 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse and Local Networks for Hypergraph Reasoning
Mar 09, 2023



Reasoning about the relationships between entities from input facts (e.g., whether Ari is a grandparent of Charlie) generally requires explicit consideration of other entities that are not mentioned in the query (e.g., the parents of Charlie). In this paper, we present an approach for learning to solve problems of this kind in large, real-world domains, using sparse and local hypergraph neural networks (SpaLoc). SpaLoc is motivated by two observations from traditional logic-based reasoning: relational inferences usually apply locally (i.e., involve only a small number of individuals), and relations are usually sparse (i.e., only hold for a small percentage of tuples in a domain). We exploit these properties to make learning and inference efficient in very large domains by (1) using a sparse tensor representation for hypergraph neural networks, (2) applying a sparsification loss during training to encourage sparse representations, and (3) subsampling based on a novel information sufficiency-based sampling process during training. SpaLoc achieves state-of-the-art performance on several real-world, large-scale knowledge graph reasoning benchmarks, and is the first framework for applying hypergraph neural networks on real-world knowledge graphs with more than 10k nodes.
On the Expressiveness and Generalization of Hypergraph Neural Networks
Mar 09, 2023This extended abstract describes a framework for analyzing the expressiveness, learning, and (structural) generalization of hypergraph neural networks (HyperGNNs). Specifically, we focus on how HyperGNNs can learn from finite datasets and generalize structurally to graph reasoning problems of arbitrary input sizes. Our first contribution is a fine-grained analysis of the expressiveness of HyperGNNs, that is, the set of functions that they can realize. Our result is a hierarchy of problems they can solve, defined in terms of various hyperparameters such as depths and edge arities. Next, we analyze the learning properties of these neural networks, especially focusing on how they can be trained on a finite set of small graphs and generalize to larger graphs, which we term structural generalization. Our theoretical results are further supported by the empirical results.
Learning Rational Subgoals from Demonstrations and Instructions
Mar 09, 2023We present a framework for learning useful subgoals that support efficient long-term planning to achieve novel goals. At the core of our framework is a collection of rational subgoals (RSGs), which are essentially binary classifiers over the environmental states. RSGs can be learned from weakly-annotated data, in the form of unsegmented demonstration trajectories, paired with abstract task descriptions, which are composed of terms initially unknown to the agent (e.g., collect-wood then craft-boat then go-across-river). Our framework also discovers dependencies between RSGs, e.g., the task collect-wood is a helpful subgoal for the task craft-boat. Given a goal description, the learned subgoals and the derived dependencies facilitate off-the-shelf planning algorithms, such as A* and RRT, by setting helpful subgoals as waypoints to the planner, which significantly improves performance-time efficiency.
Visibility-Aware Navigation Among Movable Obstacles
Dec 06, 2022In this paper, we examine the problem of visibility-aware robot navigation among movable obstacles (VANAMO). A variant of the well-known NAMO robotic planning problem, VANAMO puts additional visibility constraints on robot motion and object movability. This new problem formulation lifts the restrictive assumption that the map is fully visible and the object positions are fully known. We provide a formal definition of the VANAMO problem and propose the Look and Manipulate Backchaining (LaMB) algorithm for solving such problems. LaMB has a simple vision-based API that makes it more easily transferable to real-world robot applications and scales to the large 3D environments. To evaluate LaMB, we construct a set of tasks that illustrate the complex interplay between visibility and object movability that can arise in mobile base manipulation problems in unknown environments. We show that LaMB outperforms NAMO and visibility-aware motion planning approaches as well as simple combinations of them on complex manipulation problems with partial observability.
SE(3)-Equivariant Relational Rearrangement with Neural Descriptor Fields
Nov 17, 2022We present a method for performing tasks involving spatial relations between novel object instances initialized in arbitrary poses directly from point cloud observations. Our framework provides a scalable way for specifying new tasks using only 5-10 demonstrations. Object rearrangement is formalized as the question of finding actions that configure task-relevant parts of the object in a desired alignment. This formalism is implemented in three steps: assigning a consistent local coordinate frame to the task-relevant object parts, determining the location and orientation of this coordinate frame on unseen object instances, and executing an action that brings these frames into the desired alignment. We overcome the key technical challenge of determining task-relevant local coordinate frames from a few demonstrations by developing an optimization method based on Neural Descriptor Fields (NDFs) and a single annotated 3D keypoint. An energy-based learning scheme to model the joint configuration of the objects that satisfies a desired relational task further improves performance. The method is tested on three multi-object rearrangement tasks in simulation and on a real robot. Project website, videos, and code: https://anthonysimeonov.github.io/r-ndf/
Learning Operators with Ignore Effects for Bilevel Planning in Continuous Domains
Aug 16, 2022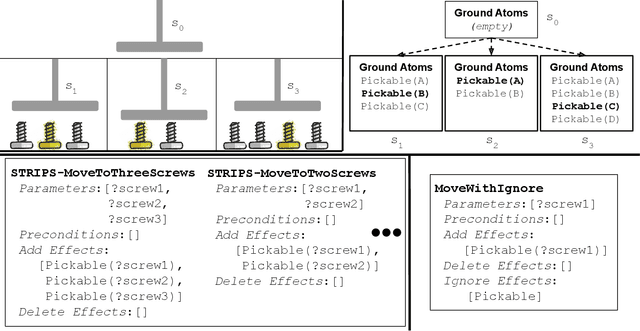
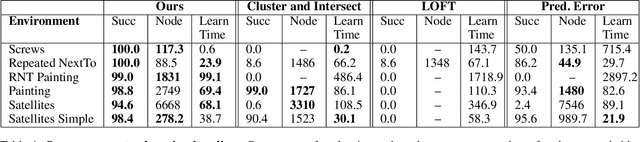
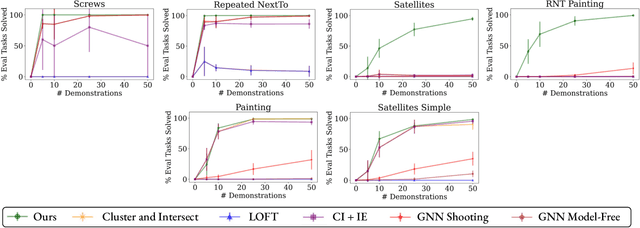
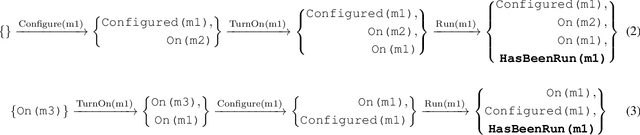
Bilevel planning, in which a high-level search over an abstraction of an environment is used to guide low-level decision making, is an effective approach to solving long-horizon tasks in continuous state and action spaces. Recent work has shown that action abstractions that enable such bilevel planning can be learned in the form of symbolic operators and neural samplers given symbolic predicates and demonstrations that achieve known goals. In this work, we show that existing approaches fall short in environments where actions tend to cause a large number of predicates to change. To address this issue, we propose to learn operators with ignore effects. The key idea motivating our approach is that modeling every observed change in the predicates is unnecessary; the only changes that need be modeled are those that are necessary for high-level search to achieve the specified goal. Experimentally, we show that our approach is able to learn operators with ignore effects across six hybrid robotic domains that enable an agent to solve novel variations of a task, with different initial states, goals, and numbers of objects, significantly more efficiently than several baselines.
Learning Neuro-Symbolic Skills for Bilevel Planning
Jun 21, 2022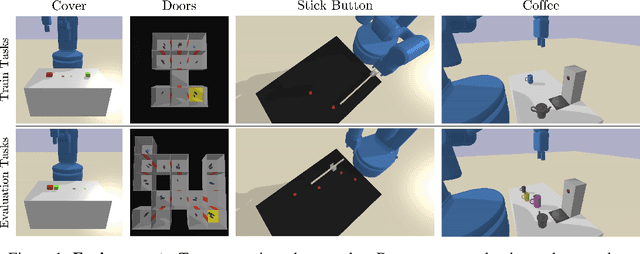

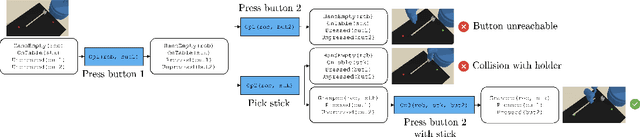
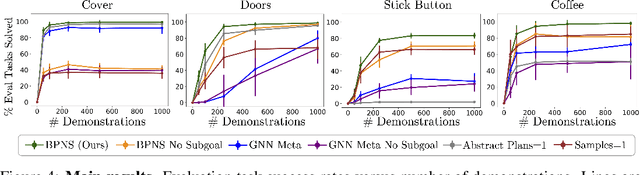
Decision-making is challenging in robotics environments with continuous object-centric states, continuous actions, long horizons, and sparse feedback. Hierarchical approaches, such as task and motion planning (TAMP), address these challenges by decomposing decision-making into two or more levels of abstraction. In a setting where demonstrations and symbolic predicates are given, prior work has shown how to learn symbolic operators and neural samplers for TAMP with manually designed parameterized policies. Our main contribution is a method for learning parameterized polices in combination with operators and samplers. These components are packaged into modular neuro-symbolic skills and sequenced together with search-then-sample TAMP to solve new tasks. In experiments in four robotics domains, we show that our approach -- bilevel planning with neuro-symbolic skills -- can solve a wide range of tasks with varying initial states, goals, and objects, outperforming six baselines and ablations. Video: https://youtu.be/PbFZP8rPuGg Code: https://tinyurl.com/skill-learning
Fully Persistent Spatial Data Structures for Efficient Queries in Path-Dependent Motion Planning Applications
Jun 06, 2022
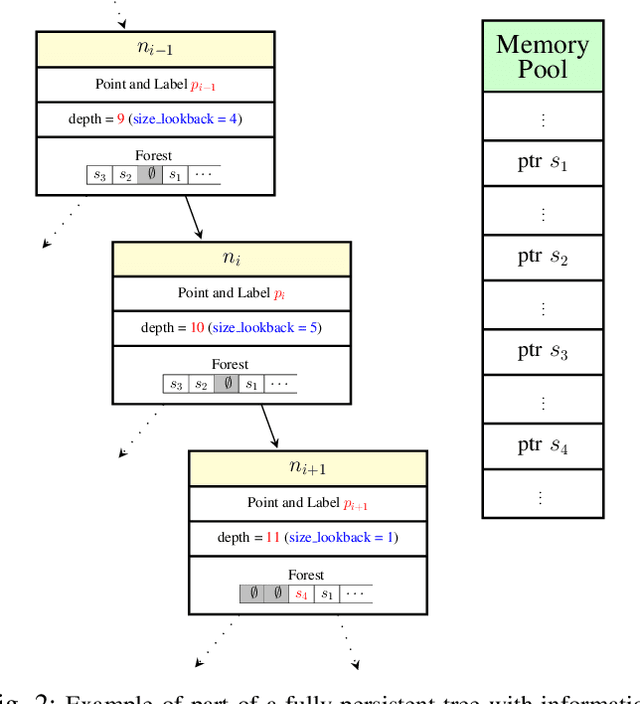
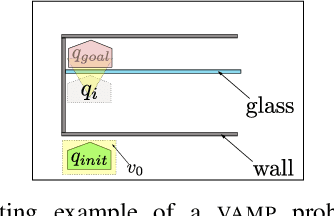

Motion planning is a ubiquitous problem that is often a bottleneck in robotic applications. We demonstrate that motion planning problems such as minimum constraint removal, belief-space planning, and visibility-aware motion planning (VAMP) benefit from a path-dependent formulation, in which the state at a search node is represented implicitly by the path to that node. A naive approach to computing the feasibility of a successor node in such a path-dependent formulation takes time linear in the path length to the node, in contrast to a (possibly very large) constant time for a more typical search formulation. For long-horizon plans, performing this linear-time computation, which we call the lookback, for each node becomes prohibitive. To improve upon this, we introduce the use of a fully persistent spatial data structure (FPSDS), which bounds the size of the lookback. We then focus on the application of the FPSDS in VAMP, which involves incremental geometric computations that can be accelerated by filtering configurations with bounding volumes using nearest-neighbor data structures. We demonstrate an asymptotic and practical improvement in the runtime of finding VAMP solutions in several illustrative domains. To the best of our knowledge, this is the first use of a fully persistent data structure for accelerating motion planning.
PG3: Policy-Guided Planning for Generalized Policy Generation
Apr 21, 2022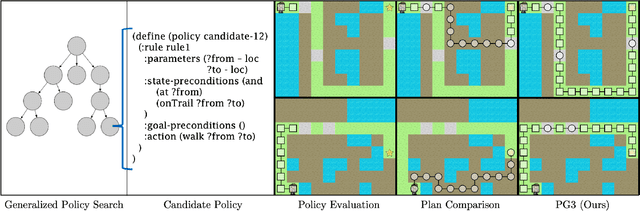



A longstanding objective in classical planning is to synthesize policies that generalize across multiple problems from the same domain. In this work, we study generalized policy search-based methods with a focus on the score function used to guide the search over policies. We demonstrate limitations of two score functions and propose a new approach that overcomes these limitations. The main idea behind our approach, Policy-Guided Planning for Generalized Policy Generation (PG3), is that a candidate policy should be used to guide planning on training problems as a mechanism for evaluating that candidate. Theoretical results in a simplified setting give conditions under which PG3 is optimal or admissible. We then study a specific instantiation of policy search where planning problems are PDDL-based and policies are lifted decision lists. Empirical results in six domains confirm that PG3 learns generalized policies more efficiently and effectively than several baselines. Code: https://github.com/ryangpeixu/pg3
Inventing Relational State and Action Abstractions for Effective and Efficient Bilevel Planning
Mar 17, 2022

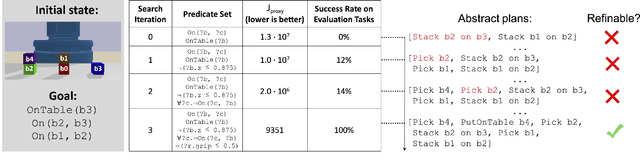

Effective and efficient planning in continuous state and action spaces is fundamentally hard, even when the transition model is deterministic and known. One way to alleviate this challenge is to perform bilevel planning with abstractions, where a high-level search for abstract plans is used to guide planning in the original transition space. In this paper, we develop a novel framework for learning state and action abstractions that are explicitly optimized for both effective (successful) and efficient (fast) bilevel planning. Given demonstrations of tasks in an environment, our data-efficient approach learns relational, neuro-symbolic abstractions that generalize over object identities and numbers. The symbolic components resemble the STRIPS predicates and operators found in AI planning, and the neural components refine the abstractions into actions that can be executed in the environment. Experimentally, we show across four robotic planning environments that our learned abstractions are able to quickly solve held-out tasks of longer horizons than were seen in the demonstrations, and can even outperform the efficiency of abstractions that we manually specified. We also find that as the planner configuration varies, the learned abstractions adapt accordingly, indicating that our abstraction learning method is both "task-aware" and "planner-aware." Code: https://tinyurl.com/predicators-release