 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaintHuman: Towards High-fidelity Text-to-3D Human Texturing via Denoised Score Distillation
Oct 14, 2023



Recent advances in zero-shot text-to-3D human generation, which employ the human model prior (eg, SMPL) or Score Distillation Sampling (SDS) with pre-trained text-to-image diffusion models, have been groundbreaking. However, SDS may provide inaccurate gradient directions under the weak diffusion guidance, as it tends to produce over-smoothed results and generate body textures that are inconsistent with the detailed mesh geometry. Therefore, directly leverage existing strategies for high-fidelity text-to-3D human texturing is challenging. In this work, we propose a model called PaintHuman to addresses the challenges from two aspects. We first propose a novel score function, Denoised Score Distillation (DSD), which directly modifies the SDS by introducing negative gradient components to iteratively correct the gradient direction and generate high-quality textures. In addition, we use the depth map as a geometric guidance to ensure the texture is semantically aligned to human mesh surfaces. To guarantee the quality of rendered results, we employ geometry-aware networks to predict surface materials and render realistic human textures. Extensive experiments, benchmarked against state-of-the-art methods, validate the efficacy of our approach.
StyleInV: A Temporal Style Modulated Inversion Network for Unconditional Video Generation
Aug 31, 2023



Unconditional video generation is a challenging task that involves synthesizing high-quality videos that are both coherent and of extended duration. To address this challenge, researchers have used pretrained StyleGAN image generators for high-quality frame synthesis and focused on motion generator design. The motion generator is trained in an autoregressive manner using heavy 3D convolutional discriminators to ensure motion coherence during video generation. In this paper, we introduce a novel motion generator design that uses a learning-based inversion network for GAN. The encoder in our method captures rich and smooth priors from encoding images to latents, and given the latent of an initially generated frame as guidance, our method can generate smooth future latent by modulating the inversion encoder temporally. Our method enjoys the advantage of sparse training and naturally constrains the generation space of our motion generator with the inversion network guided by the initial frame, eliminating the need for heavy discriminators. Moreover, our method supports style transfer with simple fine-tuning when the encoder is paired with a pretrained StyleGAN generator. Extensive experiments conducted on various benchmarks demonstrate the superiority of our method in generating long and high-resolution videos with decent single-frame quality and temporal consistency.
Scenimefy: Learning to Craft Anime Scene via Semi-Supervised Image-to-Image Translation
Aug 24, 2023



Automatic high-quality rendering of anime scenes from complex real-world images is of significant practical value. The challenges of this task lie in the complexity of the scenes, the unique features of anime style, and the lack of high-quality datasets to bridge the domain gap. Despite promising attempts, previous efforts are still incompetent in achieving satisfactory results with consistent semantic preservation, evident stylization, and fine details. In this study, we propose Scenimefy, a novel semi-supervised image-to-image translation framework that addresses these challenges. Our approach guides the learning with structure-consistent pseudo paired data, simplifying the pure unsupervised setting. The pseudo data are derived uniquely from a semantic-constrained StyleGAN leveraging rich model priors like CLIP. We further apply segmentation-guided data selection to obtain high-quality pseudo supervision. A patch-wise contrastive style loss is introduced to improve stylization and fine details. Besides, we contribute a high-resolution anime scene dataset to facilitate future research. Our extensive experiments demonstrate the superiority of our method over state-of-the-art baselines in terms of both perceptual quality and quantitative performance.
GP-UNIT: Generative Prior for Versatile Unsupervised Image-to-Image Translation
Jun 07, 2023Recent advances in deep learning have witnessed many successful unsupervised image-to-image translation models that learn correspondences between two visual domains without paired data. However, it is still a great challenge to build robust mappings between various domains especially for those with drastic visual discrepancies. In this paper, we introduce a novel versatile framework, Generative Prior-guided UNsupervised Image-to-image Translation (GP-UNIT), that improves the quality, applicability and controllability of the existing translation models. The key idea of GP-UNIT is to distill the generative prior from pre-trained class-conditional GANs to build coarse-level cross-domain correspondences, and to apply the learned prior to adversarial translations to excavate fine-level correspondences. With the learned multi-level content correspondences, GP-UNIT is able to perform valid translations between both close domains and distant domains. For close domains, GP-UNIT can be conditioned on a parameter to determine the intensity of the content correspondences during translation, allowing users to balance between content and style consistency. For distant domains, semi-supervised learning is explored to guide GP-UNIT to discover accurate semantic correspondences that are hard to learn solely from the appearance. We validate the superiority of GP-UNIT over state-of-the-art translation models in robust, high-quality and diversified translations between various domains through extensive experiments.
CelebV-Text: A Large-Scale Facial Text-Video Dataset
Mar 26, 2023Text-driven generation models are flourishing in video generation and editing. However, face-centric text-to-video generation remains a challenge due to the lack of a suitable dataset containing high-quality videos and highly relevant texts. This paper presents CelebV-Text, a large-scale, diverse, and high-quality dataset of facial text-video pairs, to facilitate research on facial text-to-video generation tasks. CelebV-Text comprises 70,000 in-the-wild face video clips with diverse visual content, each paired with 20 texts generated using the proposed semi-automatic text generation strategy. The provided texts are of high quality, describing both static and dynamic attributes precisely. The superiority of CelebV-Text over other datasets is demonstrated via comprehensive statistical analysis of the videos, texts, and text-video relevance. The effectiveness and potential of CelebV-Text are further shown through extensive self-evaluation. A benchmark is constructed with representative methods to standardize the evaluation of the facial text-to-video generation task. All data and models are publicly available.
StyleGANEX: StyleGAN-Based Manipulation Beyond Cropped Aligned Faces
Mar 10, 2023



Recent advances in face manipulation using StyleGAN have produced impressive results. However, StyleGAN is inherently limited to cropped aligned faces at a fixed image resolution it is pre-trained on. In this paper, we propose a simple and effective solution to this limitation by using dilated convolutions to rescale the receptive fields of shallow layers in StyleGAN, without altering any model parameters. This allows fixed-size small features at shallow layers to be extended into larger ones that can accommodate variable resolutions, making them more robust in characterizing unaligned faces. To enable real face inversion and manipulation, we introduce a corresponding encoder that provides the first-layer feature of the extended StyleGAN in addition to the latent style code. We validate the effectiveness of our method using unaligned face inputs of various resolutions in a diverse set of face manipulation tasks, including facial attribute editing, super-resolution, sketch/mask-to-face translation, and face toonification.
VToonify: Controllable High-Resolution Portrait Video Style Transfer
Sep 30, 2022


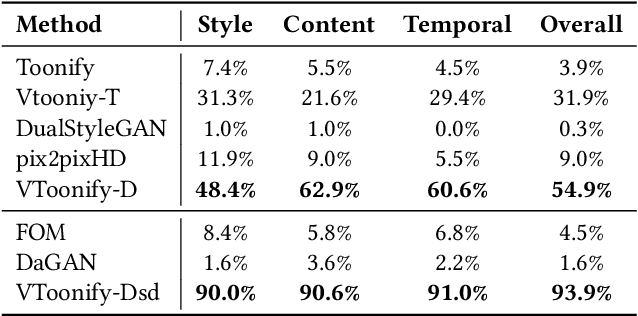
Generating high-quality artistic portrait videos is an important and desirable task in computer graphics and vision. Although a series of successful portrait image toonification models built upon the powerful StyleGAN have been proposed, these image-oriented methods have obvious limitations when applied to videos, such as the fixed frame size, the requirement of face alignment, missing non-facial details and temporal inconsistency. In this work, we investigate the challenging controllable high-resolution portrait video style transfer by introducing a novel VToonify framework. Specifically, VToonify leverages the mid- and high-resolution layers of StyleGAN to render high-quality artistic portraits based on the multi-scale content features extracted by an encoder to better preserve the frame details. The resulting fully convolutional architecture accepts non-aligned faces in videos of variable size as input, contributing to complete face regions with natural motions in the output. Our framework is compatible with existing StyleGAN-based image toonification models to extend them to video toonification, and inherits appealing features of these models for flexible style control on color and intensity. This work presents two instantiations of VToonify built upon Toonify and DualStyleGAN for collection-based and exemplar-based portrait video style transfer, respectively. Extensive experimental results demonstrate the effectiveness of our proposed VToonify framework over existing methods in generating high-quality and temporally-coherent artistic portrait videos with flexible style controls.
CelebV-HQ: A Large-Scale Video Facial Attributes Dataset
Jul 25, 2022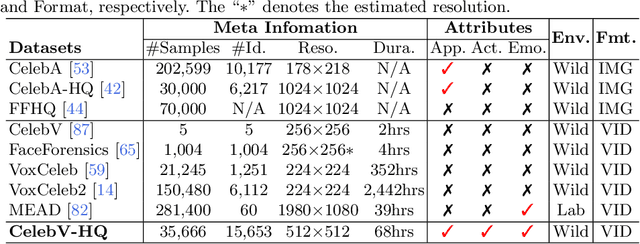
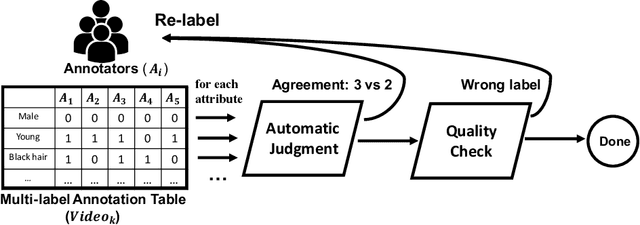

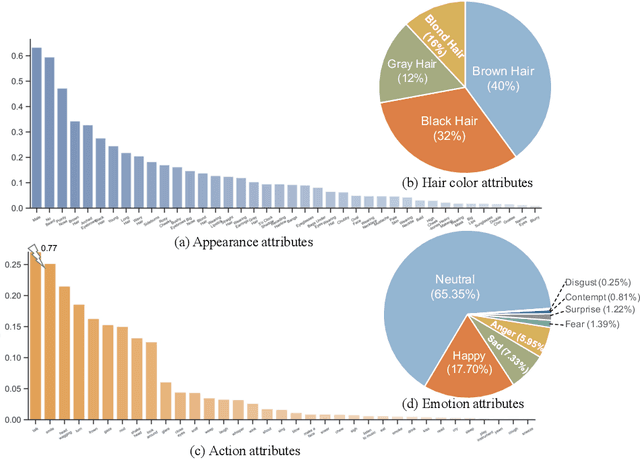
Large-scale datasets have played indispensable roles in the recent success of face generation/editing and significantly facilitated the advances of emerging research fields. However, the academic community still lacks a video dataset with diverse facial attribute annotations, which is crucial for the research on face-related videos. In this work, we propose a large-scale, high-quality, and diverse video dataset with rich facial attribute annotations, named the High-Quality Celebrity Video Dataset (CelebV-HQ). CelebV-HQ contains 35,666 video clips with the resolution of 512x512 at least, involving 15,653 identities. All clips are labeled manually with 83 facial attributes, covering appearance, action, and emotion. We conduct a comprehensive analysis in terms of age, ethnicity, brightness stability, motion smoothness, head pose diversity, and data quality to demonstrate the diversity and temporal coherence of CelebV-HQ. Besides, its versatility and potential are validated on two representative tasks, i.e., unconditional video generation and video facial attribute editing. Furthermore, we envision the future potential of CelebV-HQ, as well as the new opportunities and challenges it would bring to related research directions. Data, code, and models are publicly available. Project page: https://celebv-hq.github.io.
Delving into High-Quality Synthetic Face Occlusion Segmentation Datasets
May 12, 2022


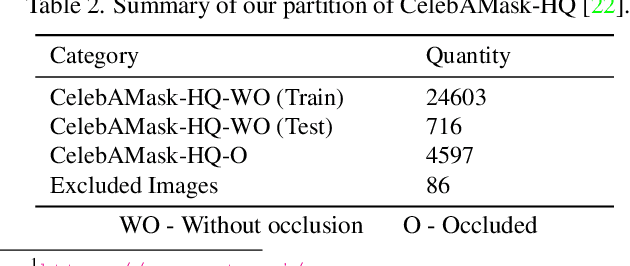
This paper performs comprehensive analysis on datasets for occlusion-aware face segmentation, a task that is crucial for many downstream applications. The collection and annotation of such datasets are time-consuming and labor-intensive. Although some efforts have been made in synthetic data generation, the naturalistic aspect of data remains less explored. In our study, we propose two occlusion generation techniques, Naturalistic Occlusion Generation (NatOcc), for producing high-quality naturalistic synthetic occluded faces; and Random Occlusion Generation (RandOcc), a more general synthetic occluded data generation method. We empirically show the effectiveness and robustness of both methods, even for unseen occlusions. To facilitate model evaluation, we present two high-resolution real-world occluded face datasets with fine-grained annotations, RealOcc and RealOcc-Wild, featuring both careful alignment preprocessing and an in-the-wild setting for robustness test. We further conduct a comprehensive analysis on a newly introduced segmentation benchmark, offering insights for future exploration.
Unsupervised Image-to-Image Translation with Generative Prior
Apr 07, 2022

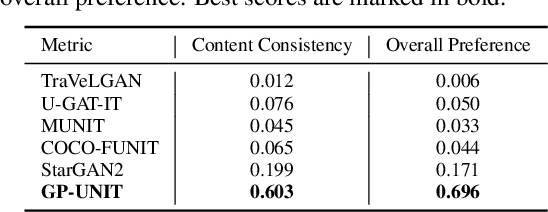

Unsupervised image-to-image translation aims to learn the translation between two visual domains without paired data. Despite the recent progress in image translation models, it remains challenging to build mappings between complex domains with drastic visual discrepancies. In this work, we present a novel framework, Generative Prior-guided UNsupervised Image-to-image Translation (GP-UNIT), to improve the overall quality and applicability of the translation algorithm. Our key insight is to leverage the generative prior from pre-trained class-conditional GANs (e.g., BigGAN) to learn rich content correspondences across various domains. We propose a novel coarse-to-fine scheme: we first distill the generative prior to capture a robust coarse-level content representation that can link objects at an abstract semantic level, based on which fine-level content features are adaptively learned for more accurate multi-level content correspondences. Extensive experiments demonstrate the superiority of our versatile framework over state-of-the-art methods in robust, high-quality and diversified translations, even for challenging and distant domains.