 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Pose Estimation and Future Motion Prediction from 2D Images
Nov 26, 2021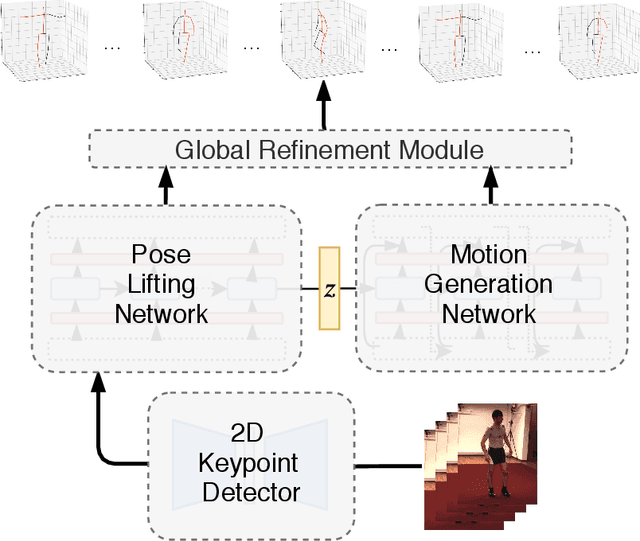
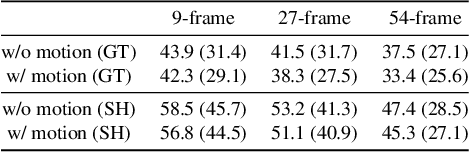

This paper considers to jointly tackle the highly correlated tasks of estimating 3D human body poses and predicting future 3D motions from RGB image sequences. Based on Lie algebra pose representation, a novel self-projection mechanism is proposed that naturally preserves human motion kinematics. This is further facilitated by a sequence-to-sequence multi-task architecture based on an encoder-decoder topology, which enables us to tap into the common ground shared by both tasks. Finally, a global refinement module is proposed to boost the performance of our framework. The effectiveness of our approach, called PoseMoNet, is demonstrated by ablation tests and empirical evaluations on Human3.6M and HumanEva-I benchmark, where competitive performance is obtained comparing to the state-of-the-arts.
The RETA Benchmark for Retinal Vascular Tree Analysis
Nov 23, 2021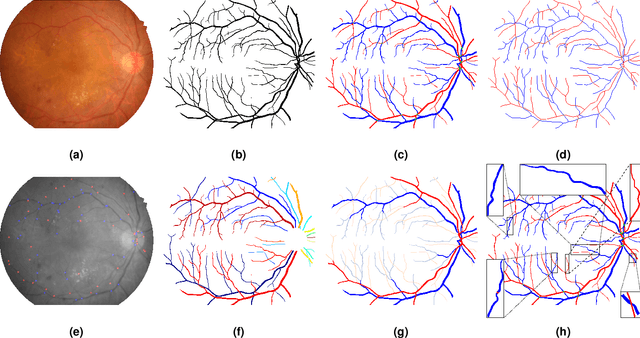

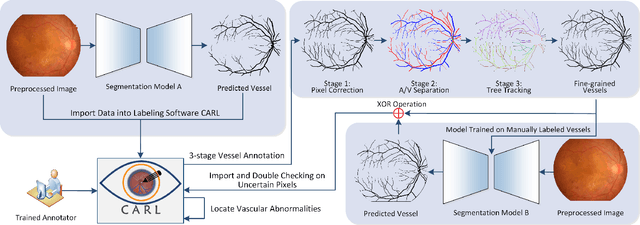
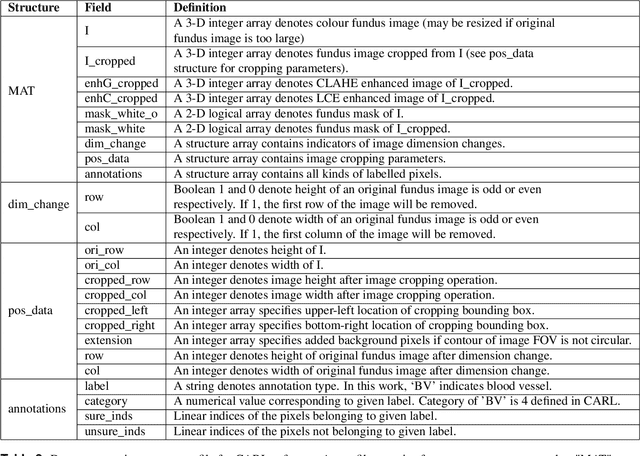
Topological and geometrical analysis of retinal blood vessel is a cost-effective way for early detection of many common diseases. Meanwhile, automated vessel segmentation and vascular tree analysis are still lacking in terms of generalization capability. In this work, we construct a novel benchmark RETA with 81 labeled vessel masks aiming to facilitate retinal vessel analysis. A semi-automated coarse-to-fine workflow is proposed to annotating vessel pixels. During dataset construction, we strived to control inter-annotator variability and intra-annotator variability by performing multi-stage annotation and label disambiguation on self-developed dedicated software. In addition to binary vessel masks, we obtained vessel annotations containing artery/vein masks, vascular skeletons, bifurcations, trees and abnormalities during vessel labelling. Both subjective and objective quality validation of labeled vessel masks have demonstrated significant improved quality over other publicly datasets. The annotation software is also made publicly available for vessel annotation visualization. Users could develop vessel segmentation algorithms or evaluate vessel segmentation performance with our dataset. Moreover, our dataset might be a good research source for cross-modality tubular structure segmentation.
Action2video: Generating Videos of Human 3D Actions
Nov 12, 2021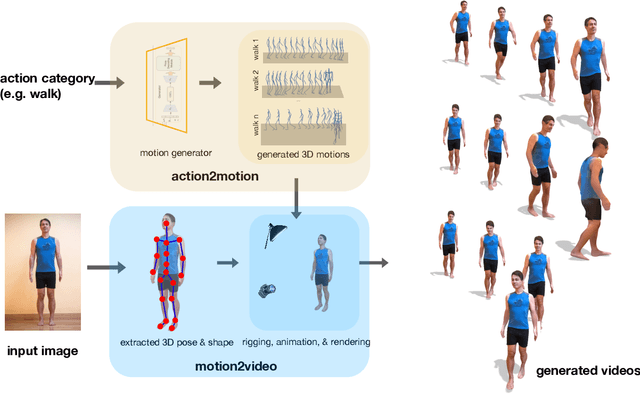
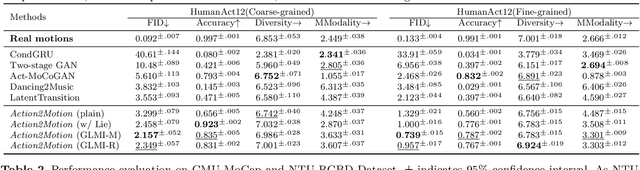
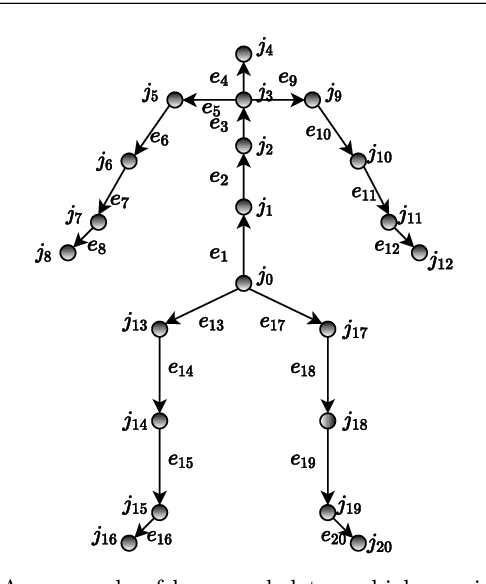
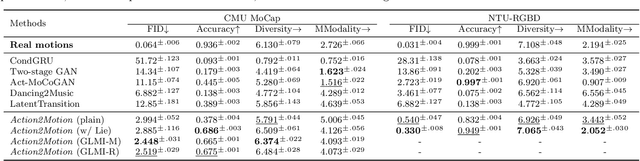
We aim to tackle the interesting yet challenging problem of generating videos of diverse and natural human motions from prescribed action categories. The key issue lies in the ability to synthesize multiple distinct motion sequences that are realistic in their visual appearances. It is achieved in this paper by a two-step process that maintains internal 3D pose and shape representations, action2motion and motion2video. Action2motion stochastically generates plausible 3D pose sequences of a prescribed action category, which are processed and rendered by motion2video to form 2D videos. Specifically, the Lie algebraic theory is engaged in representing natural human motions following the physical law of human kinematics; a temporal variational auto-encoder (VAE) is developed that encourages diversity of output motions. Moreover, given an additional input image of a clothed human character, an entire pipeline is proposed to extract his/her 3D detailed shape, and to render in videos the plausible motions from different views. This is realized by improving existing methods to extract 3D human shapes and textures from single 2D images, rigging, animating, and rendering to form 2D videos of human motions. It also necessitates the curation and reannotation of 3D human motion datasets for training purpose. Thorough empirical experiments including ablation study, qualitative and quantitative evaluations manifest the applicability of our approach, and demonstrate its competitiveness in addressing related tasks, where components of our approach are compared favorably to the state-of-the-arts.
Automated Generation of Accurate \& Fluent Medical X-ray Reports
Aug 27, 2021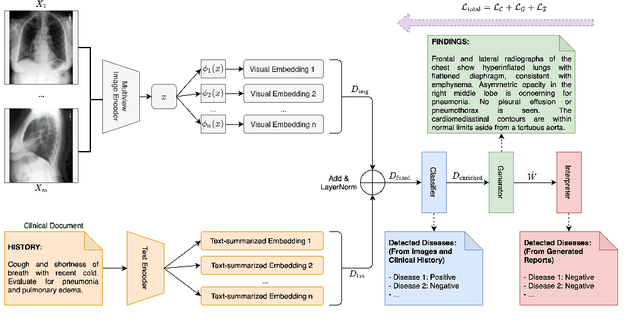
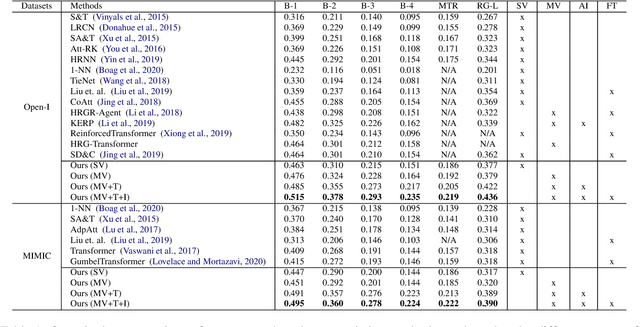
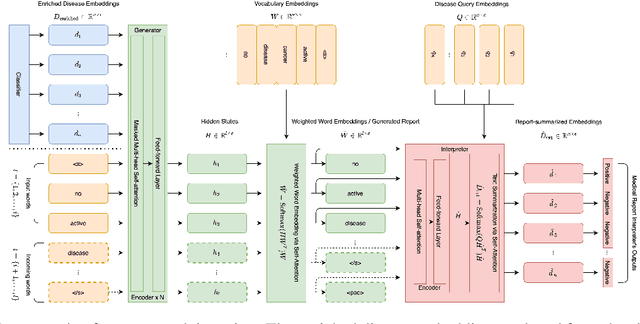
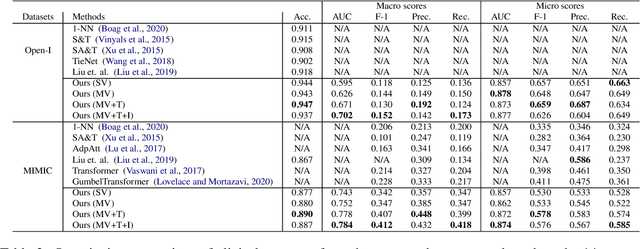
Our paper focuses on automating the generation of medical reports from chest X-ray image inputs, a critical yet time-consuming task for radiologists. Unlike existing medical re-port generation efforts that tend to produce human-readable reports, we aim to generate medical reports that are both fluent and clinically accurate. This is achieved by our fully differentiable and end-to-end paradigm containing three complementary modules: taking the chest X-ray images and clinical his-tory document of patients as inputs, our classification module produces an internal check-list of disease-related topics, referred to as enriched disease embedding; the embedding representation is then passed to our transformer-based generator, giving rise to the medical reports; meanwhile, our generator also pro-duces the weighted embedding representation, which is fed to our interpreter to ensure consistency with respect to disease-related topics.Our approach achieved promising results on commonly-used metrics concerning language fluency and clinical accuracy. Moreover, noticeable performance gains are consistently ob-served when additional input information is available, such as the clinical document and extra scans of different views.
Human Pose and Shape Estimation from Single Polarization Images
Aug 15, 2021



This paper focuses on a new problem of estimating human pose and shape from single polarization images. Polarization camera is known to be able to capture the polarization of reflected lights that preserves rich geometric cues of an object surface. Inspired by the recent applications in surface normal reconstruction from polarization images, in this paper, we attempt to estimate human pose and shape from single polarization images by leveraging the polarization-induced geometric cues. A dedicated two-stage pipeline is proposed: given a single polarization image, stage one (Polar2Normal) focuses on the fine detailed human body surface normal estimation; stage two (Polar2Shape) then reconstructs clothed human shape from the polarization image and the estimated surface normal. To empirically validate our approach, a dedicated dataset (PHSPD) is constructed, consisting of over 500K frames with accurate pose and shape annotations. Empirical evaluations on this real-world dataset as well as a synthetic dataset, SURREAL, demonstrate the effectiveness of our approach. It suggests polarization camera as a promising alternative to the more conventional RGB camera for human pose and shape estimation.
EventHPE: Event-based 3D Human Pose and Shape Estimation
Aug 15, 2021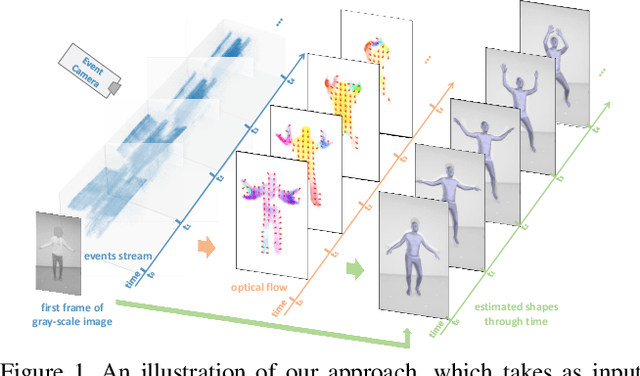

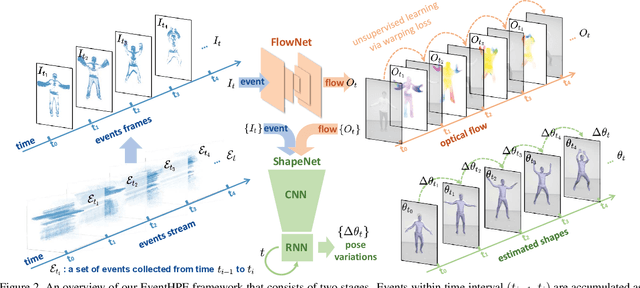
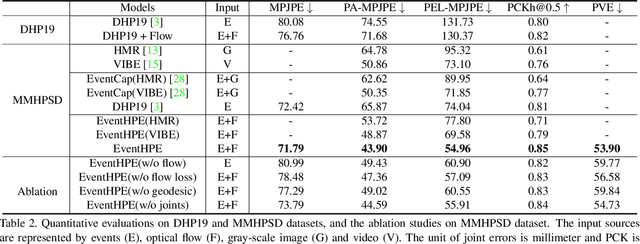
Event camera is an emerging imaging sensor for capturing dynamics of moving objects as events, which motivates our work in estimating 3D human pose and shape from the event signals. Events, on the other hand, have their unique challenges: rather than capturing static body postures, the event signals are best at capturing local motions. This leads us to propose a two-stage deep learning approach, called EventHPE. The first-stage, FlowNet, is trained by unsupervised learning to infer optical flow from events. Both events and optical flow are closely related to human body dynamics, which are fed as input to the ShapeNet in the second stage, to estimate 3D human shapes. To mitigate the discrepancy between image-based flow (optical flow) and shape-based flow (vertices movement of human body shape), a novel flow coherence loss is introduced by exploiting the fact that both flows are originated from the identical human motion. An in-house event-based 3D human dataset is curated that comes with 3D pose and shape annotations, which is by far the largest one to our knowledge. Empirical evaluations on DHP19 dataset and our in-house dataset demonstrate the effectiveness of our approach.
Object Wake-up: 3-D Object Reconstruction, Animation, and in-situ Rendering from a Single Image
Aug 05, 2021

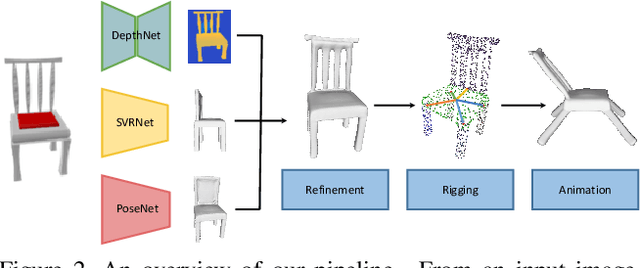
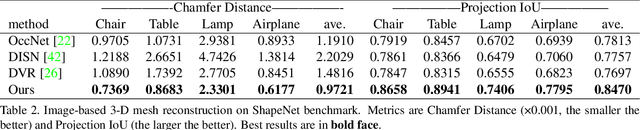
Given a picture of a chair, could we extract the 3-D shape of the chair, animate its plausible articulations and motions, and render in-situ in its original image space? The above question prompts us to devise an automated approach to extract and manipulate articulated objects in single images. Comparing with previous efforts on object manipulation, our work goes beyond 2-D manipulation and focuses on articulable objects, thus introduces greater flexibility for possible object deformations. The pipeline of our approach starts by reconstructing and refining a 3-D mesh representation of the object of interest from an input image; its control joints are predicted by exploiting the semantic part segmentation information; the obtained object 3-D mesh is then rigged \& animated by non-rigid deformation, and rendered to perform in-situ motions in its original image space. Quantitative evaluations are carried out on 3-D reconstruction from single images, an established task that is related to our pipeline, where our results surpass those of the SOTAs by a noticeable margin. Extensive visual results also demonstrate the applicability of our approach.
Unsupervised 3D Human Mesh Recovery from Noisy Point Clouds
Jul 15, 2021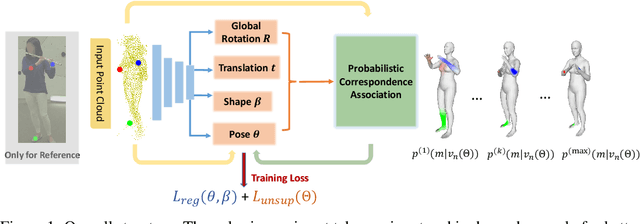
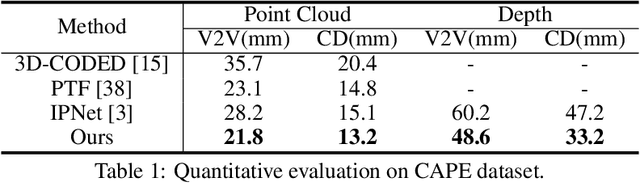
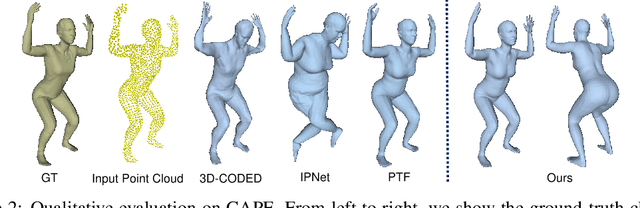
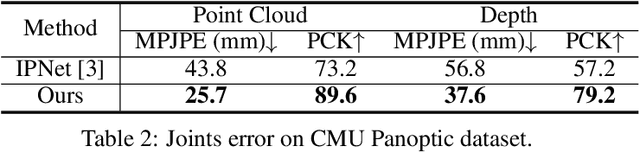
This paper presents a novel unsupervised approach to reconstruct human shape and pose from noisy point cloud. Traditional approaches search for correspondences and conduct model fitting iteratively where a good initialization is critical. Relying on large amount of dataset with ground-truth annotations, recent learning-based approaches predict correspondences for every vertice on the point cloud; Chamfer distance is usually used to minimize the distance between a deformed template model and the input point cloud. However, Chamfer distance is quite sensitive to noise and outliers, thus could be unreliable to assign correspondences. To address these issues, we model the probability distribution of the input point cloud as generated from a parametric human model under a Gaussian Mixture Model. Instead of explicitly aligning correspondences, we treat the process of correspondence search as an implicit probabilistic association by updating the posterior probability of the template model given the input. A novel unsupervised loss is further derived that penalizes the discrepancy between the deformed template and the input point cloud conditioned on the posterior probability. Our approach is very flexible, which works with both complete point cloud and incomplete ones including even a single depth image as input. Our network is trained from scratch with no need to warm-up the network with supervised data. Compared to previous unsupervised methods, our method shows the capability to deal with substantial noise and outliers. Extensive experiments conducted on various public synthetic datasets as well as a very noisy real dataset (i.e. CMU Panoptic) demonstrate the superior performance of our approach over the state-of-the-art methods. Code can be found \url{https://github.com/wangsen1312/unsupervised3dhuman.git}
CHASE: Robust Visual Tracking via Cell-Level Differentiable Neural Architecture Search
Jul 02, 2021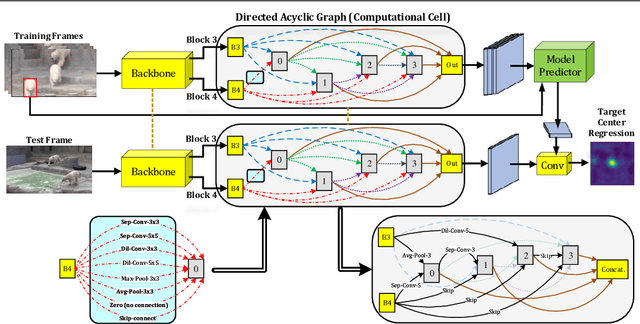

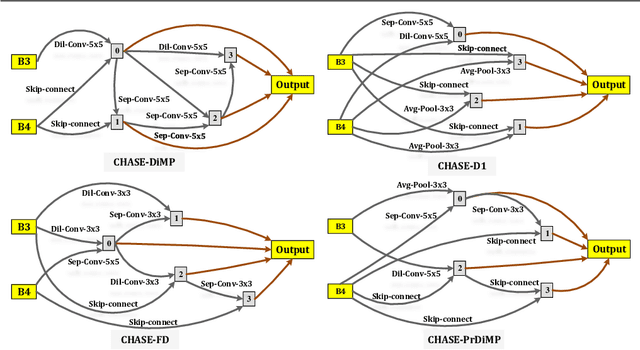
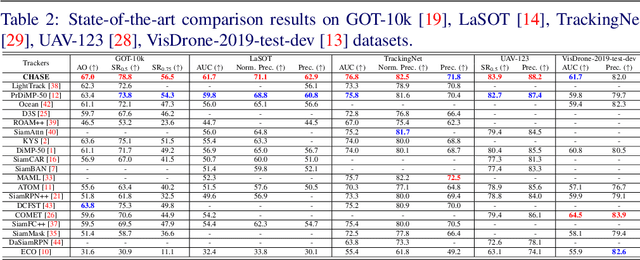
A strong visual object tracker nowadays relies on its well-crafted modules, which typically consist of manually-designed network architectures to deliver high-quality tracking results. Not surprisingly, the manual design process becomes a particularly challenging barrier, as it demands sufficient prior experience, enormous effort, intuition and perhaps some good luck. Meanwhile, neural architecture search has gaining grounds in practical applications such as image segmentation, as a promising method in tackling the issue of automated search of feasible network structures. In this work, we propose a novel cell-level differentiable architecture search mechanism to automate the network design of the tracking module, aiming to adapt backbone features to the objective of a tracking network during offline training. The proposed approach is simple, efficient, and with no need to stack a series of modules to construct a network. Our approach is easy to be incorporated into existing trackers, which is empirically validated using different differentiable architecture search-based methods and tracking objectives. Extensive experimental evaluations demonstrate the superior performance of our approach over five commonly-used benchmarks. Meanwhile, our automated searching process takes 41 (18) hours for the second (first) order DARTS method on the TrackingNet dataset.
Reconstruct high-resolution multi-focal plane images from a single 2D wide field image
Sep 21, 2020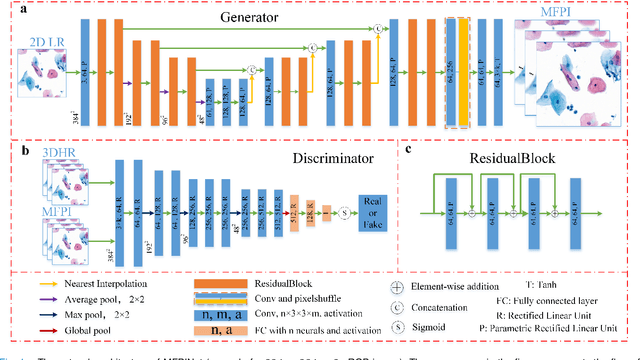
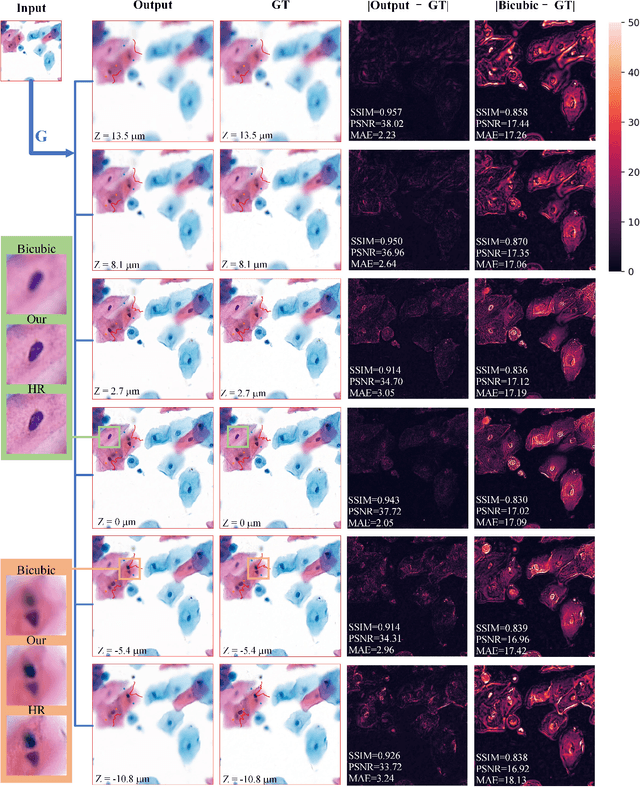
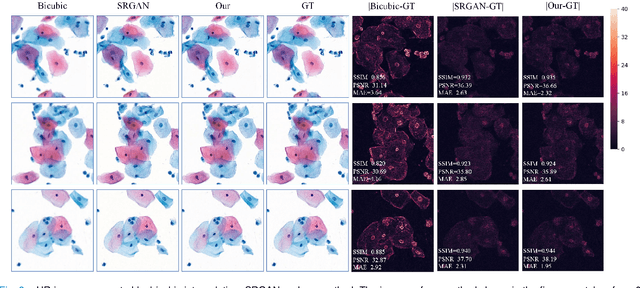

High-resolution 3D medical images are important for analysis and diagnosis, but axial scanning to acquire them is very time-consuming. In this paper, we propose a fast end-to-end multi-focal plane imaging network (MFPINet) to reconstruct high-resolution multi-focal plane images from a single 2D low-resolution wild filed image without relying on scanning. To acquire realistic MFP images fast, the proposed MFPINet adopts generative adversarial network framework and the strategies of post-sampling and refocusing all focal planes at one time. We conduct a series experiments on cytology microscopy images and demonstrate that MFPINet performs well on both axial refocusing and horizontal super resolution. Furthermore, MFPINet is approximately 24 times faster than current refocusing methods for reconstructing the same volume images. The proposed method has the potential to greatly increase the speed of high-resolution 3D imaging and expand the application of low-resolution wide-field images.