 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Feature Alignment: Learn to Convert Text Recognizer to Text Spotter
Jun 10, 2021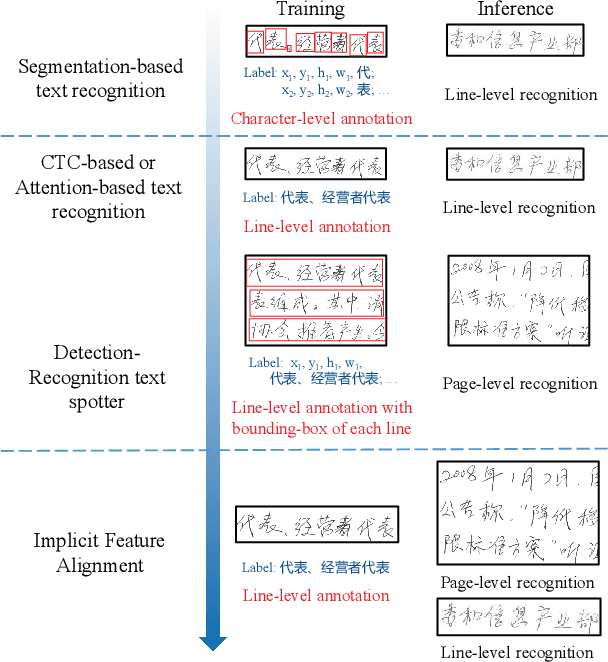
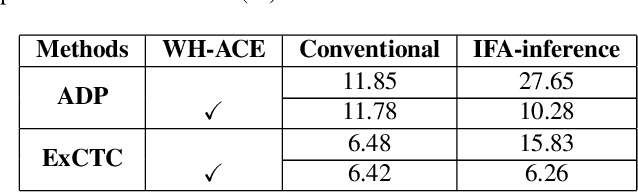
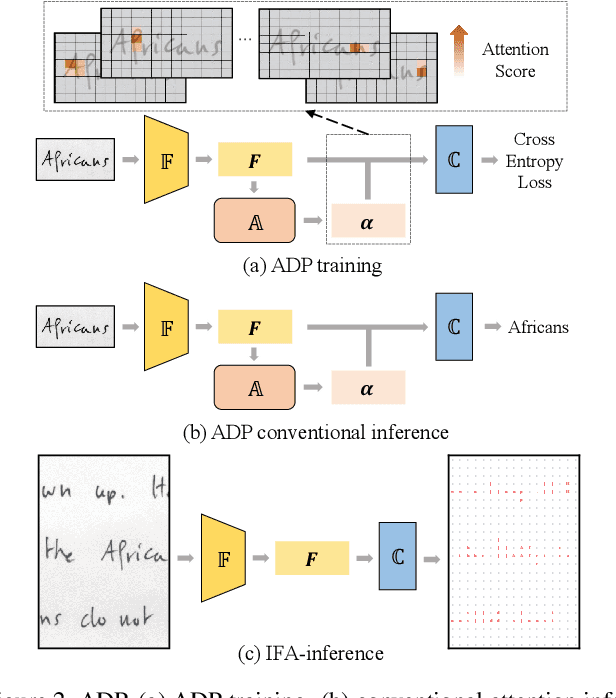
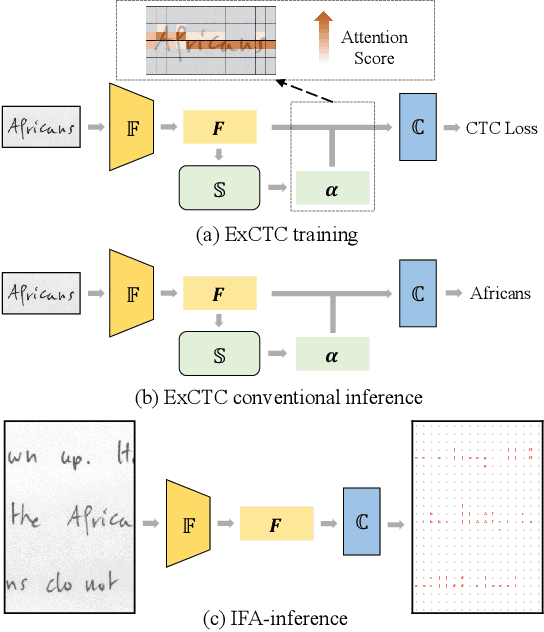
Text recognition is a popular research subject with many associated challenges. Despite the considerable progress made in recent years, the text recognition task itself is still constrained to solve the problem of reading cropped line text images and serves as a subtask of optical character recognition (OCR) systems. As a result, the final text recognition result is limited by the performance of the text detector. In this paper, we propose a simple, elegant and effective paradigm called Implicit Feature Alignment (IFA), which can be easily integrated into current text recognizers, resulting in a novel inference mechanism called IFAinference. This enables an ordinary text recognizer to process multi-line text such that text detection can be completely freed. Specifically, we integrate IFA into the two most prevailing text recognition streams (attention-based and CTC-based) and propose attention-guided dense prediction (ADP) and Extended CTC (ExCTC). Furthermore, the Wasserstein-based Hollow Aggregation Cross-Entropy (WH-ACE) is proposed to suppress negative predictions to assist in training ADP and ExCTC. We experimentally demonstrate that IFA achieves state-of-the-art performance on end-to-end document recognition tasks while maintaining the fastest speed, and ADP and ExCTC complement each other on the perspective of different application scenarios. Code will be available at https://github.com/WangTianwei/Implicit-feature-alignment.
ICDAR 2021 Competition on On-Line Signature Verification
Jun 01, 2021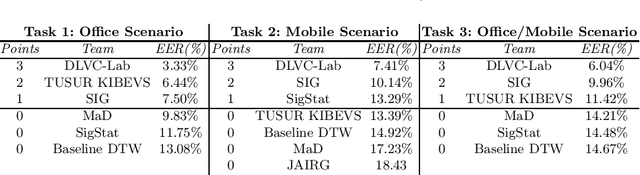
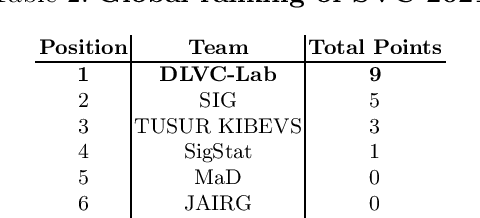
This paper describes the experimental framework and results of the ICDAR 2021 Competition on On-Line Signature Verification (SVC 2021). The goal of SVC 2021 is to evaluate the limits of on-line signature verification systems on popular scenarios (office/mobile) and writing inputs (stylus/finger) through large-scale public databases. Three different tasks are considered in the competition, simulating realistic scenarios as both random and skilled forgeries are simultaneously considered on each task. The results obtained in SVC 2021 prove the high potential of deep learning methods. In particular, the best on-line signature verification system of SVC 2021 obtained Equal Error Rate (EER) values of 3.33% (Task 1), 7.41% (Task 2), and 6.04% (Task 3). SVC 2021 will be established as an on-going competition, where researchers can easily benchmark their systems against the state of the art in an open common platform using large-scale public databases such as DeepSignDB and SVC2021_EvalDB, and standard experimental protocols.
ABCNet v2: Adaptive Bezier-Curve Network for Real-time End-to-end Text Spotting
May 29, 2021
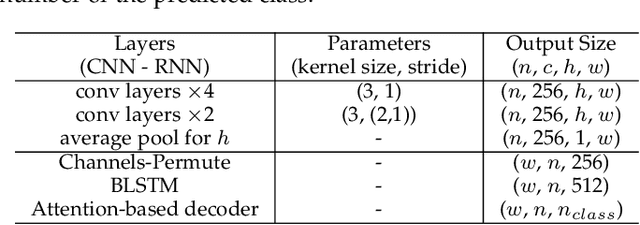


End-to-end text-spotting, which aims to integrate detection and recognition in a unified framework, has attracted increasing attention due to its simplicity of the two complimentary tasks. It remains an open problem especially when processing arbitrarily-shaped text instances. Previous methods can be roughly categorized into two groups: character-based and segmentation-based, which often require character-level annotations and/or complex post-processing due to the unstructured output. Here, we tackle end-to-end text spotting by presenting Adaptive Bezier Curve Network v2 (ABCNet v2). Our main contributions are four-fold: 1) For the first time, we adaptively fit arbitrarily-shaped text by a parameterized Bezier curve, which, compared with segmentation-based methods, can not only provide structured output but also controllable representation. 2) We design a novel BezierAlign layer for extracting accurate convolution features of a text instance of arbitrary shapes, significantly improving the precision of recognition over previous methods. 3) Different from previous methods, which often suffer from complex post-processing and sensitive hyper-parameters, our ABCNet v2 maintains a simple pipeline with the only post-processing non-maximum suppression (NMS). 4) As the performance of text recognition closely depends on feature alignment, ABCNet v2 further adopts a simple yet effective coordinate convolution to encode the position of the convolutional filters, which leads to a considerable improvement with negligible computation overhead. Comprehensive experiments conducted on various bilingual (English and Chinese) benchmark datasets demonstrate that ABCNet v2 can achieve state-of-the-art performance while maintaining very high efficiency.
Towards an efficient framework for Data Extraction from Chart Images
May 05, 2021
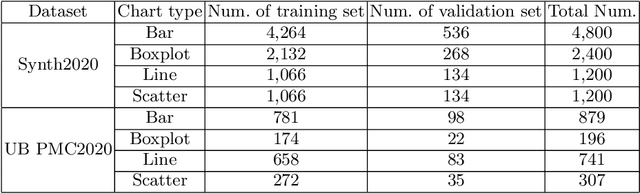
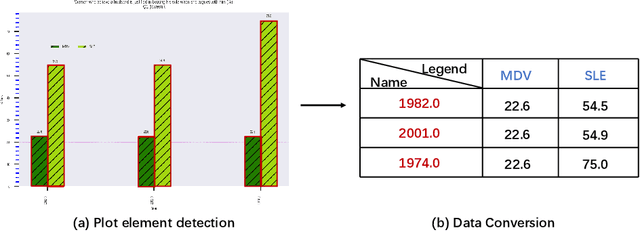
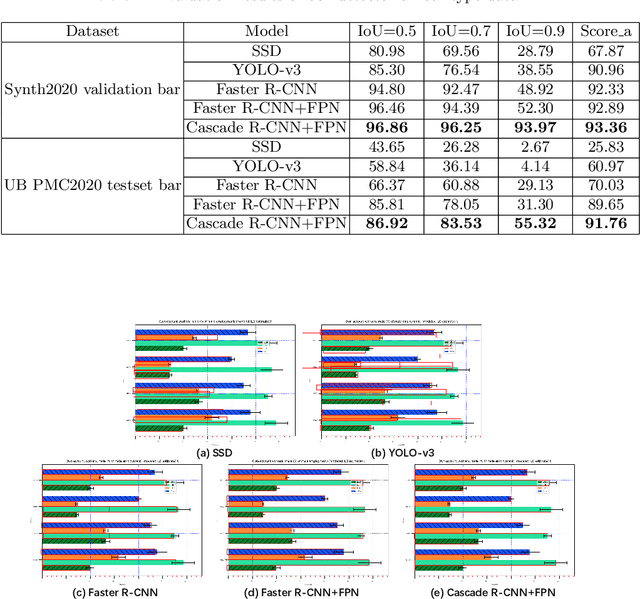
In this paper, we fill the research gap by adopting state-of-the-art computer vision techniques for the data extraction stage in a data mining system. As shown in Fig.1, this stage contains two subtasks, namely, plot element detection and data conversion. For building a robust box detector, we comprehensively compare different deep learning-based methods and find a suitable method to detect box with high precision. For building a robust point detector, a fully convolutional network with feature fusion module is adopted, which can distinguish close points compared to traditional methods. The proposed system can effectively handle various chart data without making heuristic assumptions. For data conversion, we translate the detected element into data with semantic value. A network is proposed to measure feature similarities between legends and detected elements in the legend matching phase. Furthermore, we provide a baseline on the competition of Harvesting raw tables from Infographics. Some key factors have been found to improve the performance of each stage. Experimental results demonstrate the effectiveness of the proposed system.
Fourier Contour Embedding for Arbitrary-Shaped Text Detection
Apr 22, 2021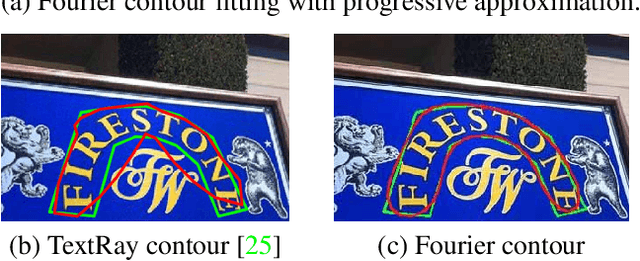
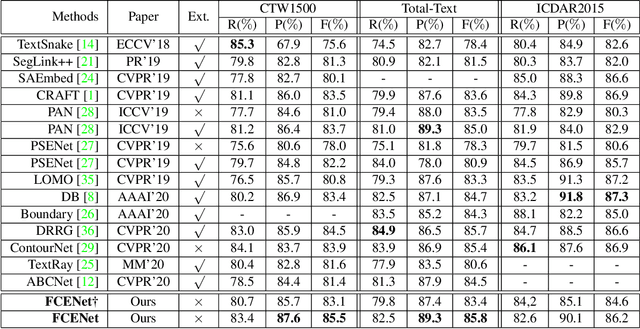
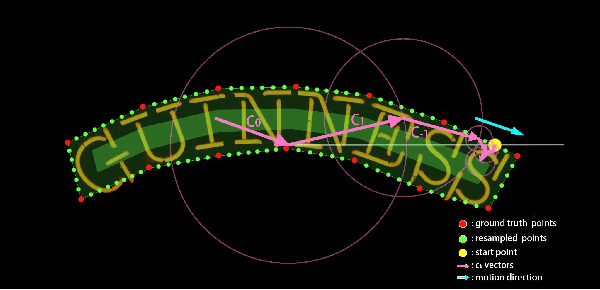
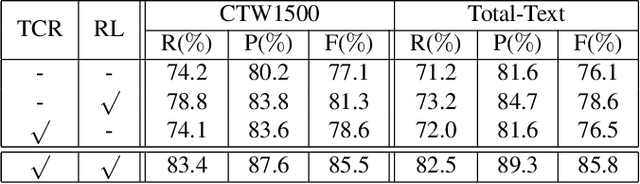
One of the main challenges for arbitrary-shaped text detection is to design a good text instance representation that allows networks to learn diverse text geometry variances. Most of existing methods model text instances in image spatial domain via masks or contour point sequences in the Cartesian or the polar coordinate system. However, the mask representation might lead to expensive post-processing, while the point sequence one may have limited capability to model texts with highly-curved shapes. To tackle these problems, we model text instances in the Fourier domain and propose one novel Fourier Contour Embedding (FCE) method to represent arbitrary shaped text contours as compact signatures. We further construct FCENet with a backbone, feature pyramid networks (FPN) and a simple post-processing with the Inverse Fourier Transformation (IFT) and Non-Maximum Suppression (NMS). Different from previous methods, FCENet first predicts compact Fourier signatures of text instances, and then reconstructs text contours via IFT and NMS during test. Extensive experiments demonstrate that FCE is accurate and robust to fit contours of scene texts even with highly-curved shapes, and also validate the effectiveness and the good generalization of FCENet for arbitrary-shaped text detection. Furthermore, experimental results show that our FCENet is superior to the state-of-the-art (SOTA) methods on CTW1500 and Total-Text, especially on challenging highly-curved text subset.
Towards Robust Visual Information Extraction in Real World: New Dataset and Novel Solution
Jan 24, 2021

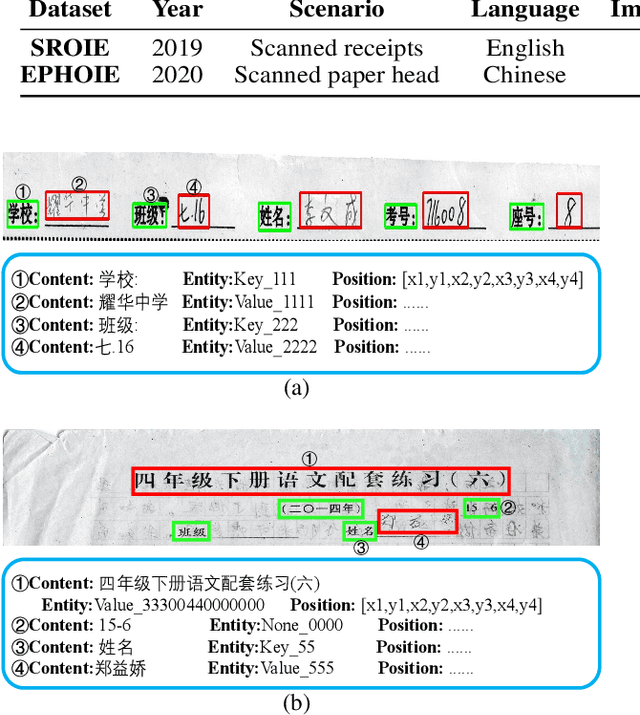
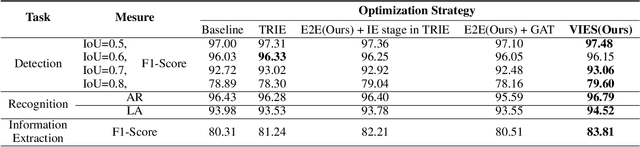
Visual information extraction (VIE) has attracted considerable attention recently owing to its various advanced applications such as document understanding, automatic marking and intelligent education. Most existing works decoupled this problem into several independent sub-tasks of text spotting (text detection and recognition) and information extraction, which completely ignored the high correlation among them during optimization. In this paper, we propose a robust visual information extraction system (VIES) towards real-world scenarios, which is a unified end-to-end trainable framework for simultaneous text detection, recognition and information extraction by taking a single document image as input and outputting the structured information. Specifically, the information extraction branch collects abundant visual and semantic representations from text spotting for multimodal feature fusion and conversely, provides higher-level semantic clues to contribute to the optimization of text spotting. Moreover, regarding the shortage of public benchmarks, we construct a fully-annotated dataset called EPHOIE (https://github.com/HCIILAB/EPHOIE), which is the first Chinese benchmark for both text spotting and visual information extraction. EPHOIE consists of 1,494 images of examination paper head with complex layouts and background, including a total of 15,771 Chinese handwritten or printed text instances. Compared with the state-of-the-art methods, our VIES shows significant superior performance on the EPHOIE dataset and achieves a 9.01% F-score gain on the widely used SROIE dataset under the end-to-end scenario.
Improving Attention-Based Handwritten Mathematical Expression Recognition with Scale Augmentation and Drop Attention
Jul 20, 2020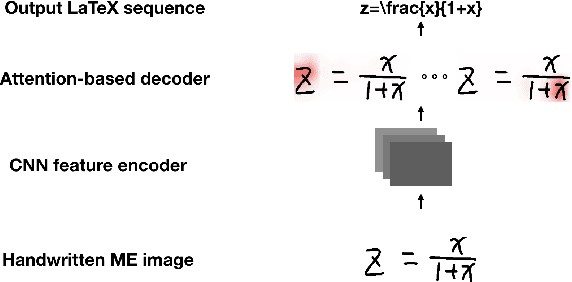
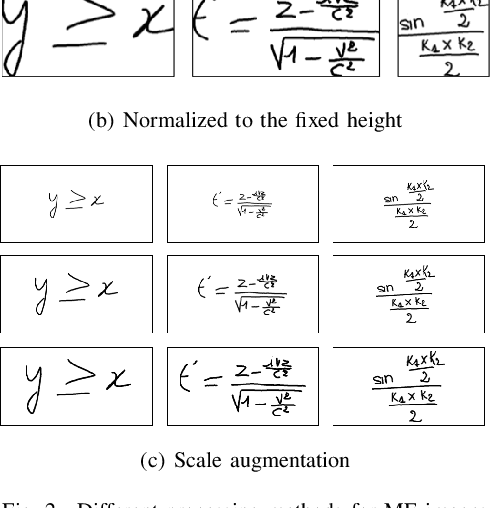
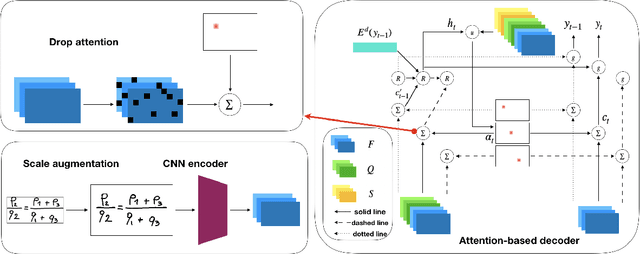
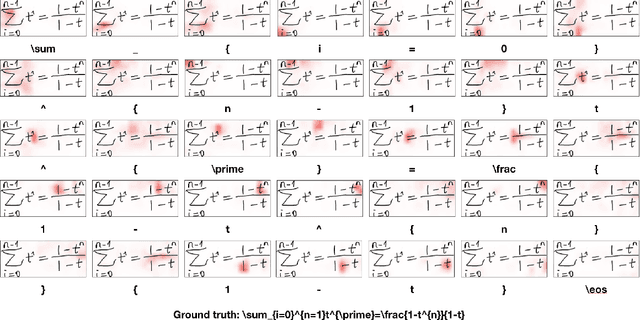
Handwritten mathematical expression recognition (HMER) is an important research direction in handwriting recognition. The performance of HMER suffers from the two-dimensional structure of mathematical expressions (MEs). To address this issue, in this paper, we propose a high-performance HMER model with scale augmentation and drop attention. Specifically, tackling ME with unstable scale in both horizontal and vertical directions, scale augmentation improves the performance of the model on MEs of various scales. An attention-based encoder-decoder network is used for extracting features and generating predictions. In addition, drop attention is proposed to further improve performance when the attention distribution of the decoder is not precise. Compared with previous methods, our method achieves state-of-the-art performance on two public datasets of CROHME 2014 and CROHME 2016.
Joint Layout Analysis, Character Detection and Recognition for Historical Document Digitization
Jul 14, 2020
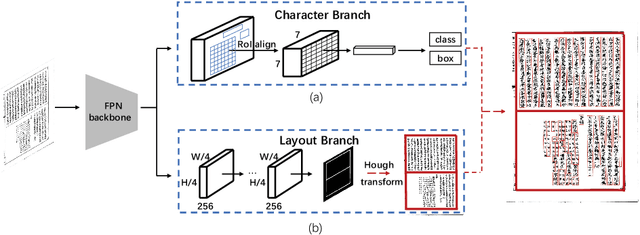
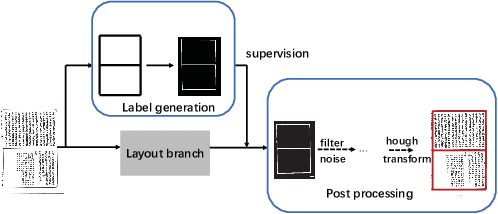
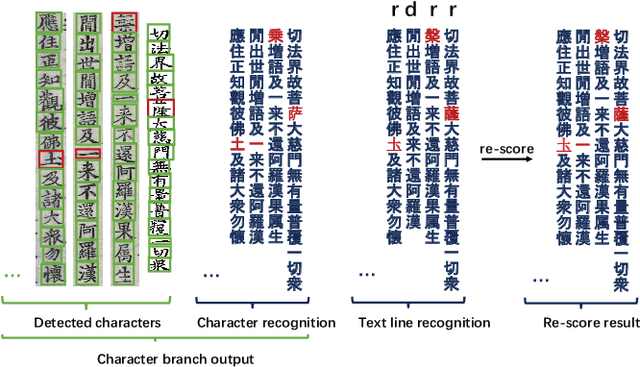
In this paper, we propose an end-to-end trainable framework for restoring historical documents content that follows the correct reading order. In this framework, two branches named character branch and layout branch are added behind the feature extraction network. The character branch localizes individual characters in a document image and recognizes them simultaneously. Then we adopt a post-processing method to group them into text lines. The layout branch based on fully convolutional network outputs a binary mask. We then use Hough transform for line detection on the binary mask and combine character results with the layout information to restore document content. These two branches can be trained in parallel and are easy to train. Furthermore, we propose a re-score mechanism to minimize recognition error. Experiment results on the extended Chinese historical document MTHv2 dataset demonstrate the effectiveness of the proposed framework.
Text Recognition in the Wild: A Survey
May 07, 2020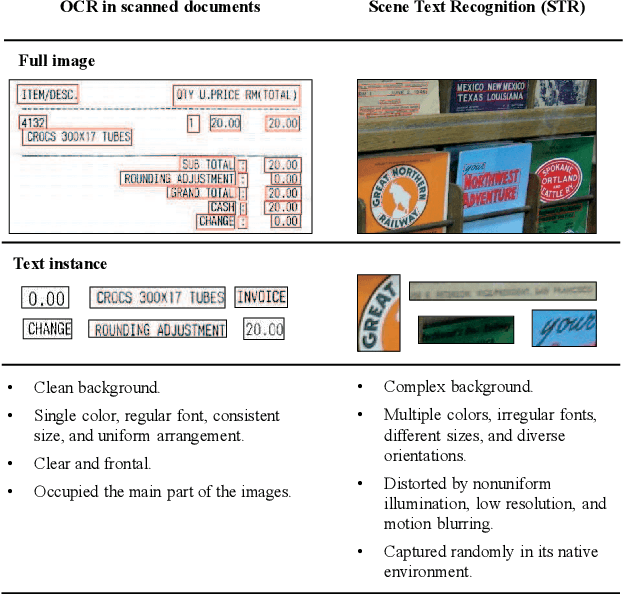
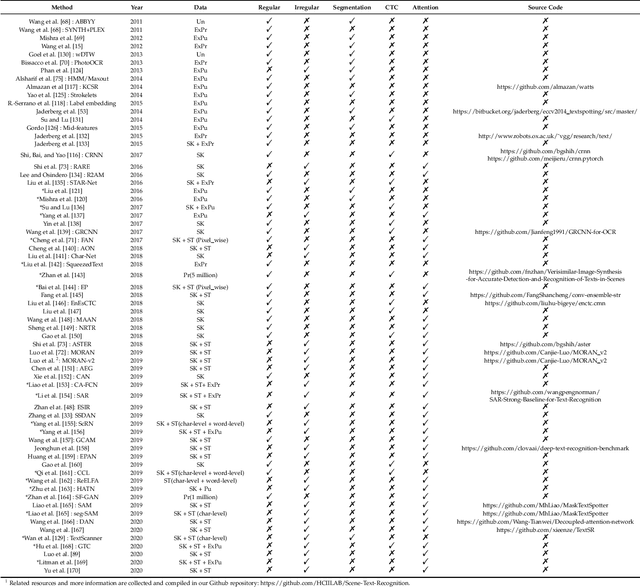

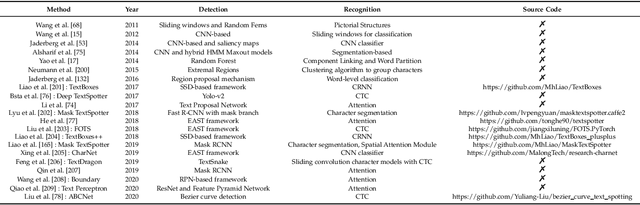
The history of text can be traced back over thousands of years. Rich and precise semantic information carried by text is important in a wide range of vision-based application scenarios. Therefore, text recognition in natural scenes has been an active research field in computer vision and pattern recognition. In recent years, with the rise and development of deep learning, numerous methods have shown promising in terms of innovation, practicality, and efficiency. This paper aims to (1) summarize the fundamental problems and the state-of-the-art associated with scene text recognition; (2) introduce new insights and ideas; (3) provide a comprehensive review of publicly available resources; (4) point out directions for future work. In summary, this literature review attempts to present the entire picture of the field of scene text recognition. It provides a comprehensive reference for people entering this field, and could be helpful to inspire future research. Related resources are available at our Github repository: https://github.com/HCIILAB/Scene-Text-Recognition.
Learn to Augment: Joint Data Augmentation and Network Optimization for Text Recognition
Mar 14, 2020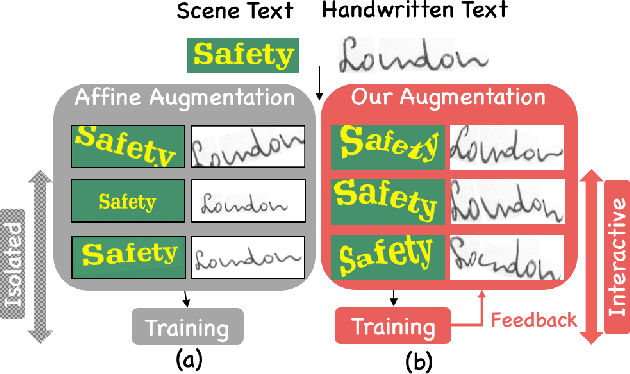

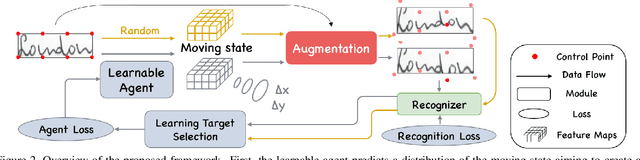
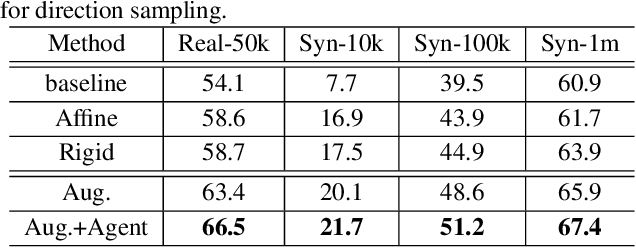
Handwritten text and scene text suffer from various shapes and distorted patterns. Thus training a robust recognition model requires a large amount of data to cover diversity as much as possible. In contrast to data collection and annotation, data augmentation is a low cost way. In this paper, we propose a new method for text image augmentation. Different from traditional augmentation methods such as rotation, scaling and perspective transformation, our proposed augmentation method is designed to learn proper and efficient data augmentation which is more effective and specific for training a robust recognizer. By using a set of custom fiducial points, the proposed augmentation method is flexible and controllable. Furthermore, we bridge the gap between the isolated processes of data augmentation and network optimization by joint learning. An agent network learns from the output of the recognition network and controls the fiducial points to generate more proper training samples for the recognition network. Extensive experiments on various benchmarks, including regular scene text, irregular scene text and handwritten text, show that the proposed augmentation and the joint learning methods significantly boost the performance of the recognition networks. A general toolkit for geometric augmentation is available.