 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Tree Explanation Methods for Anomaly Reasoning: A Case Study of SHAP TreeExplainer and TreeInterpreter
Oct 13, 2020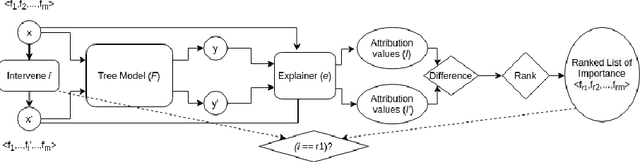
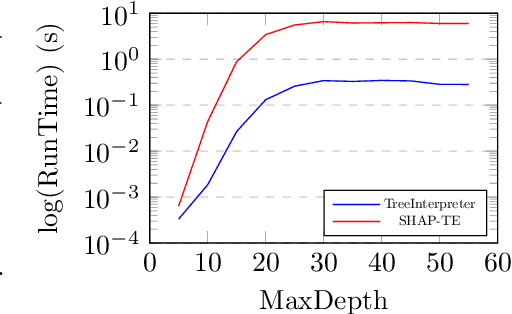
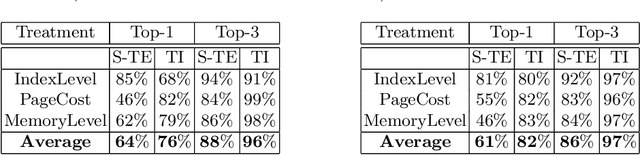
Understanding predictions made by Machine Learning models is critical in many applications. In this work, we investigate the performance of two methods for explaining tree-based models- Tree Interpreter (TI) and SHapley Additive exPlanations TreeExplainer (SHAP-TE). Using a case study on detecting anomalies in job runtimes of applications that utilize cloud-computing platforms, we compare these approaches using a variety of metrics, including computation time, significance of attribution value, and explanation accuracy. We find that, although the SHAP-TE offers consistency guarantees over TI, at the cost of increased computation, consistency does not necessarily improve the explanation performance in our case study.
Preserving Patient Privacy while Training a Predictive Model of In-hospital Mortality
Dec 01, 2019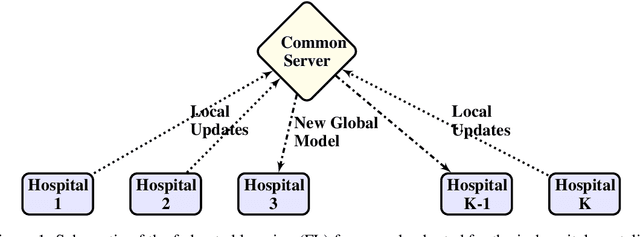

Machine learning models can be used for pattern recognition in medical data in order to improve patient outcomes, such as the prediction of in-hospital mortality. Deep learning models, in particular, require large amounts of data for model training. However, the data is often collected at different hospitals and sharing is restricted due to patient privacy concerns. In this paper, we aimed to demonstrate the potential of distributed training in achieving state-of-the-art performance while maintaining data privacy. Our results show that training the model in the federated learning framework leads to comparable performance to the traditional centralised setting. We also suggest several considerations for the success of such frameworks in future work.
Conv-codes: Audio Hashing For Bird Species Classification
Feb 07, 2019
In this work, we propose a supervised, convex representation based audio hashing framework for bird species classification. The proposed framework utilizes archetypal analysis, a matrix factorization technique, to obtain convex-sparse representations of a bird vocalization. These convex representations are hashed using Bloom filters with non-cryptographic hash functions to obtain compact binary codes, designated as conv-codes. The conv-codes extracted from the training examples are clustered using class-specific k-medoids clustering with Jaccard coefficient as the similarity metric. A hash table is populated using the cluster centers as keys while hash values/slots are pointers to the species identification information. During testing, the hash table is searched to find the species information corresponding to a cluster center that exhibits maximum similarity with the test conv-code. Hence, the proposed framework classifies a bird vocalization in the conv-code space and requires no explicit classifier or reconstruction error calculations. Apart from that, based on min-hash and direct addressing, we also propose a variant of the proposed framework that provides faster and effective classification. The performances of both these frameworks are compared with existing bird species classification frameworks on the audio recordings of 50 different bird species.