 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph GOSPA metric: a metric to measure the discrepancy between graphs of different sizes
Nov 10, 2023



This paper proposes a metric to measure the dissimilarity between graphs that may have a different number of nodes. The proposed metric extends the generalised optimal subpattern assignment (GOSPA) metric, which is a metric for sets, to graphs. The proposed graph GOSPA metric includes costs associated with node attribute errors for properly assigned nodes, missed and false nodes and edge mismatches between graphs. The computation of this metric is based on finding the optimal assignments between nodes in the two graphs, with the possibility of leaving some of the nodes unassigned. We also propose a lower bound for the metric, which is also a metric for graphs and is computable in polynomial time using linear programming. The metric is first derived for undirected unweighted graphs and it is then extended to directed and weighted graphs. The properties of the metric are demonstrated via simulated and empirical datasets.
You can have your ensemble and run it too -- Deep Ensembles Spread Over Time
Sep 20, 2023Ensembles of independently trained deep neural networks yield uncertainty estimates that rival Bayesian networks in performance. They also offer sizable improvements in terms of predictive performance over single models. However, deep ensembles are not commonly used in environments with limited computational budget -- such as autonomous driving -- since the complexity grows linearly with the number of ensemble members. An important observation that can be made for robotics applications, such as autonomous driving, is that data is typically sequential. For instance, when an object is to be recognized, an autonomous vehicle typically observes a sequence of images, rather than a single image. This raises the question, could the deep ensemble be spread over time? In this work, we propose and analyze Deep Ensembles Spread Over Time (DESOT). The idea is to apply only a single ensemble member to each data point in the sequence, and fuse the predictions over a sequence of data points. We implement and experiment with DESOT for traffic sign classification, where sequences of tracked image patches are to be classified. We find that DESOT obtains the benefits of deep ensembles, in terms of predictive and uncertainty estimation performance, while avoiding the added computational cost. Moreover, DESOT is simple to implement and does not require sequences during training. Finally, we find that DESOT, like deep ensembles, outperform single models for out-of-distribution detection.
Integrated Monostatic and Bistatic mmWave Sensing
Aug 26, 2023



Millimeter-wave (mmWave) signals provide attractive opportunities for sensing due to their inherent geometrical connections to physical propagation channels. Two common modalities used in mmWave sensing are monostatic and bistatic sensing, which are usually considered separately. By integrating these two modalities, information can be shared between them, leading to improved sensing performance. In this paper, we investigate the integration of monostatic and bistatic sensing in a 5G mmWave scenario, implement the extended Kalman-Poisson multi-Bernoulli sequential filters to solve the sensing problems, and propose a method to periodically fuse user states and maps from two sensing modalities.
MCMC-Correction of Score-Based Diffusion Models for Model Composition
Jul 26, 2023


Diffusion models can be parameterised in terms of either a score or an energy function. The energy parameterisation has better theoretical properties, mainly that it enables an extended sampling procedure with a Metropolis--Hastings correction step, based on the change in total energy in the proposed samples. However, it seems to yield slightly worse performance, and more importantly, due to the widespread popularity of score-based diffusion, there are limited availability of off-the-shelf pre-trained energy-based ones. This limitation undermines the purpose of model composition, which aims to combine pre-trained models to sample from new distributions. Our proposal, however, suggests retaining the score parameterization and instead computing the energy-based acceptance probability through line integration of the score function. This allows us to re-use existing diffusion models and still combine the reverse process with various Markov-Chain Monte Carlo (MCMC) methods. We evaluate our method on a 2D experiment and find that it achieve similar or arguably better performance than the energy parameterisation.
Set-Type Belief Propagation with Applications to Mapping, MTT, SLAM, and SLAT
May 05, 2023



Belief propagation (BP) is a useful probabilistic inference algorithm for efficiently computing approximate marginal probability densities of random variables. However, in its standard form, BP is applicable to only the vector-type random variables, while certain applications rely on set-type random variables with an unknown number of vector elements. In this paper, we first develop BP rules for set-type random variables and demonstrate that vector-type BP is a special case of set-type BP. We further propose factor graphs with set-factor and set-variable nodes by devising the set-factor nodes that can address the set-variables with random elements and cardinality, while the number of vector elements in vector-type is known. To demonstrate the validity of developed set-type BP, we apply it to the Poisson multi-Bernoulli (PMB) filter for simultaneous localization and mapping (SLAM), which naturally leads to a new set-type BP-SLAM filter. Finally, we reveal connections between the vector-type BP-SLAM filter and the proposed set-type BP-SLAM filter and show a performance gain of the proposed set-type BP-SLAM filter in comparison with the vector-type BP-SLAM filter.
Experimental Validation of Single BS 5G mmWave Positioning and Mapping for Intelligent Transport
Mar 21, 2023



Positioning with 5G signals generally requires connection to several base stations (BSs), which makes positioning more demanding in terms of infrastructure than communications. To address this issue, there have been several theoretical studies on single BS positioning, leveraging high-resolution angle and delay estimation and multipath exploitation possibilities at mmWave frequencies. This paper presents the first realistic experimental validation of such studies, involving a commercial 5G mmWave BS and a user equipment (UE) development kit mounted on a test vehicle. We present the relevant signal models, signal processing methods (including channel parameter estimation and position estimation), and validate these based on real data collected in an outdoor science park environment. Our results indicate that positioning is possible, but the performance with a single BS is limited by the knowledge of the position and orientation of the infrastructure and the multipath visibility and diversity.
Improving Open-Set Semi-Supervised Learning with Self-Supervision
Jan 24, 2023



Open-set semi-supervised learning (OSSL) is a realistic setting of semi-supervised learning where the unlabeled training set contains classes that are not present in the labeled set. Many existing OSSL methods assume that these out-of-distribution data are harmful and put effort into excluding data from unknown classes from the training objective. In contrast, we propose an OSSL framework that facilitates learning from all unlabeled data through self-supervision. Additionally, we utilize an energy-based score to accurately recognize data belonging to the known classes, making our method well-suited for handling uncurated data in deployment. We show through extensive experimental evaluations on several datasets that our method shows overall unmatched robustness and performance in terms of closed-set accuracy and open-set recognition compared with state-of-the-art for OSSL. Our code will be released upon publication.
LidarCLIP or: How I Learned to Talk to Point Clouds
Dec 13, 2022



Research connecting text and images has recently seen several breakthroughs, with models like CLIP, DALL-E 2, and Stable Diffusion. However, the connection between text and other visual modalities, such as lidar data, has received less attention, prohibited by the lack of text-lidar datasets. In this work, we propose LidarCLIP, a mapping from automotive point clouds to a pre-existing CLIP embedding space. Using image-lidar pairs, we supervise a point cloud encoder with the image CLIP embeddings, effectively relating text and lidar data with the image domain as an intermediary. We show the effectiveness of LidarCLIP by demonstrating that lidar-based retrieval is generally on par with image-based retrieval, but with complementary strengths and weaknesses. By combining image and lidar features, we improve upon both single-modality methods and enable a targeted search for challenging detection scenarios under adverse sensor conditions. We also use LidarCLIP as a tool to investigate fundamental lidar capabilities through natural language. Finally, we leverage our compatibility with CLIP to explore a range of applications, such as point cloud captioning and lidar-to-image generation, without any additional training. We hope LidarCLIP can inspire future work to dive deeper into connections between text and point cloud understanding. Code and trained models available at https://github.com/atonderski/lidarclip.
MmWave Mapping and SLAM for 5G and Beyond
Nov 29, 2022



Device localization and radar-like mapping are at the heart of integrated sensing and communication, enabling not only new services and applications, but can also improve communication quality with reduced overheads. These forms of sensing are however susceptible to data association problems, due to the unknown relation between measurements and detected objects or targets. In this chapter, we provide an overview of the fundamental tools used to solve mapping, tracking, and simultaneous localization and mapping (SLAM) problems. We distinguish the different types of sensing problems and then focus on mapping and SLAM as running examples. Starting from the applicable models and definitions, we describe the different algorithmic approaches, with a particular focus on how to deal with data association problems. In particular, methods based on random finite set theory and Bayesian graphical models are introduced in detail. A numerical study with synthetic and experimental data is then used to compare these approaches in a variety of scenarios.
Deep Fusion of Multi-Object Densities Using Transformer
Sep 23, 2022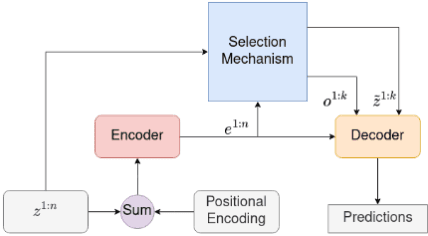

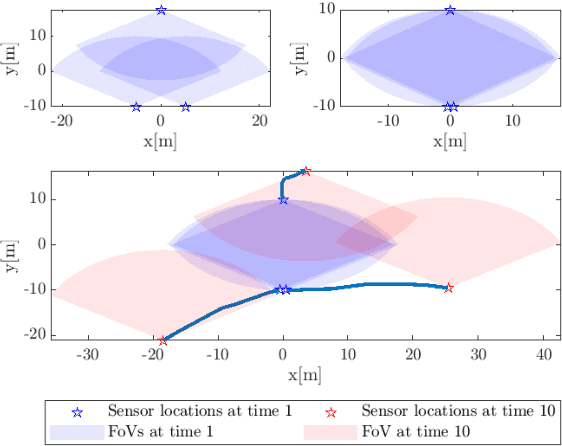
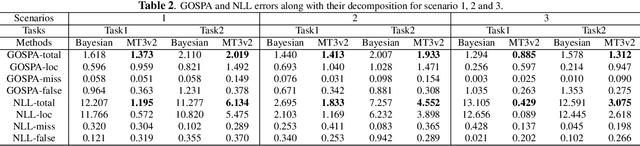
In this paper, we demonstrate that deep learning based method can be used to fuse multi-object densities. Given a scenario with several sensors with possibly different field-of-views, tracking is performed locally in each sensor by a tracker, which produces random finite set multi-object densities. To fuse outputs from different trackers, we adapt a recently proposed transformer-based multi-object tracker, where the fusion result is a global multi-object density, describing the set of all alive objects at the current time. We compare the performance of the transformer-based fusion method with a well-performing model-based Bayesian fusion method in several simulated scenarios with different parameter settings using synthetic data. The simulation results show that the transformer-based fusion method outperforms the model-based Bayesian method in our experimental scenarios.