 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Block-ADMM for Training Deep Networks
May 01, 2021

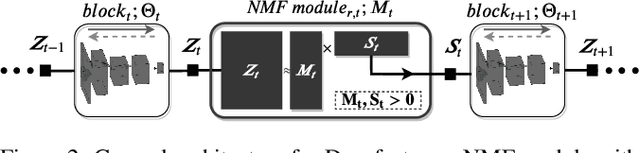
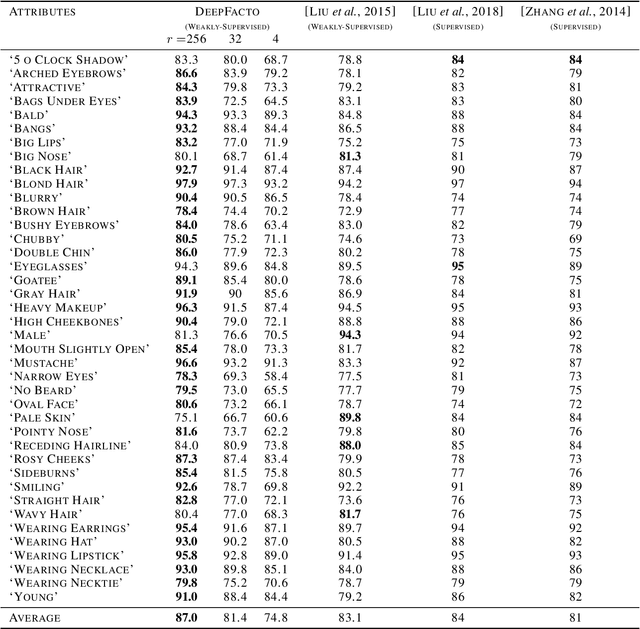
In this paper, we propose Stochastic Block-ADMM as an approach to train deep neural networks in batch and online settings. Our method works by splitting neural networks into an arbitrary number of blocks and utilizes auxiliary variables to connect these blocks while optimizing with stochastic gradient descent. This allows training deep networks with non-differentiable constraints where conventional backpropagation is not applicable. An application of this is supervised feature disentangling, where our proposed DeepFacto inserts a non-negative matrix factorization (NMF) layer into the network. Since backpropagation only needs to be performed within each block, our approach alleviates vanishing gradients and provides potentials for parallelization. We prove the convergence of our proposed method and justify its capabilities through experiments in supervised and weakly-supervised settings.
Deep Convolution for Irregularly Sampled Temporal Point Clouds
May 01, 2021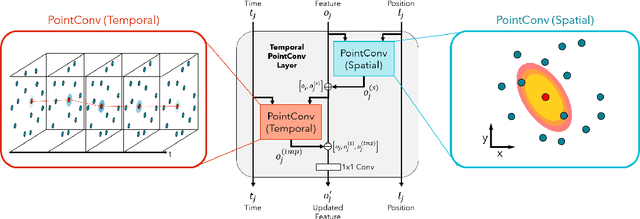

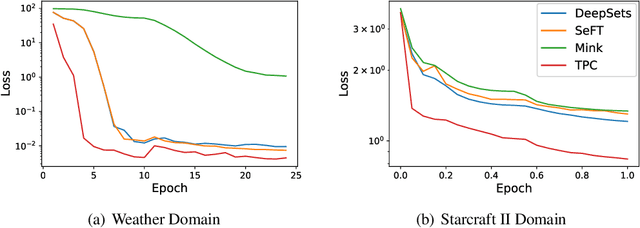

We consider the problem of modeling the dynamics of continuous spatial-temporal processes represented by irregular samples through both space and time. Such processes occur in sensor networks, citizen science, multi-robot systems, and many others. We propose a new deep model that is able to directly learn and predict over this irregularly sampled data, without voxelization, by leveraging a recent convolutional architecture for static point clouds. The model also easily incorporates the notion of multiple entities in the process. In particular, the model can flexibly answer prediction queries about arbitrary space-time points for different entities regardless of the distribution of the training or test-time data. We present experiments on real-world weather station data and battles between large armies in StarCraft II. The results demonstrate the model's flexibility in answering a variety of query types and demonstrate improved performance and efficiency compared to state-of-the-art baselines.
Topology-Aware Segmentation Using Discrete Morse Theory
Mar 18, 2021
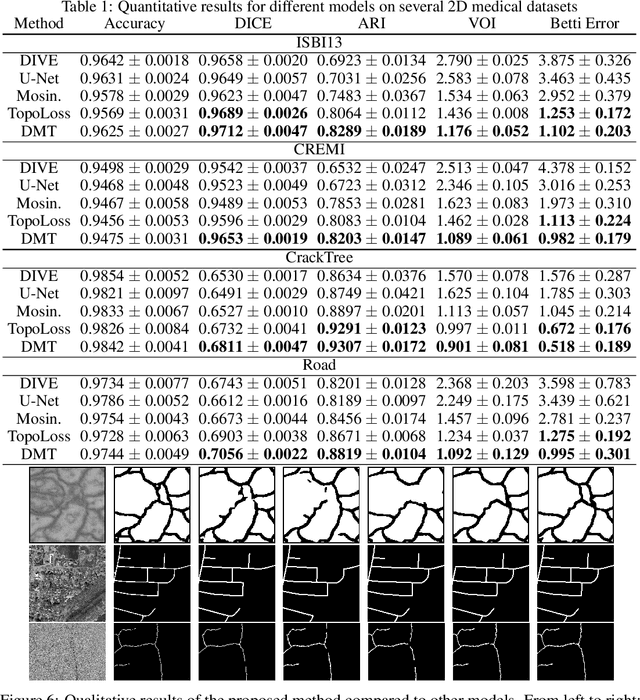
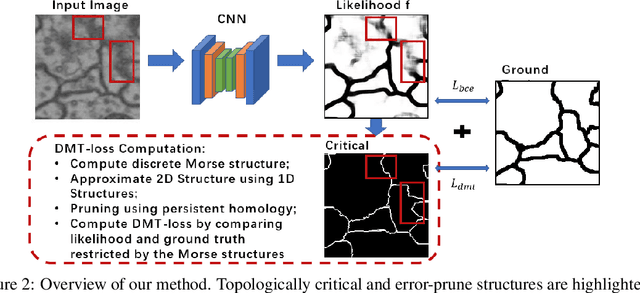
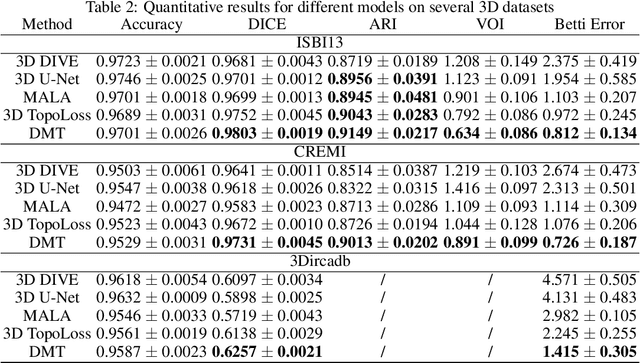
In the segmentation of fine-scale structures from natural and biomedical images, per-pixel accuracy is not the only metric of concern. Topological correctness, such as vessel connectivity and membrane closure, is crucial for downstream analysis tasks. In this paper, we propose a new approach to train deep image segmentation networks for better topological accuracy. In particular, leveraging the power of discrete Morse theory (DMT), we identify global structures, including 1D skeletons and 2D patches, which are important for topological accuracy. Trained with a novel loss based on these global structures, the network performance is significantly improved especially near topologically challenging locations (such as weak spots of connections and membranes). On diverse datasets, our method achieves superior performance on both the DICE score and topological metrics.
Generative Particle Variational Inference via Estimation of Functional Gradients
Mar 01, 2021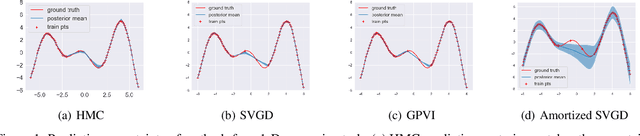
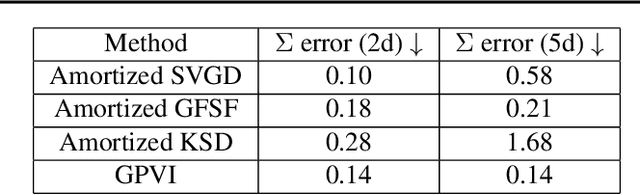
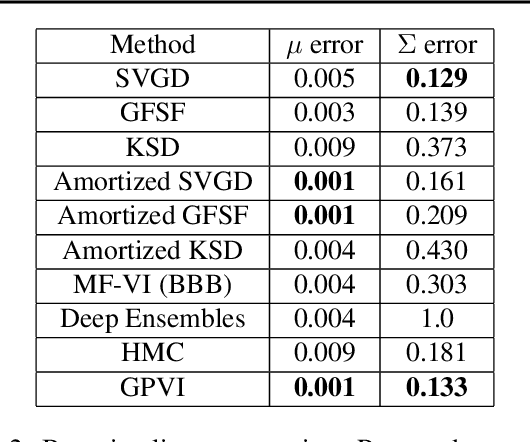
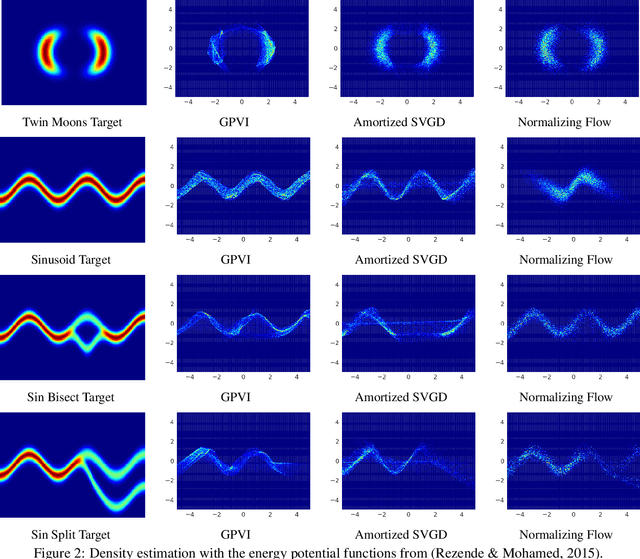
Recently, particle-based variational inference (ParVI) methods have gained interest because they directly minimize the Kullback-Leibler divergence and do not suffer from approximation errors from the evidence-based lower bound. However, many ParVI approaches do not allow arbitrary sampling from the posterior, and the few that do allow such sampling suffer from suboptimality. This work proposes a new method for learning to approximately sample from the posterior distribution. We construct a neural sampler that is trained with the functional gradient of the KL-divergence between the empirical sampling distribution and the target distribution, assuming the gradient resides within a reproducing kernel Hilbert space. Our generative ParVI (GPVI) approach maintains the asymptotic performance of ParVI methods while offering the flexibility of a generative sampler. Through carefully constructed experiments, we show that GPVI outperforms previous generative ParVI methods such as amortized SVGD, and is competitive with ParVI as well as gold-standard approaches like Hamiltonian Monte Carlo for fitting both exactly known and intractable target distributions.
The Devils in the Point Clouds: Studying the Robustness of Point Cloud Convolutions
Jan 28, 2021
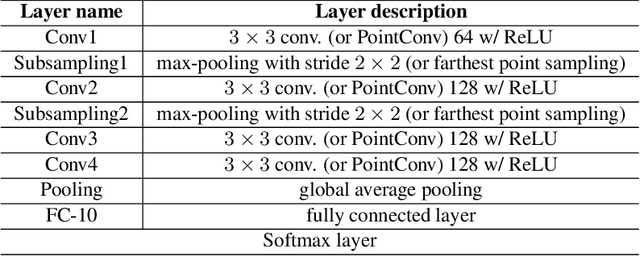
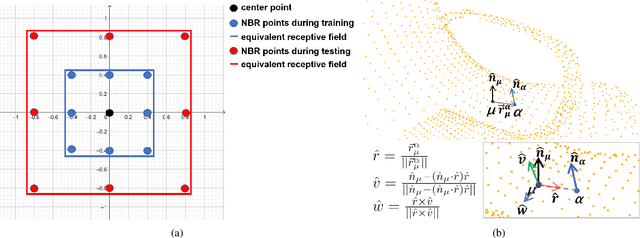
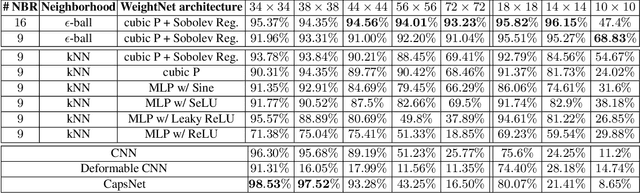
Recently, there has been a significant interest in performing convolution over irregularly sampled point clouds. Since point clouds are very different from regular raster images, it is imperative to study the generalization of the convolution networks more closely, especially their robustness under variations in scale and rotations of the input data. This paper investigates different variants of PointConv, a convolution network on point clouds, to examine their robustness to input scale and rotation changes. Of the variants we explored, two are novel and generated significant improvements. The first is replacing the multilayer perceptron based weight function with much simpler third degree polynomials, together with a Sobolev norm regularization. Secondly, for 3D datasets, we derive a novel viewpoint-invariant descriptor by utilizing 3D geometric properties as the input to PointConv, in addition to the regular 3D coordinates. We have also explored choices of activation functions, neighborhood, and subsampling methods. Experiments are conducted on the 2D MNIST & CIFAR-10 datasets as well as the 3D SemanticKITTI & ScanNet datasets. Results reveal that on 2D, using third degree polynomials greatly improves PointConv's robustness to scale changes and rotations, even surpassing traditional 2D CNNs for the MNIST dataset. On 3D datasets, the novel viewpoint-invariant descriptor significantly improves the performance as well as robustness of PointConv. We achieve the state-of-the-art semantic segmentation performance on the SemanticKITTI dataset, as well as comparable performance with the current highest framework on the ScanNet dataset among point-based approaches.
Discriminative Appearance Modeling with Multi-track Pooling for Real-time Multi-object Tracking
Jan 28, 2021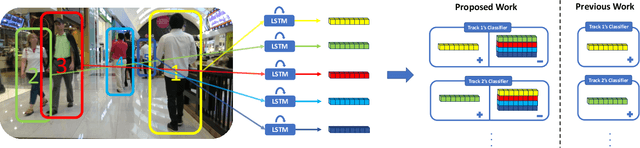

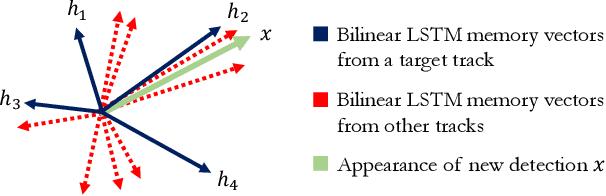

In multi-object tracking, the tracker maintains in its memory the appearance and motion information for each object in the scene. This memory is utilized for finding matches between tracks and detections and is updated based on the matching result. Many approaches model each target in isolation and lack the ability to use all the targets in the scene to jointly update the memory. This can be problematic when there are similar looking objects in the scene. In this paper, we solve the problem of simultaneously considering all tracks during memory updating, with only a small spatial overhead, via a novel multi-track pooling module. We additionally propose a training strategy adapted to multi-track pooling which generates hard tracking episodes online. We show that the combination of these innovations results in a strong discriminative appearance model, enabling the use of greedy data association to achieve online tracking performance. Our experiments demonstrate real-time, state-of-the-art performance on public multi-object tracking (MOT) datasets.
Structured Attention Graphs for Understanding Deep Image Classifications
Dec 08, 2020

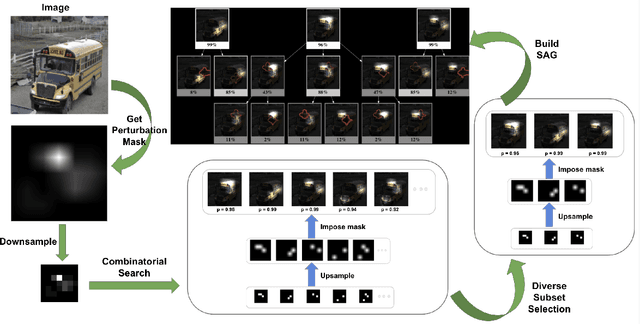

Attention maps are a popular way of explaining the decisions of convolutional networks for image classification. Typically, for each image of interest, a single attention map is produced, which assigns weights to pixels based on their importance to the classification. A single attention map, however, provides an incomplete understanding since there are often many other maps that explain a classification equally well. In this paper, we introduce structured attention graphs (SAGs), which compactly represent sets of attention maps for an image by capturing how different combinations of image regions impact a classifier's confidence. We propose an approach to compute SAGs and a visualization for SAGs so that deeper insight can be gained into a classifier's decisions. We conduct a user study comparing the use of SAGs to traditional attention maps for answering counterfactual questions about image classifications. Our results show that the users are more correct when answering comparative counterfactual questions based on SAGs compared to the baselines.
Deep Variational Instance Segmentation
Jul 22, 2020
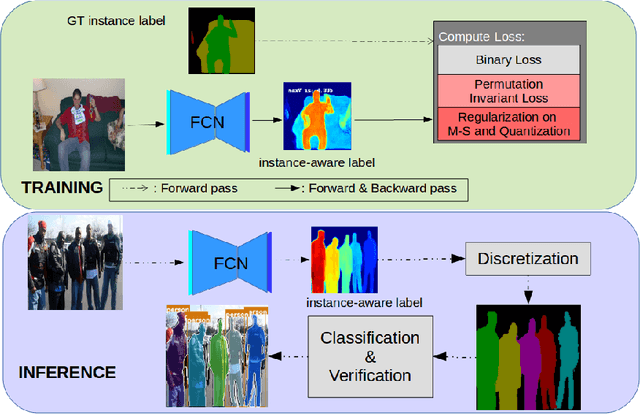
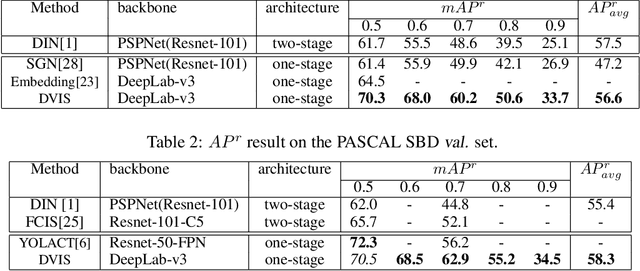
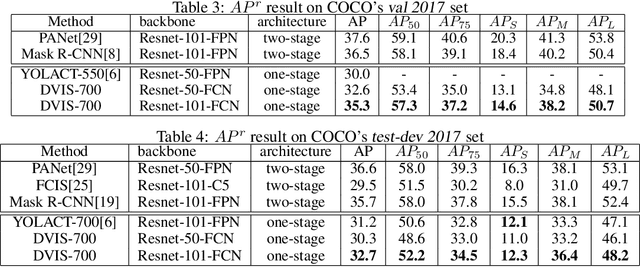
Instance Segmentation, which seeks to obtain both class and instance labels for each pixel in the input image, is a challenging task in computer vision. State-of-the-art algorithms often employ two separate stages, the first one generating object proposals and the second one recognizing and refining the boundaries. Further, proposals are usually based on detectors such as faster R-CNN which search for boxes in the entire image exhaustively. In this paper, we propose a novel algorithm that directly utilizes a fully convolutional network (FCN) to predict instance labels. Specifically, we propose a variational relaxation of instance segmentation as minimizing an optimization functional for a piecewise-constant segmentation problem, which can be used to train an FCN end-to-end. It extends the classical Mumford-Shah variational segmentation problem to be able to handle permutation-invariant labels in the ground truth of instance segmentation. Experiments on PASCAL VOC 2012, Semantic Boundaries dataset(SBD), and the MSCOCO 2017 dataset show that the proposed approach efficiently tackle the instance segmentation task. The source code and trained models will be released with the paper.
Efficient Riemannian Optimization on the Stiefel Manifold via the Cayley Transform
Feb 04, 2020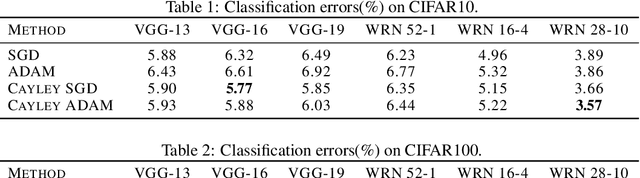
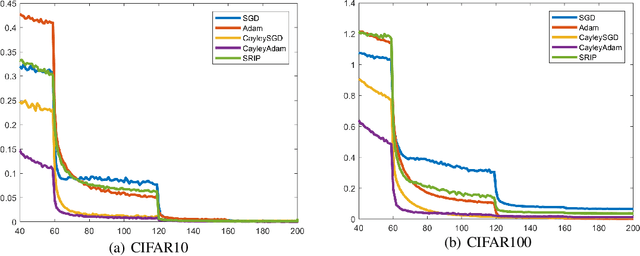

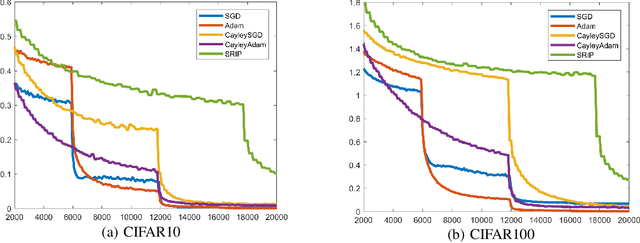
Strictly enforcing orthonormality constraints on parameter matrices has been shown advantageous in deep learning. This amounts to Riemannian optimization on the Stiefel manifold, which, however, is computationally expensive. To address this challenge, we present two main contributions: (1) A new efficient retraction map based on an iterative Cayley transform for optimization updates, and (2) An implicit vector transport mechanism based on the combination of a projection of the momentum and the Cayley transform on the Stiefel manifold. We specify two new optimization algorithms: Cayley SGD with momentum, and Cayley ADAM on the Stiefel manifold. Convergence of Cayley SGD is theoretically analyzed. Our experiments for CNN training demonstrate that both algorithms: (a) Use less running time per iteration relative to existing approaches that enforce orthonormality of CNN parameters; and (b) Achieve faster convergence rates than the baseline SGD and ADAM algorithms without compromising the performance of the CNN. Cayley SGD and Cayley ADAM are also shown to reduce the training time for optimizing the unitary transition matrices in RNNs.
PointPWC-Net: A Coarse-to-Fine Network for Supervised and Self-Supervised Scene Flow Estimation on 3D Point Clouds
Nov 27, 2019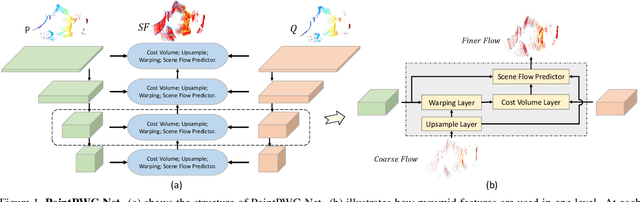
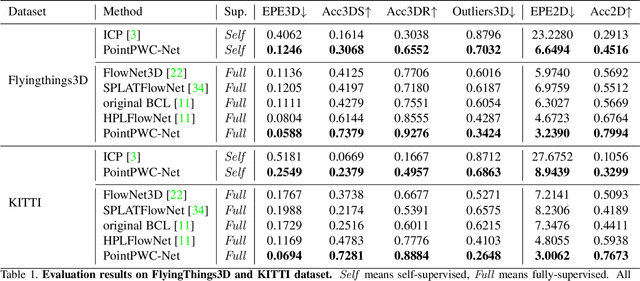
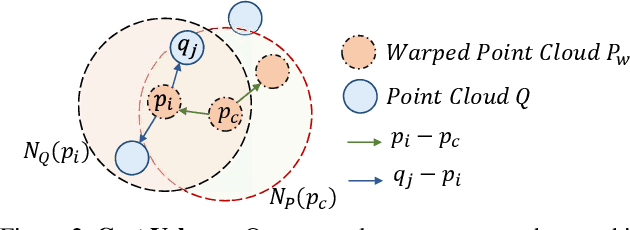
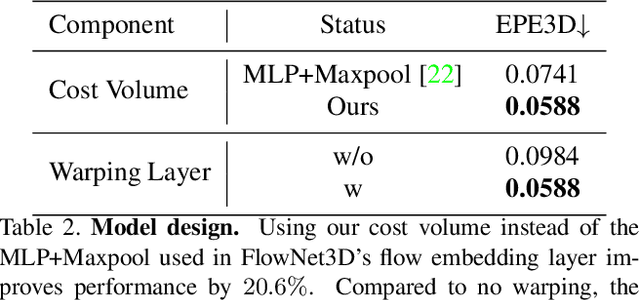
We propose a novel end-to-end deep scene flow model, called PointPWC-Net, on 3D point clouds in a coarse-to-fine fashion. Flow computed at the coarse level is upsampled and warped to a finer level, enabling the algorithm to accommodate for large motion without a prohibitive search space. We introduce novel cost volume, upsampling, and warping layers to efficiently handle 3D point cloud data. Unlike traditional cost volumes that require exhaustively computing all the cost values on a high-dimensional grid, our point-based formulation discretizes the cost volume onto input 3D points, and a PointConv operation efficiently computes convolutions on the cost volume. Experiment results on FlyingThings3D outperform the state-of-the-art by a large margin. We further explore novel self-supervised losses to train our model and achieve comparable results to state-of-the-art trained with supervised loss. Without any fine-tuning, our method also shows great generalization ability on KITTI Scene Flow 2015 dataset, outperforming all previous methods.