 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Coding for Human and Machine Vision: A Scalable Image Coding Approach
Jan 10, 2020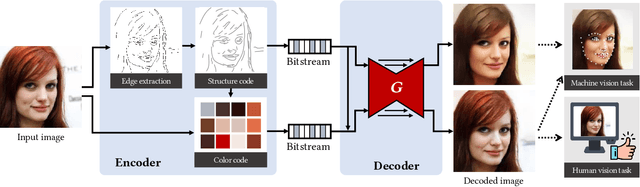

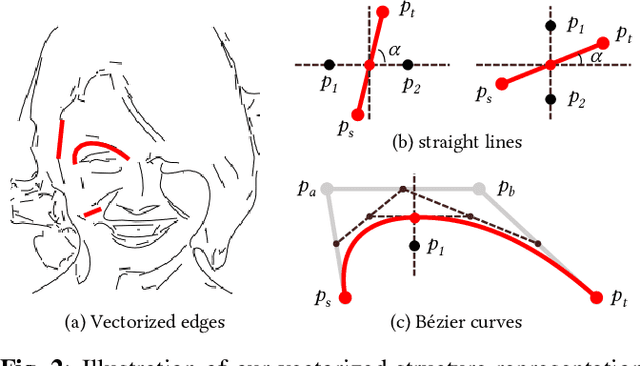

The past decades have witnessed the rapid development of image and video coding techniques in the era of big data. However, the signal fidelity-driven coding pipeline design limits the capability of the existing image/video coding frameworks to fulfill the needs of both machine and human vision. In this paper, we come up with a novel image coding framework by leveraging both the compressive and the generative models, to support machine vision and human perception tasks jointly. Given an input image, the feature analysis is first applied, and then the generative model is employed to perform image reconstruction with features and additional reference pixels, in which compact edge maps are extracted in this work to connect both kinds of vision in a scalable way. The compact edge map serves as the basic layer for machine vision tasks, and the reference pixels act as a sort of enhanced layer to guarantee signal fidelity for human vision. By introducing advanced generative models, we train a flexible network to reconstruct images from compact feature representations and the reference pixels. Experimental results demonstrate the superiority of our framework in both human visual quality and facial landmark detection, which provide useful evidence on the emerging standardization efforts on MPEG VCM (Video Coding for Machine).
An Emerging Coding Paradigm VCM: A Scalable Coding Approach Beyond Feature and Signal
Jan 09, 2020
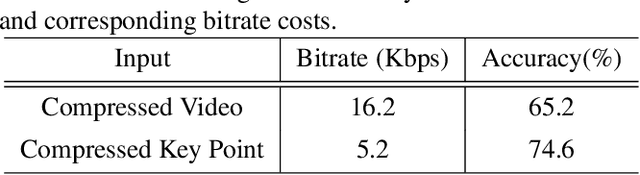
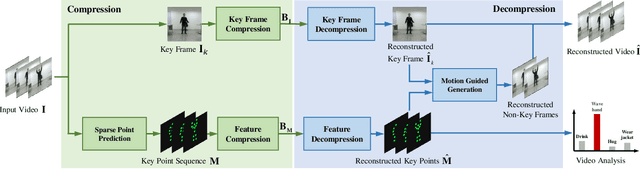

In this paper, we study a new problem arising from the emerging MPEG standardization effort Video Coding for Machine (VCM), which aims to bridge the gap between visual feature compression and classical video coding. VCM is committed to address the requirement of compact signal representation for both machine and human vision in a more or less scalable way. To this end, we make endeavors in leveraging the strength of predictive and generative models to support advanced compression techniques for both machine and human vision tasks simultaneously, in which visual features serve as a bridge to connect signal-level and task-level compact representations in a scalable manner. Specifically, we employ a conditional deep generation network to reconstruct video frames with the guidance of learned motion pattern. By learning to extract sparse motion pattern via a predictive model, the network elegantly leverages the feature representation to generate the appearance of to-be-coded frames via a generative model, relying on the appearance of the coded key frames. Meanwhile, the sparse motion pattern is compact and highly effective for high-level vision tasks, e.g. action recognition. Experimental results demonstrate that our method yields much better reconstruction quality compared with the traditional video codecs (0.0063 gain in SSIM), as well as state-of-the-art action recognition performance over highly compressed videos (9.4% gain in recognition accuracy), which showcases a promising paradigm of coding signal for both human and machine vision.
Towards Digital Retina in Smart Cities: A Model Generation, Utilization and Communication Paradigm
Jul 31, 2019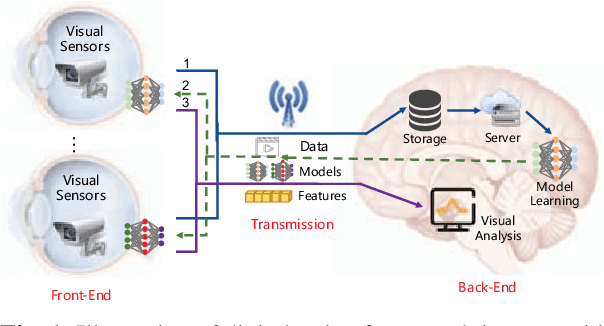
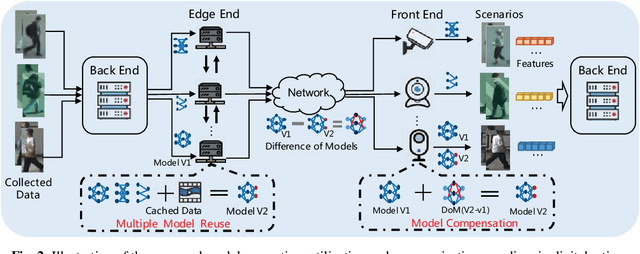
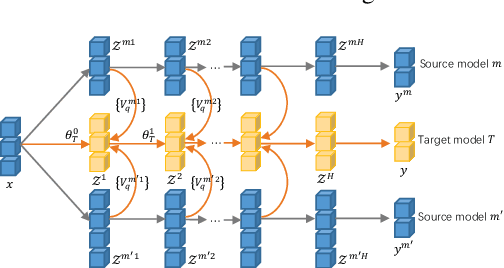
The digital retina in smart cities is to select what the City Eye tells the City Brain, and convert the acquired visual data from front-end visual sensors to features in an intelligent sensing manner. By deploying deep learning and/or handcrafted models in front-end devices, the compact features can be extracted and subsequently delivered to back-end cloud for search and advanced analytics. In this context, we propose a model generation, utilization, and communication paradigm, aiming to address a set of unique challenges for better artificial intelligence services in smart cities. In particular, we present an integrated multiple deep learning models reuse and prediction strategy, which greatly increases the feasibility of the digital retina in processing and analyzing the large-scale visual data in smart cities. The promise of the proposed paradigm is demonstrated through a set of experiments.
NTU RGB+D 120: A Large-Scale Benchmark for 3D Human Activity Understanding
May 12, 2019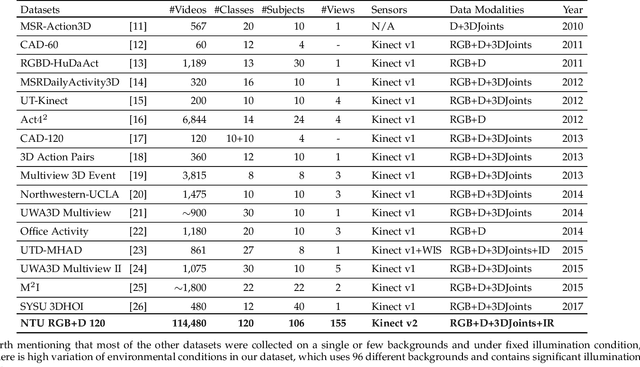
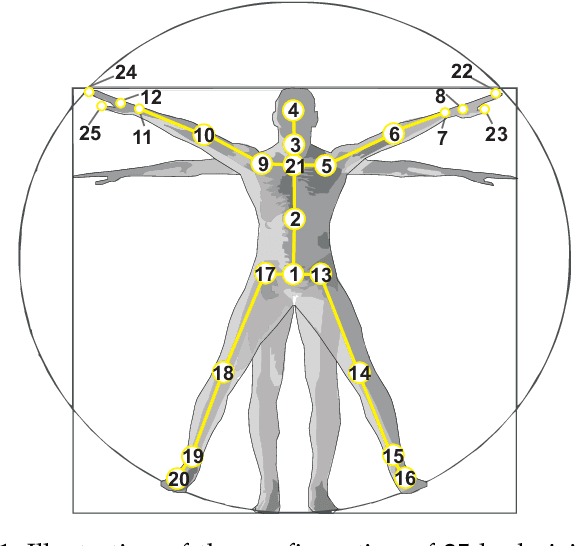
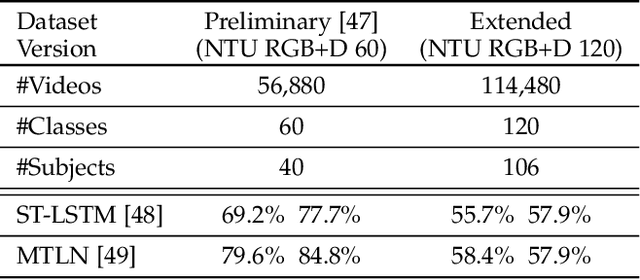
Research on depth-based human activity analysis achieved outstanding performance and demonstrated the effectiveness of 3D representation for action recognition. The existing depth-based and RGB+D-based action recognition benchmarks have a number of limitations, including the lack of large-scale training samples, realistic number of distinct class categories, diversity in camera views, varied environmental conditions, and variety of human subjects. In this work, we introduce a large-scale dataset for RGB+D human action recognition, which is collected from 106 distinct subjects and contains more than 114 thousand video samples and 8 million frames. This dataset contains 120 different action classes including daily, mutual, and health-related activities. We evaluate the performance of a series of existing 3D activity analysis methods on this dataset, and show the advantage of applying deep learning methods for 3D-based human action recognition. Furthermore, we investigate a novel one-shot 3D activity recognition problem on our dataset, and a simple yet effective Action-Part Semantic Relevance-aware (APSR) framework is proposed for this task, which yields promising results for recognition of the novel action classes. We believe the introduction of this large-scale dataset will enable the community to apply, adapt, and develop various data-hungry learning techniques for depth-based and RGB+D-based human activity understanding. [The dataset is available at: http://rose1.ntu.edu.sg/Datasets/actionRecognition.asp]
SPLINE-Net: Sparse Photometric Stereo through Lighting Interpolation and Normal Estimation Networks
May 10, 2019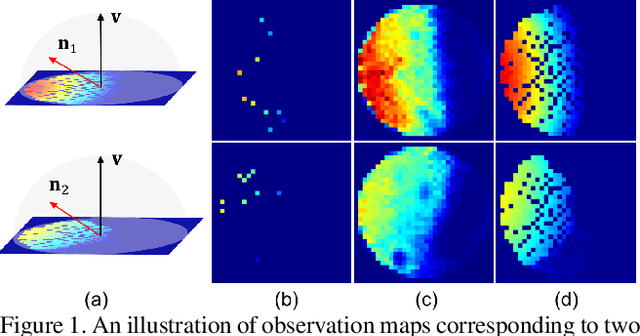
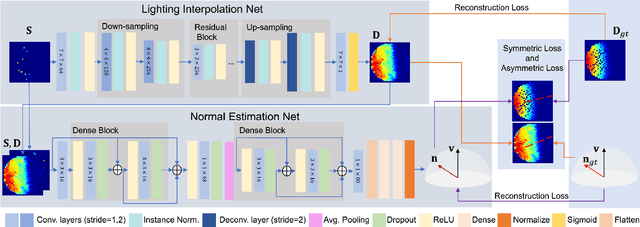
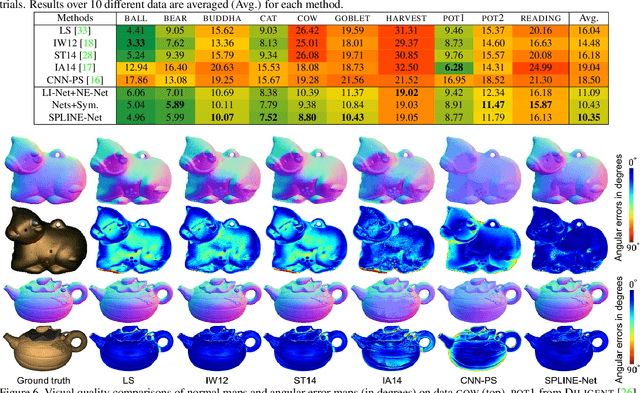
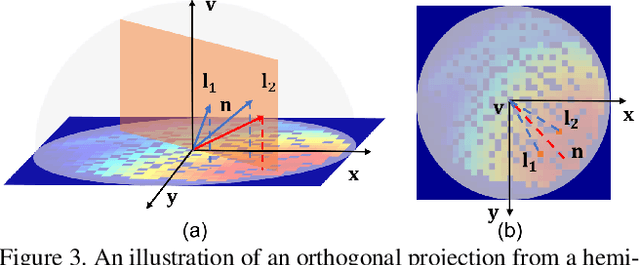
This paper solves the Sparse Photometric stereo through Lighting Interpolation and Normal Estimation using a generative Network (SPLINE-Net). SPLINE-Net contains a lighting interpolation network to generate dense lighting observations given a sparse set of lights as inputs followed by a normal estimation network to estimate surface normals. Both networks are jointly constrained by the proposed symmetric and asymmetric loss functions to enforce isotropic constrain and perform outlier rejection of global illumination effects. SPLINE-Net is verified to outperform existing methods for photometric stereo of general BRDFs by using only ten images of different lights instead of using nearly one hundred images.
Skeleton-Based Online Action Prediction Using Scale Selection Network
Apr 03, 2019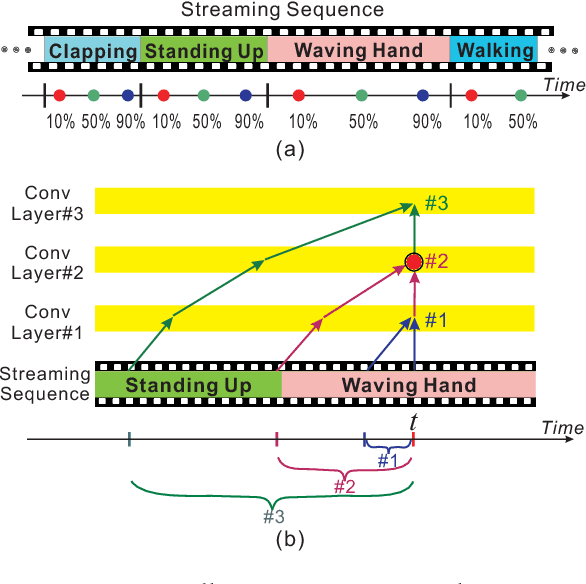

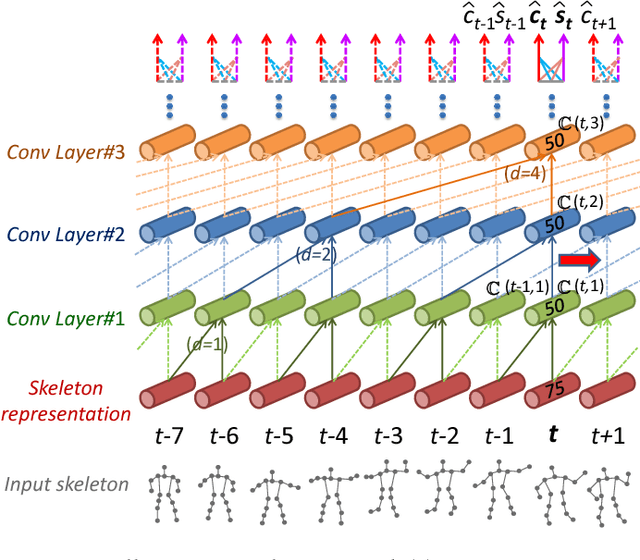
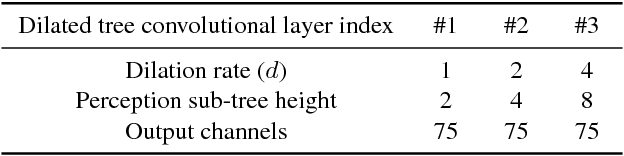
Action prediction is to recognize the class label of an ongoing activity when only a part of it is observed. In this paper, we focus on online action prediction in streaming 3D skeleton sequences. A dilated convolutional network is introduced to model the motion dynamics in temporal dimension via a sliding window over the temporal axis. Since there are significant temporal scale variations in the observed part of the ongoing action at different time steps, a novel window scale selection method is proposed to make our network focus on the performed part of the ongoing action and try to suppress the possible incoming interference from the previous actions at each step. An activation sharing scheme is also proposed to handle the overlapping computations among the adjacent time steps, which enables our framework to run more efficiently. Moreover, to enhance the performance of our framework for action prediction with the skeletal input data, a hierarchy of dilated tree convolutions are also designed to learn the multi-level structured semantic representations over the skeleton joints at each frame. Our proposed approach is evaluated on four challenging datasets. The extensive experiments demonstrate the effectiveness of our method for skeleton-based online action prediction.
Face Image Reflection Removal
Mar 03, 2019
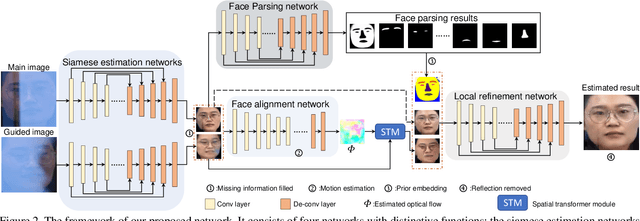

Face images captured through the glass are usually contaminated by reflections. The non-transmitted reflections make the reflection removal more challenging than for general scenes, because important facial features are completely occluded. In this paper, we propose and solve the face image reflection removal problem. We remove non-transmitted reflections by incorporating inpainting ideas into a guided reflection removal framework and recover facial features by considering various face-specific priors. We use a newly collected face reflection image dataset to train our model and compare with state-of-the-art methods. The proposed method shows advantages in estimating reflection-free face images for improving face recognition.
Feature Boosting Network For 3D Pose Estimation
Jan 15, 2019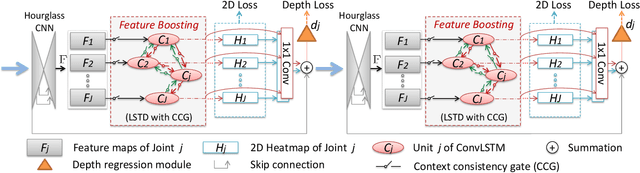
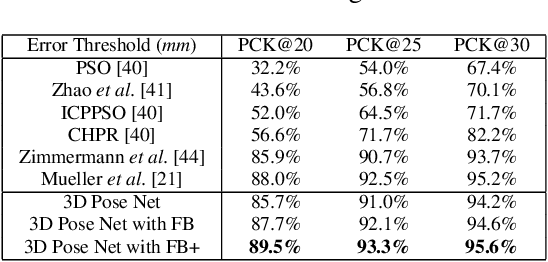
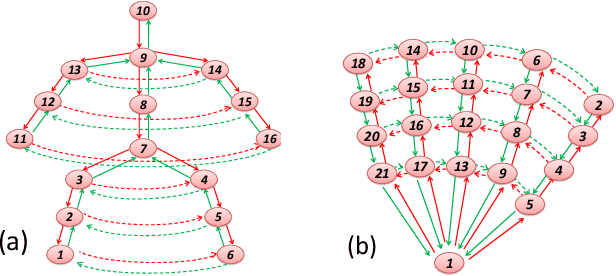

In this paper, a feature boosting network is proposed for estimating 3D hand pose and 3D body pose from a single RGB image. In this method, the features learned by the convolutional layers are boosted with a new long short-term dependence-aware (LSTD) module, which enables the intermediate convolutional feature maps to perceive the graphical long short-term dependency among different hand (or body) parts using the designed Graphical ConvLSTM. Learning a set of features that are reliable and discriminatively representative of the pose of a hand (or body) part is difficult due to the ambiguities, texture and illumination variation, and self-occlusion in the real application of 3D pose estimation. To improve the reliability of the features for representing each body part and enhance the LSTD module, we further introduce a context consistency gate (CCG) in this paper, with which the convolutional feature maps are modulated according to their consistency with the context representations. We evaluate the proposed method on challenging benchmark datasets for 3D hand pose estimation and 3D full body pose estimation. Experimental results show the effectiveness of our method that achieves state-of-the-art performance on both of the tasks.
Transfer Metric Learning: Algorithms, Applications and Outlooks
Oct 10, 2018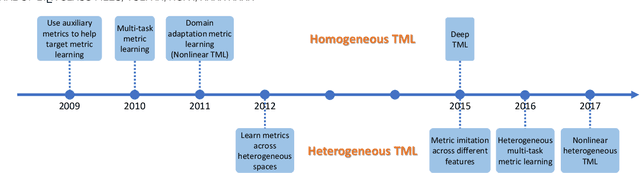
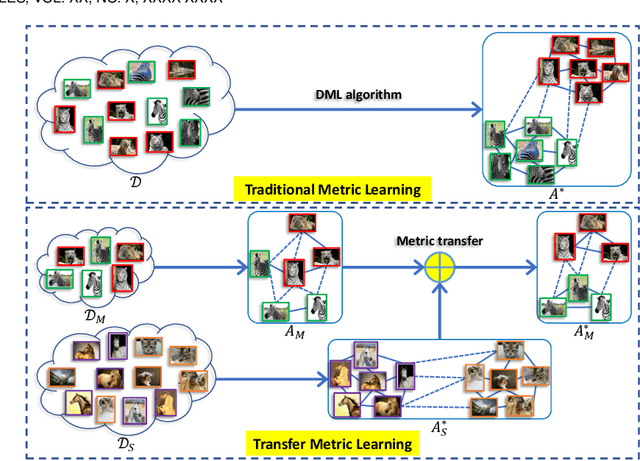
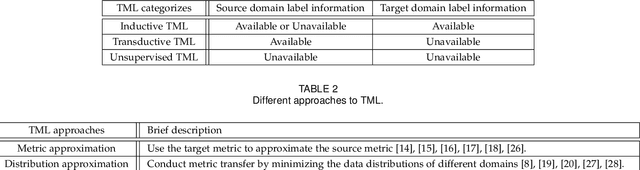
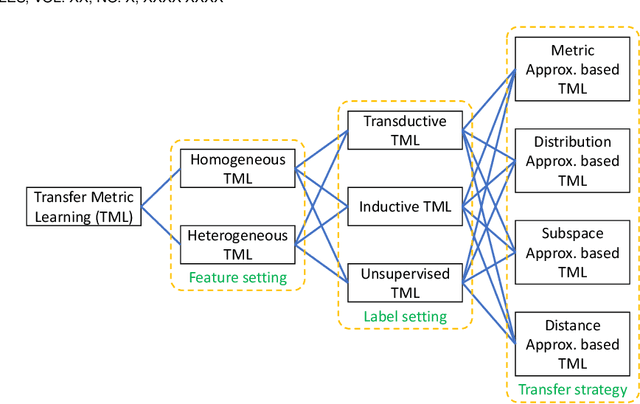
Distance metric learning (DML) aims to find an appropriate way to reveal the underlying data relationship. It is critical in many machine learning, pattern recognition and data mining algorithms, and usually require large amount of label information (class labels or pair/triplet constraints) to achieve satisfactory performance. However, the label information may be insufficient in real-world applications due to the high-labeling cost, and DML may fail in this case. Transfer metric learning (TML) is able to mitigate this issue for DML in the domain of interest (target domain) by leveraging knowledge/information from other related domains (source domains). Although achieved a certain level of development, TML has limited success in various aspects such as selective transfer, theoretical understanding, handling complex data, big data and extreme cases. In this survey, we present a systematic review of the TML literature. In particular, we group TML into different categories according to different settings and metric transfer strategies, such as direct metric approximation, subspace approximation, distance approximation, and distribution approximation. A summarization and insightful discussion of the various TML approaches and their applications will be presented. Finally, we provide some challenges and possible future directions.
CRRN: Multi-Scale Guided Concurrent Reflection Removal Network
May 30, 2018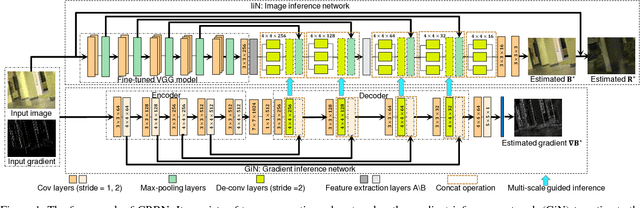
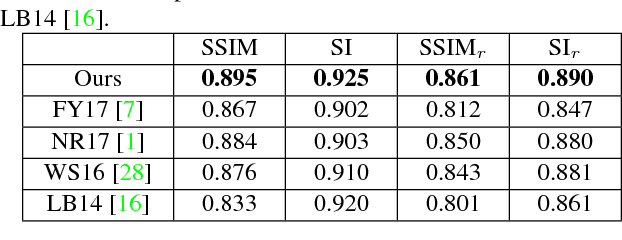

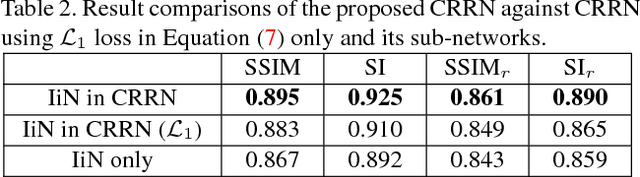
Removing the undesired reflections from images taken through the glass is of broad application to various computer vision tasks. Non-learning based methods utilize different handcrafted priors such as the separable sparse gradients caused by different levels of blurs, which often fail due to their limited description capability to the properties of real-world reflections. In this paper, we propose the Concurrent Reflection Removal Network (CRRN) to tackle this problem in a unified framework. Our proposed network integrates image appearance information and multi-scale gradient information with human perception inspired loss function, and is trained on a new dataset with 3250 reflection images taken under diverse real-world scenes. Extensive experiments on a public benchmark dataset show that the proposed method performs favorably against state-of-the-art methods.