 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Semantic Localization in Highly Dynamic Wireless Networks Using Deep Homoscedastic Domain Adaptation
Oct 11, 2023



Localization in GPS-denied outdoor locations, such as street canyons in an urban or metropolitan environment, has many applications. Machine Learning (ML) is widely used to tackle this critical problem. One challenge lies in the mixture of line-of-sight (LOS), obstructed LOS (OLOS), and non-LOS (NLOS) conditions. In this paper, we consider a semantic localization that treats these three propagation conditions as the ''semantic objects", and aims to determine them together with the actual localization, and show that this increases accuracy and robustness. Furthermore, the propagation conditions are highly dynamic, since obstruction by cars or trucks can change the channel state information (CSI) at a fixed location over time. We therefore consider the blockage by such dynamic objects as another semantic state. Based on these considerations, we formulate the semantic localization with a joint task (coordinates regression and semantics classification) learning problem. Another problem created by the dynamics is the fact that each location may be characterized by a number of different CSIs. To avoid the need for excessive amount of labeled training data, we propose a multi-task deep domain adaptation (DA) based localization technique, training neural networks with a limited number of labeled samples and numerous unlabeled ones. Besides, we introduce novel scenario adaptive learning strategies to ensure efficient representation learning and successful knowledge transfer. Finally, we use Bayesian theory for uncertainty modeling of the importance weights in each task, reducing the need for time-consuming parameter finetuning; furthermore, with some mild assumptions, we derive the related log-likelihood for the joint task and present the deep homoscedastic DA based localization method.
Multi-level Contrast Network for Wearables-based Joint Activity Segmentation and Recognition
Aug 16, 2022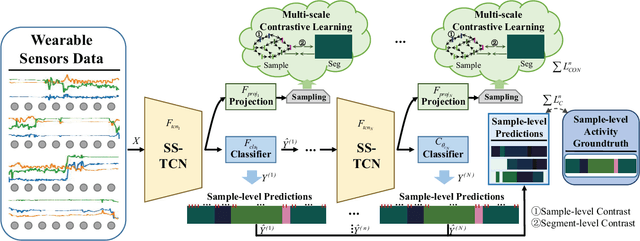
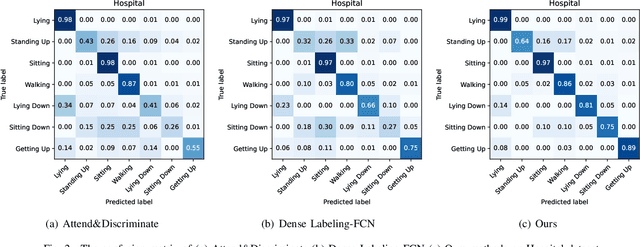
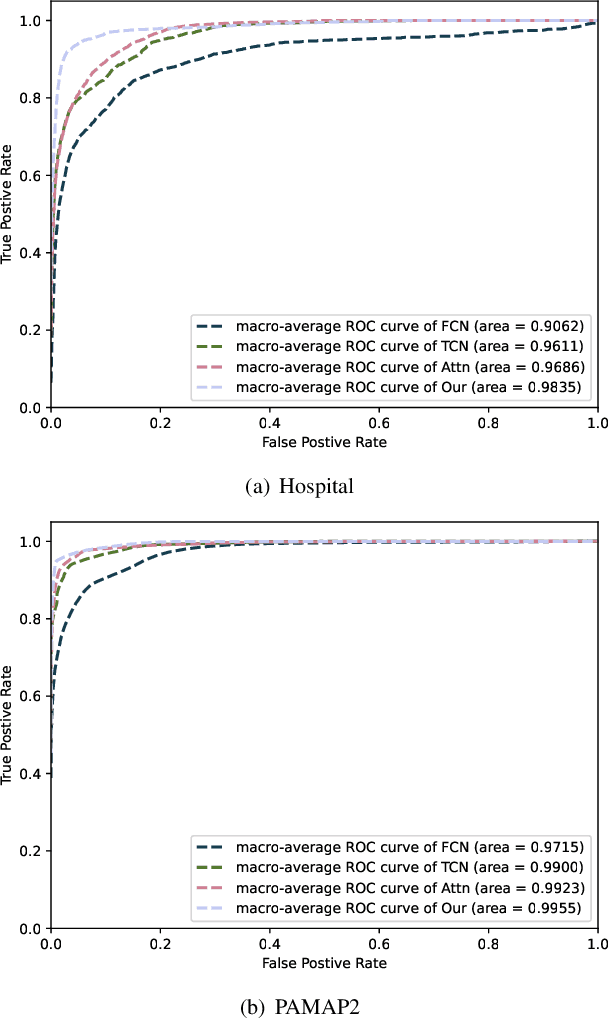
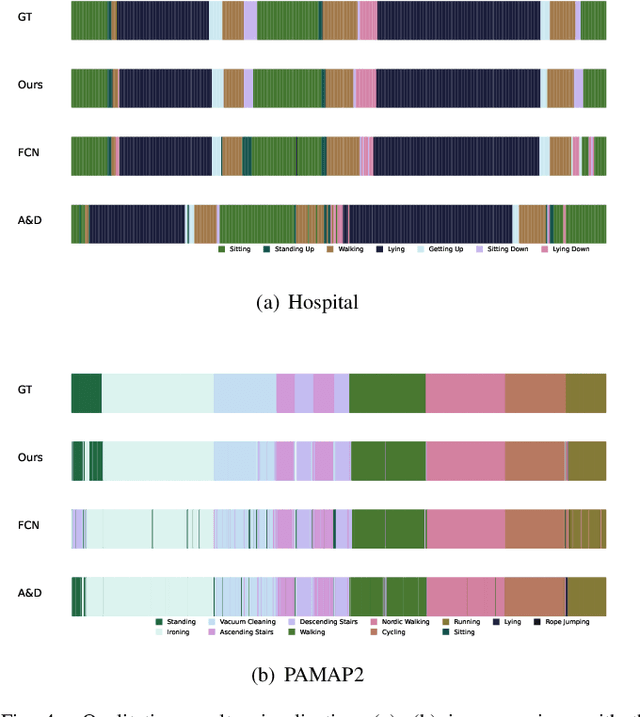
Human activity recognition (HAR) with wearables is promising research that can be widely adopted in many smart healthcare applications. In recent years, the deep learning-based HAR models have achieved impressive recognition performance. However, most HAR algorithms are susceptible to the multi-class windows problem that is essential yet rarely exploited. In this paper, we propose to relieve this challenging problem by introducing the segmentation technology into HAR, yielding joint activity segmentation and recognition. Especially, we introduce the Multi-Stage Temporal Convolutional Network (MS-TCN) architecture for sample-level activity prediction to joint segment and recognize the activity sequence. Furthermore, to enhance the robustness of HAR against the inter-class similarity and intra-class heterogeneity, a multi-level contrastive loss, containing the sample-level and segment-level contrast, has been proposed to learn a well-structured embedding space for better activity segmentation and recognition performance. Finally, with comprehensive experiments, we verify the effectiveness of the proposed method on two public HAR datasets, achieving significant improvements in the various evaluation metrics.
Self-Supervised Image Representation Learning with Geometric Set Consistency
Mar 29, 2022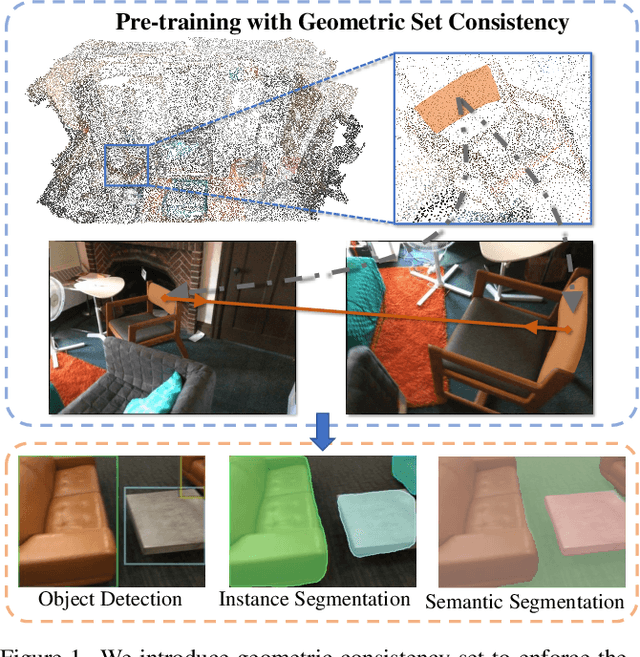
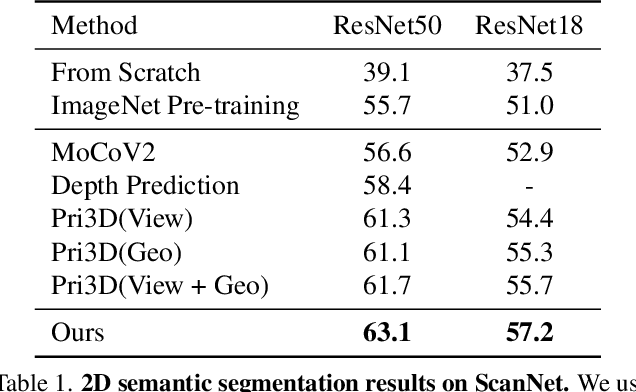
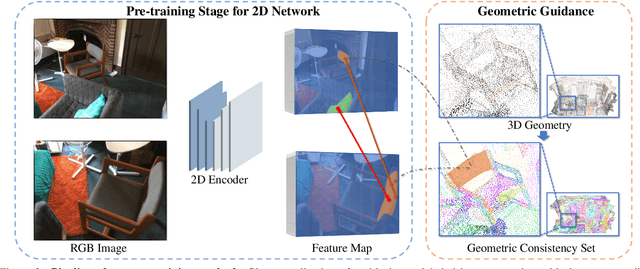
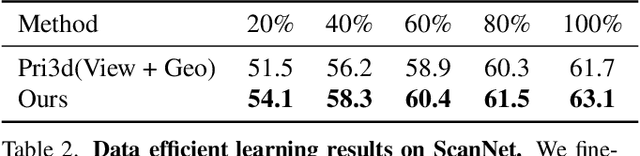
We propose a method for self-supervised image representation learning under the guidance of 3D geometric consistency. Our intuition is that 3D geometric consistency priors such as smooth regions and surface discontinuities may imply consistent semantics or object boundaries, and can act as strong cues to guide the learning of 2D image representations without semantic labels. Specifically, we introduce 3D geometric consistency into a contrastive learning framework to enforce the feature consistency within image views. We propose to use geometric consistency sets as constraints and adapt the InfoNCE loss accordingly. We show that our learned image representations are general. By fine-tuning our pre-trained representations for various 2D image-based downstream tasks, including semantic segmentation, object detection, and instance segmentation on real-world indoor scene datasets, we achieve superior performance compared with state-of-the-art methods.
Self-supervised Point Cloud Registration with Deep Versatile Descriptors
Jan 25, 2022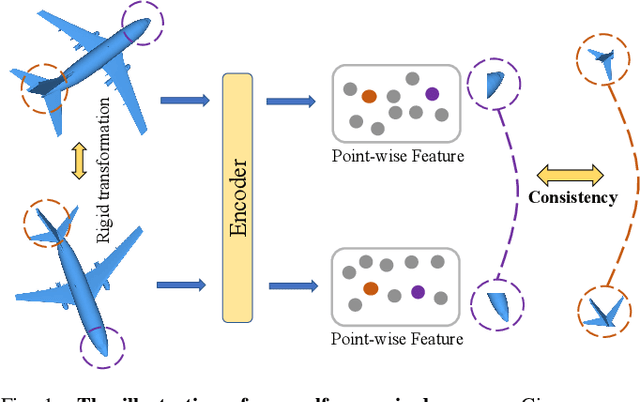

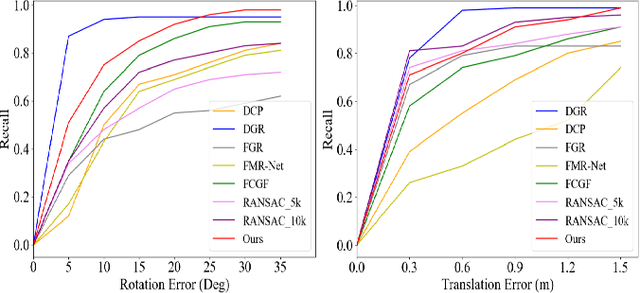
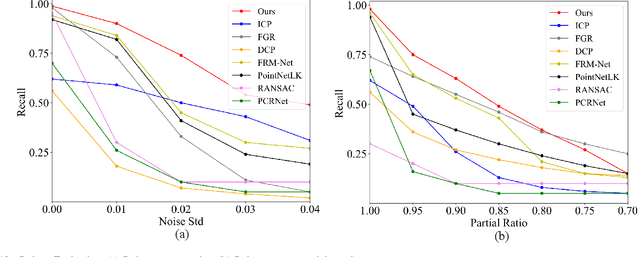
Recent years have witnessed an increasing trend toward solving point cloud registration problems with various deep learning-based algorithms. Compared to supervised/semi-supervised registration methods, unsupervised methods require no human annotations. However, unsupervised methods mainly depend on the global descriptors, which ignore the high-level representations of local geometries. In this paper, we propose a self-supervised registration scheme with a novel Deep Versatile Descriptors (DVD), jointly considering global representations and local representations. The DVD is motivated by a key observation that the local distinctive geometric structures of the point cloud by two subset points can be employed to enhance the representation ability of the feature extraction module. Furthermore, we utilize two additional tasks (reconstruction and normal estimation) to enhance the transformation awareness of the proposed DVDs. Lastly, we conduct extensive experiments on synthetic and real-world datasets, demonstrating that our method achieves state-of-the-art performance against competing methods over a wide range of experimental settings.
Learning Efficient Representations for Enhanced Object Detection on Large-scene SAR Images
Jan 22, 2022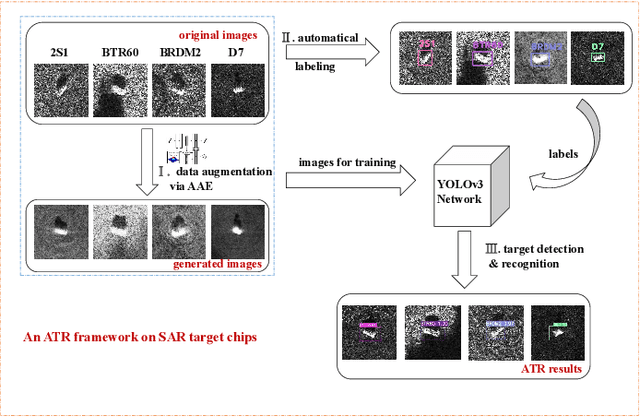
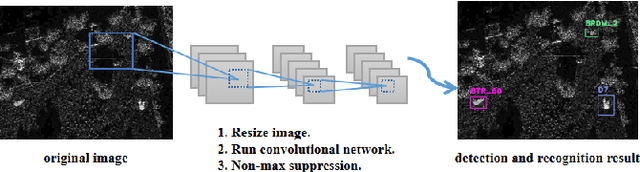


It is a challenging problem to detect and recognize targets on complex large-scene Synthetic Aperture Radar (SAR) images. Recently developed deep learning algorithms can automatically learn the intrinsic features of SAR images, but still have much room for improvement on large-scene SAR images with limited data. In this paper, based on learning representations and multi-scale features of SAR images, we propose an efficient and robust deep learning based target detection method. Especially, by leveraging the effectiveness of adversarial autoencoder (AAE) which influences the distribution of the investigated data explicitly, the raw SAR dataset is augmented into an enhanced version with a large quantity and diversity. Besides, an auto-labeling scheme is proposed to improve labeling efficiency. Finally, with jointly training small target chips and large-scene images, an integrated YOLO network combining non-maximum suppression on sub-images is used to realize multiple targets detection of high resolution images. The numerical experimental results on the MSTAR dataset show that our method can realize target detection and recognition on large-scene images accurately and efficiently. The superior anti-noise performance is also confirmed by experiments.
Unsupervised Shape Completion via Deep Prior in the Neural Tangent Kernel Perspective
Apr 19, 2021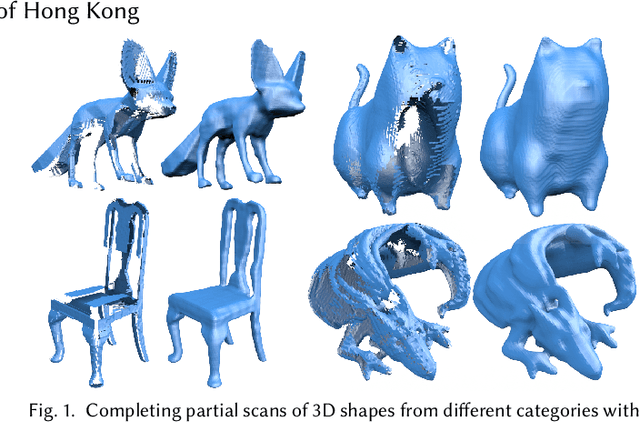
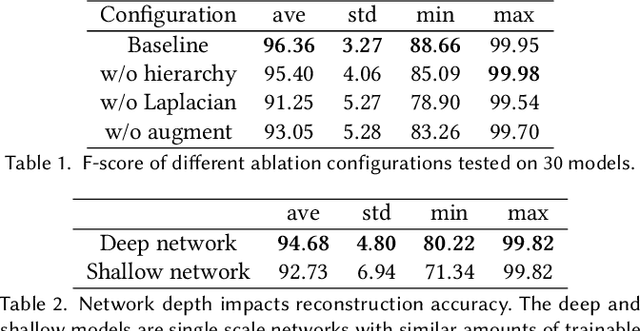
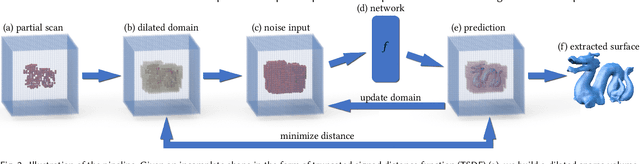

We present a novel approach for completing and reconstructing 3D shapes from incomplete scanned data by using deep neural networks. Rather than being trained on supervised completion tasks and applied on a testing shape, the network is optimized from scratch on the single testing shape, to fully adapt to the shape and complete the missing data using contextual guidance from the known regions. The ability to complete missing data by an untrained neural network is usually referred to as the deep prior. In this paper, we interpret the deep prior from a neural tangent kernel (NTK) perspective and show that the completed shape patches by the trained CNN are naturally similar to existing patches, as they are proximate in the kernel feature space induced by NTK. The interpretation allows us to design more efficient network structures and learning mechanisms for the shape completion and reconstruction task. Being more aware of structural regularities than both traditional and other unsupervised learning-based reconstruction methods, our approach completes large missing regions with plausible shapes and complements supervised learning-based methods that use database priors by requiring no extra training data set and showing flexible adaptation to a particular shape instance.
MARS: Mixed Virtual and Real Wearable Sensors for Human Activity Recognition with Multi-Domain Deep Learning Model
Oct 09, 2020

Together with the rapid development of the Internet of Things (IoT), human activity recognition (HAR) using wearable Inertial Measurement Units (IMUs) becomes a promising technology for many research areas. Recently, deep learning-based methods pave a new way of understanding and performing analysis of the complex data in the HAR system. However, the performance of these methods is mostly based on the quality and quantity of the collected data. In this paper, we innovatively propose to build a large database based on virtual IMUs and then address technical issues by introducing a multiple-domain deep learning framework consisting of three technical parts. In the first part, we propose to learn the single-frame human activity from the noisy IMU data with hybrid convolutional neural networks (CNNs) in the semi-supervised form. For the second part, the extracted data features are fused according to the principle of uncertainty-aware consistency, which reduces the uncertainty by weighting the importance of the features. The transfer learning is performed in the last part based on the newly released Archive of Motion Capture as Surface Shapes (AMASS) dataset, containing abundant synthetic human poses, which enhances the variety and diversity of the training dataset and is beneficial for the process of training and feature transfer in the proposed method. The efficiency and effectiveness of the proposed method have been demonstrated in the real deep inertial poser (DIP) dataset. The experimental results show that the proposed methods can surprisingly converge within a few iterations and outperform all competing methods.
A Self Contour-based Rotation and Translation-Invariant Transformation for Point Clouds Recognition
Sep 15, 2020
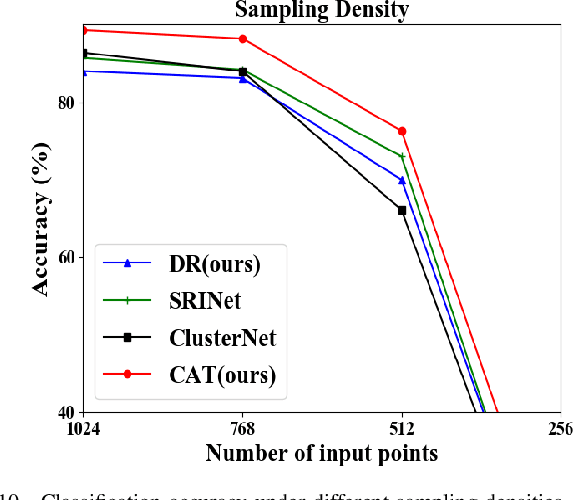
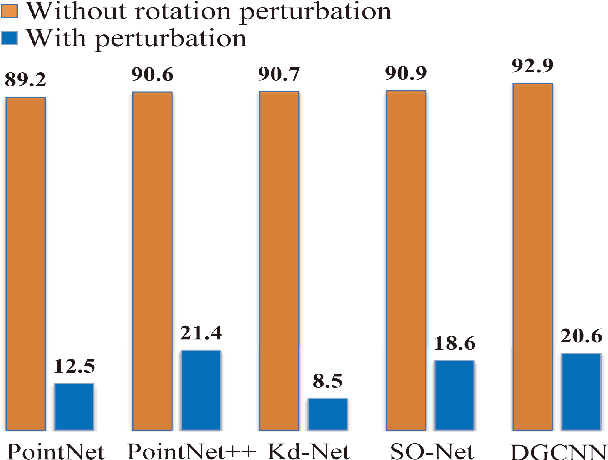
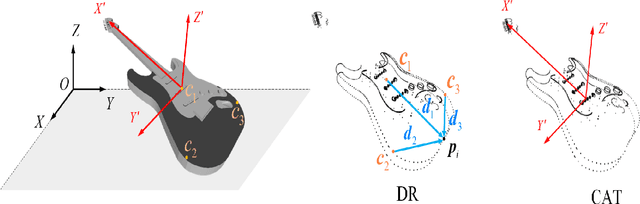
Recently, several direct processing point cloud models have achieved state-of-the-art performances for classification and segmentation tasks. However, these methods lack rotation robustness, and their performances degrade severely under random rotations, failing to extend to real-world applications with varying orientations. To address this problem, we propose a method named Self Contour-based Transformation (SCT), which can be flexibly integrated into a variety of existing point cloud recognition models against arbitrary rotations without any extra modifications. The SCT provides efficient and mathematically proved rotation and translation invariance by introducing Rotation and Translation-Invariant Transformation. It linearly transforms Cartesian coordinates of points to the self contour-based rotation-invariant representations while maintaining the global geometric structure. Moreover, to enhance discriminative feature extraction, the Frame Alignment module is further introduced, aiming to capture contours and transform self contour-based frames to the intra-class frame. Extensive experimental results and mathematical analyses show that the proposed method outperforms the state-of-the-art approaches under arbitrary rotations without any rotation augmentation on standard benchmarks, including ModelNet40, ScanObjectNN and ShapeNet.
A Deep Learning Method for Complex Human Activity Recognition Using Virtual Wearable Sensors
Mar 06, 2020
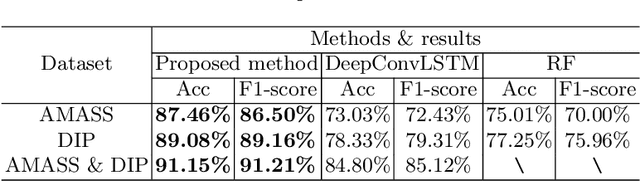

Sensor-based human activity recognition (HAR) is now a research hotspot in multiple application areas. With the rise of smart wearable devices equipped with inertial measurement units (IMUs), researchers begin to utilize IMU data for HAR. By employing machine learning algorithms, early IMU-based research for HAR can achieve accurate classification results on traditional classical HAR datasets, containing only simple and repetitive daily activities. However, these datasets rarely display a rich diversity of information in real-scene. In this paper, we propose a novel method based on deep learning for complex HAR in the real-scene. Specially, in the off-line training stage, the AMASS dataset, containing abundant human poses and virtual IMU data, is innovatively adopted for enhancing the variety and diversity. Moreover, a deep convolutional neural network with an unsupervised penalty is proposed to automatically extract the features of AMASS and improve the robustness. In the on-line testing stage, by leveraging advantages of the transfer learning, we obtain the final result by fine-tuning the partial neural network (optimizing the parameters in the fully-connected layers) using the real IMU data. The experimental results show that the proposed method can surprisingly converge in a few iterations and achieve an accuracy of 91.15% on a real IMU dataset, demonstrating the efficiency and effectiveness of the proposed method.
LEMO: Learn to Equalize for MIMO-OFDM Systems with Low-Resolution ADCs
May 14, 2019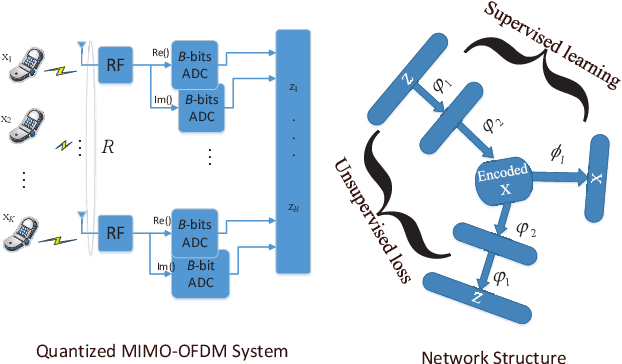
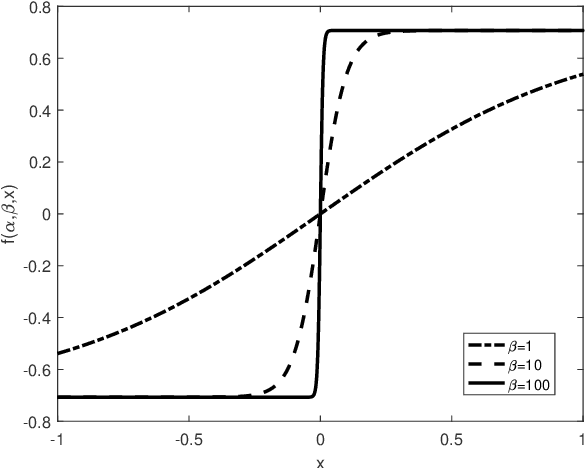
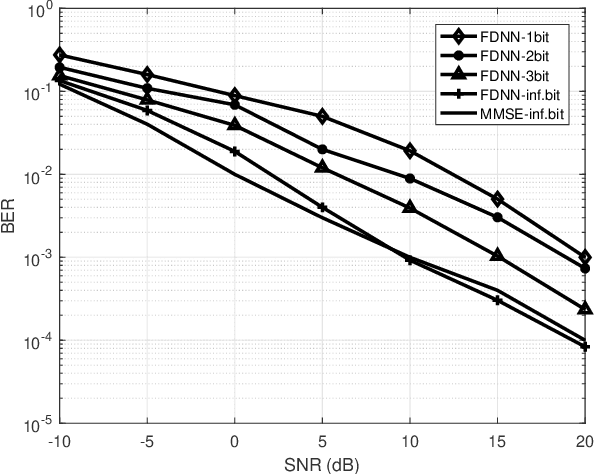
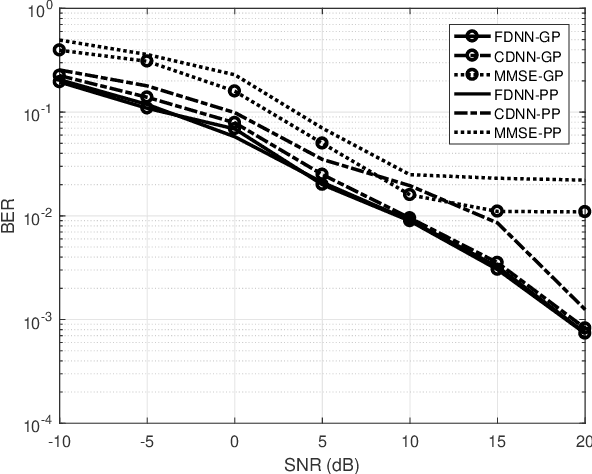
This paper develops a new deep neural network optimized equalization framework for massive multiple input multiple output orthogonal frequency division multiplexing (MIMO-OFDM) systems that employ low-resolution analog-to-digital converters (ADCs) at the base station (BS). The use of low-resolution ADCs could largely reduce hardware complexity and circuit power consumption, however, makes the channel station information almost blind to the BS, hence causing difficulty in solving the equalization problem. In this paper, we consider a supervised learning architecture, where the goal is to learn a representative function that can predict the targets (constellation points) from the inputs (outputs of the low-resolution ADCs) based on the labeled training data (pilot signals). Specially, our main contributions are two-fold: 1) First, we design a new activation function, whose outputs are close to the constellation points when the parameters are finally optimized, to help us fully exploit the stochastic gradient descent method for the discrete optimization problem. 2) Second, an unsupervised loss is designed and then added to the optimization objective, aiming to enhance the representation ability (so-called generalization). The experimental results reveal that the proposed equalizer is robust to different channel taps (i.e., Gaussian, and Poisson), significantly outperforms the linearized MMSE equalizer, and shows potential for pilot saving.