 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperFair: A Soft Approach to Integrating Fairness Criteria
Sep 05, 2020

Recommender systems are being employed across an increasingly diverse set of domains that can potentially make a significant social and individual impact. For this reason, considering fairness is a critical step in the design and evaluation of such systems. In this paper, we introduce HyperFair, a general framework for enforcing soft fairness constraints in a hybrid recommender system. HyperFair models integrate variations of fairness metrics as a regularization of a joint inference objective function. We implement our approach using probabilistic soft logic and show that it is particularly well-suited for this task as it is expressive and structural constraints can be added to the system in a concise and interpretable manner. We propose two ways to employ the methods we introduce: first as an extension of a probabilistic soft logic recommender system template; second as a fair retrofitting technique that can be used to improve the fairness of predictions from a black-box model. We empirically validate our approach by implementing multiple HyperFair hybrid recommenders and compare them to a state-of-the-art fair recommender. We also run experiments showing the effectiveness of our methods for the task of retrofitting a black-box model and the trade-off between the amount of fairness enforced and the prediction performance.
Causal Relational Learning
Apr 07, 2020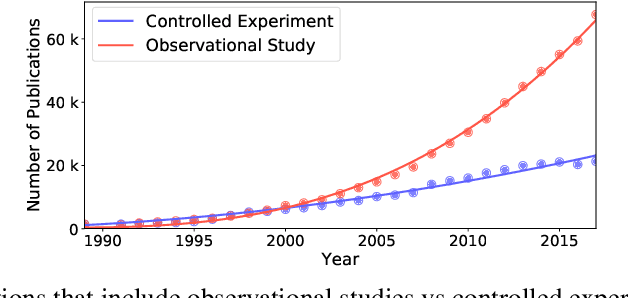



Causal inference is at the heart of empirical research in natural and social sciences and is critical for scientific discovery and informed decision making. The gold standard in causal inference is performing randomized controlled trials; unfortunately these are not always feasible due to ethical, legal, or cost constraints. As an alternative, methodologies for causal inference from observational data have been developed in statistical studies and social sciences. However, existing methods critically rely on restrictive assumptions such as the study population consisting of homogeneous elements that can be represented in a single flat table, where each row is referred to as a unit. In contrast, in many real-world settings, the study domain naturally consists of heterogeneous elements with complex relational structure, where the data is naturally represented in multiple related tables. In this paper, we present a formal framework for causal inference from such relational data. We propose a declarative language called CaRL for capturing causal background knowledge and assumptions and specifying causal queries using simple Datalog-like rules.CaRL provides a foundation for inferring causality and reasoning about the effect of complex interventions in relational domains. We present an extensive experimental evaluation on real relational data to illustrate the applicability of CaRL in social sciences and healthcare.
Estimating Aggregate Properties In Relational Networks With Unobserved Data
Jan 27, 2020
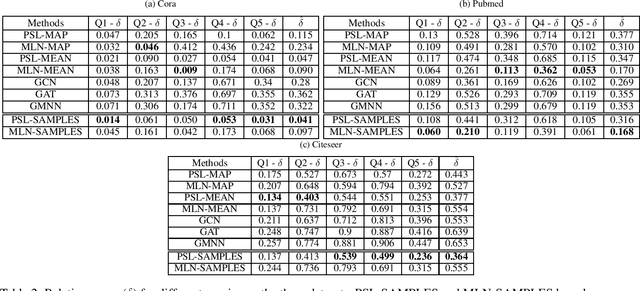
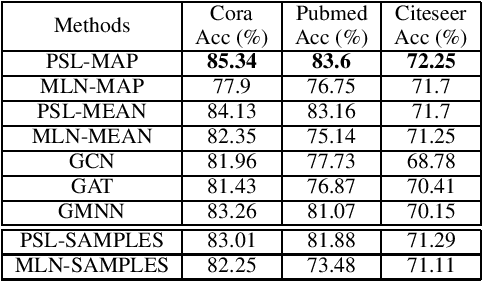
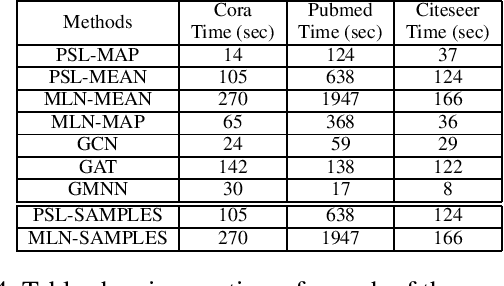
Aggregate network properties such as cluster cohesion and the number of bridge nodes can be used to glean insights about a network's community structure, spread of influence and the resilience of the network to faults. Efficiently computing network properties when the network is fully observed has received significant attention (Wasserman and Faust 1994; Cook and Holder 2006), however the problem of computing aggregate network properties when there is missing data attributes has received little attention. Computing these properties for networks with missing attributes involves performing inference over the network. Statistical relational learning (SRL) and graph neural networks (GNNs) are two classes of machine learning approaches well suited for inferring missing attributes in a graph. In this paper, we study the effectiveness of these approaches in estimating aggregate properties on networks with missing attributes. We compare two SRL approaches and three GNNs. For these approaches we estimate these properties using point estimates such as MAP and mean. For SRL-based approaches that can infer a joint distribution over the missing attributes, we also estimate these properties as an expectation over the distribution. To compute the expectation tractably for probabilistic soft logic, one of the SRL approaches that we study, we introduce a novel sampling framework. In the experimental evaluation, using three benchmark datasets, we show that SRL-based approaches tend to outperform GNN-based approaches both in computing aggregate properties and predictive accuracy. Specifically, we show that estimating the aggregate properties as an expectation over the joint distribution outperforms point estimates.
User Profiling Using Hinge-loss Markov Random Fields
Jan 05, 2020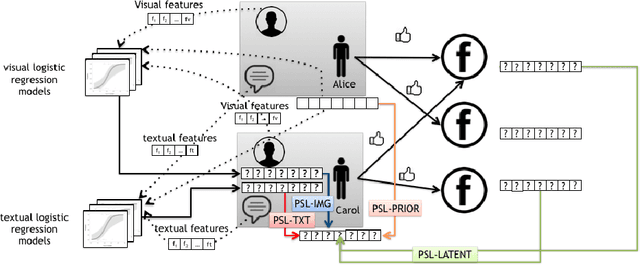
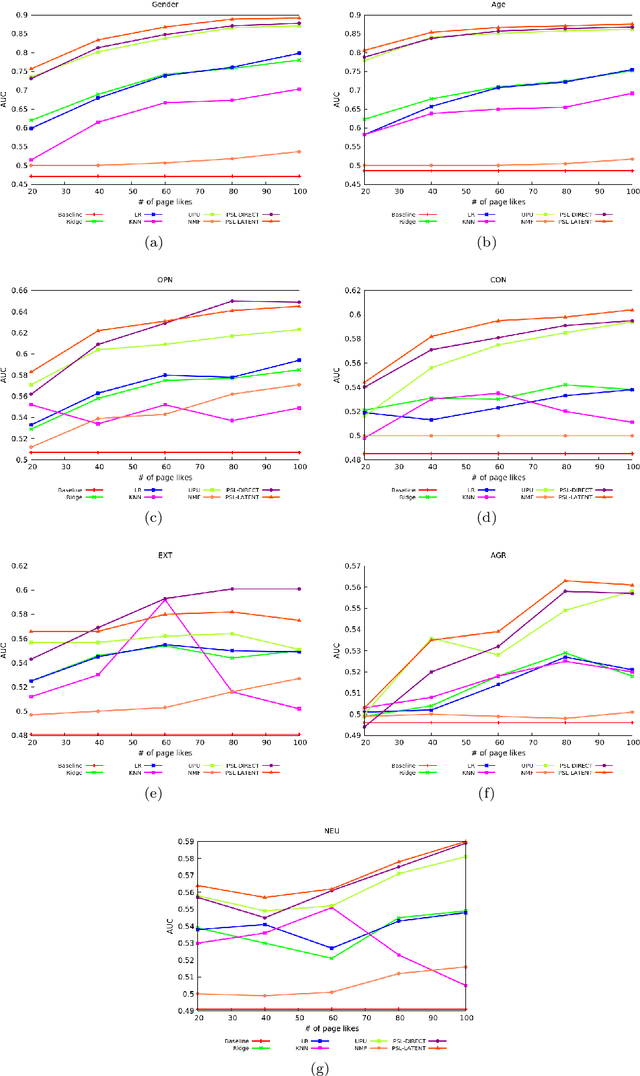
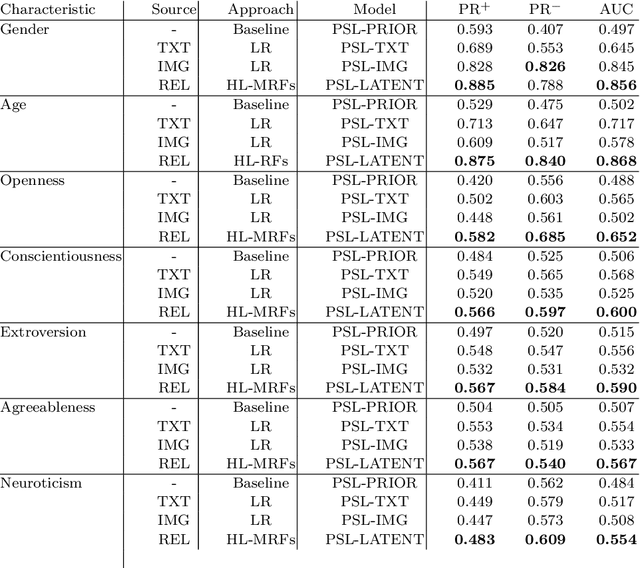
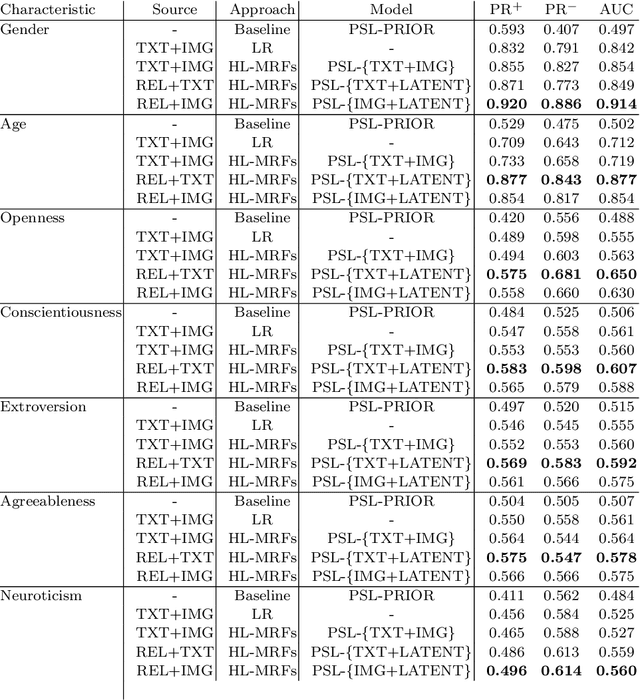
A variety of approaches have been proposed to automatically infer the profiles of users from their digital footprint in social media. Most of the proposed approaches focus on mining a single type of information, while ignoring other sources of available user-generated content (UGC). In this paper, we propose a mechanism to infer a variety of user characteristics, such as, age, gender and personality traits, which can then be compiled into a user profile. To this end, we model social media users by incorporating and reasoning over multiple sources of UGC as well as social relations. Our model is based on a statistical relational learning framework using Hinge-loss Markov Random Fields (HL-MRFs), a class of probabilistic graphical models that can be defined using a set of first-order logical rules. We validate our approach on data from Facebook with more than 5k users and almost 725k relations. We show how HL-MRFs can be used to develop a generic and extensible user profiling framework by leveraging textual, visual, and relational content in the form of status updates, profile pictures and Facebook page likes. Our experimental results demonstrate that our proposed model successfully incorporates multiple sources of information and outperforms competing methods that use only one source of information or an ensemble method across the different sources for modeling of users in social media.
Estimating Causal Effects of Tone in Online Debates
Jun 12, 2019


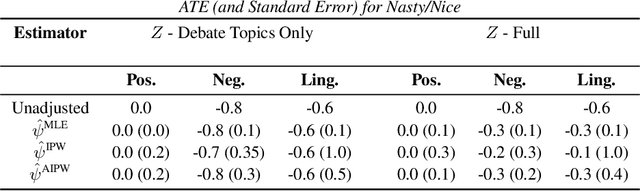
Statistical methods applied to social media posts shed light on the dynamics of online dialogue. For example, users' wording choices predict their persuasiveness and users adopt the language patterns of other dialogue participants. In this paper, we estimate the causal effect of reply tones in debates on linguistic and sentiment changes in subsequent responses. The challenge for this estimation is that a reply's tone and subsequent responses are confounded by the users' ideologies on the debate topic and their emotions. To overcome this challenge, we learn representations of ideology using generative models of text. We study debates from 4Forums and compare annotated tones of replying such as emotional versus factual, or reasonable versus attacking. We show that our latent confounder representation reduces bias in ATE estimation. Our results suggest that factual and asserting tones affect dialogue and provide a methodology for estimating causal effects from text.
SysML: The New Frontier of Machine Learning Systems
May 01, 2019Machine learning (ML) techniques are enjoying rapidly increasing adoption. However, designing and implementing the systems that support ML models in real-world deployments remains a significant obstacle, in large part due to the radically different development and deployment profile of modern ML methods, and the range of practical concerns that come with broader adoption. We propose to foster a new systems machine learning research community at the intersection of the traditional systems and ML communities, focused on topics such as hardware systems for ML, software systems for ML, and ML optimized for metrics beyond predictive accuracy. To do this, we describe a new conference, SysML, that explicitly targets research at the intersection of systems and machine learning with a program committee split evenly between experts in systems and ML, and an explicit focus on topics at the intersection of the two.
A Fairness-aware Hybrid Recommender System
Sep 13, 2018
Recommender systems are used in variety of domains affecting people's lives. This has raised concerns about possible biases and discrimination that such systems might exacerbate. There are two primary kinds of biases inherent in recommender systems: observation bias and bias stemming from imbalanced data. Observation bias exists due to a feedback loop which causes the model to learn to only predict recommendations similar to previous ones. Imbalance in data occurs when systematic societal, historical, or other ambient bias is present in the data. In this paper, we address both biases by proposing a hybrid fairness-aware recommender system. Our model provides efficient and accurate recommendations by incorporating multiple user-user and item-item similarity measures, content, and demographic information, while addressing recommendation biases. We implement our model using a powerful and expressive probabilistic programming language called probabilistic soft logic. We experimentally evaluate our approach on a popular movie recommendation dataset, showing that our proposed model can provide more accurate and fairer recommendations, compared to a state-of-the art fair recommender system.
Scalable Structure Learning for Probabilistic Soft Logic
Jul 03, 2018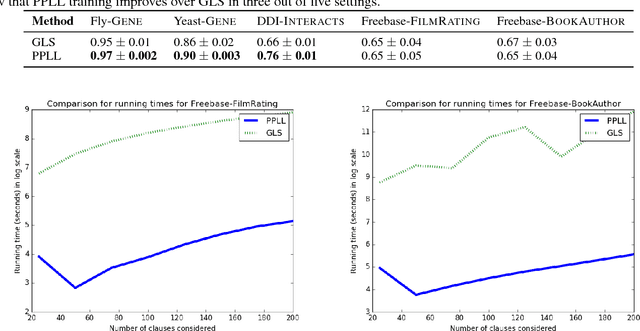
Statistical relational frameworks such as Markov logic networks and probabilistic soft logic (PSL) encode model structure with weighted first-order logical clauses. Learning these clauses from data is referred to as structure learning. Structure learning alleviates the manual cost of specifying models. However, this benefit comes with high computational costs; structure learning typically requires an expensive search over the space of clauses which involves repeated optimization of clause weights. In this paper, we propose the first two approaches to structure learning for PSL. We introduce a greedy search-based algorithm and a novel optimization method that trade-off scalability and approximations to the structure learning problem in varying ways. The highly scalable optimization method combines data-driven generation of clauses with a piecewise pseudolikelihood (PPLL) objective that learns model structure by optimizing clause weights only once. We compare both methods across five real-world tasks, showing that PPLL achieves an order of magnitude runtime speedup and AUC gains up to 15% over greedy search.
Hinge-Loss Markov Random Fields and Probabilistic Soft Logic
Nov 17, 2017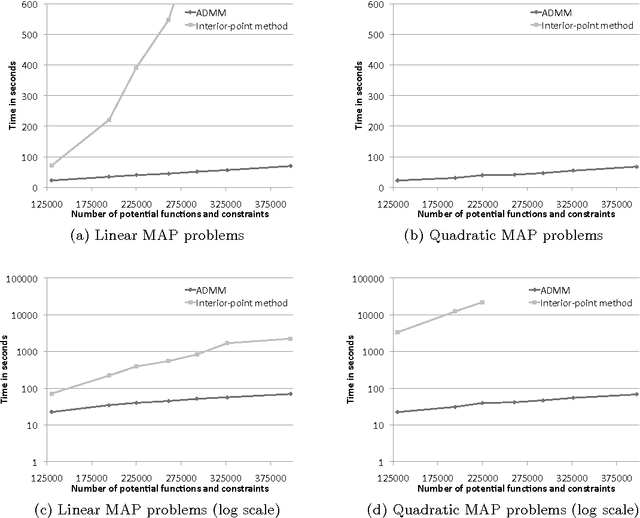
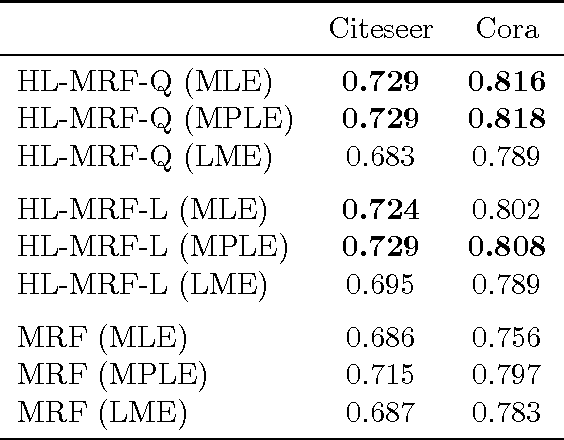
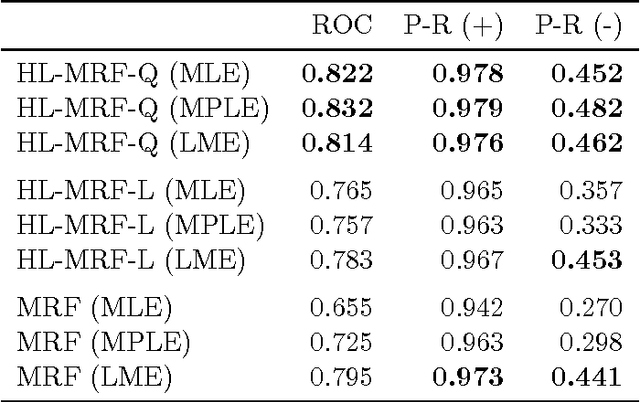

A fundamental challenge in developing high-impact machine learning technologies is balancing the need to model rich, structured domains with the ability to scale to big data. Many important problem areas are both richly structured and large scale, from social and biological networks, to knowledge graphs and the Web, to images, video, and natural language. In this paper, we introduce two new formalisms for modeling structured data, and show that they can both capture rich structure and scale to big data. The first, hinge-loss Markov random fields (HL-MRFs), is a new kind of probabilistic graphical model that generalizes different approaches to convex inference. We unite three approaches from the randomized algorithms, probabilistic graphical models, and fuzzy logic communities, showing that all three lead to the same inference objective. We then define HL-MRFs by generalizing this unified objective. The second new formalism, probabilistic soft logic (PSL), is a probabilistic programming language that makes HL-MRFs easy to define using a syntax based on first-order logic. We introduce an algorithm for inferring most-probable variable assignments (MAP inference) that is much more scalable than general-purpose convex optimization methods, because it uses message passing to take advantage of sparse dependency structures. We then show how to learn the parameters of HL-MRFs. The learned HL-MRFs are as accurate as analogous discrete models, but much more scalable. Together, these algorithms enable HL-MRFs and PSL to model rich, structured data at scales not previously possible.
Using Noisy Extractions to Discover Causal Knowledge
Nov 16, 2017
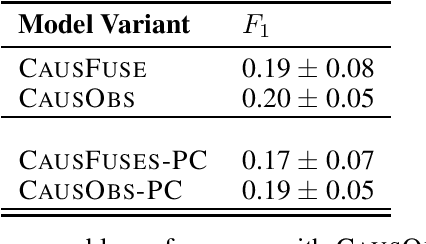
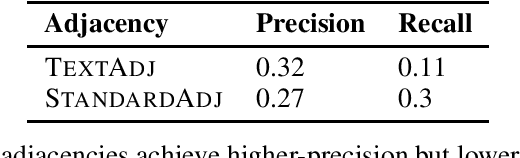
Knowledge bases (KB) constructed through information extraction from text play an important role in query answering and reasoning. In this work, we study a particular reasoning task, the problem of discovering causal relationships between entities, known as causal discovery. There are two contrasting types of approaches to discovering causal knowledge. One approach attempts to identify causal relationships from text using automatic extraction techniques, while the other approach infers causation from observational data. However, extractions alone are often insufficient to capture complex patterns and full observational data is expensive to obtain. We introduce a probabilistic method for fusing noisy extractions with observational data to discover causal knowledge. We propose a principled approach that uses the probabilistic soft logic (PSL) framework to encode well-studied constraints to recover long-range patterns and consistent predictions, while cheaply acquired extractions provide a proxy for unseen observations. We apply our method gene regulatory networks and show the promise of exploiting KB signals in causal discovery, suggesting a critical, new area of research.