 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUKP-SQuARE v2 Explainability and Adversarial Attacks for Trustworthy QA
Aug 23, 2022

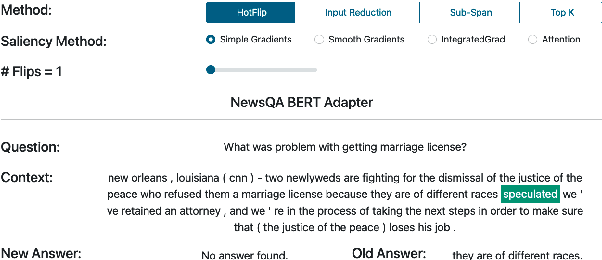

Question Answering (QA) systems are increasingly deployed in applications where they support real-world decisions. However, state-of-the-art models rely on deep neural networks, which are difficult to interpret by humans. Inherently interpretable models or post hoc explainability methods can help users to comprehend how a model arrives at its prediction and, if successful, increase their trust in the system. Furthermore, researchers can leverage these insights to develop new methods that are more accurate and less biased. In this paper, we introduce SQuARE v2, the new version of SQuARE, to provide an explainability infrastructure for comparing models based on methods such as saliency maps and graph-based explanations. While saliency maps are useful to inspect the importance of each input token for the model's prediction, graph-based explanations from external Knowledge Graphs enable the users to verify the reasoning behind the model prediction. In addition, we provide multiple adversarial attacks to compare the robustness of QA models. With these explainability methods and adversarial attacks, we aim to ease the research on trustworthy QA models. SQuARE is available on https://square.ukp-lab.de.
GEMv2: Multilingual NLG Benchmarking in a Single Line of Code
Jun 24, 2022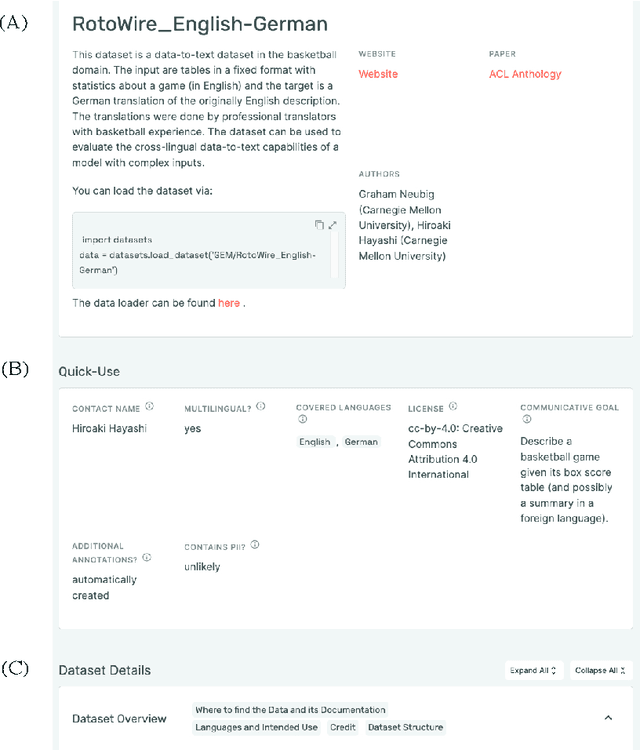


Evaluation in machine learning is usually informed by past choices, for example which datasets or metrics to use. This standardization enables the comparison on equal footing using leaderboards, but the evaluation choices become sub-optimal as better alternatives arise. This problem is especially pertinent in natural language generation which requires ever-improving suites of datasets, metrics, and human evaluation to make definitive claims. To make following best model evaluation practices easier, we introduce GEMv2. The new version of the Generation, Evaluation, and Metrics Benchmark introduces a modular infrastructure for dataset, model, and metric developers to benefit from each others work. GEMv2 supports 40 documented datasets in 51 languages. Models for all datasets can be evaluated online and our interactive data card creation and rendering tools make it easier to add new datasets to the living benchmark.
FactGraph: Evaluating Factuality in Summarization with Semantic Graph Representations
Apr 13, 2022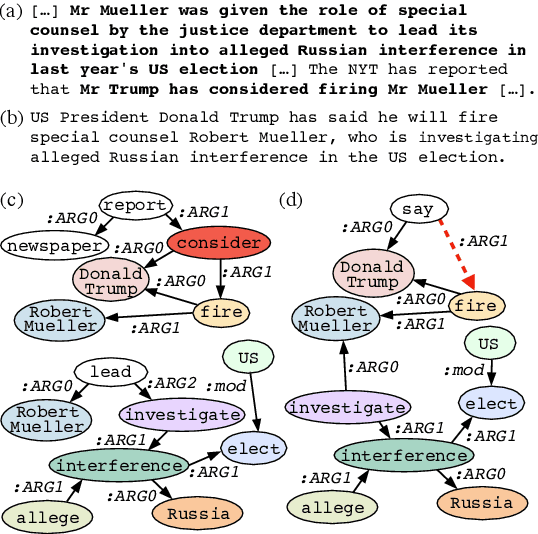
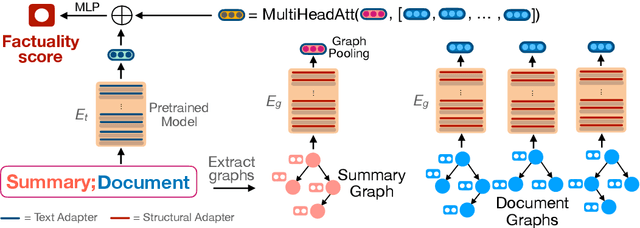

Despite recent improvements in abstractive summarization, most current approaches generate summaries that are not factually consistent with the source document, severely restricting their trust and usage in real-world applications. Recent works have shown promising improvements in factuality error identification using text or dependency arc entailments; however, they do not consider the entire semantic graph simultaneously. To this end, we propose FactGraph, a method that decomposes the document and the summary into structured meaning representations (MR), which are more suitable for factuality evaluation. MRs describe core semantic concepts and their relations, aggregating the main content in both document and summary in a canonical form, and reducing data sparsity. FactGraph encodes such graphs using a graph encoder augmented with structure-aware adapters to capture interactions among the concepts based on the graph connectivity, along with text representations using an adapter-based text encoder. Experiments on different benchmarks for evaluating factuality show that FactGraph outperforms previous approaches by up to 15%. Furthermore, FactGraph improves performance on identifying content verifiability errors and better captures subsentence-level factual inconsistencies.
UKP-SQUARE: An Online Platform for Question Answering Research
Mar 28, 2022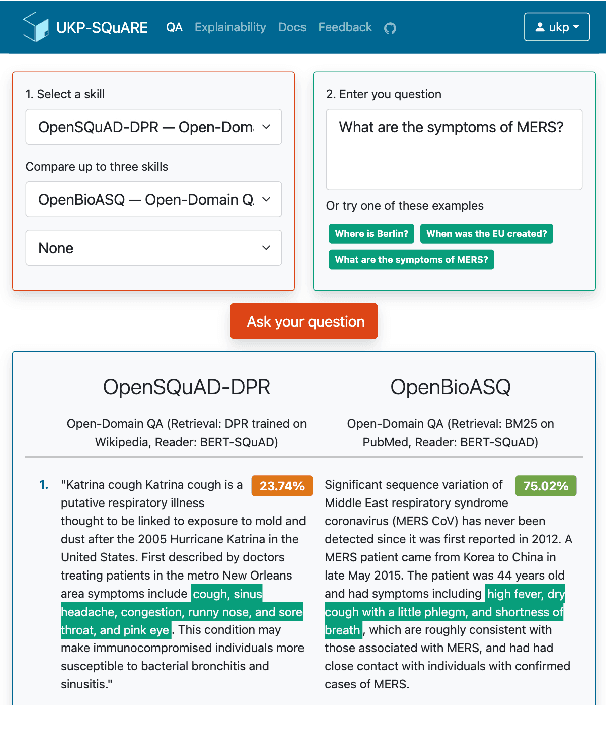

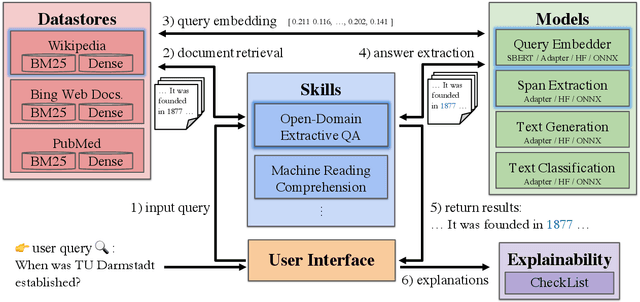
Recent advances in NLP and information retrieval have given rise to a diverse set of question answering tasks that are of different formats (e.g., extractive, abstractive), require different model architectures (e.g., generative, discriminative), and setups (e.g., with or without retrieval). Despite having a large number of powerful, specialized QA pipelines (which we refer to as Skills) that consider a single domain, model or setup, there exists no framework where users can easily explore and compare such pipelines and can extend them according to their needs. To address this issue, we present UKP-SQUARE, an extensible online QA platform for researchers which allows users to query and analyze a large collection of modern Skills via a user-friendly web interface and integrated behavioural tests. In addition, QA researchers can develop, manage, and share their custom Skills using our microservices that support a wide range of models (Transformers, Adapters, ONNX), datastores and retrieval techniques (e.g., sparse and dense). UKP-SQUARE is available on https://square.ukp-lab.de.
Smelting Gold and Silver for Improved Multilingual AMR-to-Text Generation
Sep 08, 2021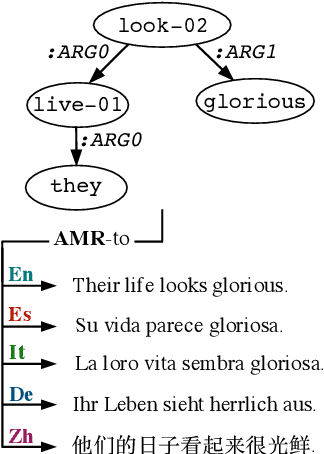
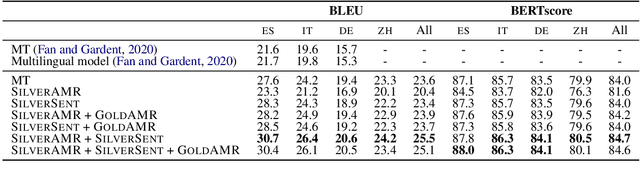
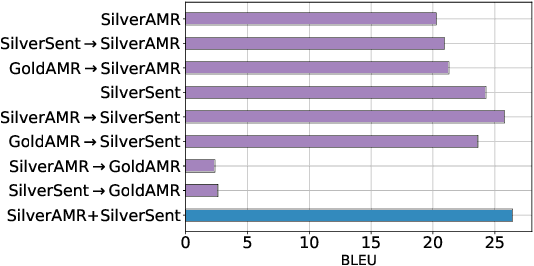

Recent work on multilingual AMR-to-text generation has exclusively focused on data augmentation strategies that utilize silver AMR. However, this assumes a high quality of generated AMRs, potentially limiting the transferability to the target task. In this paper, we investigate different techniques for automatically generating AMR annotations, where we aim to study which source of information yields better multilingual results. Our models trained on gold AMR with silver (machine translated) sentences outperform approaches which leverage generated silver AMR. We find that combining both complementary sources of information further improves multilingual AMR-to-text generation. Our models surpass the previous state of the art for German, Italian, Spanish, and Chinese by a large margin.
Structural Adapters in Pretrained Language Models for AMR-to-text Generation
Mar 16, 2021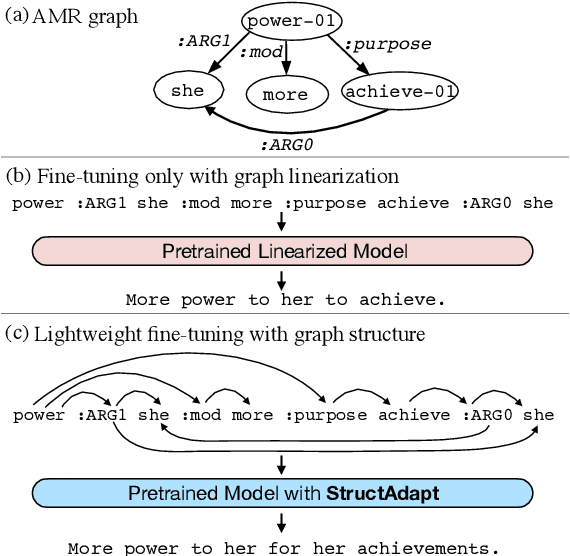
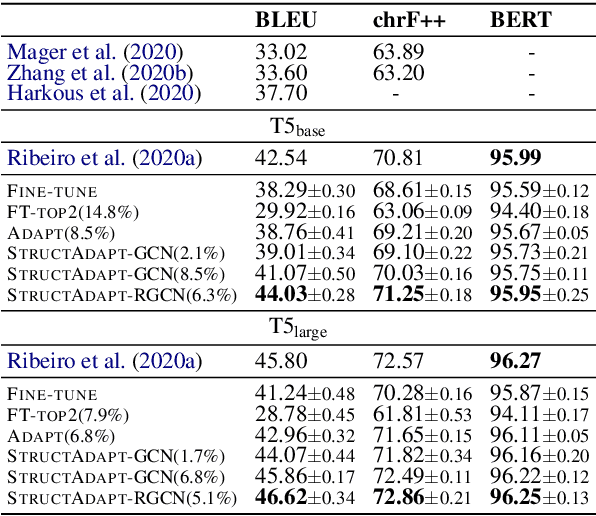
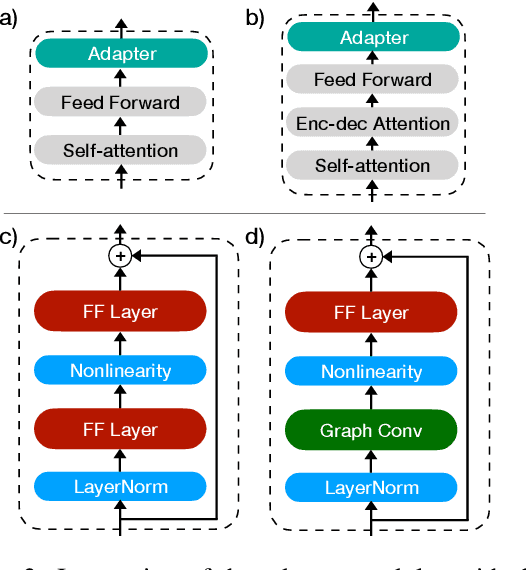
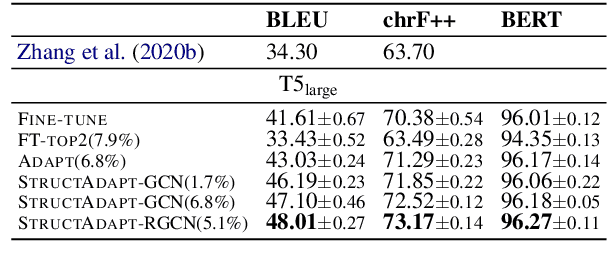
Previous work on text generation from graph-structured data relies on pretrained language models (PLMs) and utilizes graph linearization heuristics rather than explicitly considering the graph structure. Efficiently encoding the graph structure in PLMs is challenging because they were pretrained on natural language, and modeling structured data may lead to catastrophic forgetting of distributional knowledge. In this paper, we propose StructAdapt, an adapter method to encode graph structure into PLMs. Contrary to prior work, StructAdapt effectively models interactions among the nodes based on the graph connectivity, only training graph structure-aware adapter parameters. In this way, we avoid catastrophic forgetting while maintaining the topological structure of the graph. We empirically show the benefits of explicitly encoding graph structure into PLMs using adapters and achieve state-of-the-art results on two AMR-to-text datasets, training only 5.1% of the PLM parameters.
Investigating Pretrained Language Models for Graph-to-Text Generation
Jul 16, 2020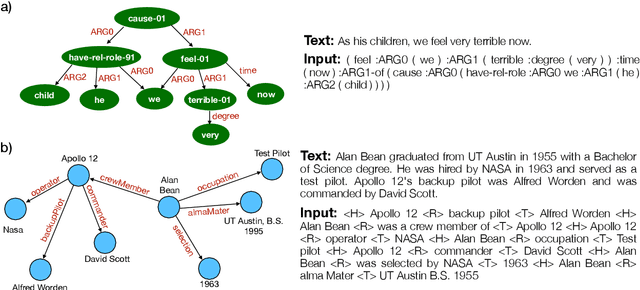
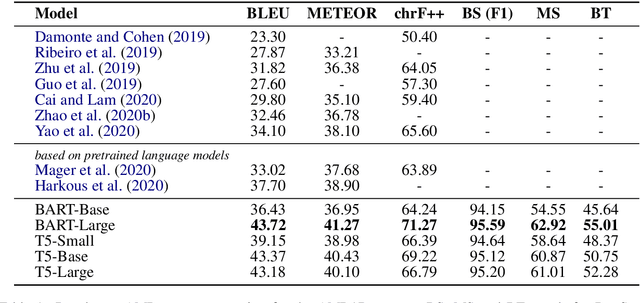
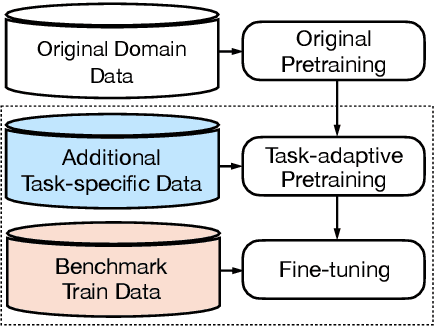
Graph-to-text generation, a subtask of data-to-text generation, aims to generate fluent texts from graph-based data. Many graph-to-text models have shown strong performance in this task employing specialized graph encoders. However, recent approaches employ large pretrained language models (PLMs) achieving state-of-the-art results in data-to-text generation. In this paper, we aim to investigate the impact of large PLMs in graph-to-text generation. We present a study across three graph domains: meaning representations, Wikipedia knowledge graphs (KGs) and scientific KGs. Our analysis shows that PLMs such as BART and T5 achieve state-of-the-art results in graph-to-text benchmarks without explicitly encoding the graph structure. We also demonstrate that task-adaptive pretraining strategies are beneficial to the target task, improving even further the state of the art in two benchmarks for graph-to-text generation. In a final analysis, we investigate possible reasons for the PLMs' success on graph-to-text tasks. We find evidence that their knowledge about the world gives them a big advantage, especially when generating texts from KGs.
Modeling Graph Structure via Relative Position for Better Text Generation from Knowledge Graphs
Jun 16, 2020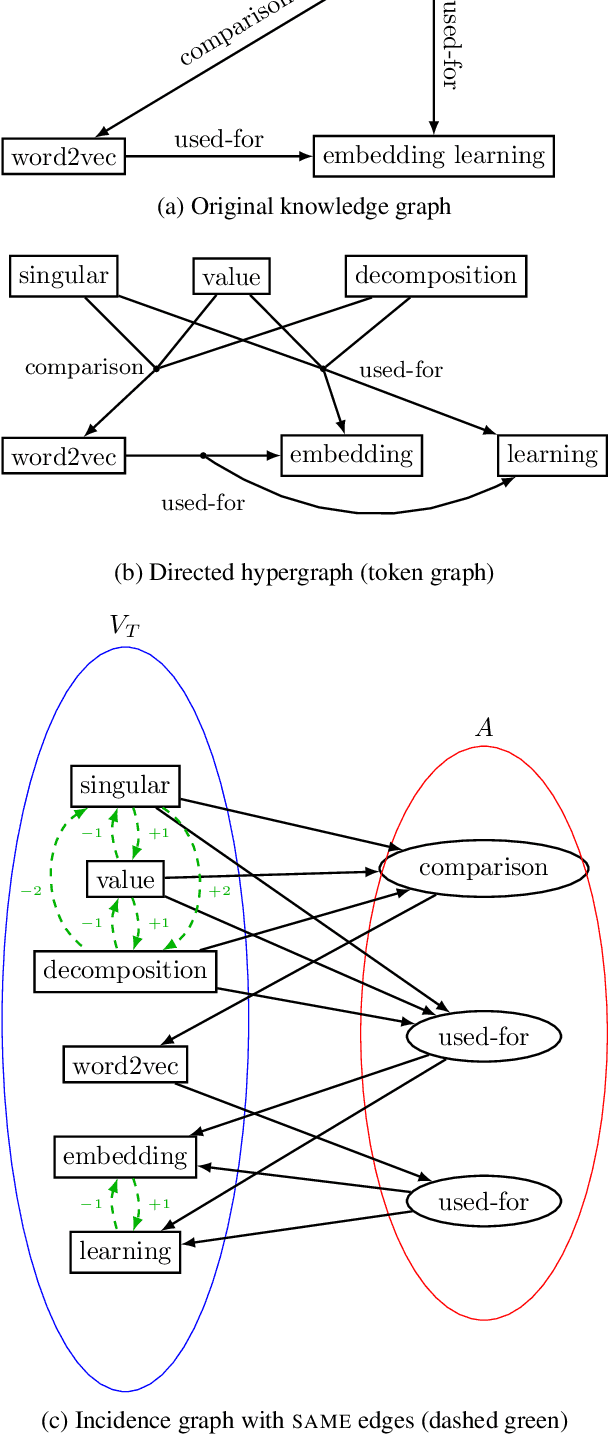
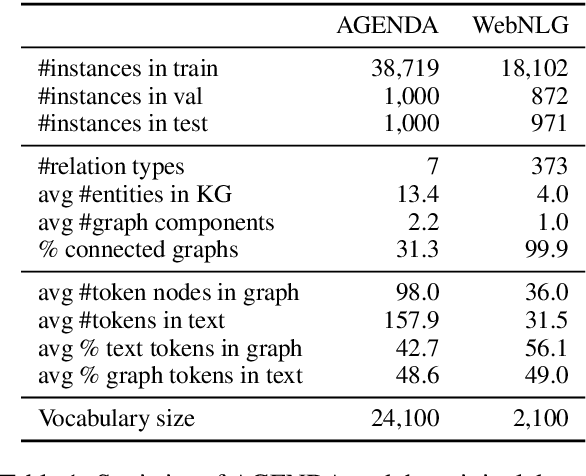
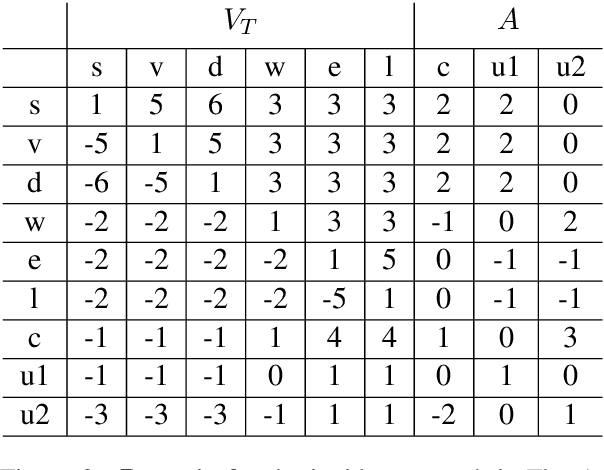
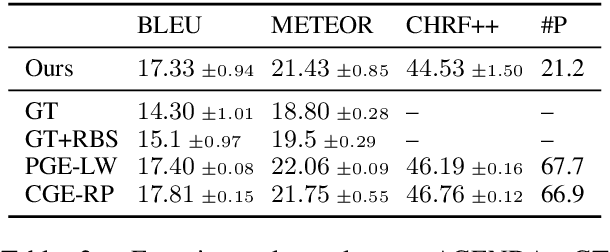
We present a novel encoder-decoder architecture for graph-to-text generation based on Transformer, called the Graformer. With our novel graph self-attention, every node in the input graph is taken into account for the encoding of every other node - not only direct neighbors, facilitating the detection of global patterns. For this, the relation between any two nodes is characterized by the length of the shortest path between them, including the special case when there is no such path. The Graformer learns to weigh these node-node relations differently for different attention heads, thus virtually learning differently connected views of the input graph. We evaluate the Graformer on two graph-to-text generation benchmarks, the AGENDA dataset and the WebNLG challenge dataset, where it achieves strong performance while using significantly less parameters than other approaches.
Common Sense or World Knowledge? Investigating Adapter-Based Knowledge Injection into Pretrained Transformers
May 24, 2020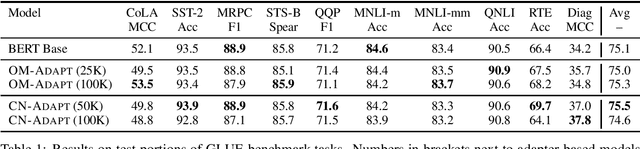
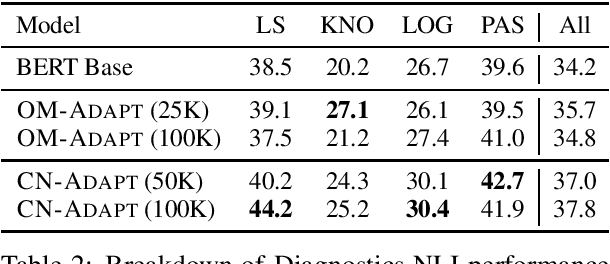
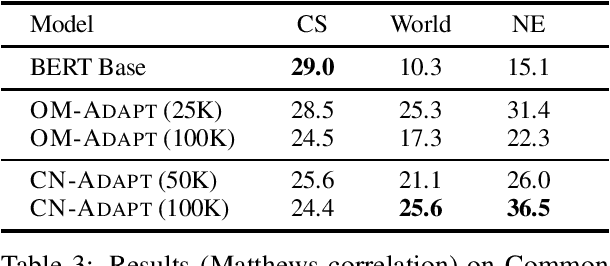
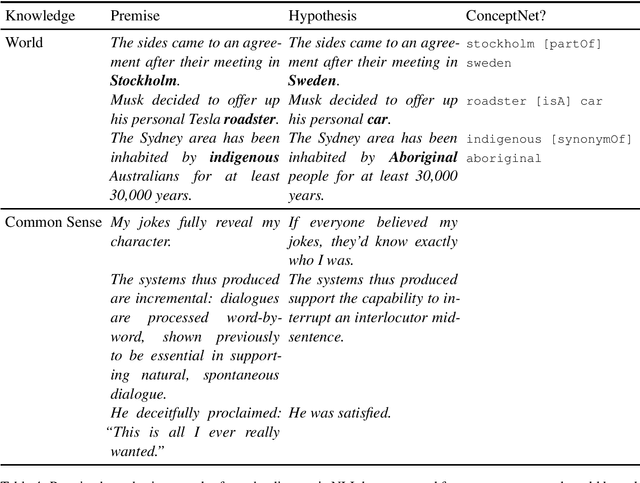
Following the major success of neural language models (LMs) such as BERT or GPT-2 on a variety of language understanding tasks, recent work focused on injecting (structured) knowledge from external resources into these models. While on the one hand, joint pretraining (i.e., training from scratch, adding objectives based on external knowledge to the primary LM objective) may be prohibitively computationally expensive, post-hoc fine-tuning on external knowledge, on the other hand, may lead to the catastrophic forgetting of distributional knowledge. In this work, we investigate models for complementing the distributional knowledge of BERT with conceptual knowledge from ConceptNet and its corresponding Open Mind Common Sense (OMCS) corpus, respectively, using adapter training. While overall results on the GLUE benchmark paint an inconclusive picture, a deeper analysis reveals that our adapter-based models substantially outperform BERT (up to 15-20 performance points) on inference tasks that require the type of conceptual knowledge explicitly present in ConceptNet and OMCS.
Modeling Global and Local Node Contexts for Text Generation from Knowledge Graphs
Jan 29, 2020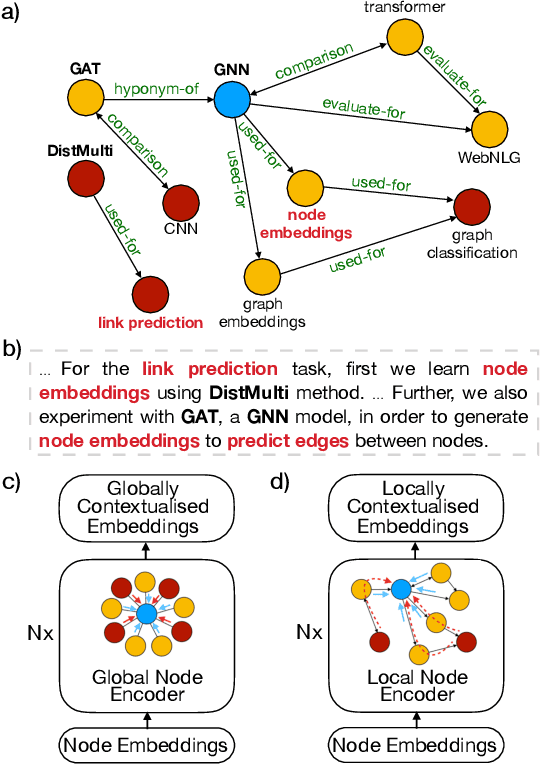


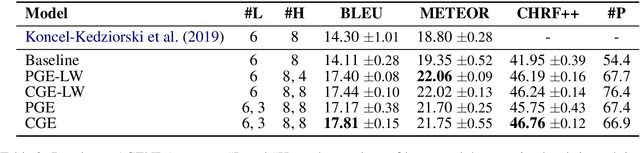
Recent graph-to-text models generate text from graph-based data using either global or local aggregation to learn node representations. Global node encoding allows explicit communication between two distant nodes, thereby neglecting graph topology as all nodes are connected. In contrast, local node encoding considers the relations between directly connected nodes capturing the graph structure, but it can fail to capture long-range relations. In this work, we gather the best of both encoding strategies, proposing novel models that encode an input graph combining both global and local node contexts. Our approaches are able to learn better contextualized node embeddings for text generation. In our experiments, we demonstrate that our models lead to significant improvements in KG-to-text generation, achieving BLEU scores of 17.81 on AGENDA dataset, and 63.10 on the WebNLG dataset for seen categories, outperforming the state of the art by 3.51 and 2.51 points, respectively.