 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Prior Sensitivity of Thompson Sampling
Jul 21, 2016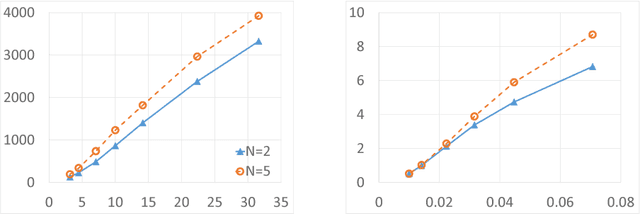
The empirically successful Thompson Sampling algorithm for stochastic bandits has drawn much interest in understanding its theoretical properties. One important benefit of the algorithm is that it allows domain knowledge to be conveniently encoded as a prior distribution to balance exploration and exploitation more effectively. While it is generally believed that the algorithm's regret is low (high) when the prior is good (bad), little is known about the exact dependence. In this paper, we fully characterize the algorithm's worst-case dependence of regret on the choice of prior, focusing on a special yet representative case. These results also provide insights into the general sensitivity of the algorithm to the choice of priors. In particular, with $p$ being the prior probability mass of the true reward-generating model, we prove $O(\sqrt{T/p})$ and $O(\sqrt{(1-p)T})$ regret upper bounds for the bad- and good-prior cases, respectively, as well as \emph{matching} lower bounds. Our proofs rely on the discovery of a fundamental property of Thompson Sampling and make heavy use of martingale theory, both of which appear novel in the literature, to the best of our knowledge.
Most Correlated Arms Identification
Apr 23, 2014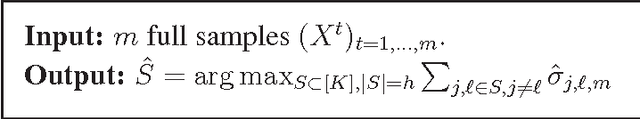


We study the problem of finding the most mutually correlated arms among many arms. We show that adaptive arms sampling strategies can have significant advantages over the non-adaptive uniform sampling strategy. Our proposed algorithms rely on a novel correlation estimator. The use of this accurate estimator allows us to get improved results for a wide range of problem instances.
Prior-free and prior-dependent regret bounds for Thompson Sampling
Oct 03, 2013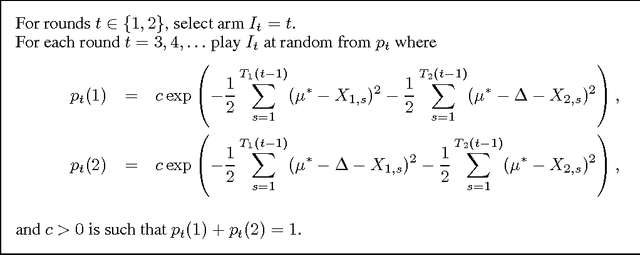
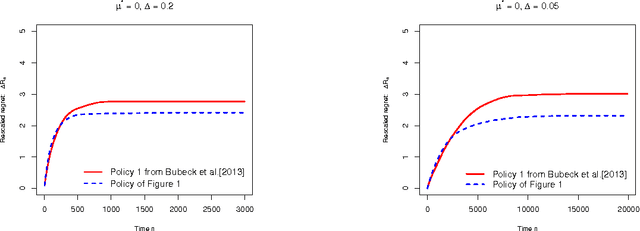
We consider the stochastic multi-armed bandit problem with a prior distribution on the reward distributions. We are interested in studying prior-free and prior-dependent regret bounds, very much in the same spirit as the usual distribution-free and distribution-dependent bounds for the non-Bayesian stochastic bandit. Building on the techniques of Audibert and Bubeck [2009] and Russo and Roy [2013] we first show that Thompson Sampling attains an optimal prior-free bound in the sense that for any prior distribution its Bayesian regret is bounded from above by $14 \sqrt{n K}$. This result is unimprovable in the sense that there exists a prior distribution such that any algorithm has a Bayesian regret bounded from below by $\frac{1}{20} \sqrt{n K}$. We also study the case of priors for the setting of Bubeck et al. [2013] (where the optimal mean is known as well as a lower bound on the smallest gap) and we show that in this case the regret of Thompson Sampling is in fact uniformly bounded over time, thus showing that Thompson Sampling can greatly take advantage of the nice properties of these priors.