 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComposite Task-Completion Dialogue Policy Learning via Hierarchical Deep Reinforcement Learning
Jul 22, 2017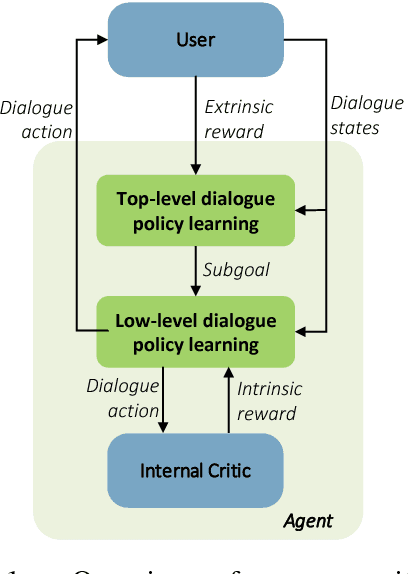
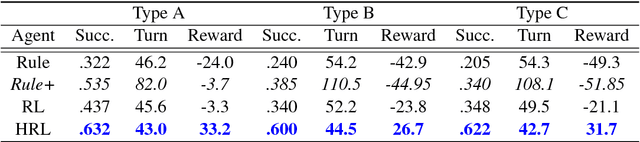
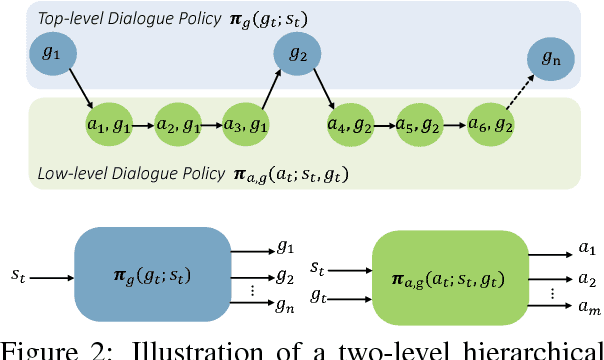
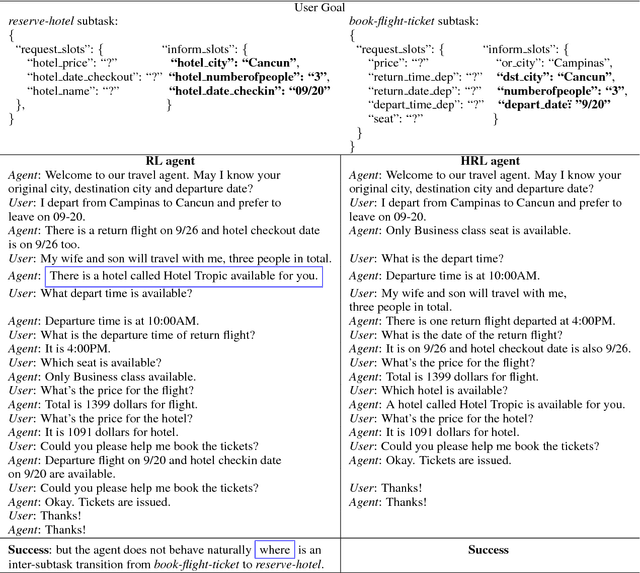
Building a dialogue agent to fulfill complex tasks, such as travel planning, is challenging because the agent has to learn to collectively complete multiple subtasks. For example, the agent needs to reserve a hotel and book a flight so that there leaves enough time for commute between arrival and hotel check-in. This paper addresses this challenge by formulating the task in the mathematical framework of options over Markov Decision Processes (MDPs), and proposing a hierarchical deep reinforcement learning approach to learning a dialogue manager that operates at different temporal scales. The dialogue manager consists of: (1) a top-level dialogue policy that selects among subtasks or options, (2) a low-level dialogue policy that selects primitive actions to complete the subtask given by the top-level policy, and (3) a global state tracker that helps ensure all cross-subtask constraints be satisfied. Experiments on a travel planning task with simulated and real users show that our approach leads to significant improvements over three baselines, two based on handcrafted rules and the other based on flat deep reinforcement learning.
Provably Optimal Algorithms for Generalized Linear Contextual Bandits
Jun 18, 2017Contextual bandits are widely used in Internet services from news recommendation to advertising, and to Web search. Generalized linear models (logistical regression in particular) have demonstrated stronger performance than linear models in many applications where rewards are binary. However, most theoretical analyses on contextual bandits so far are on linear bandits. In this work, we propose an upper confidence bound based algorithm for generalized linear contextual bandits, which achieves an $\tilde{O}(\sqrt{dT})$ regret over $T$ rounds with $d$ dimensional feature vectors. This regret matches the minimax lower bound, up to logarithmic terms, and improves on the best previous result by a $\sqrt{d}$ factor, assuming the number of arms is fixed. A key component in our analysis is to establish a new, sharp finite-sample confidence bound for maximum-likelihood estimates in generalized linear models, which may be of independent interest. We also analyze a simpler upper confidence bound algorithm, which is useful in practice, and prove it to have optimal regret for certain cases.
Stochastic Variance Reduction Methods for Policy Evaluation
Jun 09, 2017
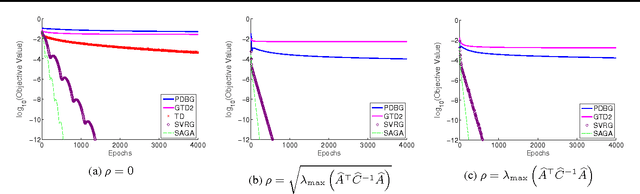
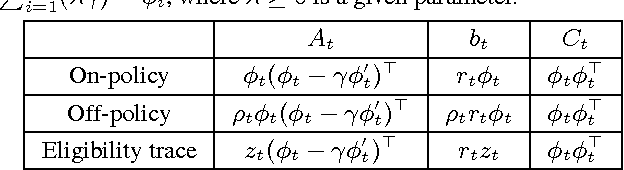
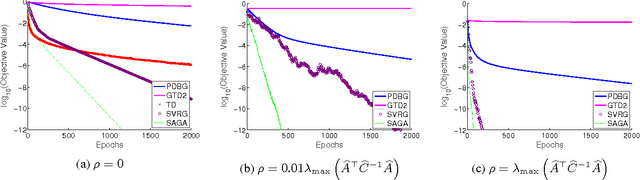
Policy evaluation is a crucial step in many reinforcement-learning procedures, which estimates a value function that predicts states' long-term value under a given policy. In this paper, we focus on policy evaluation with linear function approximation over a fixed dataset. We first transform the empirical policy evaluation problem into a (quadratic) convex-concave saddle point problem, and then present a primal-dual batch gradient method, as well as two stochastic variance reduction methods for solving the problem. These algorithms scale linearly in both sample size and feature dimension. Moreover, they achieve linear convergence even when the saddle-point problem has only strong concavity in the dual variables but no strong convexity in the primal variables. Numerical experiments on benchmark problems demonstrate the effectiveness of our methods.
Scaffolding Networks: Incremental Learning and Teaching Through Questioning
May 19, 2017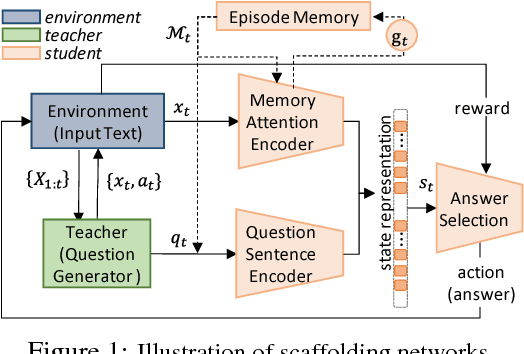

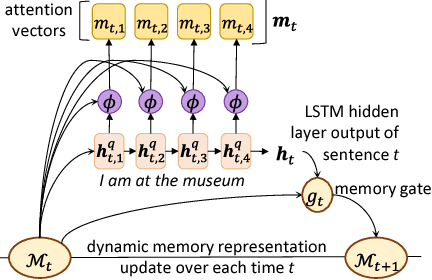
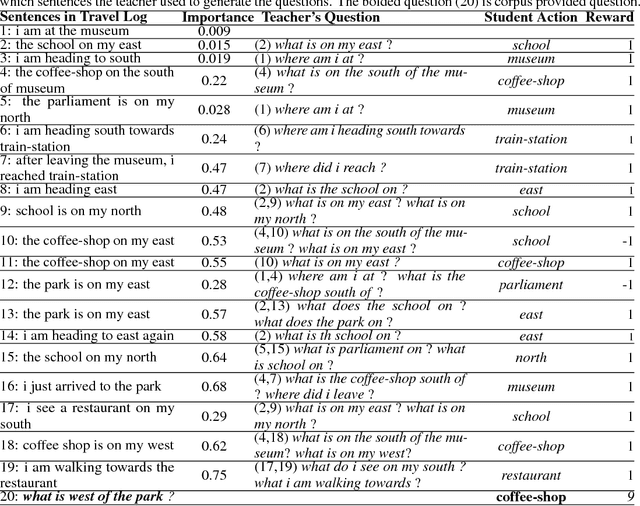
We introduce a new paradigm of learning for reasoning, understanding, and prediction, as well as the scaffolding network to implement this paradigm. The scaffolding network embodies an incremental learning approach that is formulated as a teacher-student network architecture to teach machines how to understand text and do reasoning. The key to our computational scaffolding approach is the interactions between the teacher and the student through sequential questioning. The student observes each sentence in the text incrementally, and it uses an attention-based neural net to discover and register the key information in relation to its current memory. Meanwhile, the teacher asks questions about the observed text, and the student network gets rewarded by correctly answering these questions. The entire network is updated continually using reinforcement learning. Our experimental results on synthetic and real datasets show that the scaffolding network not only outperforms state-of-the-art methods but also learns to do reasoning in a scalable way even with little human generated input.
Towards End-to-End Reinforcement Learning of Dialogue Agents for Information Access
Apr 20, 2017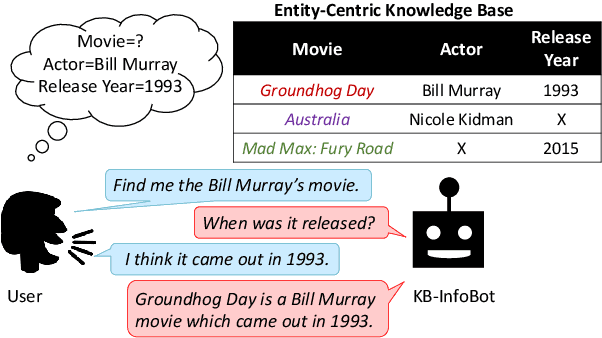
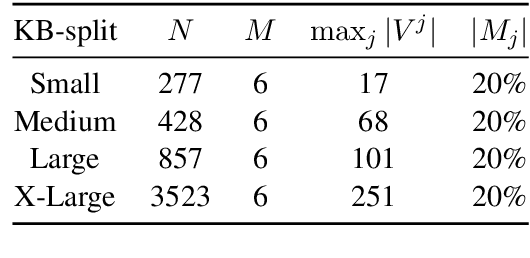
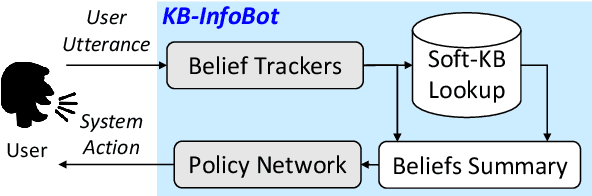
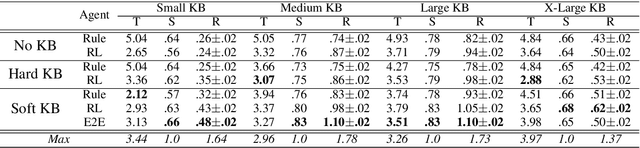
This paper proposes KB-InfoBot -- a multi-turn dialogue agent which helps users search Knowledge Bases (KBs) without composing complicated queries. Such goal-oriented dialogue agents typically need to interact with an external database to access real-world knowledge. Previous systems achieved this by issuing a symbolic query to the KB to retrieve entries based on their attributes. However, such symbolic operations break the differentiability of the system and prevent end-to-end training of neural dialogue agents. In this paper, we address this limitation by replacing symbolic queries with an induced "soft" posterior distribution over the KB that indicates which entities the user is interested in. Integrating the soft retrieval process with a reinforcement learner leads to higher task success rate and reward in both simulations and against real users. We also present a fully neural end-to-end agent, trained entirely from user feedback, and discuss its application towards personalized dialogue agents. The source code is available at https://github.com/MiuLab/KB-InfoBot.
Investigation of Language Understanding Impact for Reinforcement Learning Based Dialogue Systems
Mar 21, 2017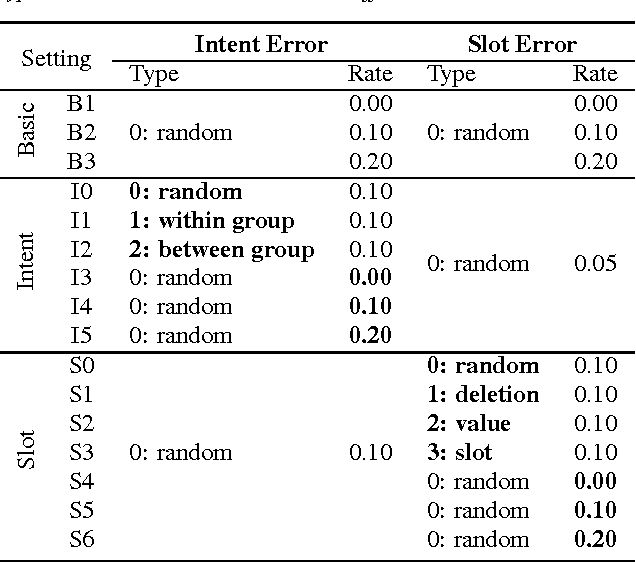
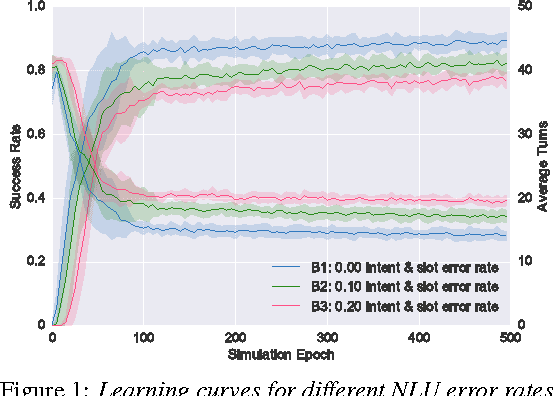
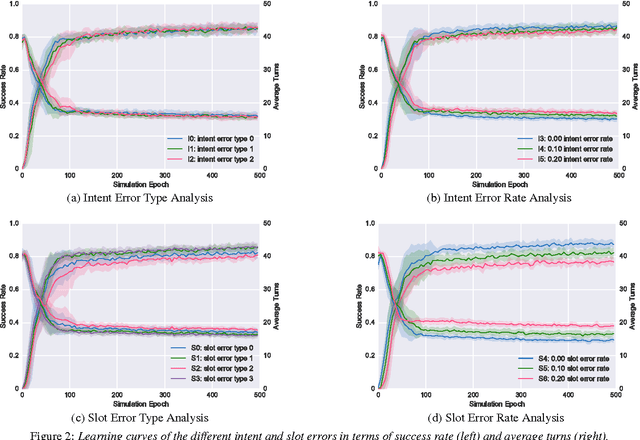
Language understanding is a key component in a spoken dialogue system. In this paper, we investigate how the language understanding module influences the dialogue system performance by conducting a series of systematic experiments on a task-oriented neural dialogue system in a reinforcement learning based setting. The empirical study shows that among different types of language understanding errors, slot-level errors can have more impact on the overall performance of a dialogue system compared to intent-level errors. In addition, our experiments demonstrate that the reinforcement learning based dialogue system is able to learn when and what to confirm in order to achieve better performance and greater robustness.
Neuro-Symbolic Program Synthesis
Nov 06, 2016
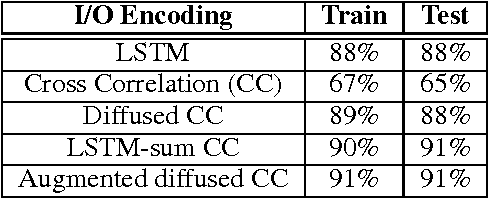
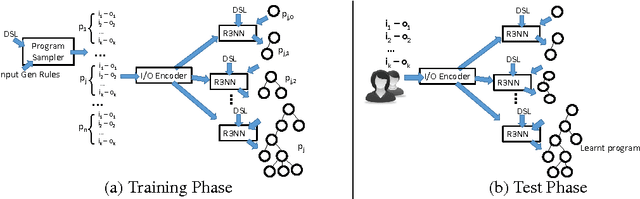
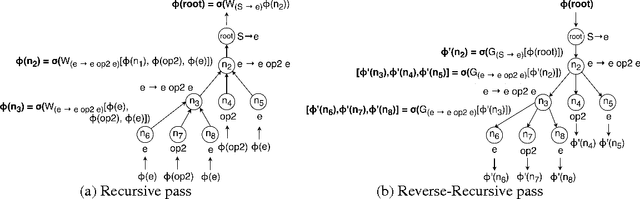
Recent years have seen the proposal of a number of neural architectures for the problem of Program Induction. Given a set of input-output examples, these architectures are able to learn mappings that generalize to new test inputs. While achieving impressive results, these approaches have a number of important limitations: (a) they are computationally expensive and hard to train, (b) a model has to be trained for each task (program) separately, and (c) it is hard to interpret or verify the correctness of the learnt mapping (as it is defined by a neural network). In this paper, we propose a novel technique, Neuro-Symbolic Program Synthesis, to overcome the above-mentioned problems. Once trained, our approach can automatically construct computer programs in a domain-specific language that are consistent with a set of input-output examples provided at test time. Our method is based on two novel neural modules. The first module, called the cross correlation I/O network, given a set of input-output examples, produces a continuous representation of the set of I/O examples. The second module, the Recursive-Reverse-Recursive Neural Network (R3NN), given the continuous representation of the examples, synthesizes a program by incrementally expanding partial programs. We demonstrate the effectiveness of our approach by applying it to the rich and complex domain of regular expression based string transformations. Experiments show that the R3NN model is not only able to construct programs from new input-output examples, but it is also able to construct new programs for tasks that it had never observed before during training.
Deep Reinforcement Learning with a Combinatorial Action Space for Predicting Popular Reddit Threads
Sep 17, 2016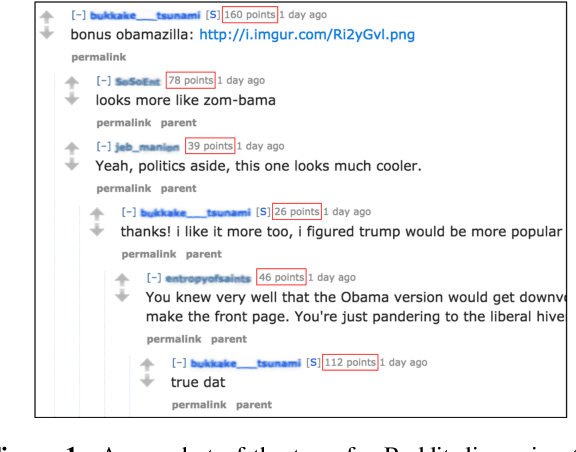
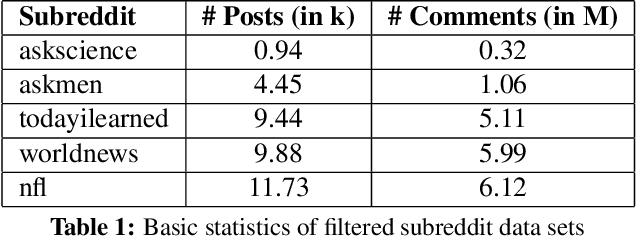
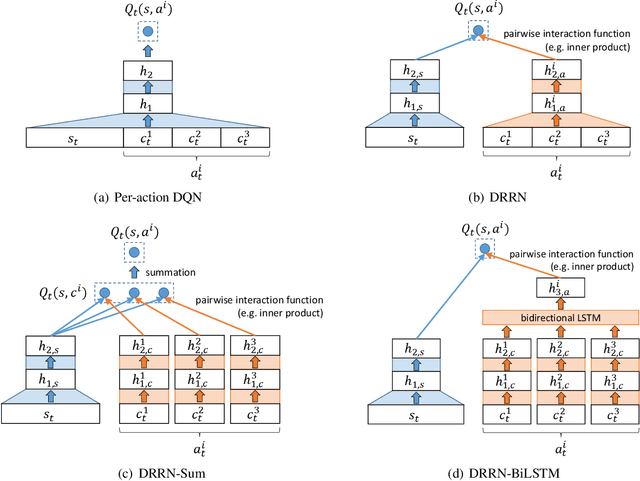
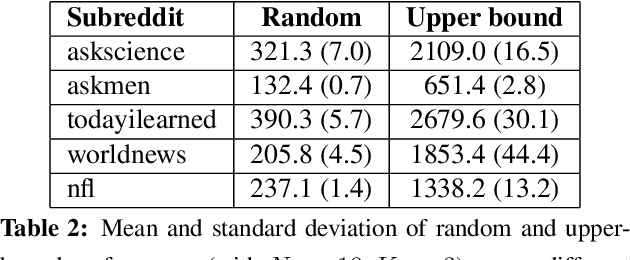
We introduce an online popularity prediction and tracking task as a benchmark task for reinforcement learning with a combinatorial, natural language action space. A specified number of discussion threads predicted to be popular are recommended, chosen from a fixed window of recent comments to track. Novel deep reinforcement learning architectures are studied for effective modeling of the value function associated with actions comprised of interdependent sub-actions. The proposed model, which represents dependence between sub-actions through a bi-directional LSTM, gives the best performance across different experimental configurations and domains, and it also generalizes well with varying numbers of recommendation requests.
On the Prior Sensitivity of Thompson Sampling
Jul 21, 2016
The empirically successful Thompson Sampling algorithm for stochastic bandits has drawn much interest in understanding its theoretical properties. One important benefit of the algorithm is that it allows domain knowledge to be conveniently encoded as a prior distribution to balance exploration and exploitation more effectively. While it is generally believed that the algorithm's regret is low (high) when the prior is good (bad), little is known about the exact dependence. In this paper, we fully characterize the algorithm's worst-case dependence of regret on the choice of prior, focusing on a special yet representative case. These results also provide insights into the general sensitivity of the algorithm to the choice of priors. In particular, with $p$ being the prior probability mass of the true reward-generating model, we prove $O(\sqrt{T/p})$ and $O(\sqrt{(1-p)T})$ regret upper bounds for the bad- and good-prior cases, respectively, as well as \emph{matching} lower bounds. Our proofs rely on the discovery of a fundamental property of Thompson Sampling and make heavy use of martingale theory, both of which appear novel in the literature, to the best of our knowledge.
An efficient algorithm for contextual bandits with knapsacks, and an extension to concave objectives
Jul 09, 2016We consider a contextual version of multi-armed bandit problem with global knapsack constraints. In each round, the outcome of pulling an arm is a scalar reward and a resource consumption vector, both dependent on the context, and the global knapsack constraints require the total consumption for each resource to be below some pre-fixed budget. The learning agent competes with an arbitrary set of context-dependent policies. This problem was introduced by Badanidiyuru et al. (2014), who gave a computationally inefficient algorithm with near-optimal regret bounds for it. We give a computationally efficient algorithm for this problem with slightly better regret bounds, by generalizing the approach of Agarwal et al. (2014) for the non-constrained version of the problem. The computational time of our algorithm scales logarithmically in the size of the policy space. This answers the main open question of Badanidiyuru et al. (2014). We also extend our results to a variant where there are no knapsack constraints but the objective is an arbitrary Lipschitz concave function of the sum of outcome vectors.