 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Weak-to-Strong Consistency in Semi-Supervised Semantic Segmentation
Aug 21, 2022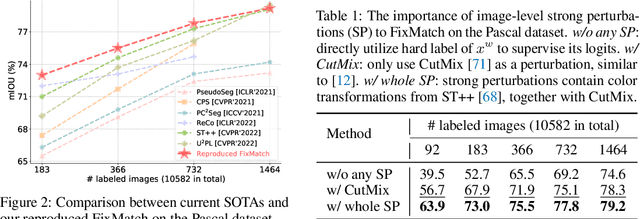
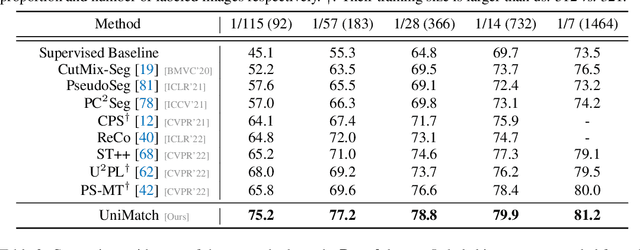

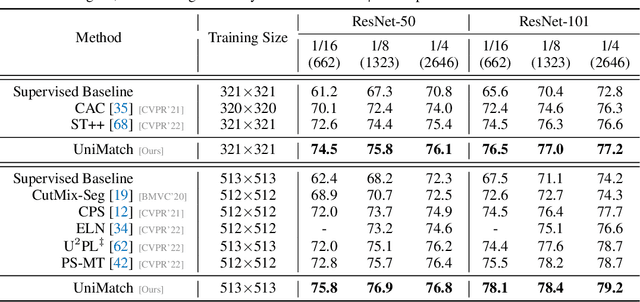
In this work, we revisit the weak-to-strong consistency framework, popularized by FixMatch from semi-supervised classification, where the prediction of a weakly perturbed image serves as supervision for its strongly perturbed version. Intriguingly, we observe that such a simple pipeline already achieves competitive results against recent advanced works, when transferred to our segmentation scenario. Its success heavily relies on the manual design of strong data augmentations, however, which may be limited and inadequate to explore a broader perturbation space. Motivated by this, we propose an auxiliary feature perturbation stream as a supplement, leading to an expanded perturbation space. On the other, to sufficiently probe original image-level augmentations, we present a dual-stream perturbation technique, enabling two strong views to be simultaneously guided by a common weak view. Consequently, our overall Unified Dual-Stream Perturbations approach (UniMatch) surpasses all existing methods significantly across all evaluation protocols on the Pascal, Cityscapes, and COCO benchmarks. We also demonstrate the superiority of our method in remote sensing interpretation and medical image analysis. Code is available at https://github.com/LiheYoung/UniMatch.
ViM: Out-Of-Distribution with Virtual-logit Matching
Mar 21, 2022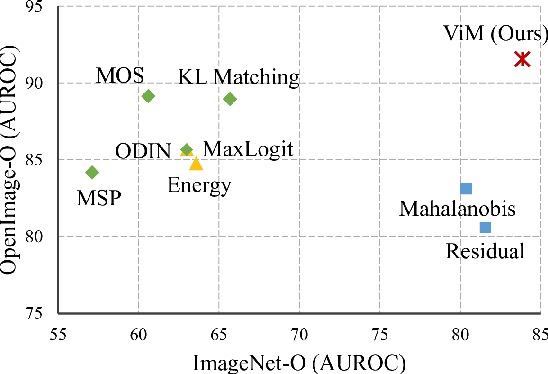

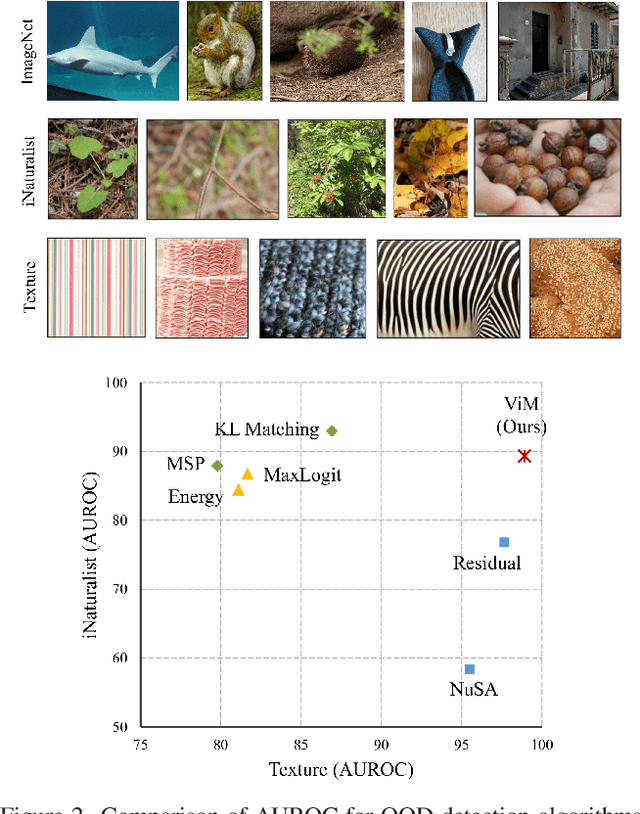
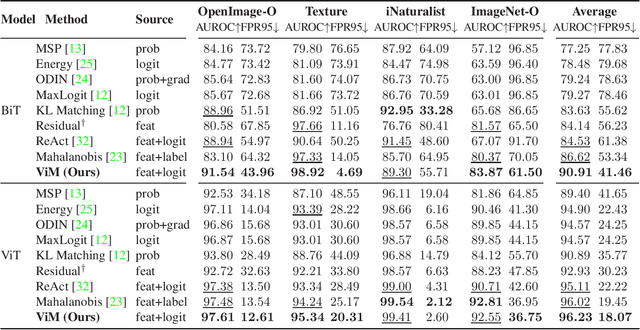
Most of the existing Out-Of-Distribution (OOD) detection algorithms depend on single input source: the feature, the logit, or the softmax probability. However, the immense diversity of the OOD examples makes such methods fragile. There are OOD samples that are easy to identify in the feature space while hard to distinguish in the logit space and vice versa. Motivated by this observation, we propose a novel OOD scoring method named Virtual-logit Matching (ViM), which combines the class-agnostic score from feature space and the In-Distribution (ID) class-dependent logits. Specifically, an additional logit representing the virtual OOD class is generated from the residual of the feature against the principal space, and then matched with the original logits by a constant scaling. The probability of this virtual logit after softmax is the indicator of OOD-ness. To facilitate the evaluation of large-scale OOD detection in academia, we create a new OOD dataset for ImageNet-1K, which is human-annotated and is 8.8x the size of existing datasets. We conducted extensive experiments, including CNNs and vision transformers, to demonstrate the effectiveness of the proposed ViM score. In particular, using the BiT-S model, our method gets an average AUROC 90.91% on four difficult OOD benchmarks, which is 4% ahead of the best baseline. Code and dataset are available at https://github.com/haoqiwang/vim.
Semantically Coherent Out-of-Distribution Detection
Aug 26, 2021
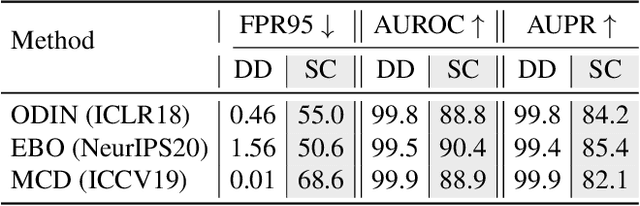
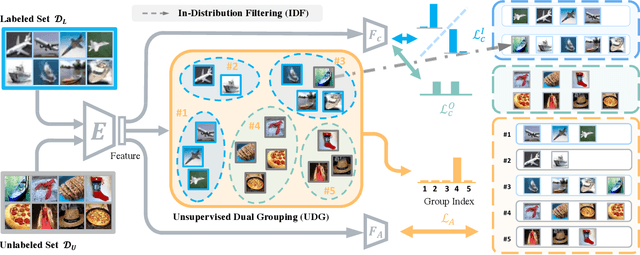
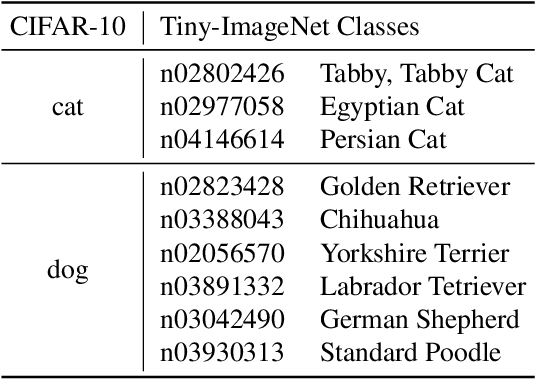
Current out-of-distribution (OOD) detection benchmarks are commonly built by defining one dataset as in-distribution (ID) and all others as OOD. However, these benchmarks unfortunately introduce some unwanted and impractical goals, e.g., to perfectly distinguish CIFAR dogs from ImageNet dogs, even though they have the same semantics and negligible covariate shifts. These unrealistic goals will result in an extremely narrow range of model capabilities, greatly limiting their use in real applications. To overcome these drawbacks, we re-design the benchmarks and propose the semantically coherent out-of-distribution detection (SC-OOD). On the SC-OOD benchmarks, existing methods suffer from large performance degradation, suggesting that they are extremely sensitive to low-level discrepancy between data sources while ignoring their inherent semantics. To develop an effective SC-OOD detection approach, we leverage an external unlabeled set and design a concise framework featured by unsupervised dual grouping (UDG) for the joint modeling of ID and OOD data. The proposed UDG can not only enrich the semantic knowledge of the model by exploiting unlabeled data in an unsupervised manner, but also distinguish ID/OOD samples to enhance ID classification and OOD detection tasks simultaneously. Extensive experiments demonstrate that our approach achieves state-of-the-art performance on SC-OOD benchmarks. Code and benchmarks are provided on our project page: https://jingkang50.github.io/projects/scood.
Progressive Representative Labeling for Deep Semi-Supervised Learning
Aug 13, 2021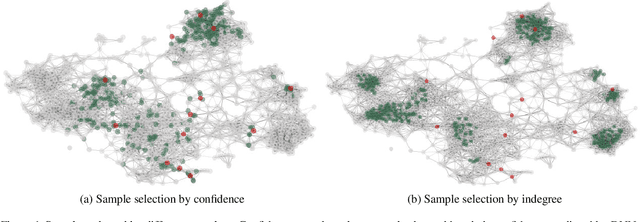

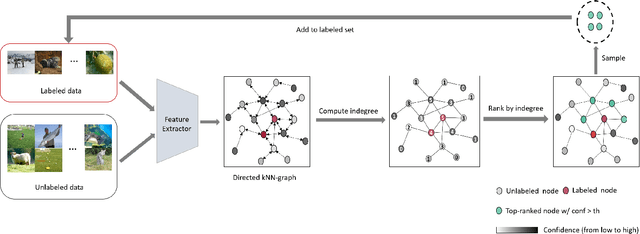
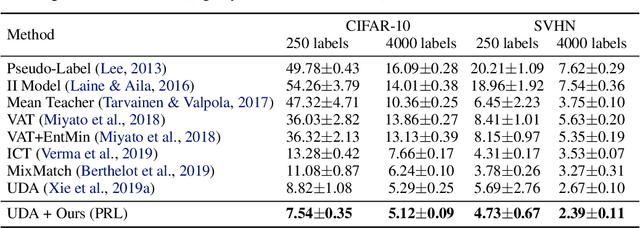
Deep semi-supervised learning (SSL) has experienced significant attention in recent years, to leverage a huge amount of unlabeled data to improve the performance of deep learning with limited labeled data. Pseudo-labeling is a popular approach to expand the labeled dataset. However, whether there is a more effective way of labeling remains an open problem. In this paper, we propose to label only the most representative samples to expand the labeled set. Representative samples, selected by indegree of corresponding nodes on a directed k-nearest neighbor (kNN) graph, lie in the k-nearest neighborhood of many other samples. We design a graph neural network (GNN) labeler to label them in a progressive learning manner. Aided by the progressive GNN labeler, our deep SSL approach outperforms state-of-the-art methods on several popular SSL benchmarks including CIFAR-10, SVHN, and ILSVRC-2012. Notably, we achieve 72.1% top-1 accuracy, surpassing the previous best result by 3.3%, on the challenging ImageNet benchmark with only $10\%$ labeled data.
Webly Supervised Image Classification with Metadata: Automatic Noisy Label Correction via Visual-Semantic Graph
Oct 12, 2020
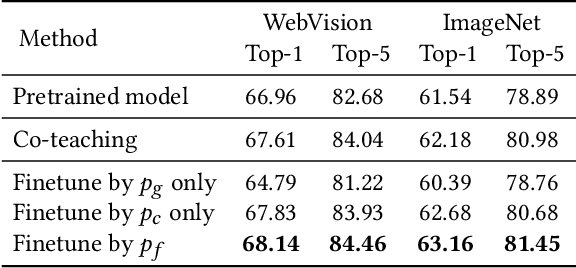
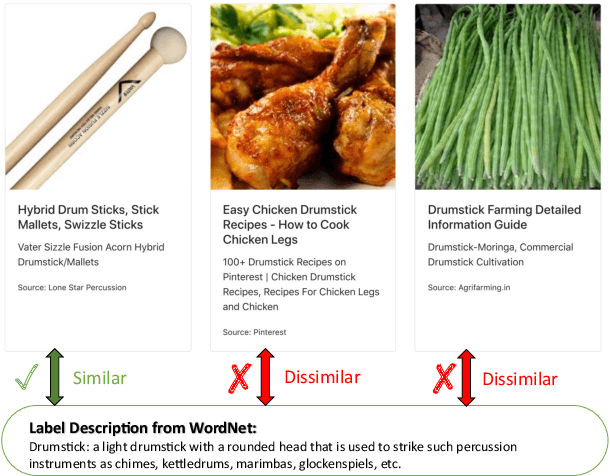
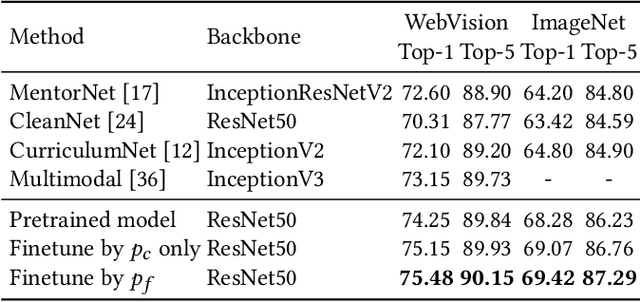
Webly supervised learning becomes attractive recently for its efficiency in data expansion without expensive human labeling. However, adopting search queries or hashtags as web labels of images for training brings massive noise that degrades the performance of DNNs. Especially, due to the semantic confusion of query words, the images retrieved by one query may contain tremendous images belonging to other concepts. For example, searching `tiger cat' on Flickr will return a dominating number of tiger images rather than the cat images. These realistic noisy samples usually have clear visual semantic clusters in the visual space that mislead DNNs from learning accurate semantic labels. To correct real-world noisy labels, expensive human annotations seem indispensable. Fortunately, we find that metadata can provide extra knowledge to discover clean web labels in a labor-free fashion, making it feasible to automatically provide correct semantic guidance among the massive label-noisy web data. In this paper, we propose an automatic label corrector VSGraph-LC based on the visual-semantic graph. VSGraph-LC starts from anchor selection referring to the semantic similarity between metadata and correct label concepts, and then propagates correct labels from anchors on a visual graph using graph neural network (GNN). Experiments on realistic webly supervised learning datasets Webvision-1000 and NUS-81-Web show the effectiveness and robustness of VSGraph-LC. Moreover, VSGraph-LC reveals its advantage on the open-set validation set.
Webly Supervised Image Classification with Self-Contained Confidence
Aug 27, 2020
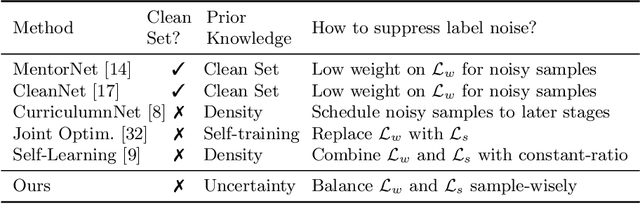
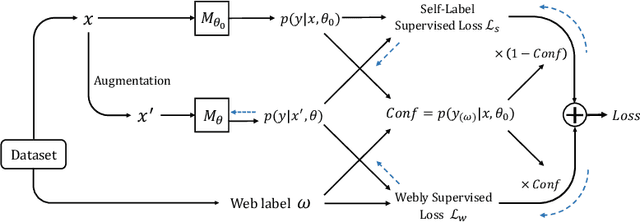
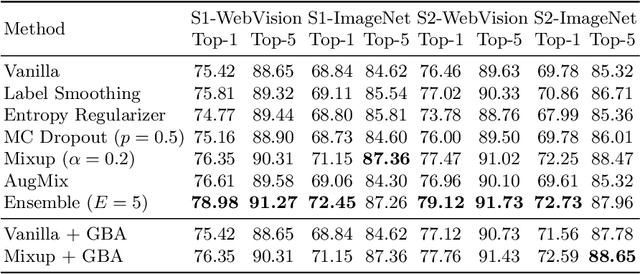
This paper focuses on webly supervised learning (WSL), where datasets are built by crawling samples from the Internet and directly using search queries as web labels. Although WSL benefits from fast and low-cost data collection, noises in web labels hinder better performance of the image classification model. To alleviate this problem, in recent works, self-label supervised loss $\mathcal{L}_s$ is utilized together with webly supervised loss $\mathcal{L}_w$. $\mathcal{L}_s$ relies on pseudo labels predicted by the model itself. Since the correctness of the web label or pseudo label is usually on a case-by-case basis for each web sample, it is desirable to adjust the balance between $\mathcal{L}_s$ and $\mathcal{L}_w$ on sample level. Inspired by the ability of Deep Neural Networks (DNNs) in confidence prediction, we introduce Self-Contained Confidence (SCC) by adapting model uncertainty for WSL setting, and use it to sample-wisely balance $\mathcal{L}_s$ and $\mathcal{L}_w$. Therefore, a simple yet effective WSL framework is proposed. A series of SCC-friendly regularization approaches are investigated, among which the proposed graph-enhanced mixup is the most effective method to provide high-quality confidence to enhance our framework. The proposed WSL framework has achieved the state-of-the-art results on two large-scale WSL datasets, WebVision-1000 and Food101-N. Code is available at https://github.com/bigvideoresearch/SCC.
Scale-Equalizing Pyramid Convolution for Object Detection
May 06, 2020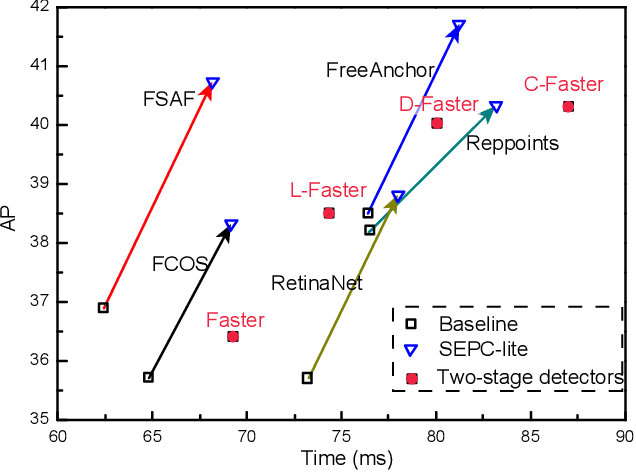
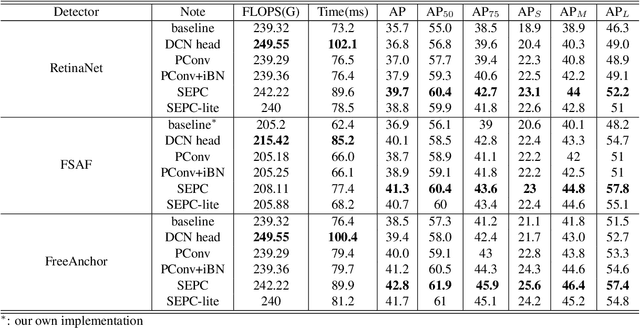
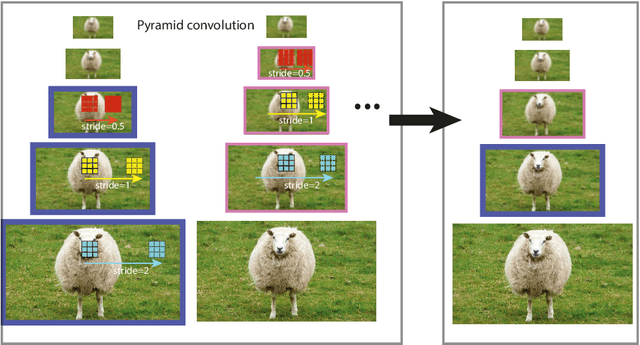
Feature pyramid has been an efficient method to extract features at different scales. Development over this method mainly focuses on aggregating contextual information at different levels while seldom touching the inter-level correlation in the feature pyramid. Early computer vision methods extracted scale-invariant features by locating the feature extrema in both spatial and scale dimension. Inspired by this, a convolution across the pyramid level is proposed in this study, which is termed pyramid convolution and is a modified 3-D convolution. Stacked pyramid convolutions directly extract 3-D (scale and spatial) features and outperforms other meticulously designed feature fusion modules. Based on the viewpoint of 3-D convolution, an integrated batch normalization that collects statistics from the whole feature pyramid is naturally inserted after the pyramid convolution. Furthermore, we also show that the naive pyramid convolution, together with the design of RetinaNet head, actually best applies for extracting features from a Gaussian pyramid, whose properties can hardly be satisfied by a feature pyramid. In order to alleviate this discrepancy, we build a scale-equalizing pyramid convolution (SEPC) that aligns the shared pyramid convolution kernel only at high-level feature maps. Being computationally efficient and compatible with the head design of most single-stage object detectors, the SEPC module brings significant performance improvement ($>4$AP increase on MS-COCO2017 dataset) in state-of-the-art one-stage object detectors, and a light version of SEPC also has $\sim3.5$AP gain with only around 7% inference time increase. The pyramid convolution also functions well as a stand-alone module in two-stage object detectors and is able to improve the performance by $\sim2$AP. The source code can be found at https://github.com/jshilong/SEPC.
How Does BN Increase Collapsed Neural Network Filters?
Jan 31, 2020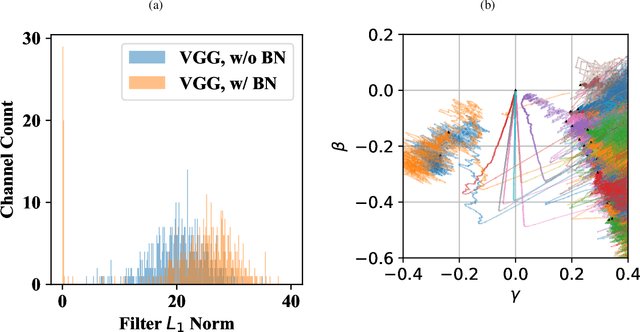

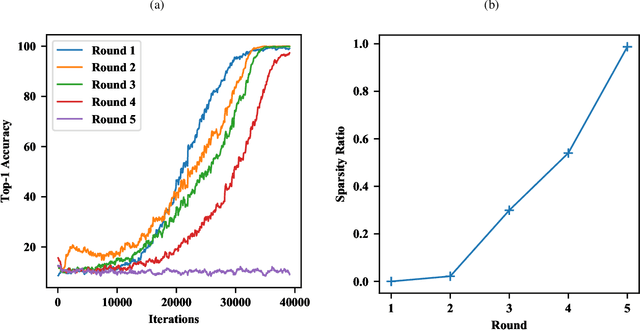
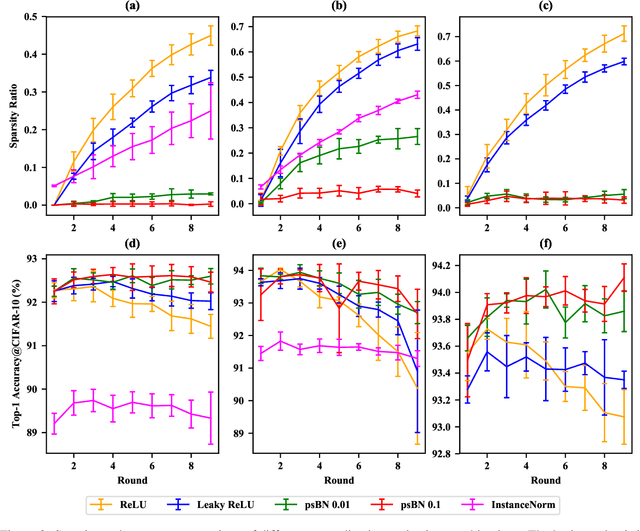
Improving sparsity of deep neural networks (DNNs) is essential for network compression and has drawn much attention. In this work, we disclose a harmful sparsifying process called filter collapse, which is common in DNNs with batch normalization (BN) and rectified linear activation functions (e.g. ReLU, Leaky ReLU). It occurs even without explicit sparsity-inducing regularizations such as $L_1$. This phenomenon is caused by the normalization effect of BN, which induces a non-trainable region in the parameter space and reduces the network capacity as a result. This phenomenon becomes more prominent when the network is trained with large learning rates (LR) or adaptive LR schedulers, and when the network is finetuned. We analytically prove that the parameters of BN tend to become sparser during SGD updates with high gradient noise and that the sparsifying probability is proportional to the square of learning rate and inversely proportional to the square of the scale parameter of BN. To prevent the undesirable collapsed filters, we propose a simple yet effective approach named post-shifted BN (psBN), which has the same representation ability as BN while being able to automatically make BN parameters trainable again as they saturate during training. With psBN, we can recover collapsed filters and increase the model performance in various tasks such as classification on CIFAR-10 and object detection on MS-COCO2017.
Gradual Network for Single Image De-raining
Sep 20, 2019
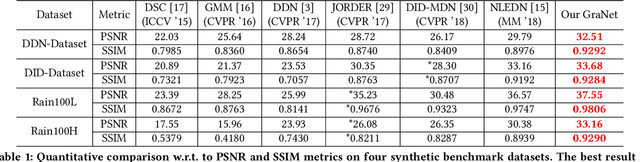
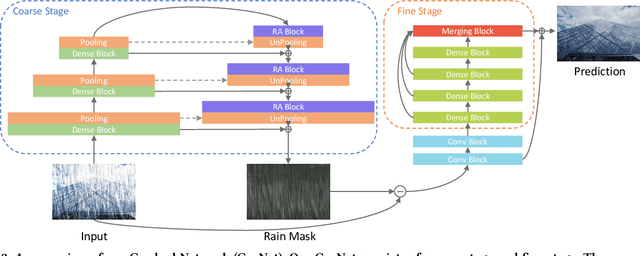
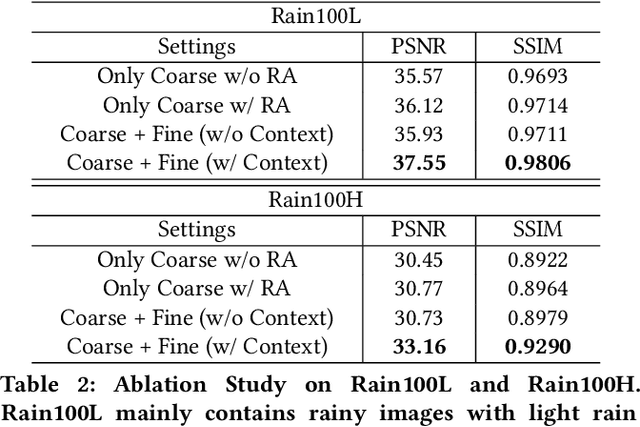
Most advances in single image de-raining meet a key challenge, which is removing rain streaks with different scales and shapes while preserving image details. Existing single image de-raining approaches treat rain-streak removal as a process of pixel-wise regression directly. However, they are lacking in mining the balance between over-de-raining (e.g. removing texture details in rain-free regions) and under-de-raining (e.g. leaving rain streaks). In this paper, we firstly propose a coarse-to-fine network called Gradual Network (GraNet) consisting of coarse stage and fine stage for delving into single image de-raining with different granularities. Specifically, to reveal coarse-grained rain-streak characteristics (e.g. long and thick rain streaks/raindrops), we propose a coarse stage by utilizing local-global spatial dependencies via a local-global subnetwork composed of region-aware blocks. Taking the residual result (the coarse de-rained result) between the rainy image sample (i.e. the input data) and the output of coarse stage (i.e. the learnt rain mask) as input, the fine stage continues to de-rain by removing the fine-grained rain streaks (e.g. light rain streaks and water mist) to get a rain-free and well-reconstructed output image via a unified contextual merging sub-network with dense blocks and a merging block. Solid and comprehensive experiments on synthetic and real data demonstrate that our GraNet can significantly outperform the state-of-the-art methods by removing rain streaks with various densities, scales and shapes while keeping the image details of rain-free regions well-preserved.
Learning Efficient Detector with Semi-supervised Adaptive Distillation
Jan 14, 2019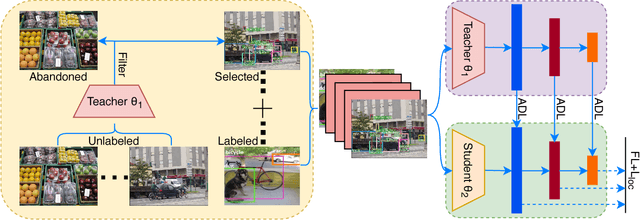
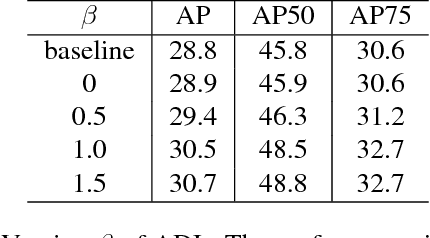
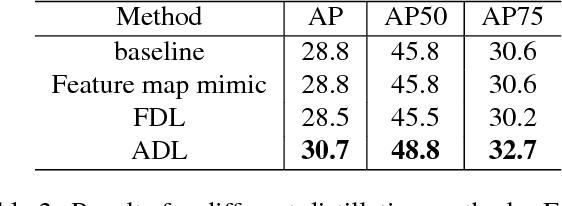
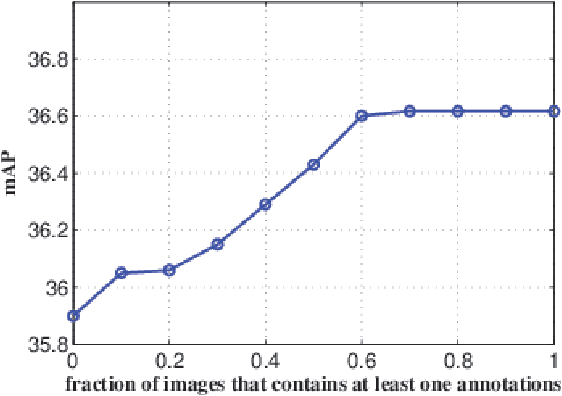
Knowledge Distillation (KD) has been used in image classification for model compression. However, rare studies apply this technology on single-stage object detectors. Focal loss shows that the accumulated errors of easily-classified samples dominate the overall loss in the training process. This problem is also encountered when applying KD in the detection task. For KD, the teacher-defined hard samples are far more important than any others. We propose ADL to address this issue by adaptively mimicking the teacher's logits, with more attention paid on two types of hard samples: hard-to-learn samples predicted by teacher with low certainty and hard-to-mimic samples with a large gap between the teacher's and the student's prediction. ADL enlarges the distillation loss for hard-to-learn and hard-to-mimic samples and reduces distillation loss for the dominant easy samples, enabling distillation to work on the single-stage detector first time, even if the student and the teacher are identical. Besides, ADL is effective in both the supervised setting and the semi-supervised setting, even when the labeled data and unlabeled data are from different distributions. For distillation on unlabeled data, ADL achieves better performance than existing data distillation which simply utilizes hard targets, making the student detector surpass its teacher. On the COCO database, semi-supervised adaptive distillation (SAD) makes a student detector with a backbone of ResNet-50 surpasses its teacher with a backbone of ResNet-101, while the student has half of the teacher's computation complexity. The code is avaiable at https://github.com/Tangshitao/Semi-supervised-Adaptive-Distillation