 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Image Harmonization by Bridging the Reality Gap
Mar 31, 2021
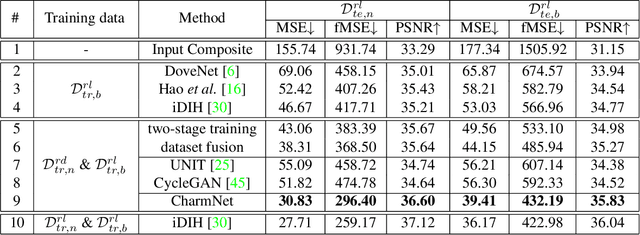
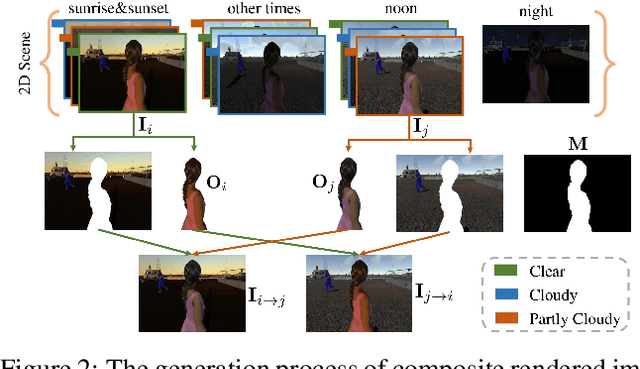
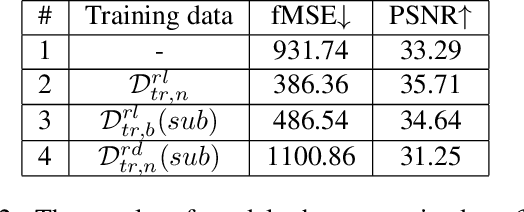
Image harmonization has been significantly advanced with large-scale harmonization dataset. However, the current way to build dataset is still labor-intensive, which adversely affects the extendability of dataset. To address this problem, we propose to construct a large-scale rendered harmonization dataset RHHarmony with fewer human efforts to augment the existing real-world dataset. To leverage both real-world images and rendered images, we propose a cross-domain harmonization network CharmNet to bridge the domain gap between two domains. Moreover, we also employ well-designed style classifiers and losses to facilitate cross-domain knowledge transfer. Extensive experiments demonstrate the potential of using rendered images for image harmonization and the effectiveness of our proposed network. Our dataset and code are available at https://github.com/bcmi/Rendered_Image_Harmonization_Datasets.
Disentangled Information Bottleneck
Dec 22, 2020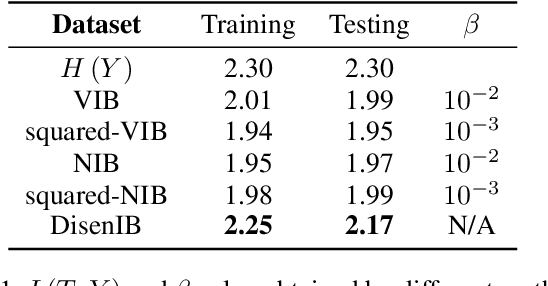
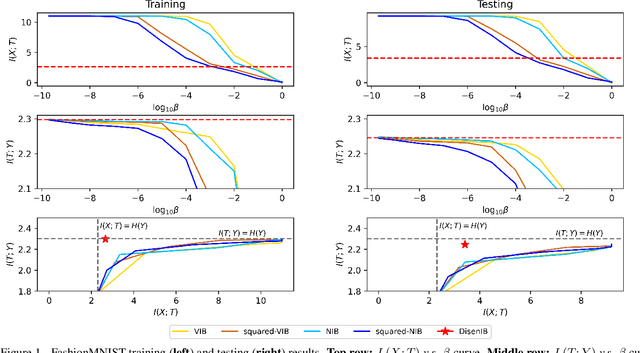
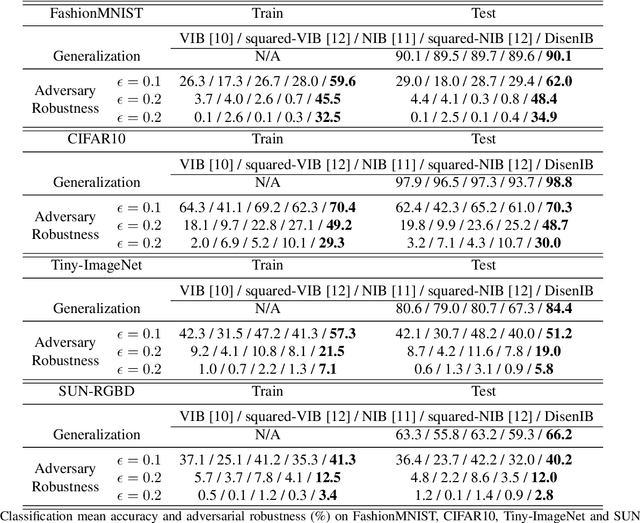
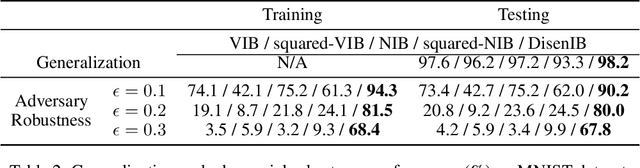
The information bottleneck (IB) method is a technique for extracting information that is relevant for predicting the target random variable from the source random variable, which is typically implemented by optimizing the IB Lagrangian that balances the compression and prediction terms. However, the IB Lagrangian is hard to optimize, and multiple trials for tuning values of Lagrangian multiplier are required. Moreover, we show that the prediction performance strictly decreases as the compression gets stronger during optimizing the IB Lagrangian. In this paper, we implement the IB method from the perspective of supervised disentangling. Specifically, we introduce Disentangled Information Bottleneck (DisenIB) that is consistent on compressing source maximally without target prediction performance loss (maximum compression). Theoretical and experimental results demonstrate that our method is consistent on maximum compression, and performs well in terms of generalization, robustness to adversarial attack, out-of-distribution detection, and supervised disentangling.
From Pixel to Patch: Synthesize Context-aware Features for Zero-shot Semantic Segmentation
Sep 29, 2020

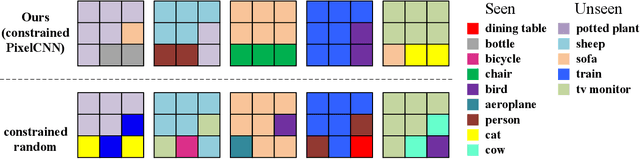
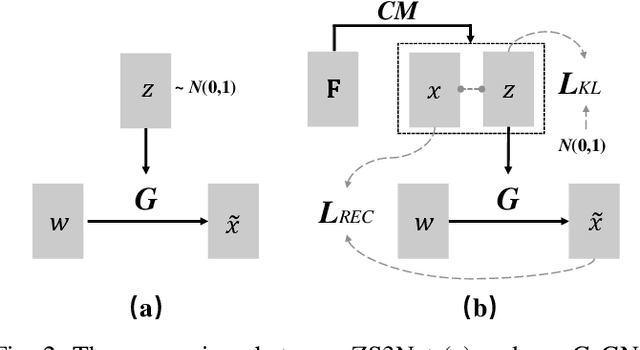
Zero-shot learning has been actively studied for image classification task to relieve the burden of annotating image labels. Interestingly, semantic segmentation task requires more labor-intensive pixel-wise annotation, but zero-shot semantic segmentation has only attracted limited research interest. Thus, we focus on zero-shot semantic segmentation, which aims to segment unseen objects with only category-level semantic representations provided for unseen categories. In this paper, we propose a novel Context-aware feature Generation Network (CaGNet), which can synthesize context-aware pixel-wise visual features for unseen categories based on category-level semantic representations and pixel-wise contextual information. The synthesized features are used to finetune the classifier to enable segmenting unseen objects. Furthermore, we extend pixel-wise feature generation and finetuning to patch-wise feature generation and finetuning, which additionally considers inter-pixel relationship. Experimental results on Pascal-VOC, Pascal-Context, and COCO-stuff show that our method significantly outperforms the existing zero-shot semantic segmentation methods. Code is available at https://github.com/bcmi/CaGNetv2-Zero-Shot-Semantic-Segmentation.
Weak-shot Fine-grained Classification via Similarity Transfer
Sep 19, 2020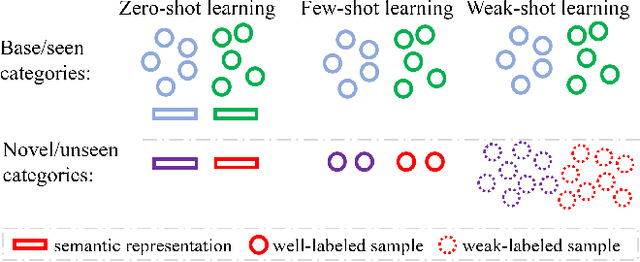
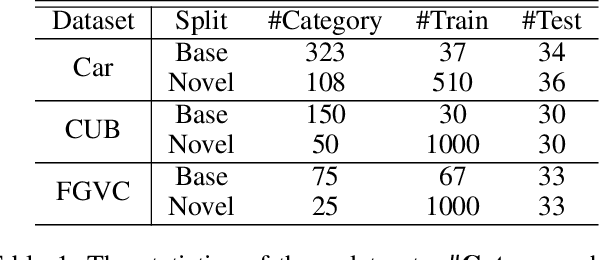
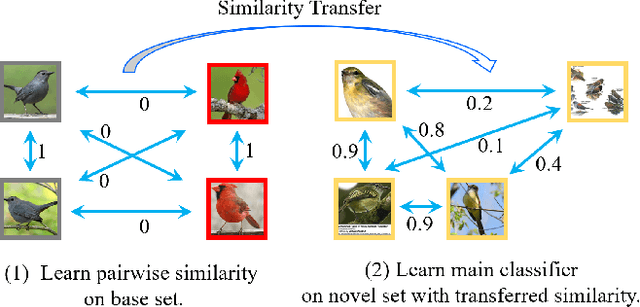
Recognizing fine-grained categories remains a challenging task, due to the subtle distinctions among different subordinate categories, which results in the need of abundant annotated samples. To alleviate the data-hungry problem, we consider the problem of learning novel categories from web data with the support of a clean set of base categories, which is referred to as weak-shot learning. Under this setting, we propose to transfer pairwise semantic similarity from base categories to novel categories, because this similarity is highly transferable and beneficial for learning from web data. Specifically, we firstly train a similarity net on clean data, and then employ two simple yet effective strategies to leverage the transferred similarity to denoise web training data. In addition, we apply adversarial loss on similarity net to enhance the transferability of similarity. Comprehensive experiments on three fine-grained datasets demonstrate that we could dramatically facilitate webly supervised learning by a clean set and similarity transfer is effective under this setting.
BargainNet: Background-Guided Domain Translation for Image Harmonization
Sep 19, 2020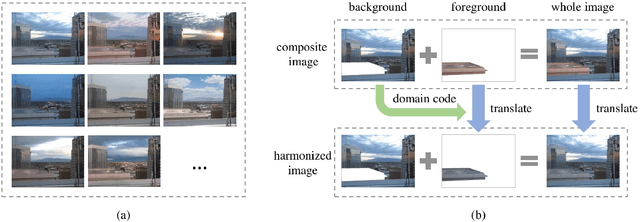
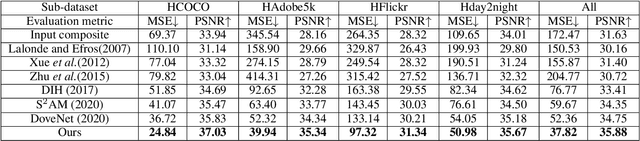


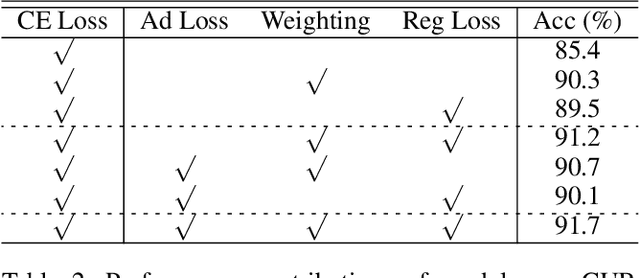
Image composition is a fundamental operation in image editing field. However, unharmonious foreground and background downgrade the quality of composite image. Image harmonization, which adjusts the foreground to improve the consistency, is an essential yet challenging task. Previous deep learning based methods mainly focus on directly learning the mapping from composite image to real image, while ignoring the crucial guidance role that background plays. In this work, with the assumption that the foreground needs to be translated to the same domain as background, we formulate image harmonization task as background-guided domain translation. Therefore, we propose an image harmonization network with a novel domain code extractor and well-tailored triplet losses, which could capture the background domain information to guide the foreground harmonization. Extensive experiments on the existing image harmonization benchmark demonstrate the effectiveness of our proposed method.
DeltaGAN: Towards Diverse Few-shot Image Generation with Sample-Specific Delta
Sep 18, 2020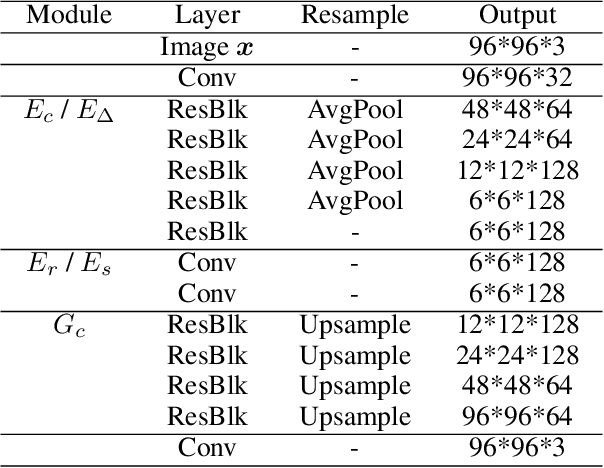


Learning to generate new images for a novel category based on only a few images, named as few-shot image generation, has attracted increasing research interest. Several state-of-the-art works have yielded impressive results, but the diversity is still limited. In this work, we propose a novel Delta Generative Adversarial Network (DeltaGAN), which consists of a reconstruction subnetwork and a generation subnetwork. The reconstruction subnetwork captures intra-category transformation, i.e., "delta", between same-category pairs. The generation subnetwork generates sample-specific "delta" for an input image, which is combined with this input image to generate a new image within the same category. Besides, an adversarial delta matching loss is designed to link the above two subnetworks together. Extensive experiments on five few-shot image datasets demonstrate the effectiveness of our proposed method.
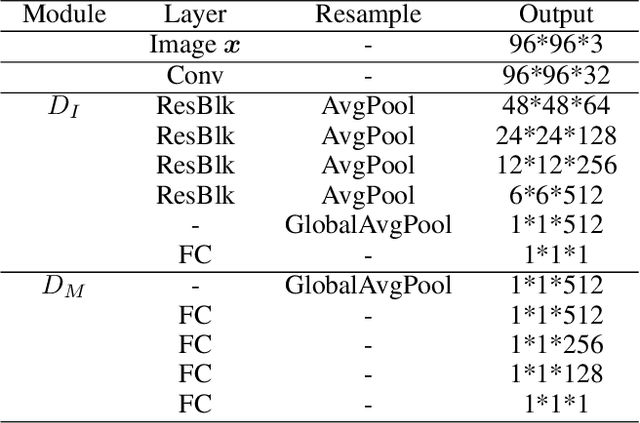
Context-aware Feature Generation for Zero-shot Semantic Segmentation
Aug 16, 2020
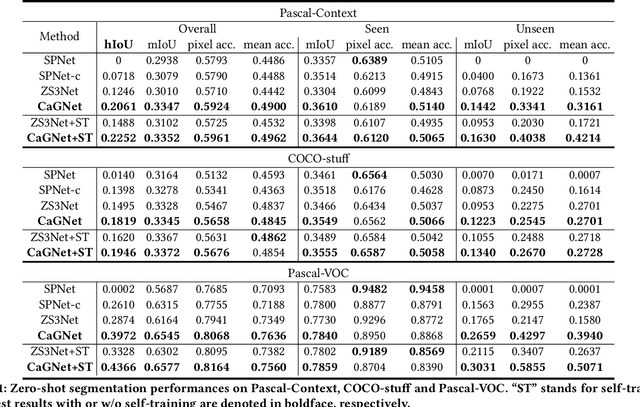
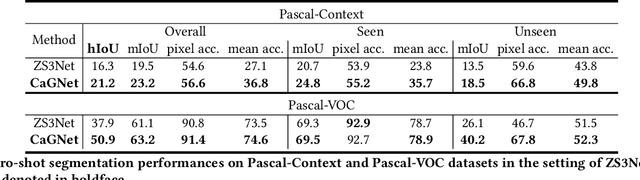
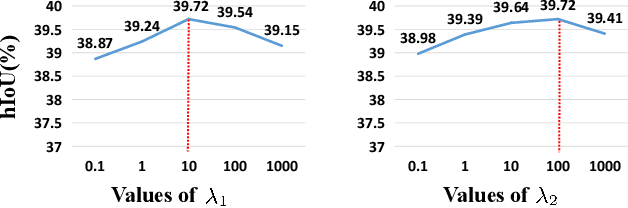
Existing semantic segmentation models heavily rely on dense pixel-wise annotations. To reduce the annotation pressure, we focus on a challenging task named zero-shot semantic segmentation, which aims to segment unseen objects with zero annotations. This task can be accomplished by transferring knowledge across categories via semantic word embeddings. In this paper, we propose a novel context-aware feature generation method for zero-shot segmentation named CaGNet. In particular, with the observation that a pixel-wise feature highly depends on its contextual information, we insert a contextual module in a segmentation network to capture the pixel-wise contextual information, which guides the process of generating more diverse and context-aware features from semantic word embeddings. Our method achieves state-of-the-art results on three benchmark datasets for zero-shot segmentation. Codes are available at: https://github.com/bcmi/CaGNet-Zero-Shot-Semantic-Segmentation.
F2GAN: Fusing-and-Filling GAN for Few-shot Image Generation
Aug 06, 2020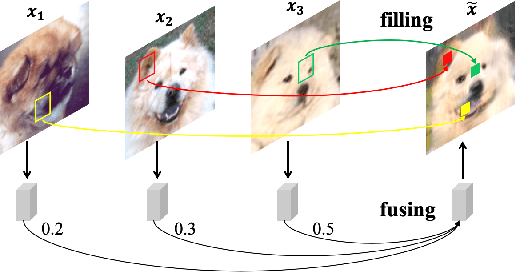
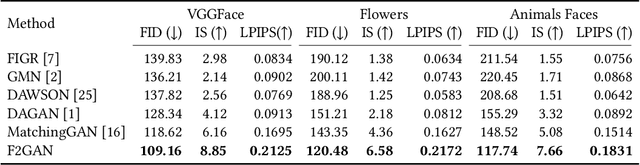
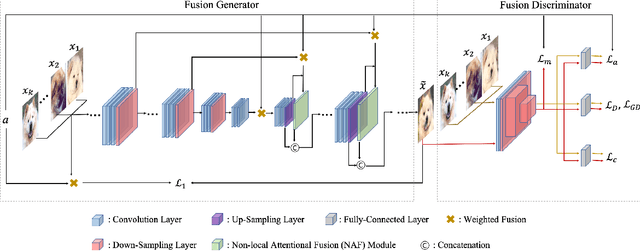
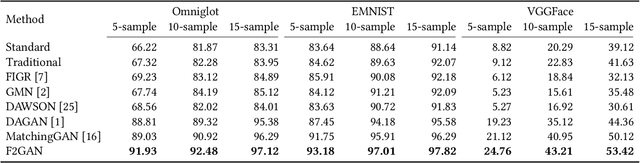
In order to generate images for a given category, existing deep generative models generally rely on abundant training images. However, extensive data acquisition is expensive and fast learning ability from limited data is necessarily required in real-world applications. Also, these existing methods are not well-suited for fast adaptation to a new category. Few-shot image generation, aiming to generate images from only a few images for a new category, has attracted some research interest. In this paper, we propose a Fusing-and-Filling Generative Adversarial Network (F2GAN) to generate realistic and diverse images for a new category with only a few images. In our F2GAN, a fusion generator is designed to fuse the high-level features of conditional images with random interpolation coefficients, and then fills in attended low-level details with non-local attention module to produce a new image. Moreover, our discriminator can ensure the diversity of generated images by a mode seeking loss and an interpolation regression loss. Extensive experiments on five datasets demonstrate the effectiveness of our proposed method for few-shot image generation.
Beyond without Forgetting: Multi-Task Learning for Classification with Disjoint Datasets
Mar 15, 2020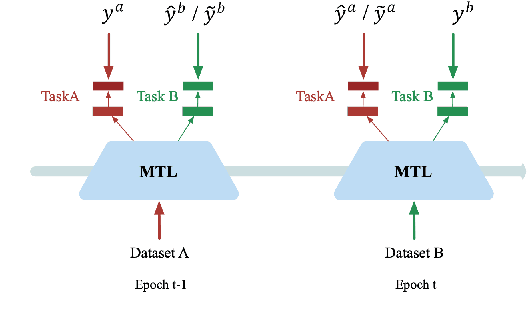
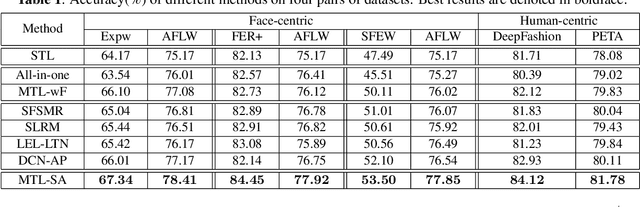
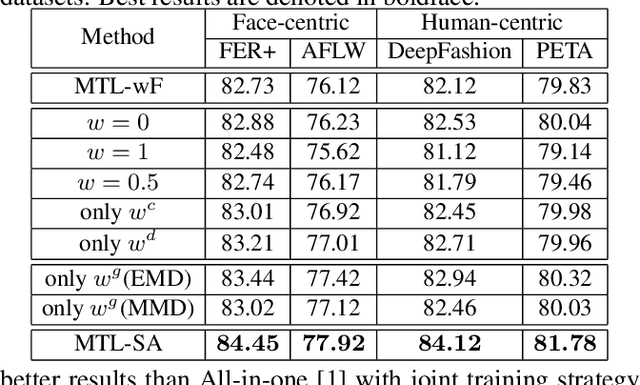
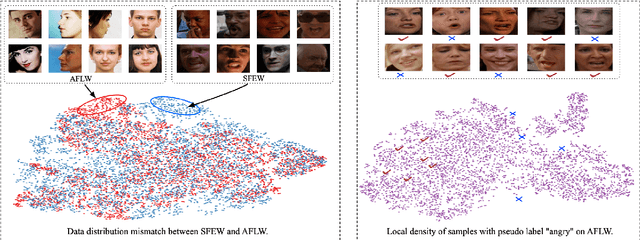
Multi-task Learning (MTL) for classification with disjoint datasets aims to explore MTL when one task only has one labeled dataset. In existing methods, for each task, the unlabeled datasets are not fully exploited to facilitate this task. Inspired by semi-supervised learning, we use unlabeled datasets with pseudo labels to facilitate each task. However, there are two major issues: 1) the pseudo labels are very noisy; 2) the unlabeled datasets and the labeled dataset for each task has considerable data distribution mismatch. To address these issues, we propose our MTL with Selective Augmentation (MTL-SA) method to select the training samples in unlabeled datasets with confident pseudo labels and close data distribution to the labeled dataset. Then, we use the selected training samples to add information and use the remaining training samples to preserve information. Extensive experiments on face-centric and human-centric applications demonstrate the effectiveness of our MTL-SA method.
MatchingGAN: Matching-based Few-shot Image Generation
Mar 15, 2020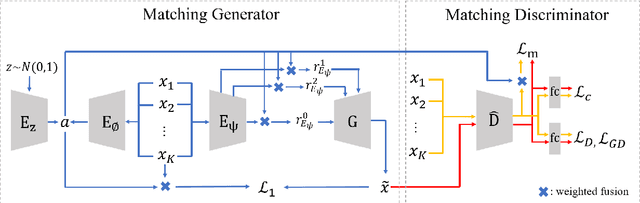
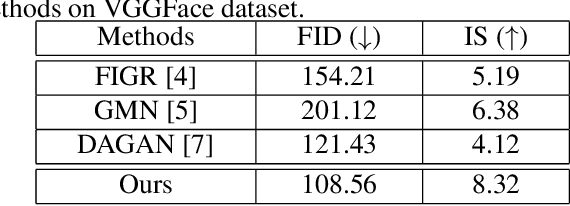

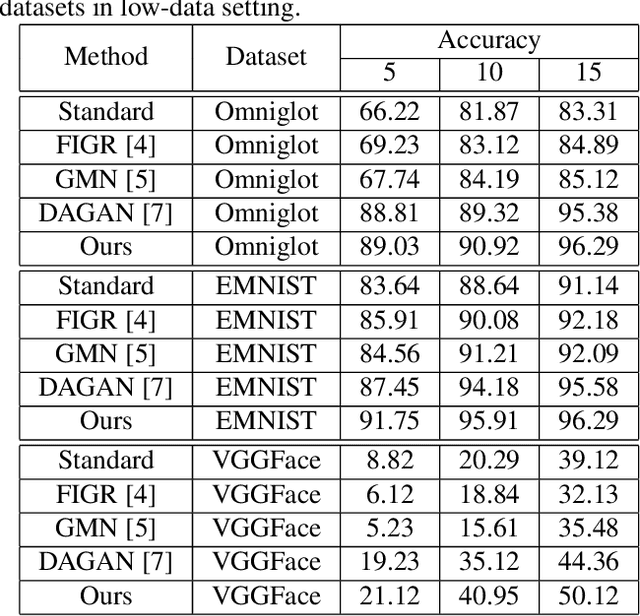
To generate new images for a given category, most deep generative models require abundant training images from this category, which are often too expensive to acquire. To achieve the goal of generation based on only a few images, we propose matching-based Generative Adversarial Network (GAN) for few-shot generation, which includes a matching generator and a matching discriminator. Matching generator can match random vectors with a few conditional images from the same category and generate new images for this category based on the fused features. The matching discriminator extends conventional GAN discriminator by matching the feature of generated image with the fused feature of conditional images. Extensive experiments on three datasets demonstrate the effectiveness of our proposed method.