 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccommodating Picky Customers: Regret Bound and Exploration Complexity for Multi-Objective Reinforcement Learning
Nov 25, 2020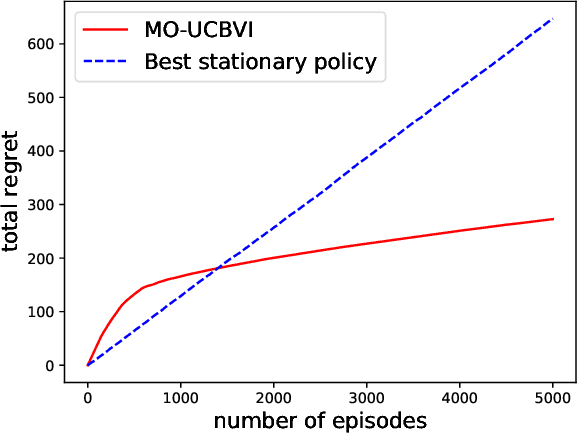
In this paper we consider multi-objective reinforcement learning where the objectives are balanced using preferences. In practice, the preferences are often given in an adversarial manner, e.g., customers can be picky in many applications. We formalize this problem as an episodic learning problem on a Markov decision process, where transitions are unknown and a reward function is the inner product of a preference vector with pre-specified multi-objective reward functions. In the online setting, the agent receives a (adversarial) preference every episode and proposes policies to interact with the environment. We provide a model-based algorithm that achieves a regret bound $\widetilde{\mathcal{O}}\left({\sqrt{\min\{d,S\}\cdot H^3 SAK}}\right)$, where $d$ is the number of objectives, $S$ is the number of states, $A$ is the number of actions, $H$ is the length of the horizon, and $K$ is the number of episodes. Furthermore, we consider preference-free exploration, i.e., the agent first interacts with the environment without specifying any preference and then is able to accommodate arbitrary preference vectors up to $\epsilon$ error. Our proposed algorithm is provably efficient with a nearly optimal sample complexity $\widetilde{\mathcal{O}}\left({\frac{\min\{d,S\}\cdot H^4 SA}{\epsilon^2}}\right)$.
Episodic Linear Quadratic Regulators with Low-rank Transitions
Nov 03, 2020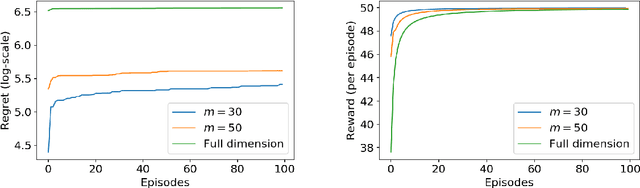

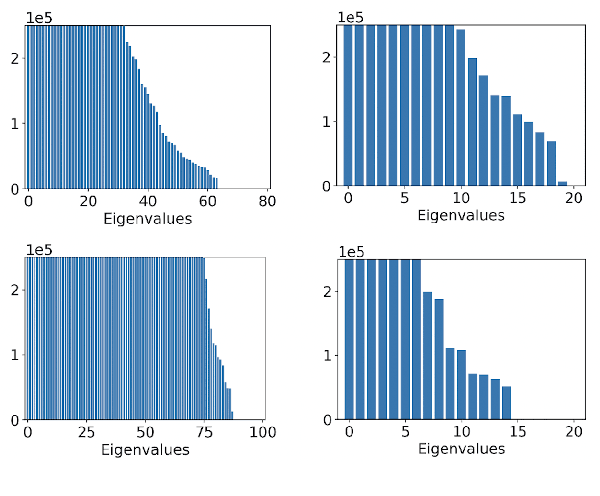
Linear Quadratic Regulators (LQR) achieve enormous successful real-world applications. Very recently, people have been focusing on efficient learning algorithms for LQRs when their dynamics are unknown. Existing results effectively learn to control the unknown system using number of episodes depending polynomially on the system parameters, including the ambient dimension of the states. These traditional approaches, however, become inefficient in common scenarios, e.g., when the states are high-resolution images. In this paper, we propose an algorithm that utilizes the intrinsic system low-rank structure for efficient learning. For problems of rank-$m$, our algorithm achieves a $K$-episode regret bound of order $\widetilde{O}(m^{3/2} K^{1/2})$. Consequently, the sample complexity of our algorithm only depends on the rank, $m$, rather than the ambient dimension, $d$, which can be orders-of-magnitude larger.
Random Walk Bandits
Nov 03, 2020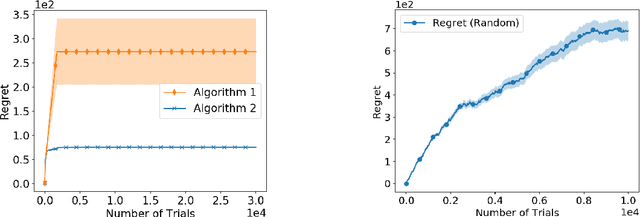

Bandit learning problems find important applications ranging from medical trials to online advertisement. In this paper, we study a novel bandit learning problem motivated by recommender systems. The goal is to recommend items so that users are likely to continue browsing. Our model views a user's browsing record as a random walk over a graph of webpages. This random walk ends (hits an absorbing node) when the user exits the website. Our model introduces a novel learning problem that calls for new technical insights on learning with graph random walk feedback. In particular, the performance and complexity depend on the structure of the decision space (represented by graphs). Our paper provides a comprehensive understanding of this new problem. We provide bandit learning algorithms for this problem with provable performance guarantees, and provide matching lower bounds.
Is Plug-in Solver Sample-Efficient for Feature-based Reinforcement Learning?
Oct 17, 2020
It is believed that a model-based approach for reinforcement learning (RL) is the key to reduce sample complexity. However, the understanding of the sample optimality of model-based RL is still largely missing, even for the linear case. This work considers sample complexity of finding an $\epsilon$-optimal policy in a Markov decision process (MDP) that admits a linear additive feature representation, given only access to a generative model. We solve this problem via a plug-in solver approach, which builds an empirical model and plans in this empirical model via an arbitrary plug-in solver. We prove that under the anchor-state assumption, which implies implicit non-negativity in the feature space, the minimax sample complexity of finding an $\epsilon$-optimal policy in a $\gamma$-discounted MDP is $O(K/(1-\gamma)^3\epsilon^2)$, which only depends on the dimensionality $K$ of the feature space and has no dependence on the state or action space. We further extend our results to a relaxed setting where anchor-states may not exist and show that a plug-in approach can be sample efficient as well, providing a flexible approach to design model-based algorithms for RL.
Toward the Fundamental Limits of Imitation Learning
Sep 13, 2020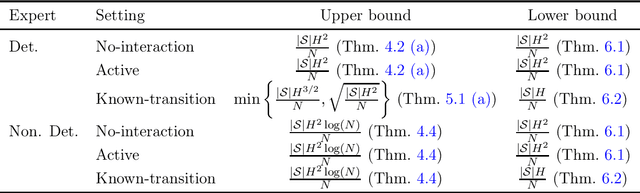
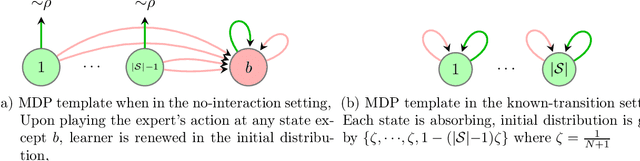
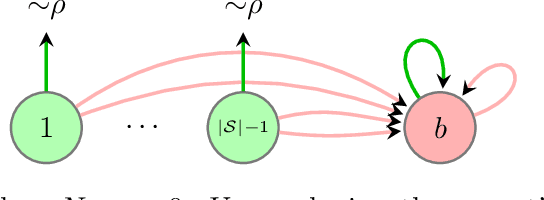
Imitation learning (IL) aims to mimic the behavior of an expert policy in a sequential decision-making problem given only demonstrations. In this paper, we focus on understanding the minimax statistical limits of IL in episodic Markov Decision Processes (MDPs). We first consider the setting where the learner is provided a dataset of $N$ expert trajectories ahead of time, and cannot interact with the MDP. Here, we show that the policy which mimics the expert whenever possible is in expectation $\lesssim \frac{|\mathcal{S}| H^2 \log (N)}{N}$ suboptimal compared to the value of the expert, even when the expert follows an arbitrary stochastic policy. Here $\mathcal{S}$ is the state space, and $H$ is the length of the episode. Furthermore, we establish a suboptimality lower bound of $\gtrsim |\mathcal{S}| H^2 / N$ which applies even if the expert is constrained to be deterministic, or if the learner is allowed to actively query the expert at visited states while interacting with the MDP for $N$ episodes. To our knowledge, this is the first algorithm with suboptimality having no dependence on the number of actions, under no additional assumptions. We then propose a novel algorithm based on minimum-distance functionals in the setting where the transition model is given and the expert is deterministic. The algorithm is suboptimal by $\lesssim \min \{ H \sqrt{|\mathcal{S}| / N} ,\ |\mathcal{S}| H^{3/2} / N \}$, showing that knowledge of transition improves the minimax rate by at least a $\sqrt{H}$ factor.
Obtaining Adjustable Regularization for Free via Iterate Averaging
Aug 15, 2020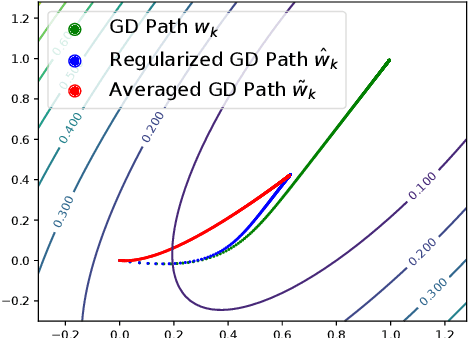
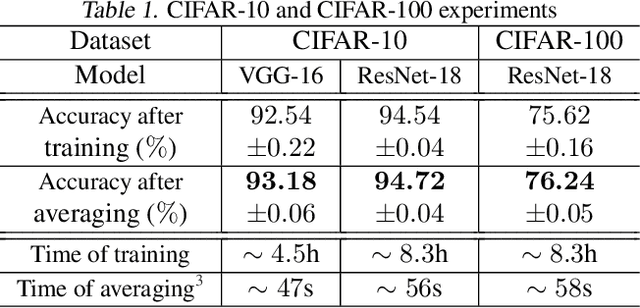

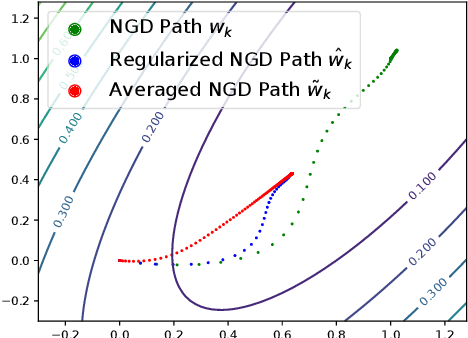
Regularization for optimization is a crucial technique to avoid overfitting in machine learning. In order to obtain the best performance, we usually train a model by tuning the regularization parameters. It becomes costly, however, when a single round of training takes significant amount of time. Very recently, Neu and Rosasco show that if we run stochastic gradient descent (SGD) on linear regression problems, then by averaging the SGD iterates properly, we obtain a regularized solution. It left open whether the same phenomenon can be achieved for other optimization problems and algorithms. In this paper, we establish an averaging scheme that provably converts the iterates of SGD on an arbitrary strongly convex and smooth objective function to its regularized counterpart with an adjustable regularization parameter. Our approaches can be used for accelerated and preconditioned optimization methods as well. We further show that the same methods work empirically on more general optimization objectives including neural networks. In sum, we obtain adjustable regularization for free for a large class of optimization problems and resolve an open question raised by Neu and Rosasco.
Model-Based Multi-Agent RL in Zero-Sum Markov Games with Near-Optimal Sample Complexity
Jul 15, 2020
Model-based reinforcement learning (RL), which finds an optimal policy using an empirical model, has long been recognized as one of the corner stones of RL. It is especially suitable for multi-agent RL (MARL), as it naturally decouples the learning and the planning phases, and avoids the non-stationarity problem when all agents are improving their policies simultaneously using samples. Though intuitive, easy-to-implement, and widely-used, the sample complexity of model-based MARL algorithms has not been fully investigated. In this paper, our goal is to address the fundamental question about its sample complexity. We study arguably the most basic MARL setting: two-player discounted zero-sum Markov games, given only access to a generative model. We show that model-based MARL achieves a sample complexity of $\tilde O(|S||A||B|(1-\gamma)^{-3}\epsilon^{-2})$ for finding the Nash equilibrium (NE) value up to some $\epsilon$ error, and the $\epsilon$-NE policies with a smooth planning oracle, where $\gamma$ is the discount factor, and $S,A,B$ denote the state space, and the action spaces for the two agents. We further show that such a sample bound is minimax-optimal (up to logarithmic factors) if the algorithm is reward-agnostic, where the algorithm queries state transition samples without reward knowledge, by establishing a matching lower bound. This is in contrast to the usual reward-aware setting, with a $\tilde\Omega(|S|(|A|+|B|)(1-\gamma)^{-3}\epsilon^{-2})$ lower bound, where this model-based approach is near-optimal with only a gap on the $|A|,|B|$ dependence. Our results not only demonstrate the sample-efficiency of this basic model-based approach in MARL, but also elaborate on the fundamental tradeoff between its power (easily handling the more challenging reward-agnostic case) and limitation (less adaptive and suboptimal in $|A|,|B|$), particularly arises in the multi-agent context.
On Reward-Free Reinforcement Learning with Linear Function Approximation
Jun 19, 2020
Reward-free reinforcement learning (RL) is a framework which is suitable for both the batch RL setting and the setting where there are many reward functions of interest. During the exploration phase, an agent collects samples without using a pre-specified reward function. After the exploration phase, a reward function is given, and the agent uses samples collected during the exploration phase to compute a near-optimal policy. Jin et al. [2020] showed that in the tabular setting, the agent only needs to collect polynomial number of samples (in terms of the number states, the number of actions, and the planning horizon) for reward-free RL. However, in practice, the number of states and actions can be large, and thus function approximation schemes are required for generalization. In this work, we give both positive and negative results for reward-free RL with linear function approximation. We give an algorithm for reward-free RL in the linear Markov decision process setting where both the transition and the reward admit linear representations. The sample complexity of our algorithm is polynomial in the feature dimension and the planning horizon, and is completely independent of the number of states and actions. We further give an exponential lower bound for reward-free RL in the setting where only the optimal $Q$-function admits a linear representation. Our results imply several interesting exponential separations on the sample complexity of reward-free RL.
Reinforcement Learning with General Value Function Approximation: Provably Efficient Approach via Bounded Eluder Dimension
Jun 19, 2020Value function approximation has demonstrated phenomenal empirical success in reinforcement learning (RL). Nevertheless, despite a handful of recent progress on developing theory for RL with linear function approximation, the understanding of general function approximation schemes largely remains missing. In this paper, we establish a provably efficient RL algorithm with general value function approximation. We show that if the value functions admit an approximation with a function class $\mathcal{F}$, our algorithm achieves a regret bound of $\widetilde{O}(\mathrm{poly}(dH)\sqrt{T})$ where $d$ is a complexity measure of $\mathcal{F}$ that depends on the eluder dimension [Russo and Van Roy, 2013] and log-covering numbers, $H$ is the planning horizon, and $T$ is the number interactions with the environment. Our theory generalizes recent progress on RL with linear value function approximation and does not make explicit assumptions on the model of the environment. Moreover, our algorithm is model-free and provides a framework to justify the effectiveness of algorithms used in practice.
$Q$-learning with Logarithmic Regret
Jun 16, 2020This paper presents the first non-asymptotic result showing that a model-free algorithm can achieve a logarithmic cumulative regret for episodic tabular reinforcement learning if there exists a strictly positive sub-optimality gap in the optimal $Q$-function. We prove that the optimistic $Q$-learning studied in [Jin et al. 2018] enjoys a ${\mathcal{O}}\left(\frac{SA\cdot \mathrm{poly}\left(H\right)}{\mathrm{gap}_{\min}}\log\left(SAT\right)\right)$ cumulative regret bound, where $S$ is the number of states, $A$ is the number of actions, $H$ is the planning horizon, $T$ is the total number of steps, and $\mathrm{gap}_{\min}$ is the minimum sub-optimality gap. This bound matches the information theoretical lower bound in terms of $S,A,T$ up to a $\log\left(SA\right)$ factor. We further extend our analysis to the discounted setting and obtain a similar logarithmic cumulative regret bound.