 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZoomNeXt: A Unified Collaborative Pyramid Network for Camouflaged Object Detection
Oct 31, 2023



Recent camouflaged object detection (COD) attempts to segment objects visually blended into their surroundings, which is extremely complex and difficult in real-world scenarios. Apart from the high intrinsic similarity between camouflaged objects and their background, objects are usually diverse in scale, fuzzy in appearance, and even severely occluded. To this end, we propose an effective unified collaborative pyramid network which mimics human behavior when observing vague images and videos, \textit{i.e.}, zooming in and out. Specifically, our approach employs the zooming strategy to learn discriminative mixed-scale semantics by the multi-head scale integration and rich granularity perception units, which are designed to fully explore imperceptible clues between candidate objects and background surroundings. The former's intrinsic multi-head aggregation provides more diverse visual patterns. The latter's routing mechanism can effectively propagate inter-frame difference in spatiotemporal scenarios and adaptively ignore static representations. They provides a solid foundation for realizing a unified architecture for static and dynamic COD. Moreover, considering the uncertainty and ambiguity derived from indistinguishable textures, we construct a simple yet effective regularization, uncertainty awareness loss, to encourage predictions with higher confidence in candidate regions. Our highly task-friendly framework consistently outperforms existing state-of-the-art methods in image and video COD benchmarks. The code will be available at \url{https://github.com/lartpang/ZoomNeXt}.
Referring Image Segmentation Using Text Supervision
Aug 28, 2023



Existing Referring Image Segmentation (RIS) methods typically require expensive pixel-level or box-level annotations for supervision. In this paper, we observe that the referring texts used in RIS already provide sufficient information to localize the target object. Hence, we propose a novel weakly-supervised RIS framework to formulate the target localization problem as a classification process to differentiate between positive and negative text expressions. While the referring text expressions for an image are used as positive expressions, the referring text expressions from other images can be used as negative expressions for this image. Our framework has three main novelties. First, we propose a bilateral prompt method to facilitate the classification process, by harmonizing the domain discrepancy between visual and linguistic features. Second, we propose a calibration method to reduce noisy background information and improve the correctness of the response maps for target object localization. Third, we propose a positive response map selection strategy to generate high-quality pseudo-labels from the enhanced response maps, for training a segmentation network for RIS inference. For evaluation, we propose a new metric to measure localization accuracy. Experiments on four benchmarks show that our framework achieves promising performances to existing fully-supervised RIS methods while outperforming state-of-the-art weakly-supervised methods adapted from related areas. Code is available at https://github.com/fawnliu/TRIS.
Fast Adversarial Training with Smooth Convergence
Aug 24, 2023Fast adversarial training (FAT) is beneficial for improving the adversarial robustness of neural networks. However, previous FAT work has encountered a significant issue known as catastrophic overfitting when dealing with large perturbation budgets, \ie the adversarial robustness of models declines to near zero during training. To address this, we analyze the training process of prior FAT work and observe that catastrophic overfitting is accompanied by the appearance of loss convergence outliers. Therefore, we argue a moderately smooth loss convergence process will be a stable FAT process that solves catastrophic overfitting. To obtain a smooth loss convergence process, we propose a novel oscillatory constraint (dubbed ConvergeSmooth) to limit the loss difference between adjacent epochs. The convergence stride of ConvergeSmooth is introduced to balance convergence and smoothing. Likewise, we design weight centralization without introducing additional hyperparameters other than the loss balance coefficient. Our proposed methods are attack-agnostic and thus can improve the training stability of various FAT techniques. Extensive experiments on popular datasets show that the proposed methods efficiently avoid catastrophic overfitting and outperform all previous FAT methods. Code is available at \url{https://github.com/FAT-CS/ConvergeSmooth}.
ComPtr: Towards Diverse Bi-source Dense Prediction Tasks via A Simple yet General Complementary Transformer
Jul 23, 2023



Deep learning (DL) has advanced the field of dense prediction, while gradually dissolving the inherent barriers between different tasks. However, most existing works focus on designing architectures and constructing visual cues only for the specific task, which ignores the potential uniformity introduced by the DL paradigm. In this paper, we attempt to construct a novel \underline{ComP}lementary \underline{tr}ansformer, \textbf{ComPtr}, for diverse bi-source dense prediction tasks. Specifically, unlike existing methods that over-specialize in a single task or a subset of tasks, ComPtr starts from the more general concept of bi-source dense prediction. Based on the basic dependence on information complementarity, we propose consistency enhancement and difference awareness components with which ComPtr can evacuate and collect important visual semantic cues from different image sources for diverse tasks, respectively. ComPtr treats different inputs equally and builds an efficient dense interaction model in the form of sequence-to-sequence on top of the transformer. This task-generic design provides a smooth foundation for constructing the unified model that can simultaneously deal with various bi-source information. In extensive experiments across several representative vision tasks, i.e. remote sensing change detection, RGB-T crowd counting, RGB-D/T salient object detection, and RGB-D semantic segmentation, the proposed method consistently obtains favorable performance. The code will be available at \url{https://github.com/lartpang/ComPtr}.
3rd Place Solution for PVUW2023 VSS Track: A Large Model for Semantic Segmentation on VSPW
Jun 06, 2023



In this paper, we introduce 3rd place solution for PVUW2023 VSS track. Semantic segmentation is a fundamental task in computer vision with numerous real-world applications. We have explored various image-level visual backbones and segmentation heads to tackle the problem of video semantic segmentation. Through our experimentation, we find that InternImage-H as the backbone and Mask2former as the segmentation head achieves the best performance. In addition, we explore two post-precessing methods: CascadePSP and Segment Anything Model (SAM). Ultimately, our approach obtains 62.60\% and 64.84\% mIoU on the VSPW test set1 and final test set, respectively, securing the third position in the PVUW2023 VSS track.
M$^{2}$SNet: Multi-scale in Multi-scale Subtraction Network for Medical Image Segmentation
Mar 20, 2023



Accurate medical image segmentation is critical for early medical diagnosis. Most existing methods are based on U-shape structure and use element-wise addition or concatenation to fuse different level features progressively in decoder. However, both the two operations easily generate plenty of redundant information, which will weaken the complementarity between different level features, resulting in inaccurate localization and blurred edges of lesions. To address this challenge, we propose a general multi-scale in multi-scale subtraction network (M$^{2}$SNet) to finish diverse segmentation from medical image. Specifically, we first design a basic subtraction unit (SU) to produce the difference features between adjacent levels in encoder. Next, we expand the single-scale SU to the intra-layer multi-scale SU, which can provide the decoder with both pixel-level and structure-level difference information. Then, we pyramidally equip the multi-scale SUs at different levels with varying receptive fields, thereby achieving the inter-layer multi-scale feature aggregation and obtaining rich multi-scale difference information. In addition, we build a training-free network ``LossNet'' to comprehensively supervise the task-aware features from bottom layer to top layer, which drives our multi-scale subtraction network to capture the detailed and structural cues simultaneously. Without bells and whistles, our method performs favorably against most state-of-the-art methods under different evaluation metrics on eleven datasets of four different medical image segmentation tasks of diverse image modalities, including color colonoscopy imaging, ultrasound imaging, computed tomography (CT), and optical coherence tomography (OCT). The source code can be available at \url{https://github.com/Xiaoqi-Zhao-DLUT/MSNet}.
Adaptive Multi-source Predictor for Zero-shot Video Object Segmentation
Mar 18, 2023Both static and moving objects usually exist in real-life videos. Most video object segmentation methods only focus on exacting and exploiting motion cues to perceive moving objects. Once faced with static objects frames, moving object predictors may predict failed results caused by uncertain motion information, such as low-quality optical flow maps. Besides, many sources such as RGB, depth, optical flow and static saliency can provide useful information about the objects. However, existing approaches only utilize the RGB or RGB and optical flow. In this paper, we propose a novel adaptive multi-source predictor for zero-shot video object segmentation. In the static object predictor, the RGB source is converted to depth and static saliency sources, simultaneously. In the moving object predictor, we propose the multi-source fusion structure. First, the spatial importance of each source is highlighted with the help of the interoceptive spatial attention module (ISAM). Second, the motion-enhanced module (MEM) is designed to generate pure foreground motion attention for improving both static and moving features used in the decoder. Furthermore, we design a feature purification module (FPM) to filter the inter-source incompatible features. By the ISAM, MEM and FPM, the multi-source features are effectively fused. In addition, we put forward an adaptive predictor fusion network (APF) to evaluate the quality of optical flow and fuse the predictions from the static object predictor and the moving object predictor in order to prevent over-reliance on the failed results caused by low-quality optical flow maps. Experiments show that the proposed model outperforms the state-of-the-art methods on three challenging ZVOS benchmarks. And, the static object predictor can precisely predicts a high-quality depth map and static saliency map at the same time.
Towards Diverse Binary Segmentation via A Simple yet General Gated Network
Mar 18, 2023In many binary segmentation tasks, most CNNs-based methods use a U-shape encoder-decoder network as their basic structure. They ignore two key problems when the encoder exchanges information with the decoder: one is the lack of interference control mechanism between them, the other is without considering the disparity of the contributions from different encoder levels. In this work, we propose a simple yet general gated network (GateNet) to tackle them all at once. With the help of multi-level gate units, the valuable context information from the encoder can be selectively transmitted to the decoder. In addition, we design a gated dual branch structure to build the cooperation among the features of different levels and improve the discrimination ability of the network. Furthermore, we introduce a ``Fold'' operation to improve the atrous convolution and form a novel folded atrous convolution, which can be flexibly embedded in ASPP or DenseASPP to accurately localize foreground objects of various scales. GateNet can be easily generalized to many binary segmentation tasks, including general and specific object segmentation and multi-modal segmentation. Without bells and whistles, our network consistently performs favorably against the state-of-the-art methods under 10 metrics on 33 datasets of 10 binary segmentation tasks.
Deeply Interleaved Two-Stream Encoder for Referring Video Segmentation
Mar 30, 2022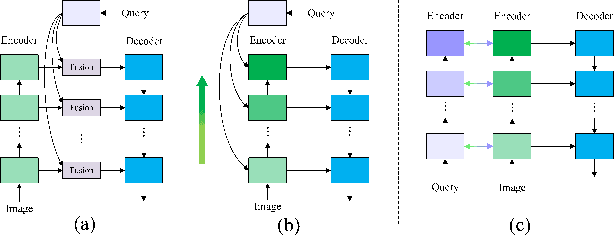
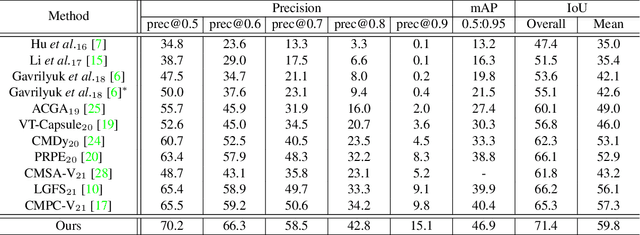
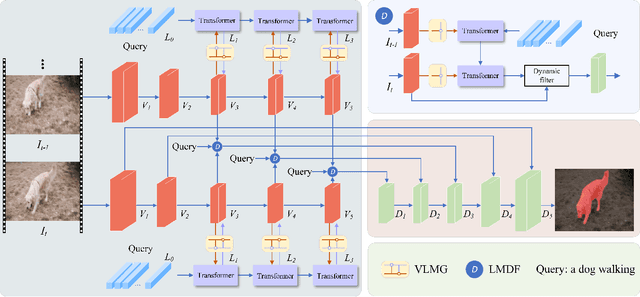
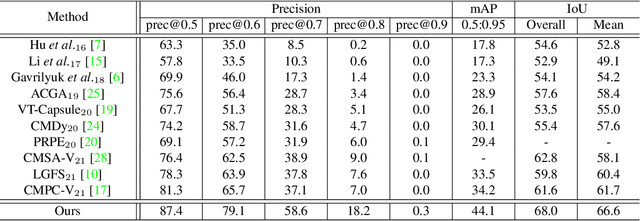
Referring video segmentation aims to segment the corresponding video object described by the language expression. To address this task, we first design a two-stream encoder to extract CNN-based visual features and transformer-based linguistic features hierarchically, and a vision-language mutual guidance (VLMG) module is inserted into the encoder multiple times to promote the hierarchical and progressive fusion of multi-modal features. Compared with the existing multi-modal fusion methods, this two-stream encoder takes into account the multi-granularity linguistic context, and realizes the deep interleaving between modalities with the help of VLGM. In order to promote the temporal alignment between frames, we further propose a language-guided multi-scale dynamic filtering (LMDF) module to strengthen the temporal coherence, which uses the language-guided spatial-temporal features to generate a set of position-specific dynamic filters to more flexibly and effectively update the feature of current frame. Extensive experiments on four datasets verify the effectiveness of the proposed model.
Joint Learning of Salient Object Detection, Depth Estimation and Contour Extraction
Mar 09, 2022



Benefiting from color independence, illumination invariance and location discrimination attributed by the depth map, it can provide important supplemental information for extracting salient objects in complex environments. However, high-quality depth sensors are expensive and can not be widely applied. While general depth sensors produce the noisy and sparse depth information, which brings the depth-based networks with irreversible interference. In this paper, we propose a novel multi-task and multi-modal filtered transformer (MMFT) network for RGB-D salient object detection (SOD). Specifically, we unify three complementary tasks: depth estimation, salient object detection and contour estimation. The multi-task mechanism promotes the model to learn the task-aware features from the auxiliary tasks. In this way, the depth information can be completed and purified. Moreover, we introduce a multi-modal filtered transformer (MFT) module, which equips with three modality-specific filters to generate the transformer-enhanced feature for each modality. The proposed model works in a depth-free style during the testing phase. Experiments show that it not only significantly surpasses the depth-based RGB-D SOD methods on multiple datasets, but also precisely predicts a high-quality depth map and salient contour at the same time. And, the resulted depth map can help existing RGB-D SOD methods obtain significant performance gain.