 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrelating Edge, Pose with Parsing
May 04, 2020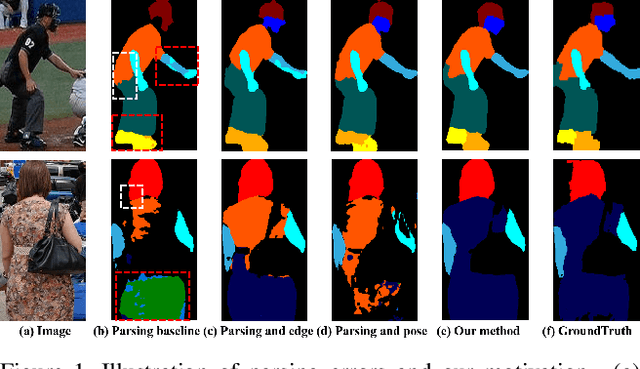
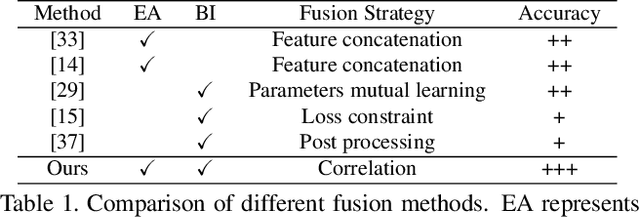
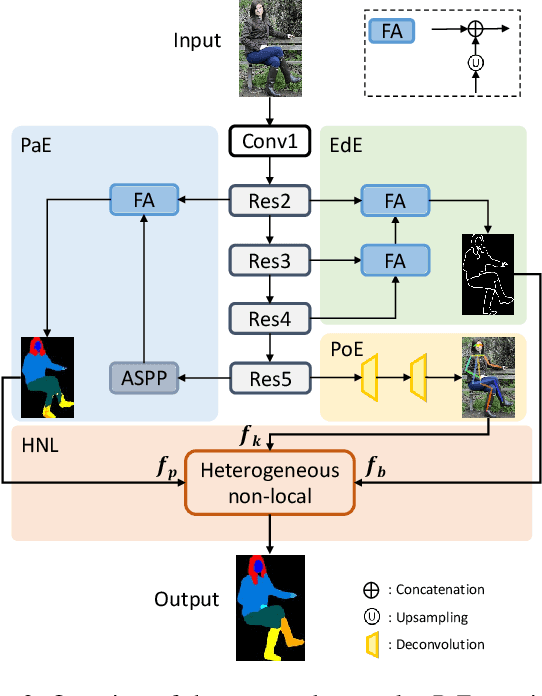
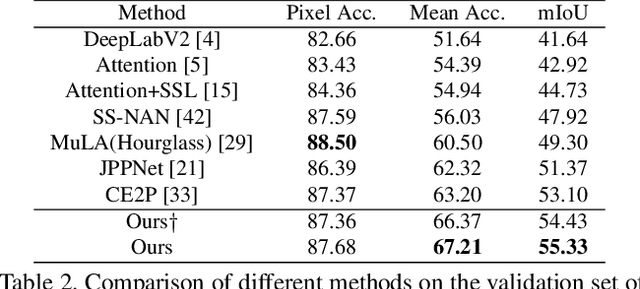
According to existing studies, human body edge and pose are two beneficial factors to human parsing. The effectiveness of each of the high-level features (edge and pose) is confirmed through the concatenation of their features with the parsing features. Driven by the insights, this paper studies how human semantic boundaries and keypoint locations can jointly improve human parsing. Compared with the existing practice of feature concatenation, we find that uncovering the correlation among the three factors is a superior way of leveraging the pivotal contextual cues provided by edges and poses. To capture such correlations, we propose a Correlation Parsing Machine (CorrPM) employing a heterogeneous non-local block to discover the spatial affinity among feature maps from the edge, pose and parsing. The proposed CorrPM allows us to report new state-of-the-art accuracy on three human parsing datasets. Importantly, comparative studies confirm the advantages of feature correlation over the concatenation.
The 4th AI City Challenge
Apr 30, 2020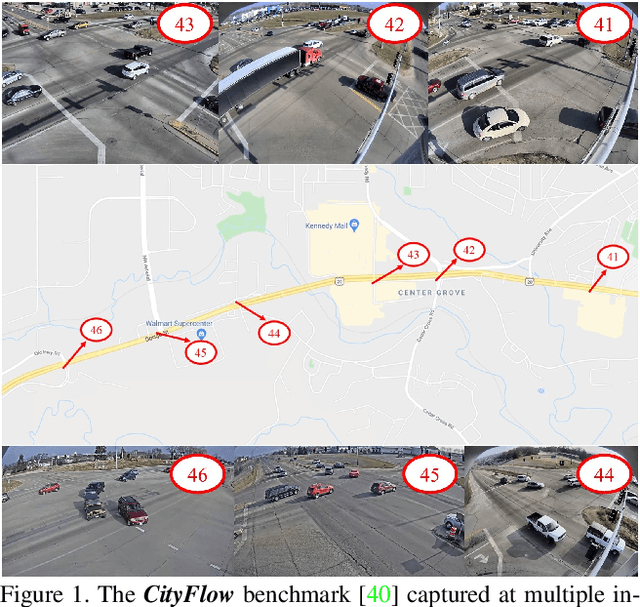
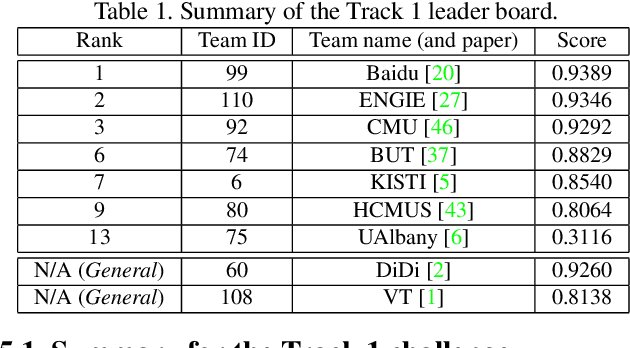
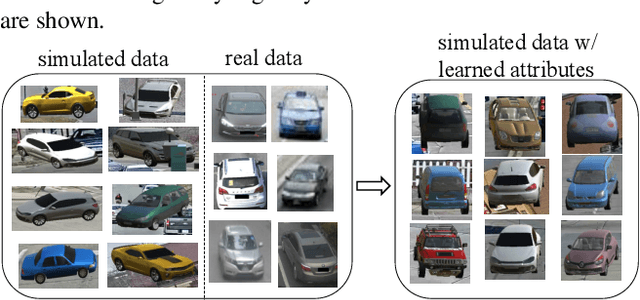
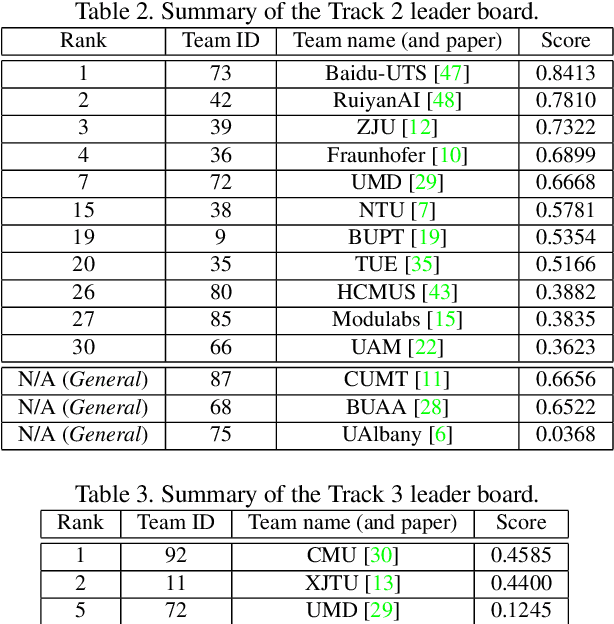
The AI City Challenge was created to accelerate intelligent video analysis that helps make cities smarter and safer. Transportation is one of the largest segments that can benefit from actionable insights derived from data captured by sensors, where computer vision and deep learning have shown promise in achieving large-scale practical deployment. The 4th annual edition of the AI City Challenge has attracted 315 participating teams across 37 countries, who leveraged city-scale real traffic data and high-quality synthetic data to compete in four challenge tracks. Track 1 addressed video-based automatic vehicle counting, where the evaluation is conducted on both algorithmic effectiveness and computational efficiency. Track 2 addressed city-scale vehicle re-identification with augmented synthetic data to substantially increase the training set for the task. Track 3 addressed city-scale multi-target multi-camera vehicle tracking. Track 4 addressed traffic anomaly detection. The evaluation system shows two leader boards, in which a general leader board shows all submitted results, and a public leader board shows results limited to our contest participation rules, that teams are not allowed to use external data in their work. The public leader board shows results more close to real-world situations where annotated data are limited. Our results show promise that AI technology can enable smarter and safer transportation systems.
Learning to Structure an Image with Few Colors
Mar 17, 2020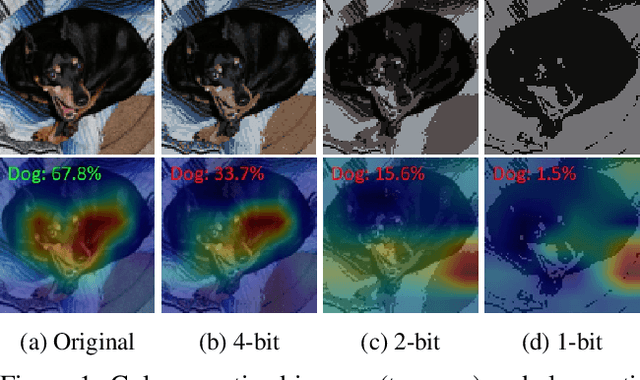
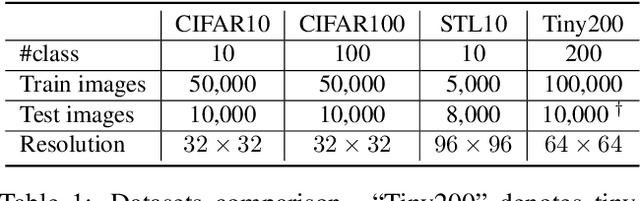

Color and structure are the two pillars that construct an image. Usually, the structure is well expressed through a rich spectrum of colors, allowing objects in an image to be recognized by neural networks. However, under extreme limitations of color space, the structure tends to vanish, and thus a neural network might fail to understand the image. Interested in exploring this interplay between color and structure, we study the scientific problem of identifying and preserving the most informative image structures while constraining the color space to just a few bits, such that the resulting image can be recognized with possibly high accuracy. To this end, we propose a color quantization network, ColorCNN, which learns to structure the images from the classification loss in an end-to-end manner. Given a color space size, ColorCNN quantizes colors in the original image by generating a color index map and an RGB color palette. Then, this color-quantized image is fed to a pre-trained task network to evaluate its performance. In our experiment, with only a 1-bit color space (i.e., two colors), the proposed network achieves 82.1% top-1 accuracy on the CIFAR10 dataset, outperforming traditional color quantization methods by a large margin. For applications, when encoded with PNG, the proposed color quantization shows superiority over other image compression methods in the extremely low bit-rate regime. The code is available at: https://github.com/hou-yz/color_distillation.
Circle Loss: A Unified Perspective of Pair Similarity Optimization
Feb 25, 2020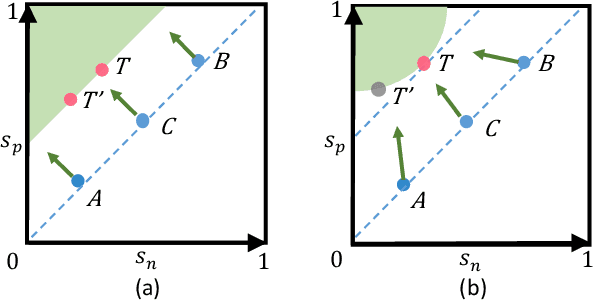
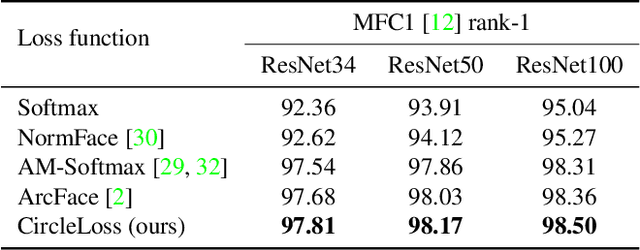
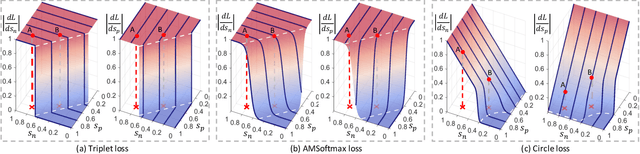
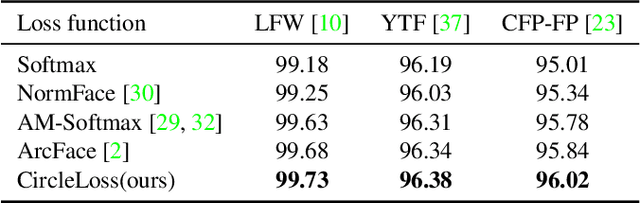
This paper provides a pair similarity optimization viewpoint on deep feature learning, aiming to maximize the within-class similarity $s_p$ and minimize the between-class similarity $s_n$. We find a majority of loss functions, including the triplet loss and the softmax plus cross-entropy loss, embed $s_n$ and $s_p$ into similarity pairs and seek to reduce $(s_n-s_p)$. Such an optimization manner is inflexible, because the penalty strength on every single similarity score is restricted to be equal. Our intuition is that if a similarity score deviates far from the optimum, it should be emphasized. To this end, we simply re-weight each similarity to highlight the less-optimized similarity scores. It results in a Circle loss, which is named due to its circular decision boundary. The Circle loss has a unified formula for two elemental deep feature learning approaches, i.e. learning with class-level labels and pair-wise labels. Analytically, we show that the Circle loss offers a more flexible optimization approach towards a more definite convergence target, compared with the loss functions optimizing $(s_n-s_p)$. Experimentally, we demonstrate the superiority of the Circle loss on a variety of deep feature learning tasks. On face recognition, person re-identification, as well as several fine-grained image retrieval datasets, the achieved performance is on par with the state of the art.
Simulating Content Consistent Vehicle Datasets with Attribute Descent
Dec 18, 2019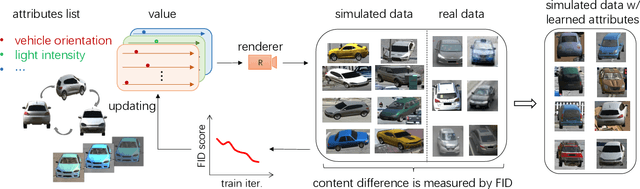
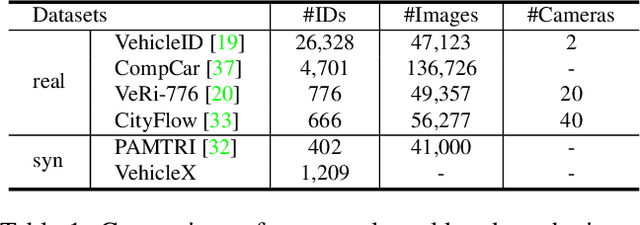

We simulate data using a graphic engine to augment real-world datasets, with application to vehicle re-identification (re-ID). In order for data augmentation to be effective, the simulated data should be similar to the real data in key attributes like illumination and viewpoint. We introduce a large-scale synthetic dataset VehicleX. Created in Unity, it contains 1,209 vehicles of various models in 3D with fully editable attributes. We propose an attribute descent approach to let VehicleX approximate the attributes in real-world datasets. Specifically, we manipulate each attribute in VehicleX, aiming to minimize the discrepancy between VehicleX and real data in terms of the Fr'echet Inception Distance (FID). This attribute descent algorithm allows content-level domain adaptation (DA), which has advantages over existing DA methods working on the pixel level or feature level. We mix adapted VehicleX data with three vehicle re-ID datasets individually, and observe consistent improvement when the proposed attribute descent is applied. With the augmented datasets, we report competitive accuracy compared with state-of-the-art results. The VehicleX engine and code of this paper will be released.
Locality Aware Appearance Metric for Multi-Target Multi-Camera Tracking
Nov 27, 2019
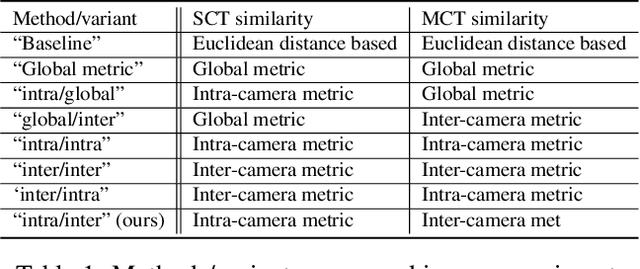
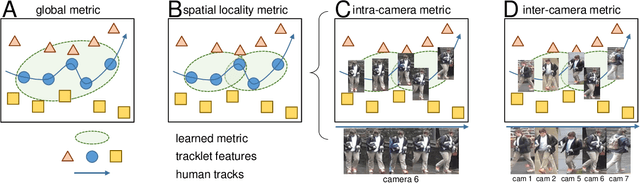
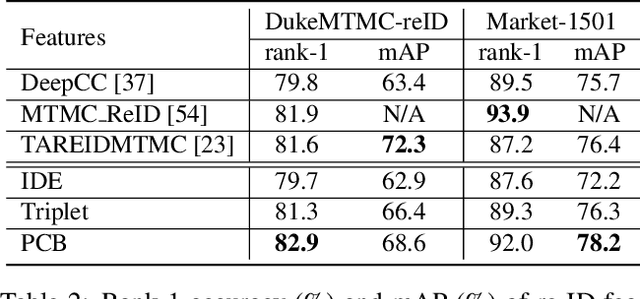
Multi-target multi-camera tracking (MTMCT) systems track targets across cameras. Due to the continuity of target trajectories, tracking systems usually restrict their data association within a local neighborhood. In single camera tracking, local neighborhood refers to consecutive frames; in multi-camera tracking, it refers to neighboring cameras that the target may appear successively. For similarity estimation, tracking systems often adopt appearance features learned from the re-identification (re-ID) perspective. Different from tracking, re-ID usually does not have access to the trajectory cues that can limit the search space to a local neighborhood. Due to its global matching property, the re-ID perspective requires to learn global appearance features. We argue that the mismatch between the local matching procedure in tracking and the global nature of re-ID appearance features may compromise MTMCT performance. To fit the local matching procedure in MTMCT, in this work, we introduce locality aware appearance metric (LAAM). Specifically, we design an intra-camera metric for single camera tracking, and an inter-camera metric for multi-camera tracking. Both metrics are trained with data pairs sampled from their corresponding local neighborhoods, as opposed to global sampling in the re-ID perspective. We show that the locally learned metrics can be successfully applied on top of several globally learned re-ID features. With the proposed method, we report new state-of-the-art performance on the DukeMTMC dataset, and a substantial improvement on the CityFlow dataset.
Towards Real-Time Multi-Object Tracking
Sep 27, 2019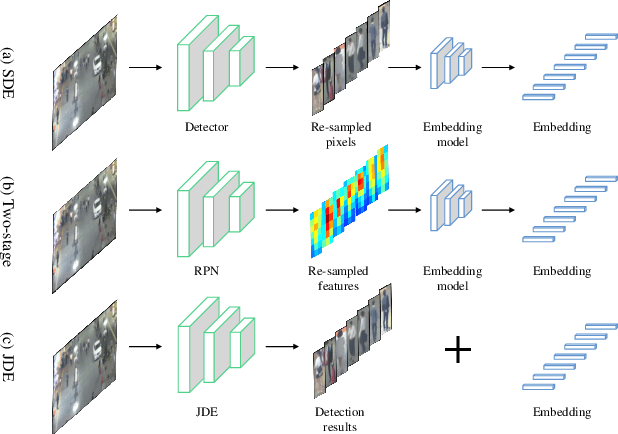
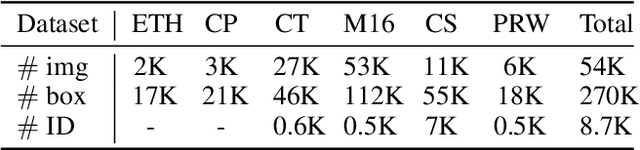
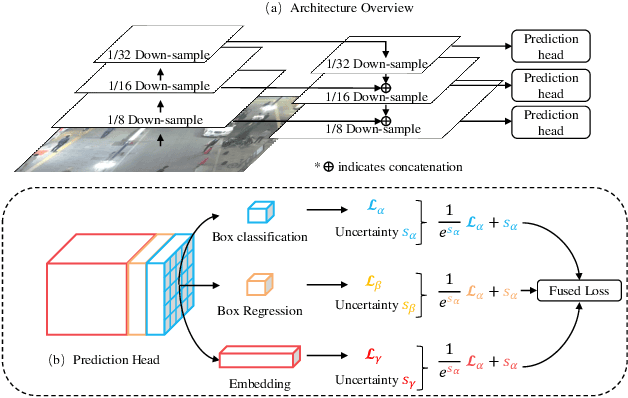
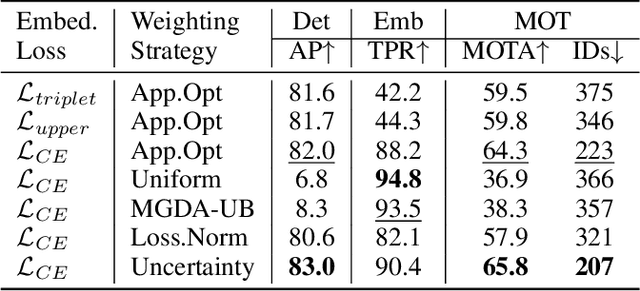
Modern multiple object tracking (MOT) systems usually follow the tracking-by-detection paradigm. It has 1) a detection model for target localization and 2) an appearance embedding model for data association. Having the two models separately executed might lead to efficiency problems, as the running time is simply a sum of the two steps without investigating potential structures that can be shared between them. Existing research efforts on real-time MOT usually focus on the association step, so they are essentially real-time association methods but not real-time MOT system. In this paper, we propose an MOT system that allows target detection and appearance embedding to be learned in a shared model. Specifically, we incorporate the appearance embedding model into a single-shot detector, such that the model can simultaneously output detections and the corresponding embeddings. As such, the system is formulated as a multi-task learning problem: there are multiple objectives, i.e., anchor classification, bounding box regression, and embedding learning; and the individual losses are automatically weighted. To our knowledge, this work reports the first (near) real-time MOT system, with a running speed of 18.8 to 24.1 FPS depending on the input resolution. Meanwhile, its tracking accuracy is comparable to the state-of-the-art trackers embodying separate detection and embedding (SDE) learning (64.4% MOTA v.s. 66.1% MOTA on MOT-16 challenge). The code and models are available at https://github.com/Zhongdao/Towards-Realtime-MOT.
Learning to Adapt Invariance in Memory for Person Re-identification
Aug 01, 2019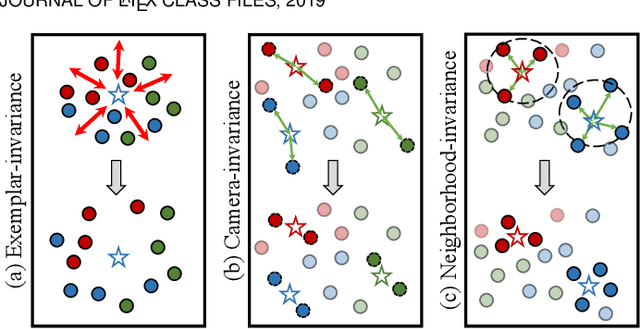
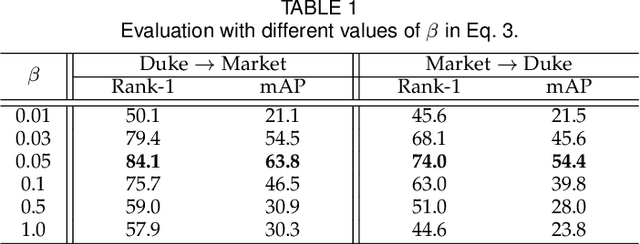
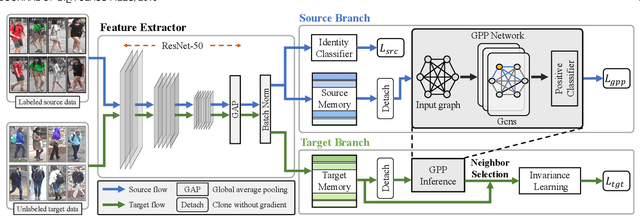

This work considers the problem of unsupervised domain adaptation in person re-identification (re-ID), which aims to transfer knowledge from the source domain to the target domain. Existing methods are primary to reduce the inter-domain shift between the domains, which however usually overlook the relations among target samples. This paper investigates into the intra-domain variations of the target domain and proposes a novel adaptation framework w.r.t. three types of underlying invariance, i.e., Exemplar-Invariance, Camera-Invariance, and Neighborhood-Invariance. Specifically, an exemplar memory is introduced to store features of samples, which can effectively and efficiently enforce the invariance constraints over the global dataset. We further present the Graph-based Positive Prediction (GPP) method to explore reliable neighbors for the target domain, which is built upon the memory and is trained on the source samples. Experiments demonstrate that 1) the three invariance properties are indispensable for effective domain adaptation, 2) the memory plays a key role in implementing invariance learning and improves the performance with limited extra computation cost, 3) GPP could facilitate the invariance learning and thus significantly improves the results, and 4) our approach produces new state-of-the-art adaptation accuracy on three re-ID large-scale benchmarks.
Joint Discriminative and Generative Learning for Person Re-identification
May 22, 2019
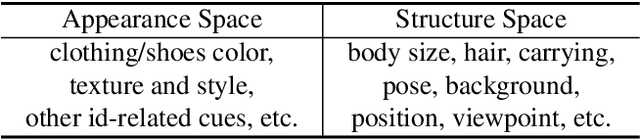
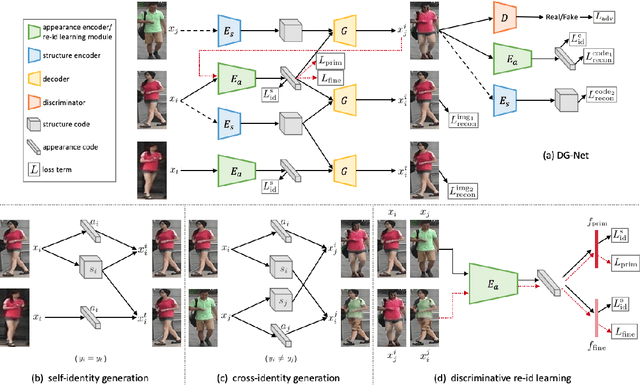
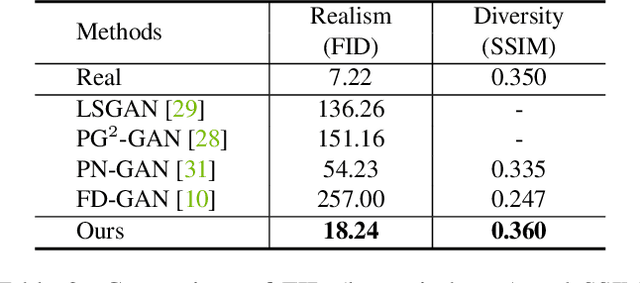
Person re-identification (re-id) remains challenging due to significant intra-class variations across different cameras. Recently, there has been a growing interest in using generative models to augment training data and enhance the invariance to input changes. The generative pipelines in existing methods, however, stay relatively separate from the discriminative re-id learning stages. Accordingly, re-id models are often trained in a straightforward manner on the generated data. In this paper, we seek to improve learned re-id embeddings by better leveraging the generated data. To this end, we propose a joint learning framework that couples re-id learning and data generation end-to-end. Our model involves a generative module that separately encodes each person into an appearance code and a structure code, and a discriminative module that shares the appearance encoder with the generative module. By switching the appearance or structure codes, the generative module is able to generate high-quality cross-id composed images, which are online fed back to the appearance encoder and used to improve the discriminative module. The proposed joint learning framework renders significant improvement over the baseline without using generated data, leading to the state-of-the-art performance on several benchmark datasets.
Linkage Based Face Clustering via Graph Convolution Network
Apr 08, 2019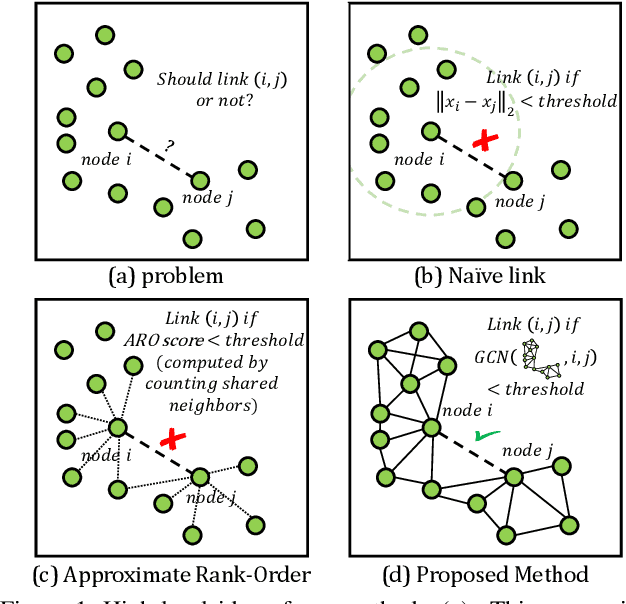
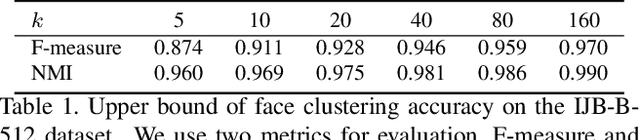
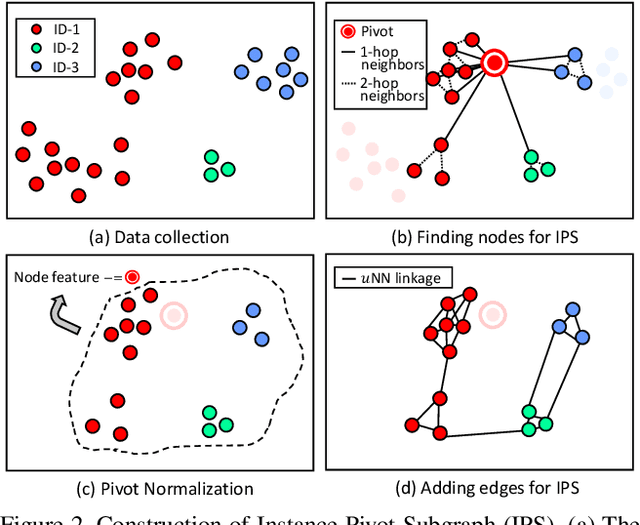
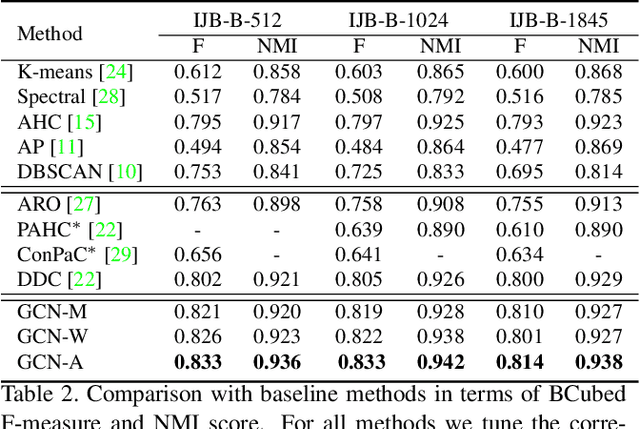
In this paper, we present an accurate and scalable approach to the face clustering task. We aim at grouping a set of faces by their potential identities. We formulate this task as a link prediction problem: a link exists between two faces if they are of the same identity. The key idea is that we find the local context in the feature space around an instance (face) contains rich information about the linkage relationship between this instance and its neighbors. By constructing sub-graphs around each instance as input data, which depict the local context, we utilize the graph convolution network (GCN) to perform reasoning and infer the likelihood of linkage between pairs in the sub-graphs. Experiments show that our method is more robust to the complex distribution of faces than conventional methods, yielding favorably comparable results to state-of-the-art methods on standard face clustering benchmarks, and is scalable to large datasets. Furthermore, we show that the proposed method does not need the number of clusters as prior, is aware of noises and outliers, and can be extended to a multi-view version for more accurate clustering accuracy.