 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Translation in Pronunciation Space
Nov 03, 2019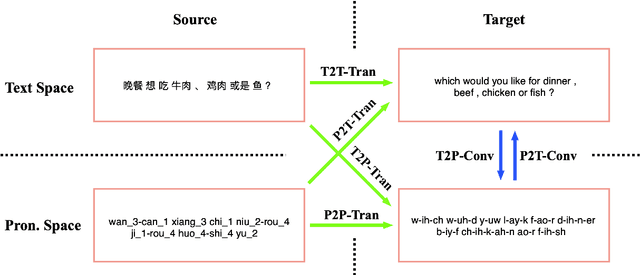



The research in machine translation community focus on translation in text space. However, humans are in fact also good at direct translation in pronunciation space. Some existing translation systems, such as simultaneous machine translation, are inherently more natural and thus potentially more robust by directly translating in pronunciation space. In this paper, we conduct large scale experiments on a self-built dataset with about $20$M En-Zh pairs of text sentences and corresponding pronunciation sentences. We proposed three new categories of translations: $1)$ translating a pronunciation sentence in source language into a pronunciation sentence in target language (P2P-Tran), $2)$ translating a text sentence in source language into a pronunciation sentence in target language (T2P-Tran), and $3)$ translating a pronunciation sentence in source language into a text sentence in target language (P2T-Tran), and compare them with traditional text translation (T2T-Tran). Our experiments clearly show that all $4$ categories of translations have comparable performances, with small and sometimes ignorable differences.
Simpler and Faster Learning of Adaptive Policies for Simultaneous Translation
Sep 12, 2019
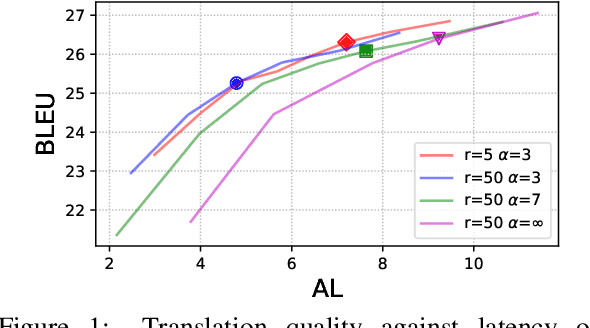
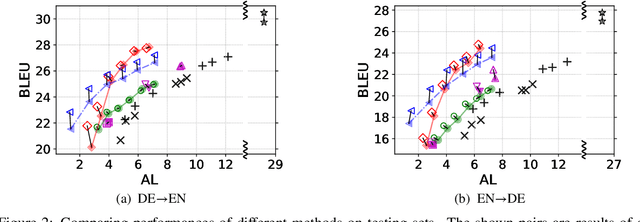
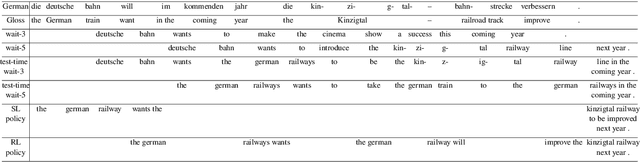
Simultaneous translation is widely useful but remains challenging. Previous work falls into two main categories: (a) fixed-latency policies such as Ma et al. (2019) and (b) adaptive policies such as Gu et al. (2017). The former are simple and effective, but have to aggressively predict future content due to diverging source-target word order; the latter do not anticipate, but suffer from unstable and inefficient training. To combine the merits of both approaches, we propose a simple supervised-learning framework to learn an adaptive policy from oracle READ/WRITE sequences generated from parallel text. At each step, such an oracle sequence chooses to WRITE the next target word if the available source sentence context provides enough information to do so, otherwise READ the next source word. Experiments on German<->English show that our method, without retraining the underlying NMT model, can learn flexible policies with better BLEU scores and similar latencies compared to previous work.
Speculative Beam Search for Simultaneous Translation
Sep 12, 2019

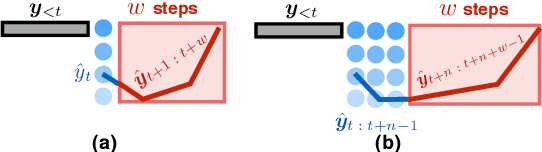
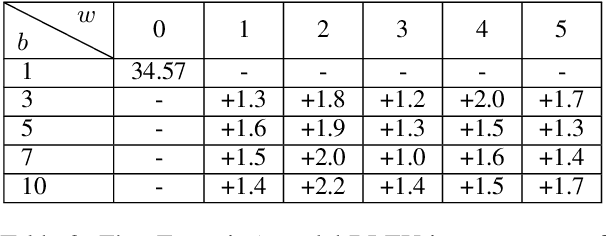
Beam search is universally used in full-sentence translation but its application to simultaneous translation remains non-trivial, where output words are committed on the fly. In particular, the recently proposed wait-k policy (Ma et al., 2019a) is a simple and effective method that (after an initial wait) commits one output word on receiving each input word, making beam search seemingly impossible. To address this challenge, we propose a speculative beam search algorithm that hallucinates several steps into the future in order to reach a more accurate decision, implicitly benefiting from a target language model. This makes beam search applicable for the first time to the generation of a single word in each step. Experiments over diverse language pairs show large improvements over previous work.
Robust Machine Translation with Domain Sensitive Pseudo-Sources: Baidu-OSU WMT19 MT Robustness Shared Task System Report
Jun 22, 2019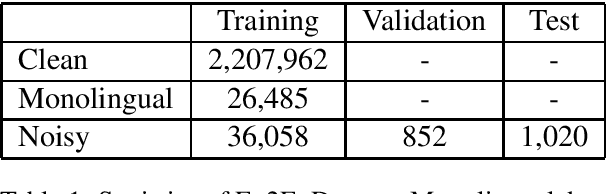
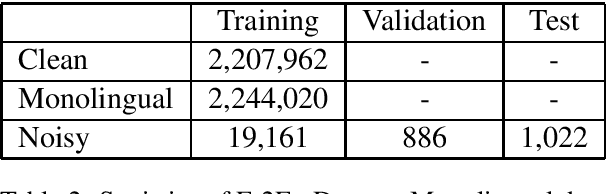
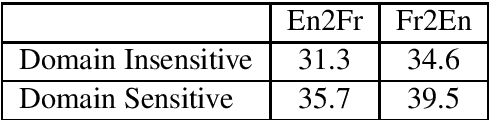
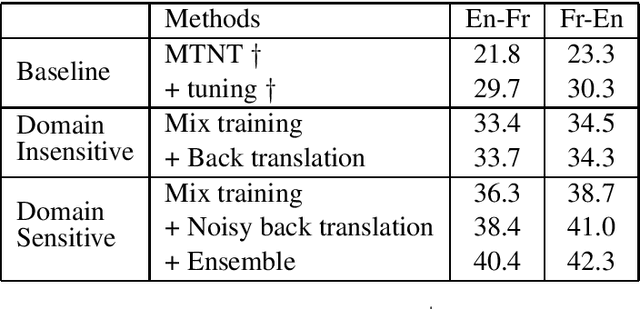
This paper describes the machine translation system developed jointly by Baidu Research and Oregon State University for WMT 2019 Machine Translation Robustness Shared Task. Translation of social media is a very challenging problem, since its style is very different from normal parallel corpora (e.g. News) and also include various types of noises. To make it worse, the amount of social media parallel corpora is extremely limited. In this paper, we use a domain sensitive training method which leverages a large amount of parallel data from popular domains together with a little amount of parallel data from social media. Furthermore, we generate a parallel dataset with pseudo noisy source sentences which are back-translated from monolingual data using a model trained by a similar domain sensitive way. We achieve more than 10 BLEU improvement in both En-Fr and Fr-En translation compared with the baseline methods.
Simultaneous Translation with Flexible Policy via Restricted Imitation Learning
Jun 04, 2019
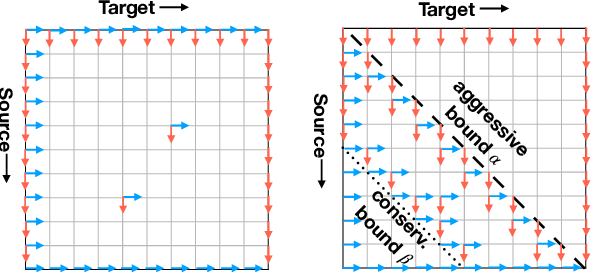
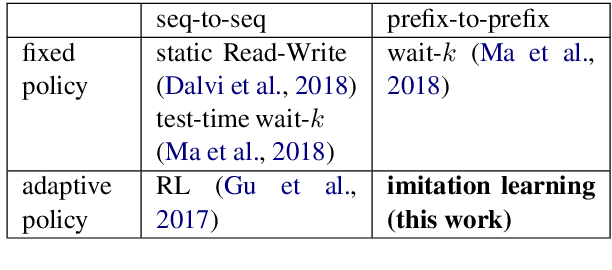
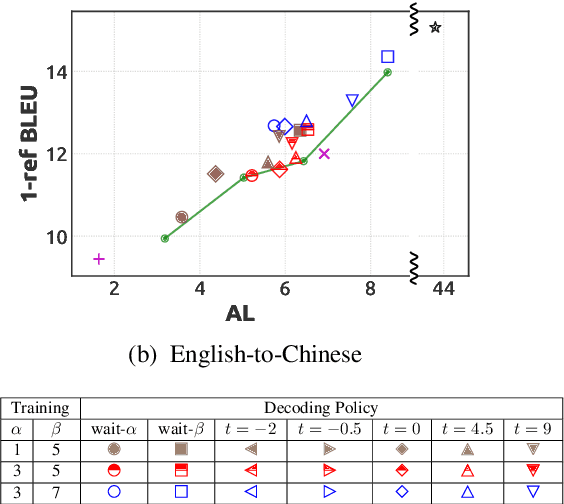
Simultaneous translation is widely useful but remains one of the most difficult tasks in NLP. Previous work either uses fixed-latency policies, or train a complicated two-staged model using reinforcement learning. We propose a much simpler single model that adds a `delay' token to the target vocabulary, and design a restricted dynamic oracle to greatly simplify training. Experiments on Chinese<->English simultaneous translation show that our work leads to flexible policies that achieve better BLEU scores and lower latencies compared to both fixed and RL-learned policies.
Learning to Stop in Structured Prediction for Neural Machine Translation
Apr 01, 2019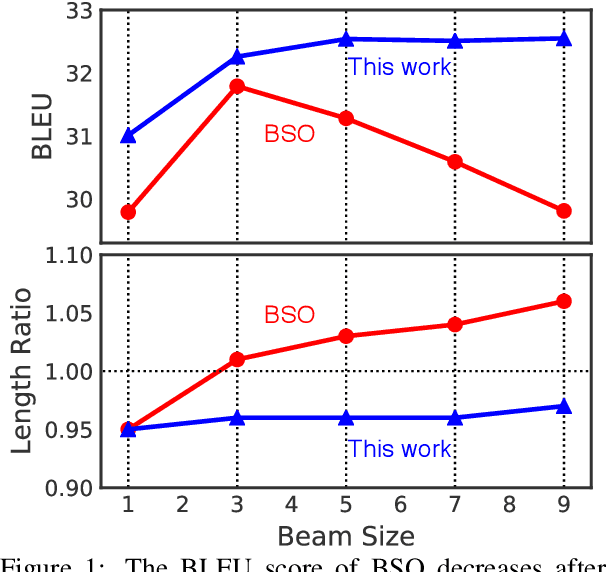
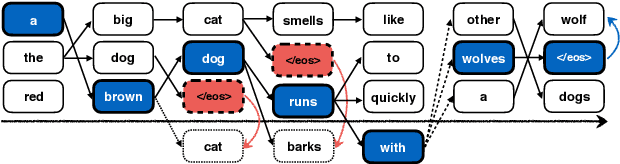
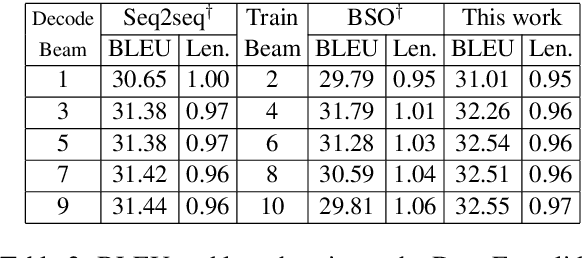
Beam search optimization resolves many issues in neural machine translation. However, this method lacks principled stopping criteria and does not learn how to stop during training, and the model naturally prefers the longer hypotheses during the testing time in practice since they use the raw score instead of the probability-based score. We propose a novel ranking method which enables an optimal beam search stopping criteria. We further introduce a structured prediction loss function which penalizes suboptimal finished candidates produced by beam search during training. Experiments of neural machine translation on both synthetic data and real languages (German-to-English and Chinese-to-English) demonstrate our proposed methods lead to better length and BLEU score.
* 5 pages
STACL: Simultaneous Translation with Integrated Anticipation and Controllable Latency
Nov 03, 2018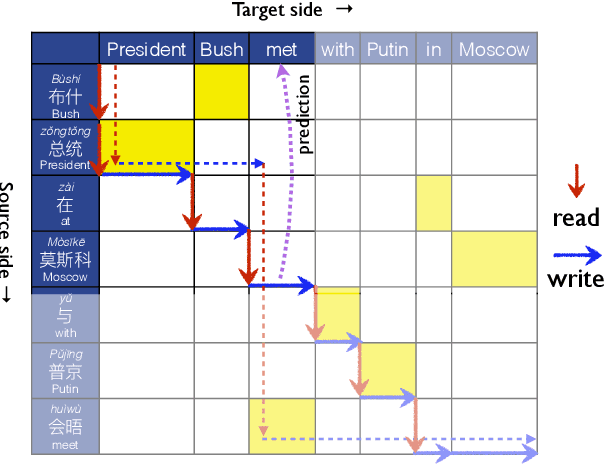
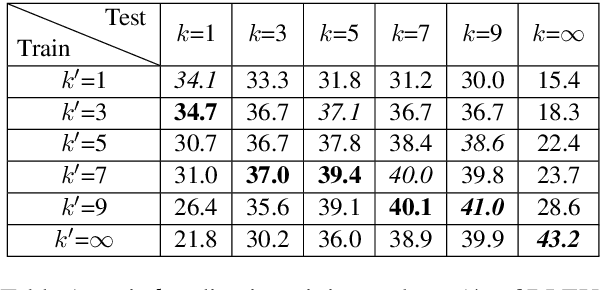

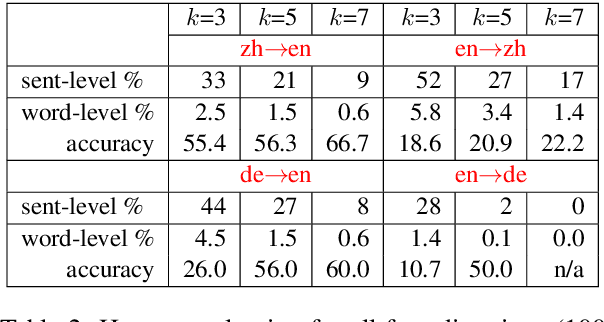
Simultaneous translation, which translates sentences before they are finished, is useful in many scenarios but is notoriously difficult due to word-order differences and simultaneity requirements. We introduce a very simple yet surprisingly effective `wait-k' model trained to generate the target sentence concurrently with the source sentence, but always k words behind, for any given k. This framework seamlessly integrates anticipation and translation in a single model that involves only minor changes to the existing neural translation framework. Experiments on Chinese-to-English simultaneous translation achieve a 5-word latency with 3.4 (single-ref) BLEU points degradation in quality compared to full-sentence non-simultaneous translation. We also formulate a new latency metric that addresses deficiencies in previous ones.
Breaking the Beam Search Curse: A Study of Scoring Methods and Stopping Criteria for Neural Machine Translation
Oct 27, 2018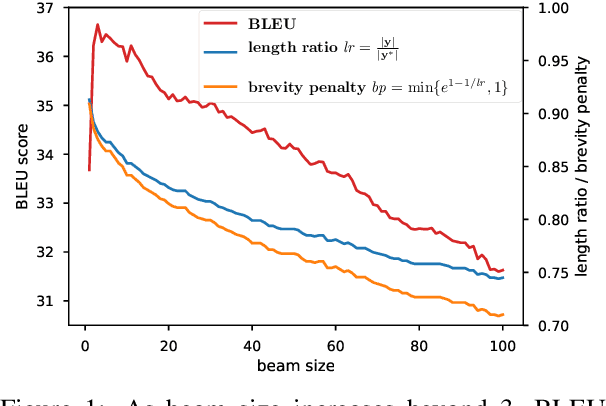
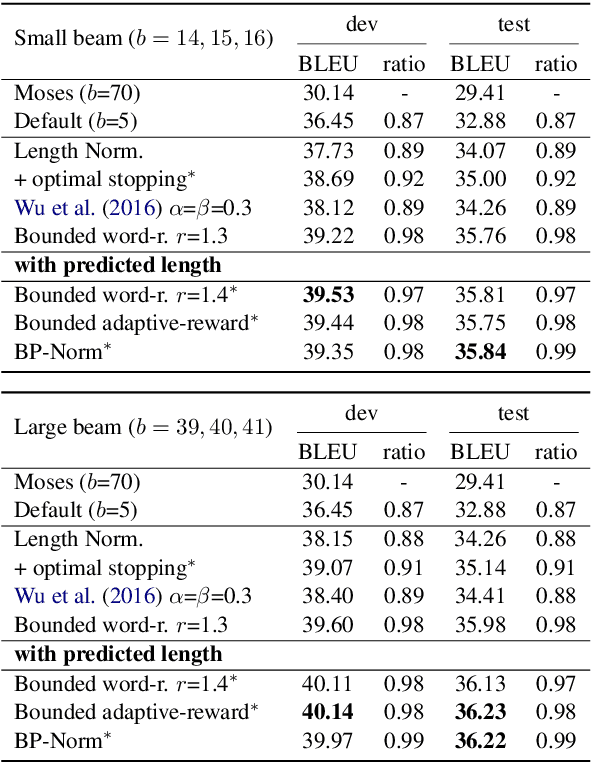
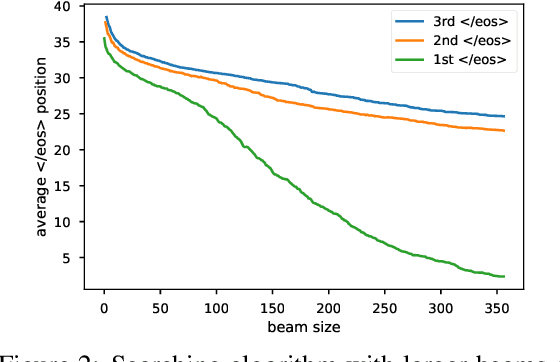
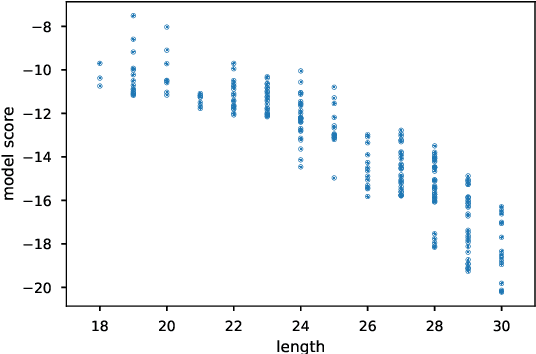
Beam search is widely used in neural machine translation, and usually improves translation quality compared to greedy search. It has been widely observed that, however, beam sizes larger than 5 hurt translation quality. We explain why this happens, and propose several methods to address this problem. Furthermore, we discuss the optimal stopping criteria for these methods. Results show that our hyperparameter-free methods outperform the widely-used hyperparameter-free heuristic of length normalization by +2.0 BLEU, and achieve the best results among all methods on Chinese-to-English translation.
Robust Neural Machine Translation with Joint Textual and Phonetic Embedding
Oct 15, 2018
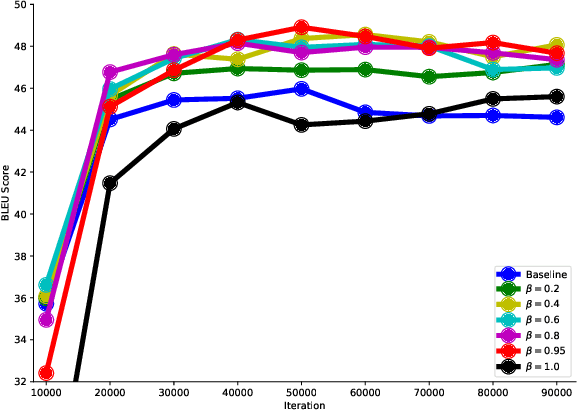
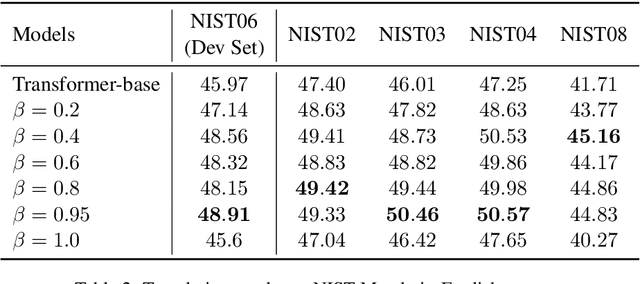
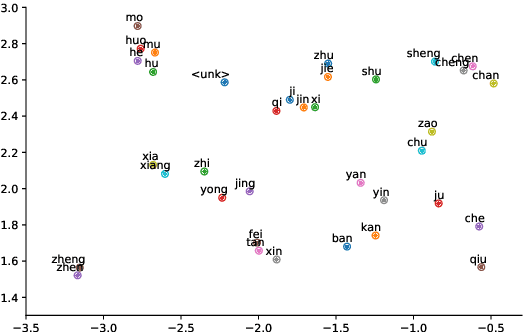
Neural machine translation (NMT) is notoriously sensitive to noises, but noises are almost inevitable in practice. One special kind of noise is the homophone noise, where words are replaced by other words with the same (or similar) pronunciations. Homophone noise arises frequently from many real-world scenarios upstream to translation, such as automatic speech recognition (ASR) or phonetic-based input systems. We propose to improve the robustness of NMT to homophone noise by 1) jointly embedding both textual and phonetic information of source sentences, and 2) augmenting the training dataset with homophone noise. Interestingly, we found that in order to achieve the best translation quality, most (though not all) weights should be put on the phonetic rather than textual information, where the latter is only used as auxiliary information. Experiments show that our method not only significantly improves the robustness of NMT to homophone noise, which is expected but also surprisingly improves the translation quality on clean test sets.
Speeding Up Neural Machine Translation Decoding by Cube Pruning
Sep 09, 2018
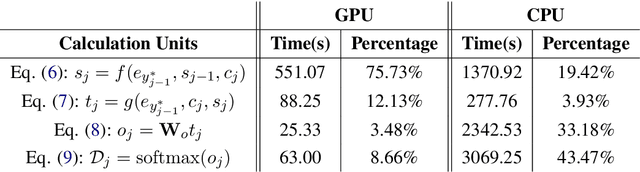
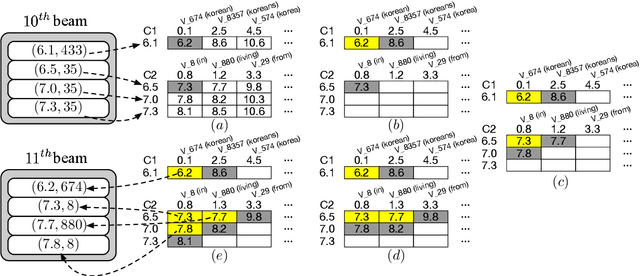
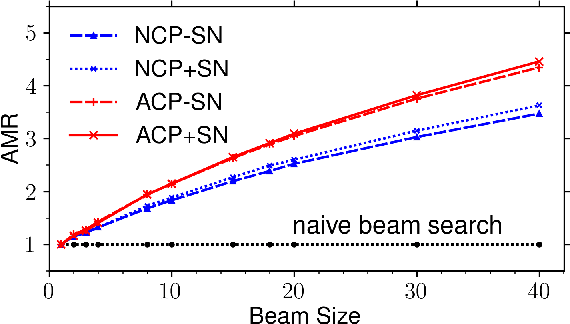
Although neural machine translation has achieved promising results, it suffers from slow translation speed. The direct consequence is that a trade-off has to be made between translation quality and speed, thus its performance can not come into full play. We apply cube pruning, a popular technique to speed up dynamic programming, into neural machine translation to speed up the translation. To construct the equivalence class, similar target hidden states are combined, leading to less RNN expansion operations on the target side and less \$\mathrm{softmax}\$ operations over the large target vocabulary. The experiments show that, at the same or even better translation quality, our method can translate faster compared with naive beam search by \$3.3\times\$ on GPUs and \$3.5\times\$ on CPUs.