 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaming the Tail in Class-Conditional GANs: Knowledge Sharing via Unconditional Training at Lower Resolutions
Feb 26, 2024



Despite the extensive research on training generative adversarial networks (GANs) with limited training data, learning to generate images from long-tailed training distributions remains fairly unexplored. In the presence of imbalanced multi-class training data, GANs tend to favor classes with more samples, leading to the generation of low-quality and less diverse samples in tail classes. In this study, we aim to improve the training of class-conditional GANs with long-tailed data. We propose a straightforward yet effective method for knowledge sharing, allowing tail classes to borrow from the rich information from classes with more abundant training data. More concretely, we propose modifications to existing class-conditional GAN architectures to ensure that the lower-resolution layers of the generator are trained entirely unconditionally while reserving class-conditional generation for the higher-resolution layers. Experiments on several long-tail benchmarks and GAN architectures demonstrate a significant improvement over existing methods in both the diversity and fidelity of the generated images. The code is available at https://github.com/khorrams/utlo.
Diverse Shape Completion via Style Modulated Generative Adversarial Networks
Nov 18, 2023



Shape completion aims to recover the full 3D geometry of an object from a partial observation. This problem is inherently multi-modal since there can be many ways to plausibly complete the missing regions of a shape. Such diversity would be indicative of the underlying uncertainty of the shape and could be preferable for downstream tasks such as planning. In this paper, we propose a novel conditional generative adversarial network that can produce many diverse plausible completions of a partially observed point cloud. To enable our network to produce multiple completions for the same partial input, we introduce stochasticity into our network via style modulation. By extracting style codes from complete shapes during training, and learning a distribution over them, our style codes can explicitly carry shape category information leading to better completions. We further introduce diversity penalties and discriminators at multiple scales to prevent conditional mode collapse and to train without the need for multiple ground truth completions for each partial input. Evaluations across several synthetic and real datasets demonstrate that our method achieves significant improvements in respecting the partial observations while obtaining greater diversity in completions.
Out of Sight, Still in Mind: Reasoning and Planning about Unobserved Objects with Video Tracking Enabled Memory Models
Sep 26, 2023



Robots need to have a memory of previously observed, but currently occluded objects to work reliably in realistic environments. We investigate the problem of encoding object-oriented memory into a multi-object manipulation reasoning and planning framework. We propose DOOM and LOOM, which leverage transformer relational dynamics to encode the history of trajectories given partial-view point clouds and an object discovery and tracking engine. Our approaches can perform multiple challenging tasks including reasoning with occluded objects, novel objects appearance, and object reappearance. Throughout our extensive simulation and real-world experiments, we find that our approaches perform well in terms of different numbers of objects and different numbers of distractor actions. Furthermore, we show our approaches outperform an implicit memory baseline.
AutoFocusFormer: Image Segmentation off the Grid
Apr 24, 2023Real world images often have highly imbalanced content density. Some areas are very uniform, e.g., large patches of blue sky, while other areas are scattered with many small objects. Yet, the commonly used successive grid downsampling strategy in convolutional deep networks treats all areas equally. Hence, small objects are represented in very few spatial locations, leading to worse results in tasks such as segmentation. Intuitively, retaining more pixels representing small objects during downsampling helps to preserve important information. To achieve this, we propose AutoFocusFormer (AFF), a local-attention transformer image recognition backbone, which performs adaptive downsampling by learning to retain the most important pixels for the task. Since adaptive downsampling generates a set of pixels irregularly distributed on the image plane, we abandon the classic grid structure. Instead, we develop a novel point-based local attention block, facilitated by a balanced clustering module and a learnable neighborhood merging module, which yields representations for our point-based versions of state-of-the-art segmentation heads. Experiments show that our AutoFocusFormer (AFF) improves significantly over baseline models of similar sizes.
Maximal Cliques on Multi-Frame Proposal Graph for Unsupervised Video Object Segmentation
Jan 29, 2023



Unsupervised Video Object Segmentation (UVOS) aims at discovering objects and tracking them through videos. For accurate UVOS, we observe if one can locate precise segment proposals on key frames, subsequent processes are much simpler. Hence, we propose to reason about key frame proposals using a graph built with the object probability masks initially generated from multiple frames around the key frame and then propagated to the key frame. On this graph, we compute maximal cliques, with each clique representing one candidate object. By making multiple proposals in the clique to vote for the key frame proposal, we obtain refined key frame proposals that could be better than any of the single-frame proposals. A semi-supervised VOS algorithm subsequently tracks these key frame proposals to the entire video. Our algorithm is modular and hence can be used with any instance segmentation and semi-supervised VOS algorithm. We achieve state-of-the-art performance on the DAVIS-2017 validation and test-dev dataset. On the related problem of video instance segmentation, our method shows competitive performance with the previous best algorithm that requires joint training with the VOS algorithm.
Examining the Difference Among Transformers and CNNs with Explanation Methods
Dec 15, 2022



We propose a methodology that systematically applies deep explanation algorithms on a dataset-wide basis, to compare different types of visual recognition backbones, such as convolutional networks (CNNs), global attention networks, and local attention networks. Examination of both qualitative visualizations and quantitative statistics across the dataset helps us to gain intuitions that are not just anecdotal, but are supported by the statistics computed on the entire dataset. Specifically, we propose two methods. The first one, sub-explanation counting, systematically searches for minimally-sufficient explanations of all images and count the amount of sub-explanations for each network. The second one, called cross-testing, computes salient regions using one network and then evaluates the performance by only showing these regions as an image to other networks. Through a combination of qualitative insights and quantitative statistics, we illustrate that 1) there are significant differences between the salient features of CNNs and attention models; 2) the occlusion-robustness in local attention models and global attention models may come from different decision-making mechanisms.
BATMAN: Bilateral Attention Transformer in Motion-Appearance Neighboring Space for Video Object Segmentation
Aug 08, 2022
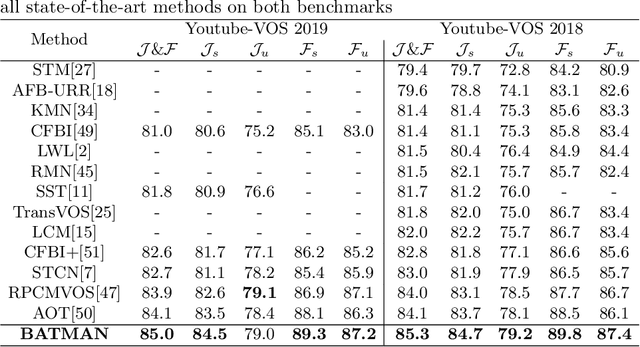
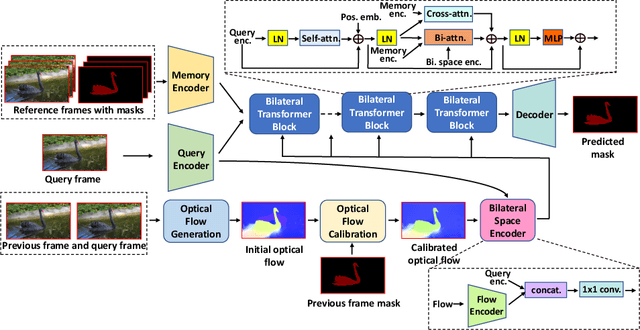
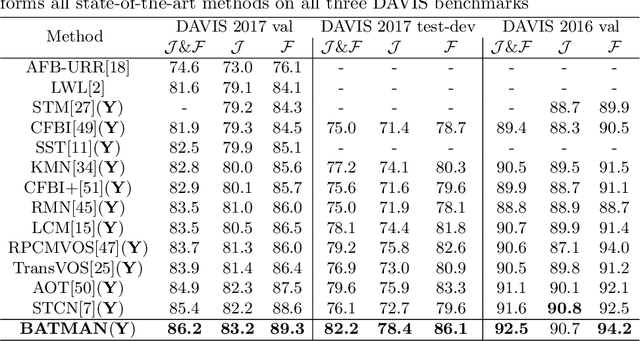
Video Object Segmentation (VOS) is fundamental to video understanding. Transformer-based methods show significant performance improvement on semi-supervised VOS. However, existing work faces challenges segmenting visually similar objects in close proximity of each other. In this paper, we propose a novel Bilateral Attention Transformer in Motion-Appearance Neighboring space (BATMAN) for semi-supervised VOS. It captures object motion in the video via a novel optical flow calibration module that fuses the segmentation mask with optical flow estimation to improve within-object optical flow smoothness and reduce noise at object boundaries. This calibrated optical flow is then employed in our novel bilateral attention, which computes the correspondence between the query and reference frames in the neighboring bilateral space considering both motion and appearance. Extensive experiments validate the effectiveness of BATMAN architecture by outperforming all existing state-of-the-art on all four popular VOS benchmarks: Youtube-VOS 2019 (85.0%), Youtube-VOS 2018 (85.3%), DAVIS 2017Val/Testdev (86.2%/82.2%), and DAVIS 2016 (92.5%).
PointConvFormer: Revenge of the Point-based Convolution
Aug 04, 2022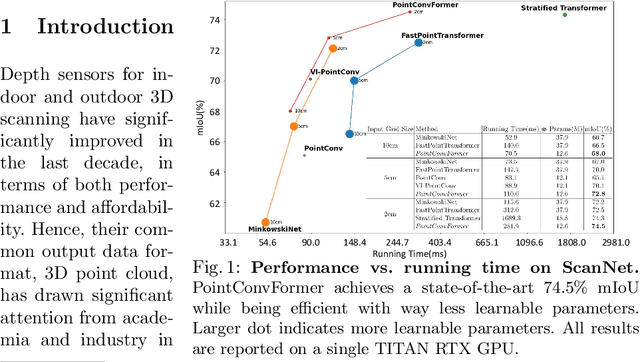
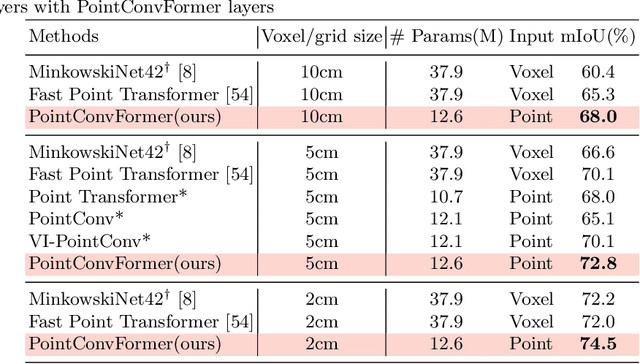
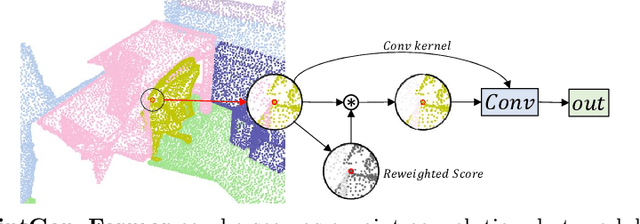
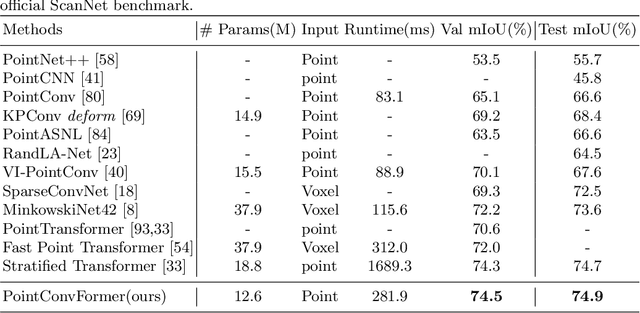
We introduce PointConvFormer, a novel building block for point cloud based deep neural network architectures. Inspired by generalization theory, PointConvFormer combines ideas from point convolution, where filter weights are only based on relative position, and Transformers which utilizes feature-based attention. In PointConvFormer, feature difference between points in the neighborhood serves as an indicator to re-weight the convolutional weights. Hence, we preserved the invariances from the point convolution operation whereas attention is used to select relevant points in the neighborhood for convolution. To validate the effectiveness of PointConvFormer, we experiment on both semantic segmentation and scene flow estimation tasks on point clouds with multiple datasets including ScanNet, SemanticKitti, FlyingThings3D and KITTI. Our results show that PointConvFormer substantially outperforms classic convolutions, regular transformers, and voxelized sparse convolution approaches with smaller, more computationally efficient networks. Visualizations show that PointConvFormer performs similarly to convolution on flat surfaces, whereas the neighborhood selection effect is stronger on object boundaries, showing that it got the best of both worlds.
Cycle-Consistent Counterfactuals by Latent Transformations
Mar 28, 2022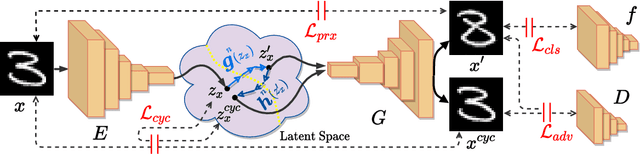



CounterFactual (CF) visual explanations try to find images similar to the query image that change the decision of a vision system to a specified outcome. Existing methods either require inference-time optimization or joint training with a generative adversarial model which makes them time-consuming and difficult to use in practice. We propose a novel approach, Cycle-Consistent Counterfactuals by Latent Transformations (C3LT), which learns a latent transformation that automatically generates visual CFs by steering in the latent space of generative models. Our method uses cycle consistency between the query and CF latent representations which helps our training to find better solutions. C3LT can be easily plugged into any state-of-the-art pretrained generative network. This enables our method to generate high-quality and interpretable CF images at high resolution such as those in ImageNet. In addition to several established metrics for evaluating CF explanations, we introduce a novel metric tailored to assess the quality of the generated CF examples and validate the effectiveness of our method on an extensive set of experiments.
From Heatmaps to Structural Explanations of Image Classifiers
Sep 13, 2021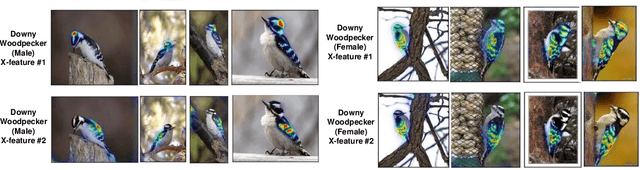
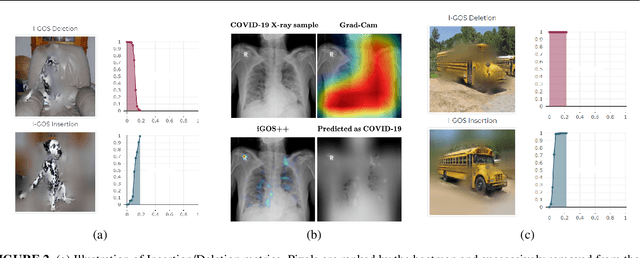

This paper summarizes our endeavors in the past few years in terms of explaining image classifiers, with the aim of including negative results and insights we have gained. The paper starts with describing the explainable neural network (XNN), which attempts to extract and visualize several high-level concepts purely from the deep network, without relying on human linguistic concepts. This helps users understand network classifications that are less intuitive and substantially improves user performance on a difficult fine-grained classification task of discriminating among different species of seagulls. Realizing that an important missing piece is a reliable heatmap visualization tool, we have developed I-GOS and iGOS++ utilizing integrated gradients to avoid local optima in heatmap generation, which improved the performance across all resolutions. During the development of those visualizations, we realized that for a significant number of images, the classifier has multiple different paths to reach a confident prediction. This has lead to our recent development of structured attention graphs (SAGs), an approach that utilizes beam search to locate multiple coarse heatmaps for a single image, and compactly visualizes a set of heatmaps by capturing how different combinations of image regions impact the confidence of a classifier. Through the research process, we have learned much about insights in building deep network explanations, the existence and frequency of multiple explanations, and various tricks of the trade that make explanations work. In this paper, we attempt to share those insights and opinions with the readers with the hope that some of them will be informative for future researchers on explainable deep learning.