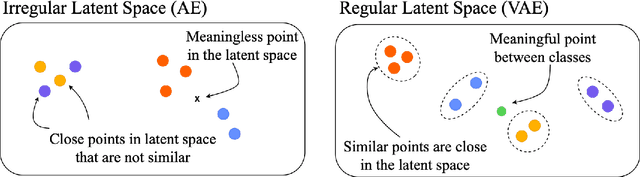

Monitoring plankton populations in situ is fundamental to preserve the aquatic ecosystem. Plankton microorganisms are in fact susceptible of minor environmental perturbations, that can reflect into consequent morphological and dynamical modifications. Nowadays, the availability of advanced automatic or semi-automatic acquisition systems has been allowing the production of an increasingly large amount of plankton image data. The adoption of machine learning algorithms to classify such data may be affected by the significant cost of manual annotation, due to both the huge quantity of acquired data and the numerosity of plankton species. To address these challenges, we propose an efficient unsupervised learning pipeline to provide accurate classification of plankton microorganisms. We build a set of image descriptors exploiting a two-step procedure. First, a Variational Autoencoder (VAE) is trained on features extracted by a pre-trained neural network. We then use the learnt latent space as image descriptor for clustering. We compare our method with state-of-the-art unsupervised approaches, where a set of pre-defined hand-crafted features is used for clustering of plankton images. The proposed pipeline outperforms the benchmark algorithms for all the plankton datasets included in our analysis, providing better image embedding properties.
Approximate Bayesian Neural Operators: Uncertainty Quantification for Parametric PDEs
Aug 02, 2022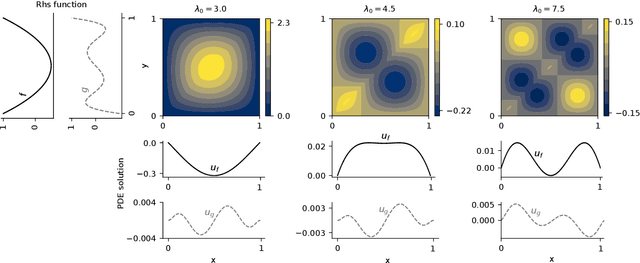
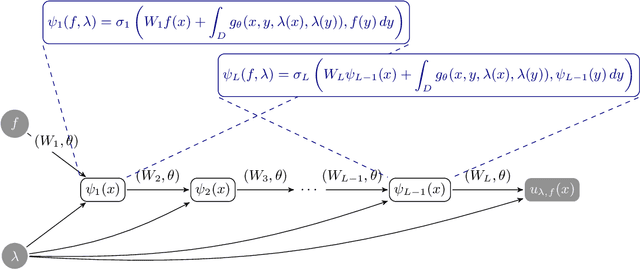
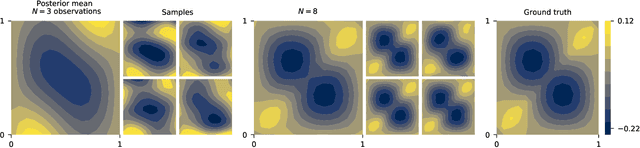
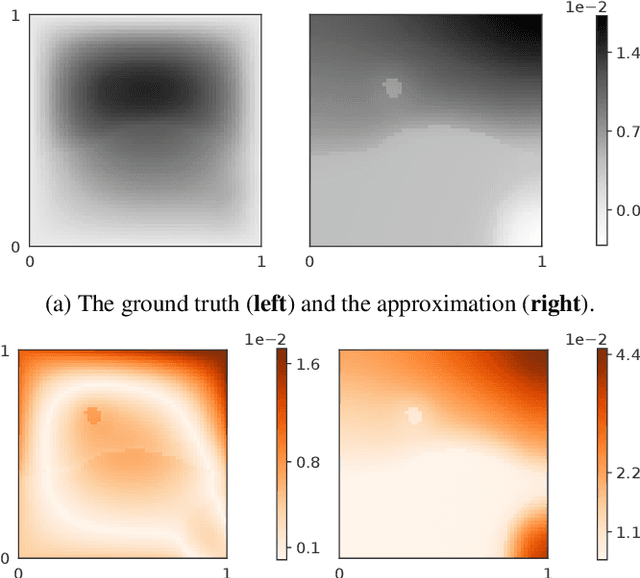
Neural operators are a type of deep architecture that learns to solve (i.e. learns the nonlinear solution operator of) partial differential equations (PDEs). The current state of the art for these models does not provide explicit uncertainty quantification. This is arguably even more of a problem for this kind of tasks than elsewhere in machine learning, because the dynamical systems typically described by PDEs often exhibit subtle, multiscale structure that makes errors hard to spot by humans. In this work, we first provide a mathematically detailed Bayesian formulation of the ''shallow'' (linear) version of neural operators in the formalism of Gaussian processes. We then extend this analytic treatment to general deep neural operators using approximate methods from Bayesian deep learning. We extend previous results on neural operators by providing them with uncertainty quantification. As a result, our approach is able to identify cases, and provide structured uncertainty estimates, where the neural operator fails to predict well.
Learn Fast, Segment Well: Fast Object Segmentation Learning on the iCub Robot
Jun 27, 2022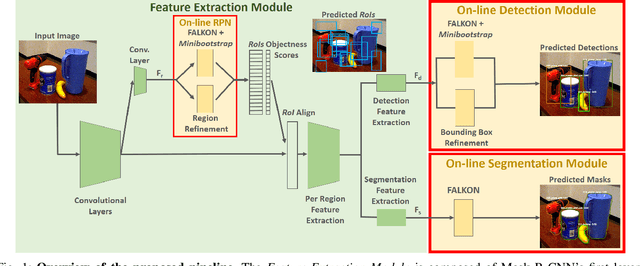

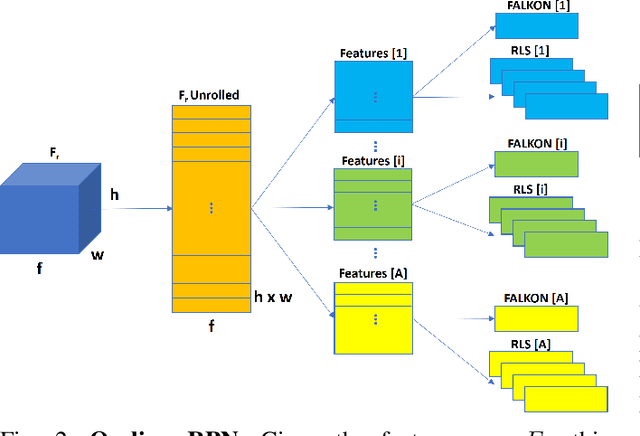

The visual system of a robot has different requirements depending on the application: it may require high accuracy or reliability, be constrained by limited resources or need fast adaptation to dynamically changing environments. In this work, we focus on the instance segmentation task and provide a comprehensive study of different techniques that allow adapting an object segmentation model in presence of novel objects or different domains. We propose a pipeline for fast instance segmentation learning designed for robotic applications where data come in stream. It is based on an hybrid method leveraging on a pre-trained CNN for feature extraction and fast-to-train Kernel-based classifiers. We also propose a training protocol that allows to shorten the training time by performing feature extraction during the data acquisition. We benchmark the proposed pipeline on two robotics datasets and we deploy it on a real robot, i.e. the iCub humanoid. To this aim, we adapt our method to an incremental setting in which novel objects are learned on-line by the robot. The code to reproduce the experiments is publicly available on GitHub.
Stochastic Zeroth order Descent with Structured Directions
Jun 10, 2022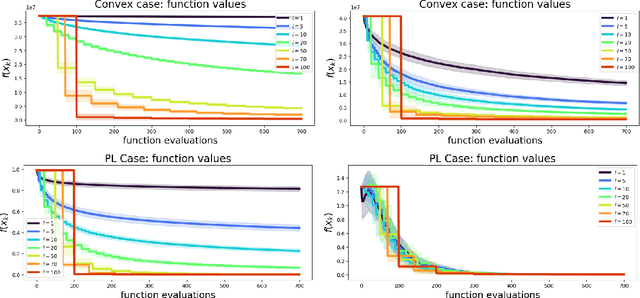
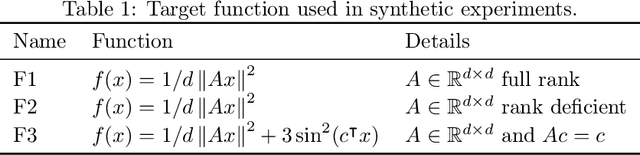
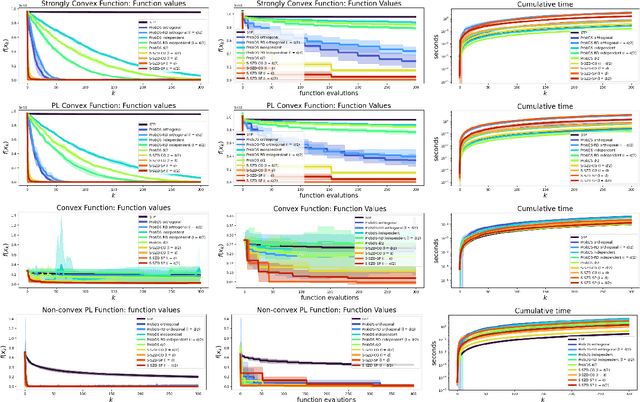
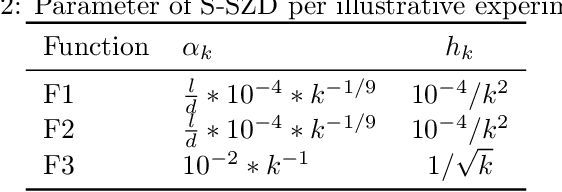
We introduce and analyze Structured Stochastic Zeroth order Descent (S-SZD), a finite difference approach which approximates a stochastic gradient on a set of $l\leq d$ orthogonal directions, where $d$ is the dimension of the ambient space. These directions are randomly chosen, and may change at each step. For smooth convex functions we prove almost sure convergence of the iterates and a convergence rate on the function values of the form $O(d/l k^{-c})$ for every $c<1/2$, which is arbitrarily close to the one of Stochastic Gradient Descent (SGD) in terms of number of iterations. Our bound also shows the benefits of using $l$ multiple directions instead of one. For non-convex functions satisfying the Polyak-{\L}ojasiewicz condition, we establish the first convergence rates for stochastic zeroth order algorithms under such an assumption. We corroborate our theoretical findings in numerical simulations where assumptions are satisfied and on the real-world problem of hyper-parameter optimization, observing that S-SZD has very good practical performances.
AdaTask: Adaptive Multitask Online Learning
May 31, 2022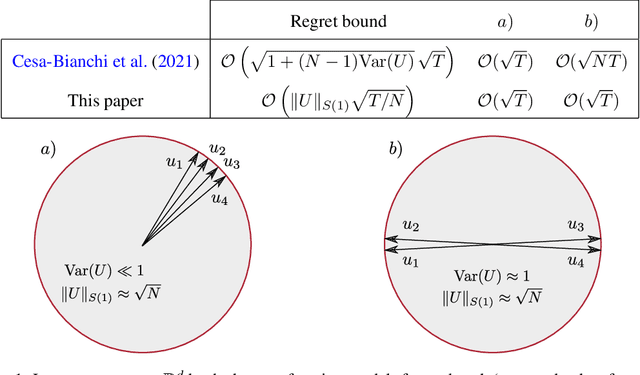
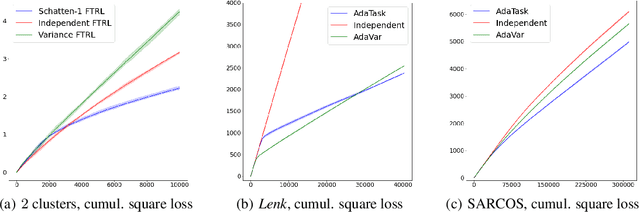
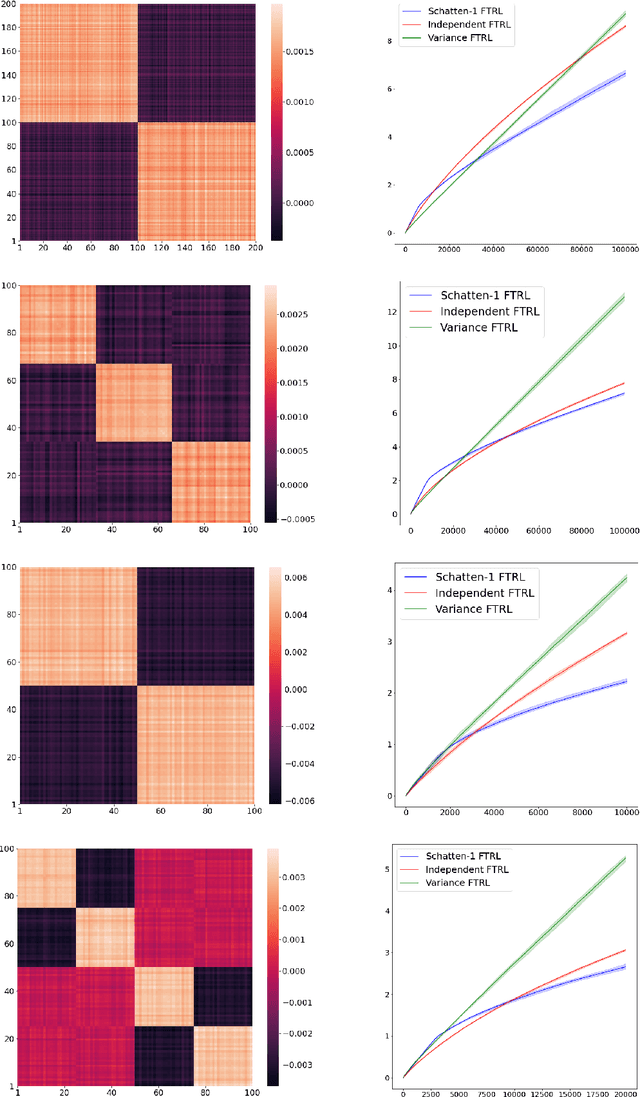
We introduce and analyze AdaTask, a multitask online learning algorithm that adapts to the unknown structure of the tasks. When the $N$ tasks are stochastically activated, we show that the regret of AdaTask is better, by a factor that can be as large as $\sqrt{N}$, than the regret achieved by running $N$ independent algorithms, one for each task. AdaTask can be seen as a comparator-adaptive version of Follow-the-Regularized-Leader with a Mahalanobis norm potential. Through a variational formulation of this potential, our analysis reveals how AdaTask jointly learns the tasks and their structure. Experiments supporting our findings are presented.
Learning Dynamical Systems via Koopman Operator Regression in Reproducing Kernel Hilbert Spaces
May 27, 2022

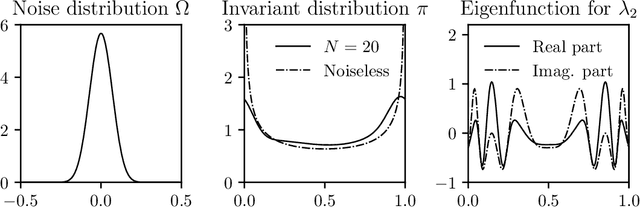
We study a class of dynamical systems modelled as Markov chains that admit an invariant distribution via the corresponding transfer, or Koopman, operator. While data-driven algorithms to reconstruct such operators are well known, their relationship with statistical learning is largely unexplored. We formalize a framework to learn the Koopman operator from finite data trajectories of the dynamical system. We consider the restriction of this operator to a reproducing kernel Hilbert space and introduce a notion of risk, from which different estimators naturally arise. We link the risk with the estimation of the spectral decomposition of the Koopman operator. These observations motivate a reduced-rank operator regression (RRR) estimator. We derive learning bounds for the proposed estimator, holding both in i.i.d. and non i.i.d. settings, the latter in terms of mixing coefficients. Our results suggest RRR might be beneficial over other widely used estimators as confirmed in numerical experiments both for forecasting and mode decomposition.
Learning new physics efficiently with nonparametric methods
Apr 05, 2022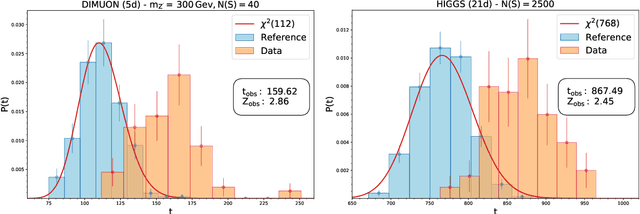
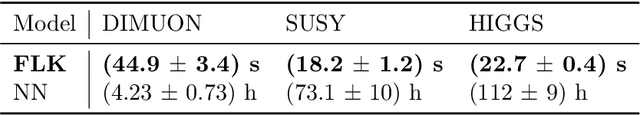
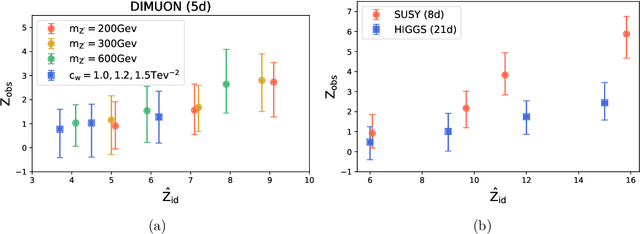

We present a machine learning approach for model-independent new physics searches. The corresponding algorithm is powered by recent large-scale implementations of kernel methods, nonparametric learning algorithms that can approximate any continuous function given enough data. Based on the original proposal by D'Agnolo and Wulzer (arXiv:1806.02350), the model evaluates the compatibility between experimental data and a reference model, by implementing a hypothesis testing procedure based on the likelihood ratio. Model-independence is enforced by avoiding any prior assumption about the presence or shape of new physics components in the measurements. We show that our approach has dramatic advantages compared to neural network implementations in terms of training times and computational resources, while maintaining comparable performances. In particular, we conduct our tests on higher dimensional datasets, a step forward with respect to previous studies.
Physics Informed Shallow Machine Learning for Wind Speed Prediction
Apr 01, 2022
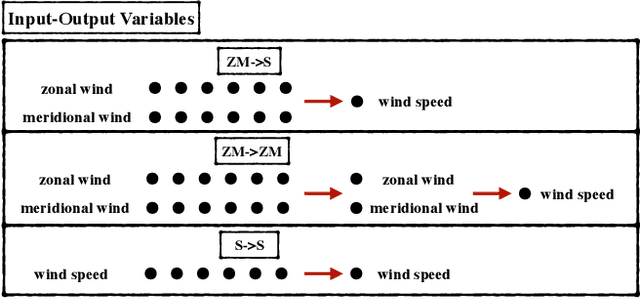
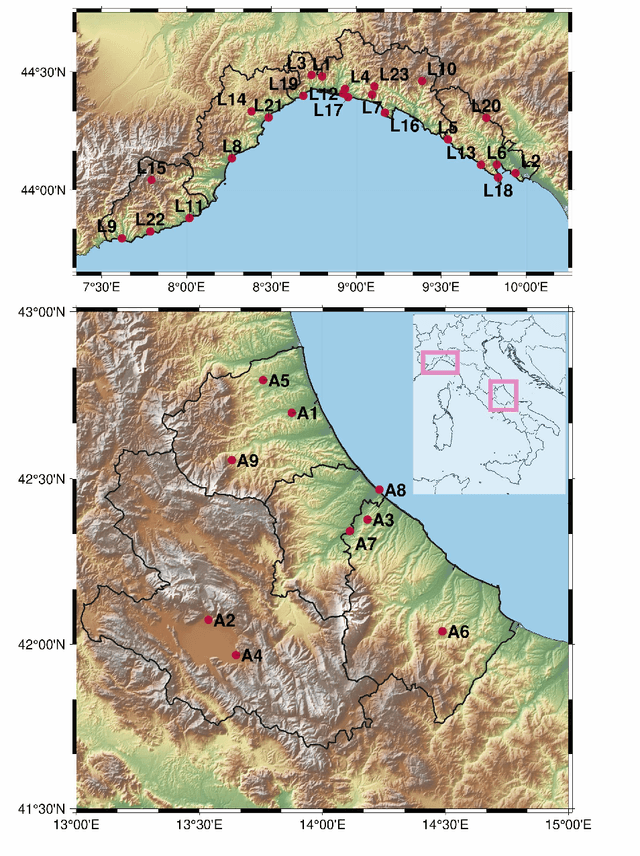
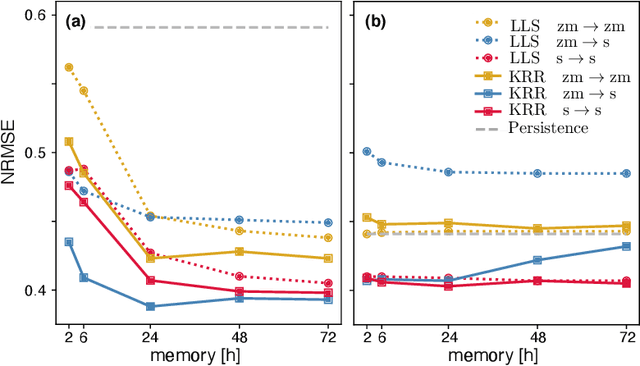
The ability to predict wind is crucial for both energy production and weather forecasting. Mechanistic models that form the basis of traditional forecasting perform poorly near the ground. In this paper, we take an alternative data-driven approach based on supervised learning. We analyze a massive dataset of wind measured from anemometers located at 10 m height in 32 locations in two central and north west regions of Italy (Abruzzo and Liguria). We train supervised learning algorithms using the past history of wind to predict its value at a future time (horizon). Using data from a single location and time horizon we compare systematically several algorithms where we vary the input/output variables, the memory of the input and the linear vs non-linear learning model. We then compare performance of the best algorithms across all locations and forecasting horizons. We find that the optimal design as well as its performance vary with the location. We demonstrate that the presence of a reproducible diurnal cycle provides a rationale to understand this variation. We conclude with a systematic comparison with state of the art algorithms and show that, when the model is accurately designed, shallow algorithms are competitive with more complex deep architectures.
An elementary analysis of ridge regression with random design
Mar 16, 2022In this short note, we present an elementary analysis of the prediction error of ridge regression with random design. The proof is short and self-contained. In particular, it avoids matrix concentration or control of empirical processes, by using a simple combination of exchangeability arguments, matrix identities and operator convexity.
Multiclass learning with margin: exponential rates with no bias-variance trade-off
Feb 03, 2022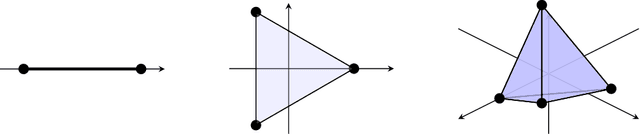

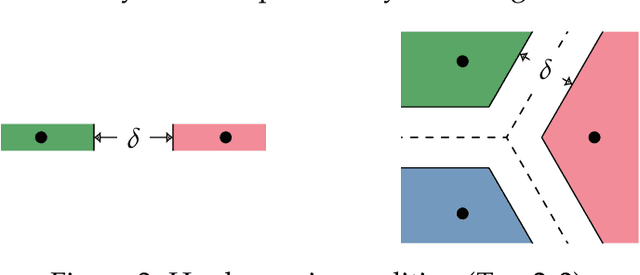
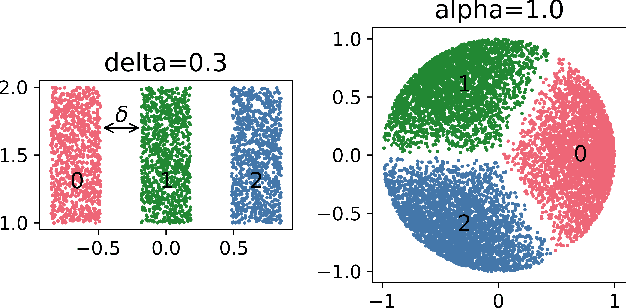
We study the behavior of error bounds for multiclass classification under suitable margin conditions. For a wide variety of methods we prove that the classification error under a hard-margin condition decreases exponentially fast without any bias-variance trade-off. Different convergence rates can be obtained in correspondence of different margin assumptions. With a self-contained and instructive analysis we are able to generalize known results from the binary to the multiclass setting.