 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning with a Natural Language Action Space
Jun 08, 2016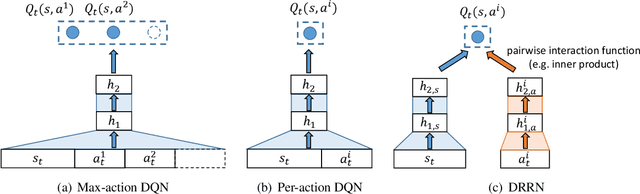
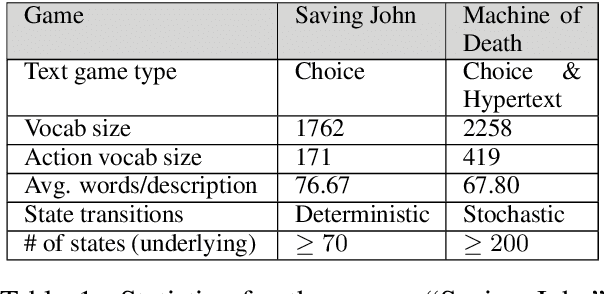
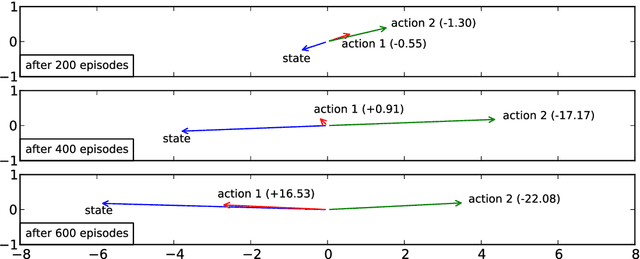
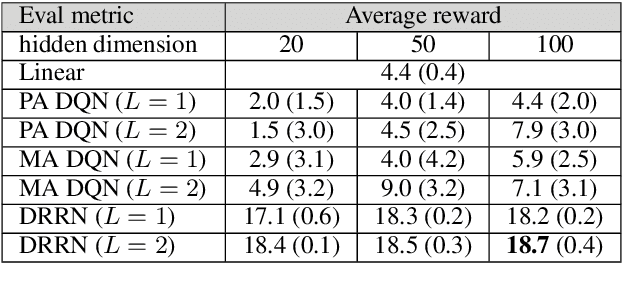
This paper introduces a novel architecture for reinforcement learning with deep neural networks designed to handle state and action spaces characterized by natural language, as found in text-based games. Termed a deep reinforcement relevance network (DRRN), the architecture represents action and state spaces with separate embedding vectors, which are combined with an interaction function to approximate the Q-function in reinforcement learning. We evaluate the DRRN on two popular text games, showing superior performance over other deep Q-learning architectures. Experiments with paraphrased action descriptions show that the model is extracting meaning rather than simply memorizing strings of text.
Doubly Robust Off-policy Value Evaluation for Reinforcement Learning
May 26, 2016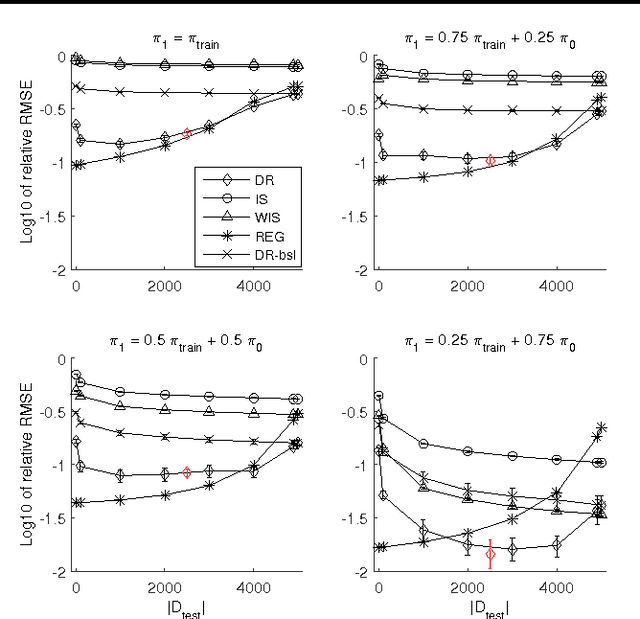
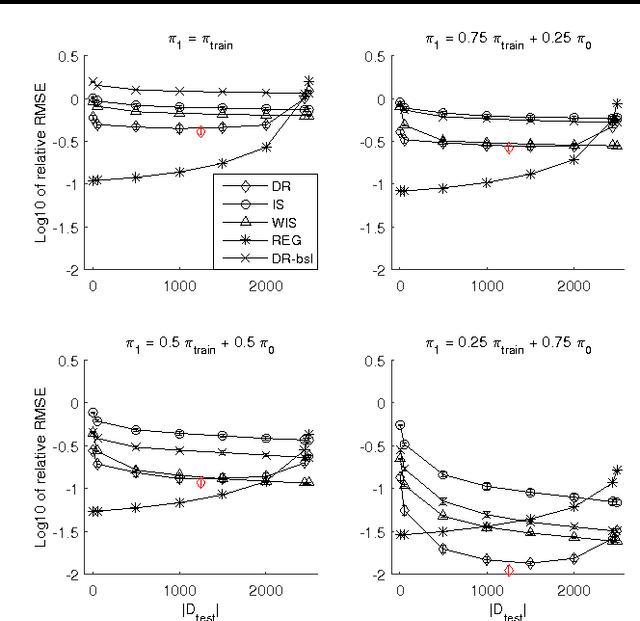
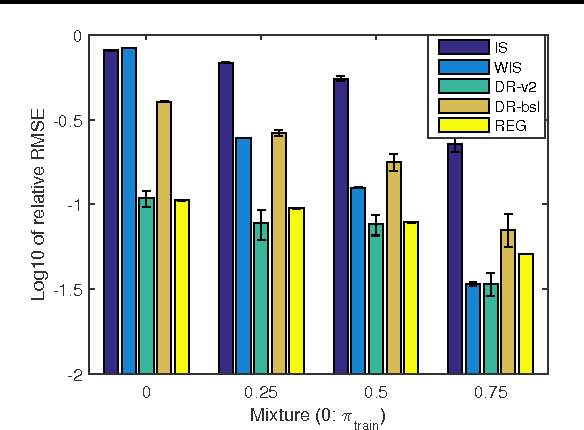
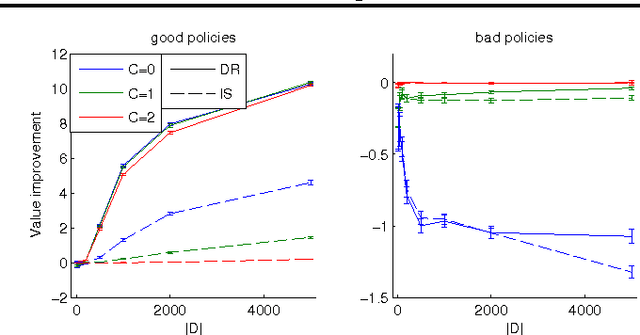
We study the problem of off-policy value evaluation in reinforcement learning (RL), where one aims to estimate the value of a new policy based on data collected by a different policy. This problem is often a critical step when applying RL in real-world problems. Despite its importance, existing general methods either have uncontrolled bias or suffer high variance. In this work, we extend the doubly robust estimator for bandits to sequential decision-making problems, which gets the best of both worlds: it is guaranteed to be unbiased and can have a much lower variance than the popular importance sampling estimators. We demonstrate the estimator's accuracy in several benchmark problems, and illustrate its use as a subroutine in safe policy improvement. We also provide theoretical results on the hardness of the problem, and show that our estimator can match the lower bound in certain scenarios.
Recurrent Reinforcement Learning: A Hybrid Approach
Nov 19, 2015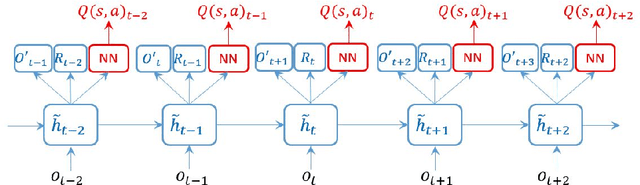
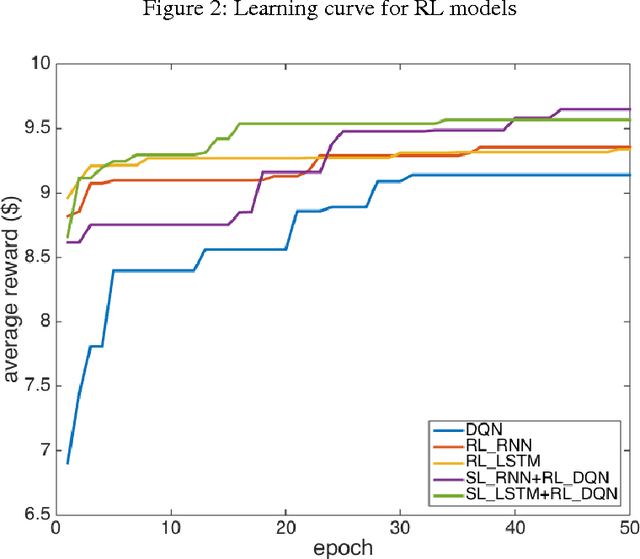
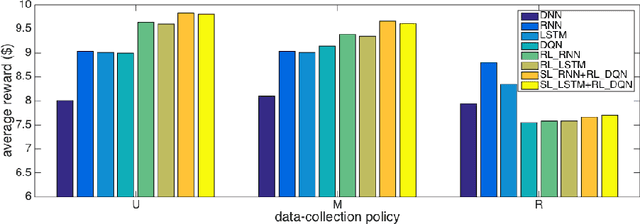
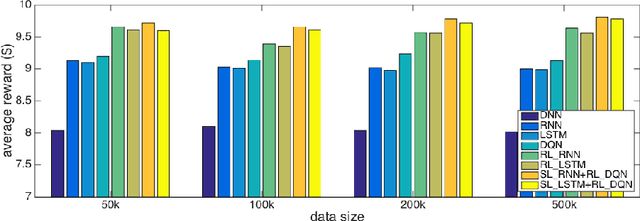
Successful applications of reinforcement learning in real-world problems often require dealing with partially observable states. It is in general very challenging to construct and infer hidden states as they often depend on the agent's entire interaction history and may require substantial domain knowledge. In this work, we investigate a deep-learning approach to learning the representation of states in partially observable tasks, with minimal prior knowledge of the domain. In particular, we propose a new family of hybrid models that combines the strength of both supervised learning (SL) and reinforcement learning (RL), trained in a joint fashion: The SL component can be a recurrent neural networks (RNN) or its long short-term memory (LSTM) version, which is equipped with the desired property of being able to capture long-term dependency on history, thus providing an effective way of learning the representation of hidden states. The RL component is a deep Q-network (DQN) that learns to optimize the control for maximizing long-term rewards. Extensive experiments in a direct mailing campaign problem demonstrate the effectiveness and advantages of the proposed approach, which performs the best among a set of previous state-of-the-art methods.
The Online Coupon-Collector Problem and Its Application to Lifelong Reinforcement Learning
Sep 21, 2015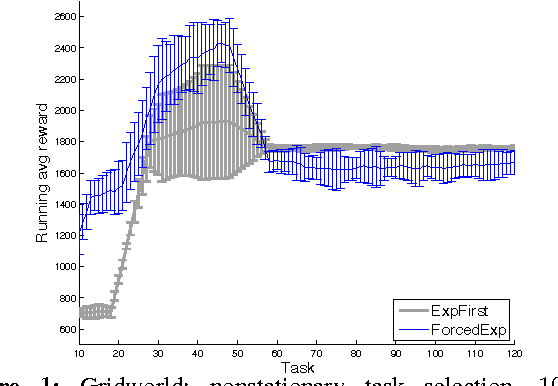

Transferring knowledge across a sequence of related tasks is an important challenge in reinforcement learning (RL). Despite much encouraging empirical evidence, there has been little theoretical analysis. In this paper, we study a class of lifelong RL problems: the agent solves a sequence of tasks modeled as finite Markov decision processes (MDPs), each of which is from a finite set of MDPs with the same state/action sets and different transition/reward functions. Motivated by the need for cross-task exploration in lifelong learning, we formulate a novel online coupon-collector problem and give an optimal algorithm. This allows us to develop a new lifelong RL algorithm, whose overall sample complexity in a sequence of tasks is much smaller than single-task learning, even if the sequence of tasks is generated by an adversary. Benefits of the algorithm are demonstrated in simulated problems, including a recently introduced human-robot interaction problem.
Evaluation of Explore-Exploit Policies in Multi-result Ranking Systems
Apr 28, 2015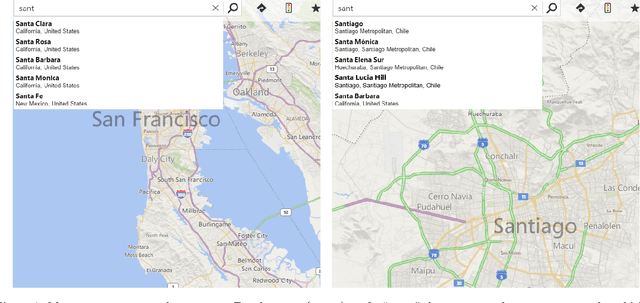
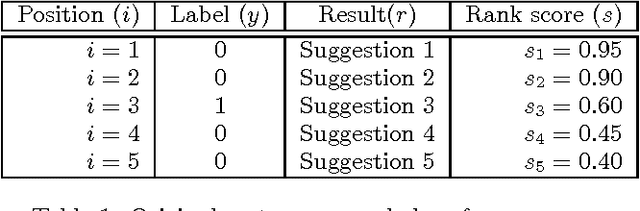
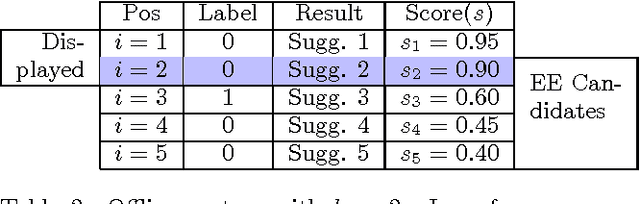
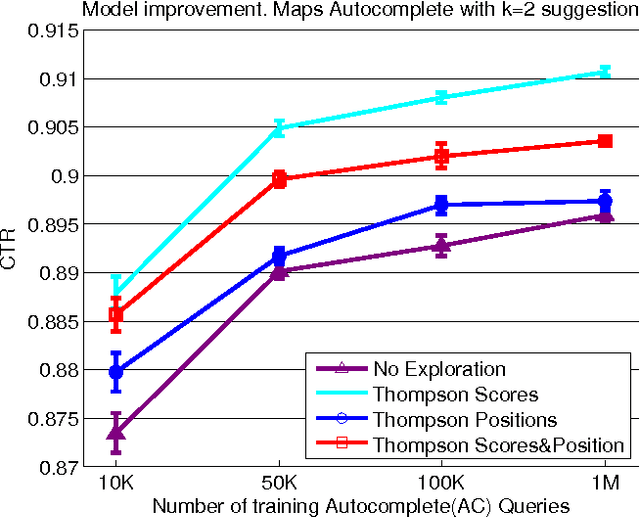
We analyze the problem of using Explore-Exploit techniques to improve precision in multi-result ranking systems such as web search, query autocompletion and news recommendation. Adopting an exploration policy directly online, without understanding its impact on the production system, may have unwanted consequences - the system may sustain large losses, create user dissatisfaction, or collect exploration data which does not help improve ranking quality. An offline framework is thus necessary to let us decide what policy and how we should apply in a production environment to ensure positive outcome. Here, we describe such an offline framework. Using the framework, we study a popular exploration policy - Thompson sampling. We show that there are different ways of implementing it in multi-result ranking systems, each having different semantic interpretation and leading to different results in terms of sustained click-through-rate (CTR) loss and expected model improvement. In particular, we demonstrate that Thompson sampling can act as an online learner optimizing CTR, which in some cases can lead to an interesting outcome: lift in CTR during exploration. The observation is important for production systems as it suggests that one can get both valuable exploration data to improve ranking performance on the long run, and at the same time increase CTR while exploration lasts.
Doubly Robust Policy Evaluation and Optimization
Mar 10, 2015
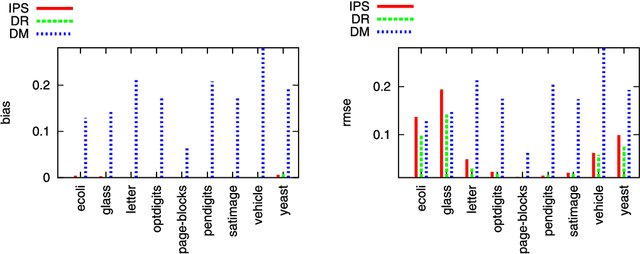
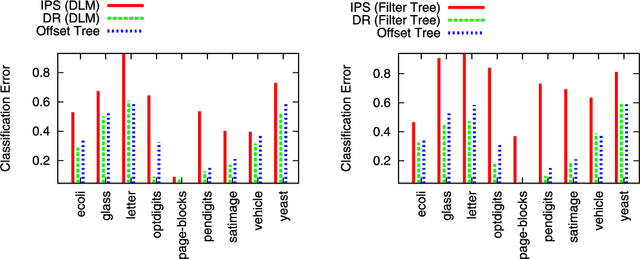
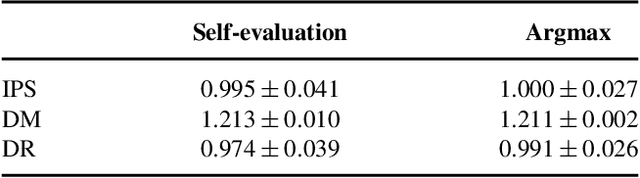
We study sequential decision making in environments where rewards are only partially observed, but can be modeled as a function of observed contexts and the chosen action by the decision maker. This setting, known as contextual bandits, encompasses a wide variety of applications such as health care, content recommendation and Internet advertising. A central task is evaluation of a new policy given historic data consisting of contexts, actions and received rewards. The key challenge is that the past data typically does not faithfully represent proportions of actions taken by a new policy. Previous approaches rely either on models of rewards or models of the past policy. The former are plagued by a large bias whereas the latter have a large variance. In this work, we leverage the strengths and overcome the weaknesses of the two approaches by applying the doubly robust estimation technique to the problems of policy evaluation and optimization. We prove that this approach yields accurate value estimates when we have either a good (but not necessarily consistent) model of rewards or a good (but not necessarily consistent) model of past policy. Extensive empirical comparison demonstrates that the doubly robust estimation uniformly improves over existing techniques, achieving both lower variance in value estimation and better policies. As such, we expect the doubly robust approach to become common practice in policy evaluation and optimization.
* Published in at http://dx.doi.org/10.1214/14-STS500 the Statistical Science (http://www.imstat.org/sts/) by the Institute of Mathematical Statistics (http://www.imstat.org)
Taming the Monster: A Fast and Simple Algorithm for Contextual Bandits
Oct 14, 2014
We present a new algorithm for the contextual bandit learning problem, where the learner repeatedly takes one of $K$ actions in response to the observed context, and observes the reward only for that chosen action. Our method assumes access to an oracle for solving fully supervised cost-sensitive classification problems and achieves the statistically optimal regret guarantee with only $\tilde{O}(\sqrt{KT/\log N})$ oracle calls across all $T$ rounds, where $N$ is the number of policies in the policy class we compete against. By doing so, we obtain the most practical contextual bandit learning algorithm amongst approaches that work for general policy classes. We further conduct a proof-of-concept experiment which demonstrates the excellent computational and prediction performance of (an online variant of) our algorithm relative to several baselines.
On Minimax Optimal Offline Policy Evaluation
Sep 12, 2014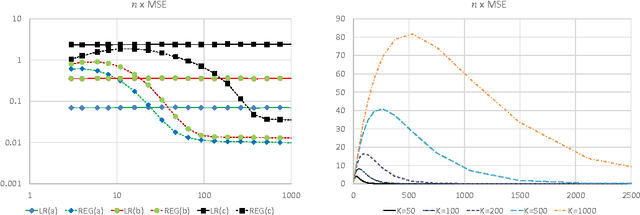
This paper studies the off-policy evaluation problem, where one aims to estimate the value of a target policy based on a sample of observations collected by another policy. We first consider the multi-armed bandit case, establish a minimax risk lower bound, and analyze the risk of two standard estimators. It is shown, and verified in simulation, that one is minimax optimal up to a constant, while another can be arbitrarily worse, despite its empirical success and popularity. The results are applied to related problems in contextual bandits and fixed-horizon Markov decision processes, and are also related to semi-supervised learning.
Counterfactual Estimation and Optimization of Click Metrics for Search Engines
Mar 12, 2014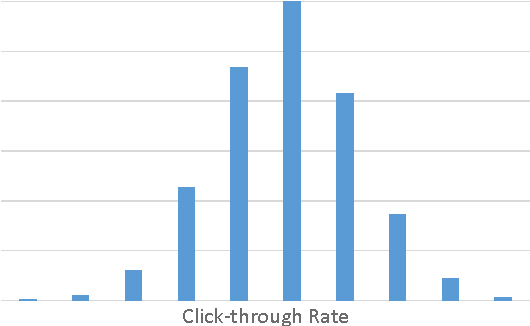
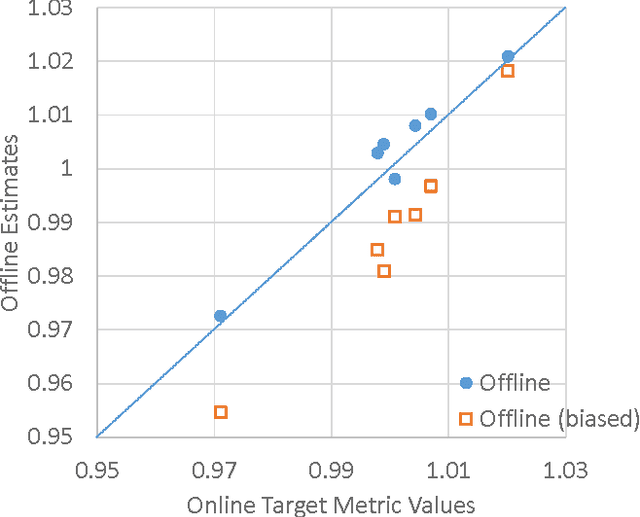
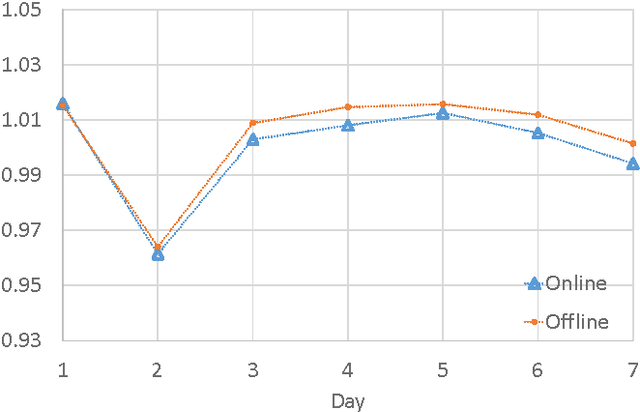
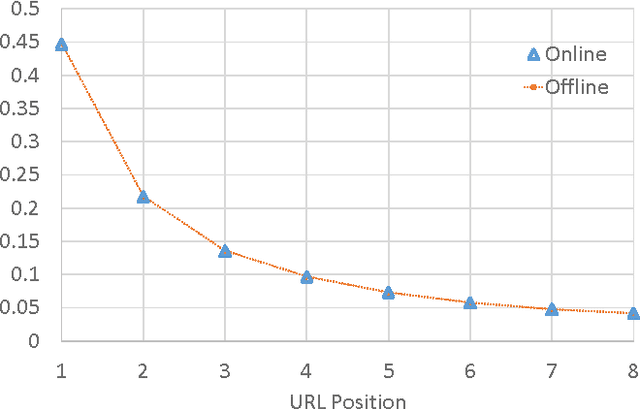
Optimizing an interactive system against a predefined online metric is particularly challenging, when the metric is computed from user feedback such as clicks and payments. The key challenge is the counterfactual nature: in the case of Web search, any change to a component of the search engine may result in a different search result page for the same query, but we normally cannot infer reliably from search log how users would react to the new result page. Consequently, it appears impossible to accurately estimate online metrics that depend on user feedback, unless the new engine is run to serve users and compared with a baseline in an A/B test. This approach, while valid and successful, is unfortunately expensive and time-consuming. In this paper, we propose to address this problem using causal inference techniques, under the contextual-bandit framework. This approach effectively allows one to run (potentially infinitely) many A/B tests offline from search log, making it possible to estimate and optimize online metrics quickly and inexpensively. Focusing on an important component in a commercial search engine, we show how these ideas can be instantiated and applied, and obtain very promising results that suggest the wide applicability of these techniques.
Efficient Online Bootstrapping for Large Scale Learning
Dec 18, 2013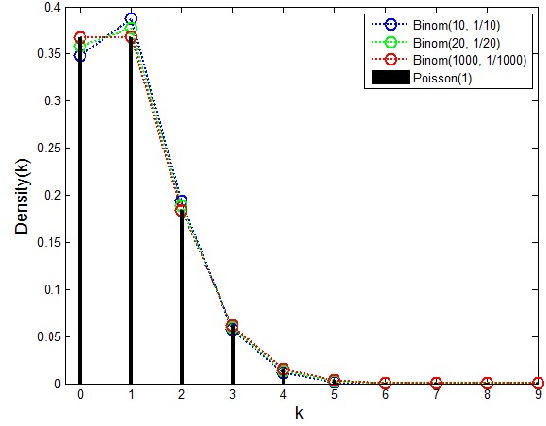
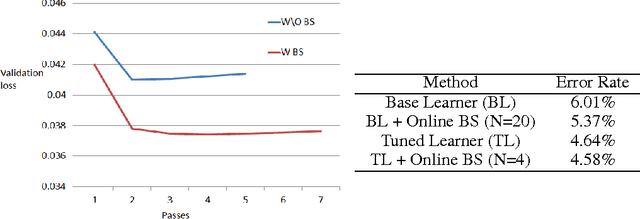
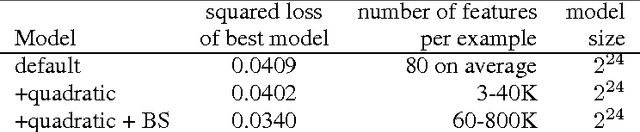
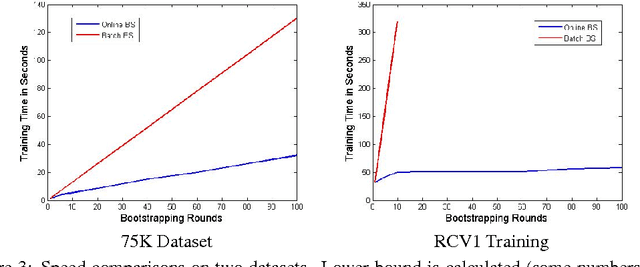
Bootstrapping is a useful technique for estimating the uncertainty of a predictor, for example, confidence intervals for prediction. It is typically used on small to moderate sized datasets, due to its high computation cost. This work describes a highly scalable online bootstrapping strategy, implemented inside Vowpal Wabbit, that is several times faster than traditional strategies. Our experiments indicate that, in addition to providing a black box-like method for estimating uncertainty, our implementation of online bootstrapping may also help to train models with better prediction performance due to model averaging.