 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeaching Diffusion to Speculate Left-to-Right
Jun 10, 2026Large language models (LLMs) achieve remarkable performance across a wide range of tasks, but their autoregressive decoding process incurs substantial inference costs due to inherently sequential token generation. Speculative decoding addresses this bottleneck by employing a lightweight draft model to propose multiple future tokens that are subsequently verified in parallel by a larger target model. Recent work has demonstrated that diffusion language models are well suited for this setting, as they can generate entire blocks of draft tokens in parallel and thereby alleviate the sequential constraints of autoregressive drafting. A subtlety of this regime is that block-diffusion drafters generate tokens bidirectionally within a block, whereas verification is performed by an autoregressive target model that evaluates tokens in a strictly left-to-right manner, leaving a gap between the symmetric training-time objective and the asymmetric verification-time reward. In this work, we offer an empirical analysis of three training-time interventions that narrow this gap: token positional weighting, a first-error focal loss that targets the position that breaks the accepted prefix within each block, and a chain loss term that substitutes a differentiable surrogate for the expected accepted length. The three interventions act along orthogonal axes (position, block-conditional first error, joint prefix) and compose additively; they are likewise orthogonal to test-time alignment mechanisms such as multi-draft self-selection, with which they can in principle be combined. Across four target models and six reasoning, code, and dialogue benchmarks, the three interventions raise accepted draft length by 21-76% per benchmark over a position-uniform baseline, without adding additional forward passes and without changing the inference pipeline or the rejection-sampling exactness contract.
Efficient-DLM: From Autoregressive to Diffusion Language Models, and Beyond in Speed
Dec 16, 2025



Diffusion language models (dLMs) have emerged as a promising paradigm that enables parallel, non-autoregressive generation, but their learning efficiency lags behind that of autoregressive (AR) language models when trained from scratch. To this end, we study AR-to-dLM conversion to transform pretrained AR models into efficient dLMs that excel in speed while preserving AR models' task accuracy. We achieve this by identifying limitations in the attention patterns and objectives of existing AR-to-dLM methods and then proposing principles and methodologies for more effective AR-to-dLM conversion. Specifically, we first systematically compare different attention patterns and find that maintaining pretrained AR weight distributions is critical for effective AR-to-dLM conversion. As such, we introduce a continuous pretraining scheme with a block-wise attention pattern, which remains causal across blocks while enabling bidirectional modeling within each block. We find that this approach can better preserve pretrained AR models' weight distributions than fully bidirectional modeling, in addition to its known benefit of enabling KV caching, and leads to a win-win in accuracy and efficiency. Second, to mitigate the training-test gap in mask token distributions (uniform vs. highly left-to-right), we propose a position-dependent token masking strategy that assigns higher masking probabilities to later tokens during training to better mimic test-time behavior. Leveraging this framework, we conduct extensive studies of dLMs' attention patterns, training dynamics, and other design choices, providing actionable insights into scalable AR-to-dLM conversion. These studies lead to the Efficient-DLM family, which outperforms state-of-the-art AR models and dLMs, e.g., our Efficient-DLM 8B achieves +5.4%/+2.7% higher accuracy with 4.5x/2.7x higher throughput compared to Dream 7B and Qwen3 4B, respectively.
Early-Bird Diffusion: Investigating and Leveraging Timestep-Aware Early-Bird Tickets in Diffusion Models for Efficient Training
Apr 13, 2025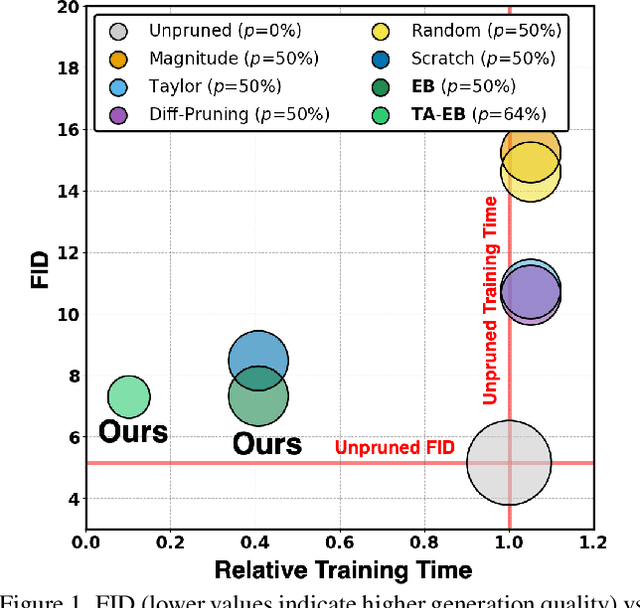
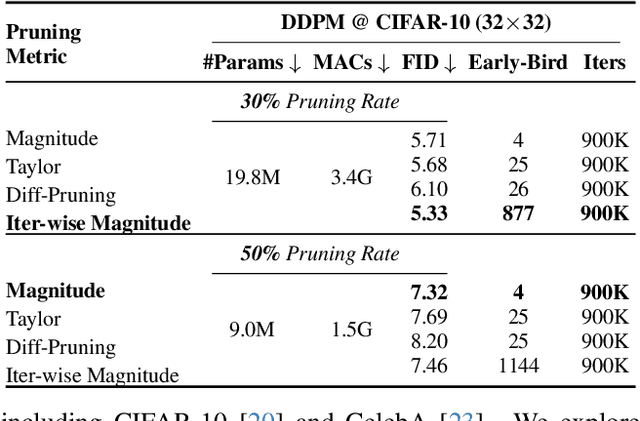
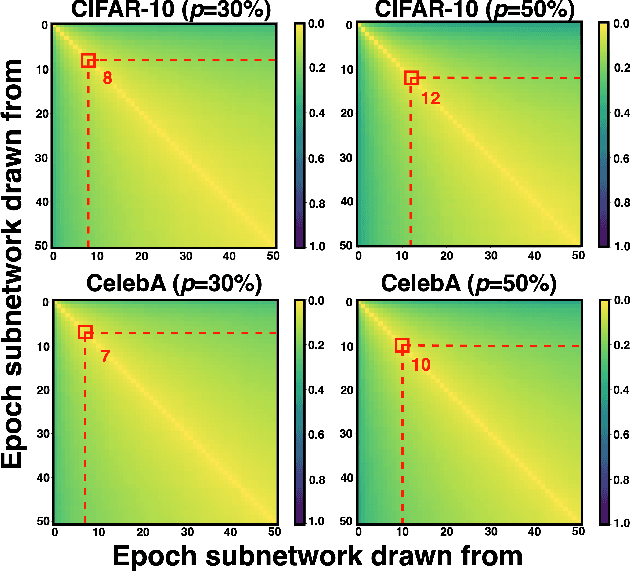
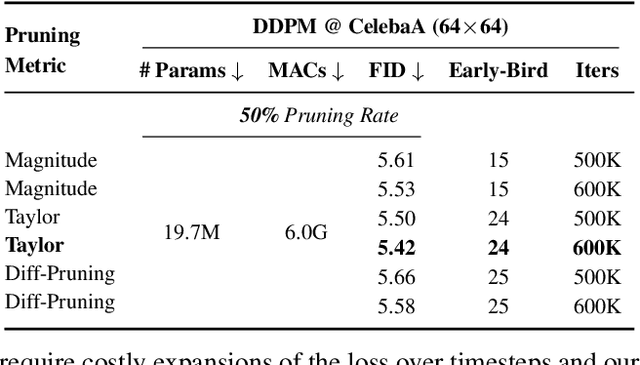
Training diffusion models (DMs) requires substantial computational resources due to multiple forward and backward passes across numerous timesteps, motivating research into efficient training techniques. In this paper, we propose EB-Diff-Train, a new efficient DM training approach that is orthogonal to other methods of accelerating DM training, by investigating and leveraging Early-Bird (EB) tickets -- sparse subnetworks that manifest early in the training process and maintain high generation quality. We first investigate the existence of traditional EB tickets in DMs, enabling competitive generation quality without fully training a dense model. Then, we delve into the concept of diffusion-dedicated EB tickets, drawing on insights from varying importance of different timestep regions. These tickets adapt their sparsity levels according to the importance of corresponding timestep regions, allowing for aggressive sparsity during non-critical regions while conserving computational resources for crucial timestep regions. Building on this, we develop an efficient DM training technique that derives timestep-aware EB tickets, trains them in parallel, and combines them during inference for image generation. Extensive experiments validate the existence of both traditional and timestep-aware EB tickets, as well as the effectiveness of our proposed EB-Diff-Train method. This approach can significantly reduce training time both spatially and temporally -- achieving 2.9$\times$ to 5.8$\times$ speedups over training unpruned dense models, and up to 10.3$\times$ faster training compared to standard train-prune-finetune pipelines -- without compromising generative quality. Our code is available at https://github.com/GATECH-EIC/Early-Bird-Diffusion.