 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Unifying Hamiltonian Monte Carlo and Slice Sampling
Jan 10, 2018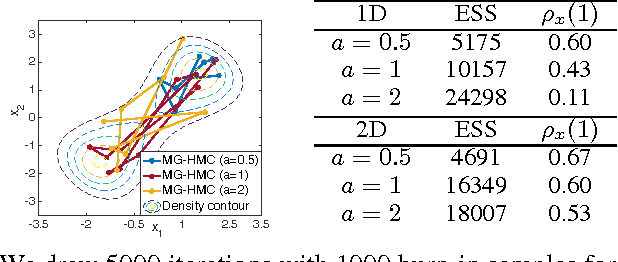


We unify slice sampling and Hamiltonian Monte Carlo (HMC) sampling, demonstrating their connection via the Hamiltonian-Jacobi equation from Hamiltonian mechanics. This insight enables extension of HMC and slice sampling to a broader family of samplers, called Monomial Gamma Samplers (MGS). We provide a theoretical analysis of the mixing performance of such samplers, proving that in the limit of a single parameter, the MGS draws decorrelated samples from the desired target distribution. We further show that as this parameter tends toward this limit, performance gains are achieved at a cost of increasing numerical difficulty and some practical convergence issues. Our theoretical results are validated with synthetic data and real-world applications.
* updated version
On Connecting Stochastic Gradient MCMC and Differential Privacy
Dec 25, 2017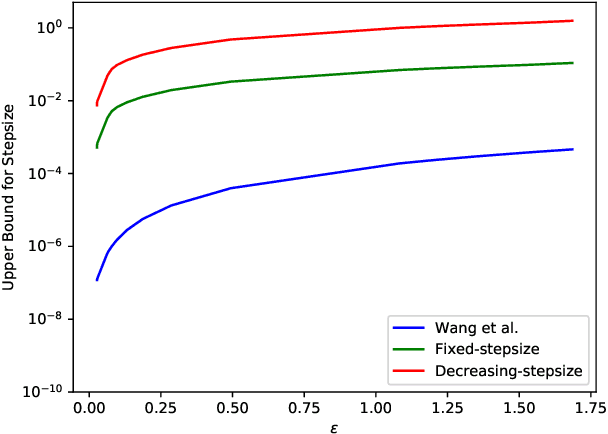
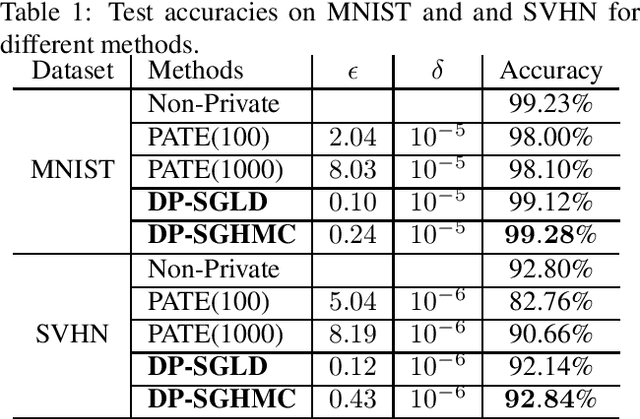
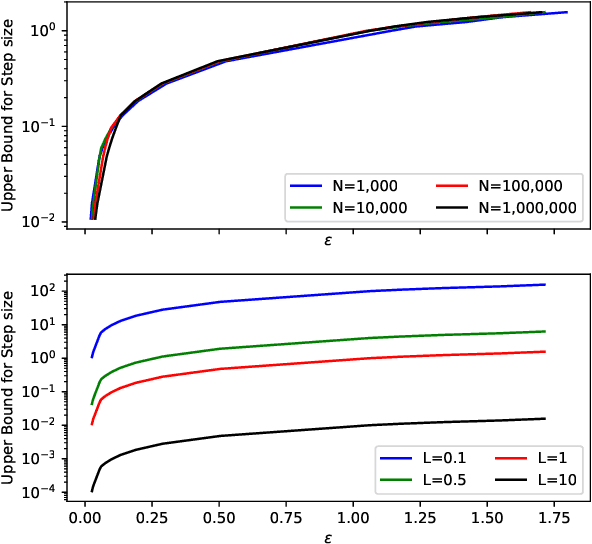
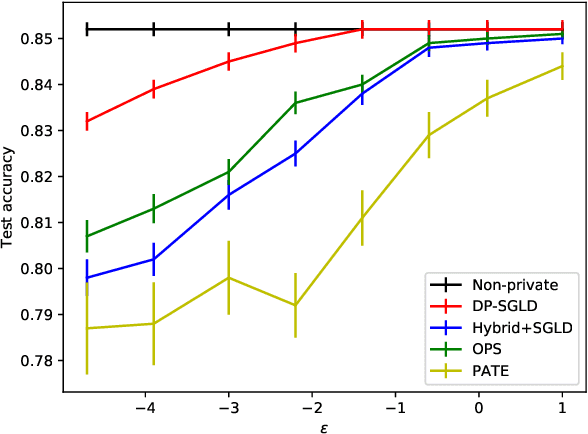
Significant success has been realized recently on applying machine learning to real-world applications. There have also been corresponding concerns on the privacy of training data, which relates to data security and confidentiality issues. Differential privacy provides a principled and rigorous privacy guarantee on machine learning models. While it is common to design a model satisfying a required differential-privacy property by injecting noise, it is generally hard to balance the trade-off between privacy and utility. We show that stochastic gradient Markov chain Monte Carlo (SG-MCMC) -- a class of scalable Bayesian posterior sampling algorithms proposed recently -- satisfies strong differential privacy with carefully chosen step sizes. We develop theory on the performance of the proposed differentially-private SG-MCMC method. We conduct experiments to support our analysis and show that a standard SG-MCMC sampler without any modification (under a default setting) can reach state-of-the-art performance in terms of both privacy and utility on Bayesian learning.
Deconvolutional Latent-Variable Model for Text Sequence Matching
Nov 22, 2017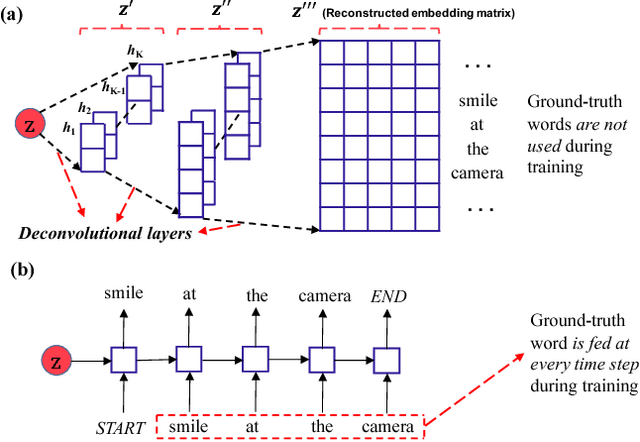

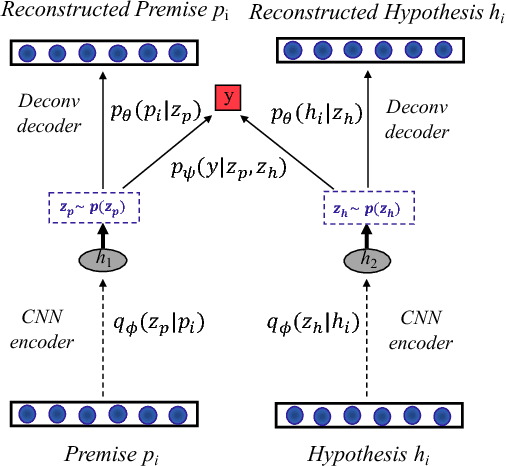

A latent-variable model is introduced for text matching, inferring sentence representations by jointly optimizing generative and discriminative objectives. To alleviate typical optimization challenges in latent-variable models for text, we employ deconvolutional networks as the sequence decoder (generator), providing learned latent codes with more semantic information and better generalization. Our model, trained in an unsupervised manner, yields stronger empirical predictive performance than a decoder based on Long Short-Term Memory (LSTM), with less parameters and considerably faster training. Further, we apply it to text sequence-matching problems. The proposed model significantly outperforms several strong sentence-encoding baselines, especially in the semi-supervised setting.
Zero-Shot Learning via Class-Conditioned Deep Generative Models
Nov 19, 2017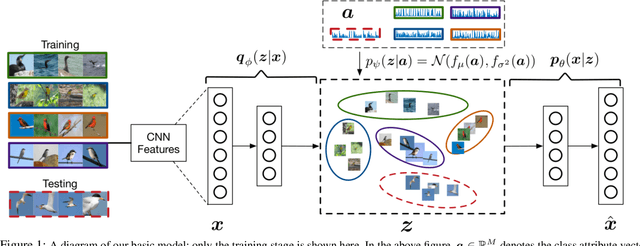
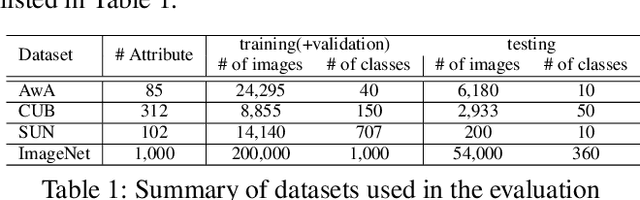
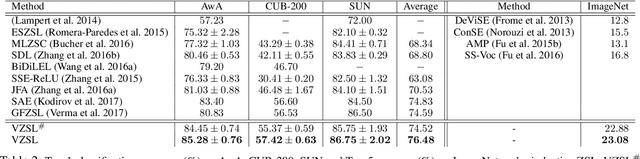
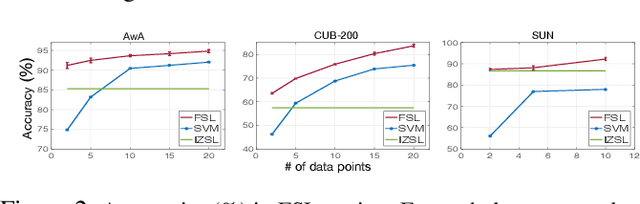
We present a deep generative model for learning to predict classes not seen at training time. Unlike most existing methods for this problem, that represent each class as a point (via a semantic embedding), we represent each seen/unseen class using a class-specific latent-space distribution, conditioned on class attributes. We use these latent-space distributions as a prior for a supervised variational autoencoder (VAE), which also facilitates learning highly discriminative feature representations for the inputs. The entire framework is learned end-to-end using only the seen-class training data. The model infers corresponding attributes of a test image by maximizing the VAE lower bound; the inferred attributes may be linked to labels not seen when training. We further extend our model to a (1) semi-supervised/transductive setting by leveraging unlabeled unseen-class data via an unsupervised learning module, and (2) few-shot learning where we also have a small number of labeled inputs from the unseen classes. We compare our model with several state-of-the-art methods through a comprehensive set of experiments on a variety of benchmark data sets.
Triangle Generative Adversarial Networks
Nov 18, 2017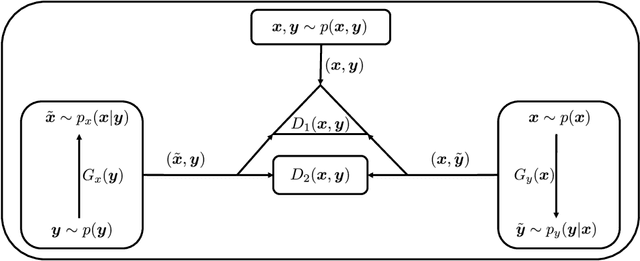
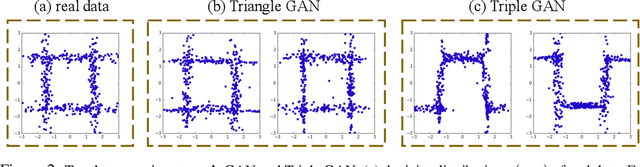
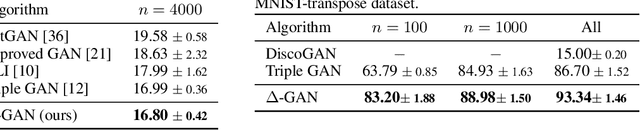

A Triangle Generative Adversarial Network ($\Delta$-GAN) is developed for semi-supervised cross-domain joint distribution matching, where the training data consists of samples from each domain, and supervision of domain correspondence is provided by only a few paired samples. $\Delta$-GAN consists of four neural networks, two generators and two discriminators. The generators are designed to learn the two-way conditional distributions between the two domains, while the discriminators implicitly define a ternary discriminative function, which is trained to distinguish real data pairs and two kinds of fake data pairs. The generators and discriminators are trained together using adversarial learning. Under mild assumptions, in theory the joint distributions characterized by the two generators concentrate to the data distribution. In experiments, three different kinds of domain pairs are considered, image-label, image-image and image-attribute pairs. Experiments on semi-supervised image classification, image-to-image translation and attribute-based image generation demonstrate the superiority of the proposed approach.
Adversarial Feature Matching for Text Generation
Nov 18, 2017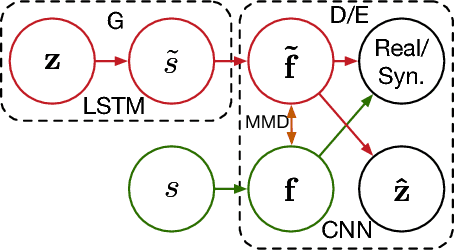
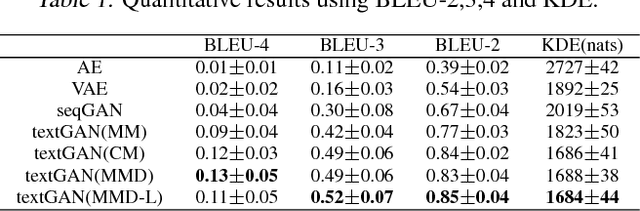
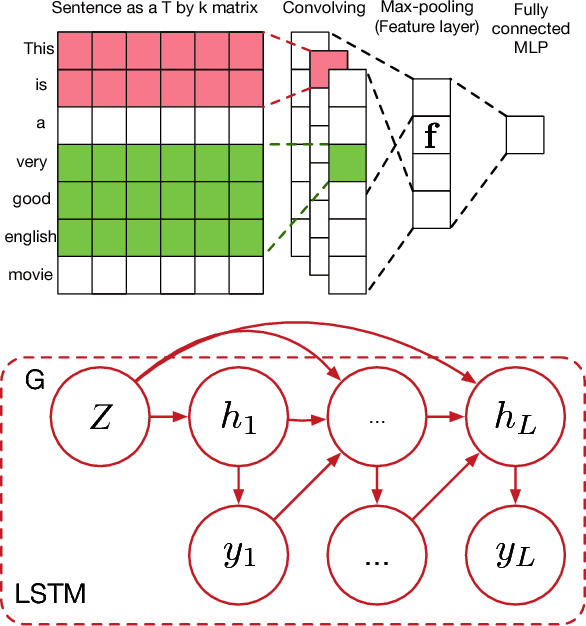

The Generative Adversarial Network (GAN) has achieved great success in generating realistic (real-valued) synthetic data. However, convergence issues and difficulties dealing with discrete data hinder the applicability of GAN to text. We propose a framework for generating realistic text via adversarial training. We employ a long short-term memory network as generator, and a convolutional network as discriminator. Instead of using the standard objective of GAN, we propose matching the high-dimensional latent feature distributions of real and synthetic sentences, via a kernelized discrepancy metric. This eases adversarial training by alleviating the mode-collapsing problem. Our experiments show superior performance in quantitative evaluation, and demonstrate that our model can generate realistic-looking sentences.
Adversarial Symmetric Variational Autoencoder
Nov 18, 2017
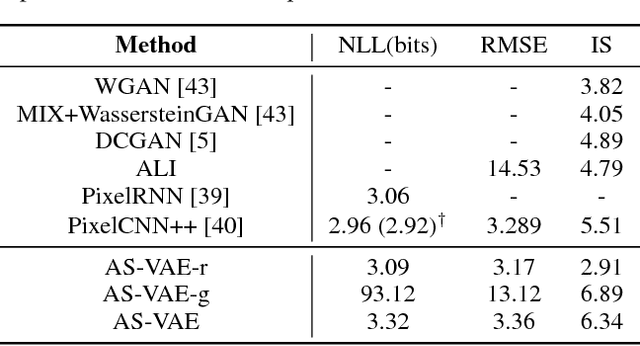

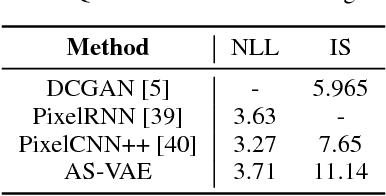
A new form of variational autoencoder (VAE) is developed, in which the joint distribution of data and codes is considered in two (symmetric) forms: ($i$) from observed data fed through the encoder to yield codes, and ($ii$) from latent codes drawn from a simple prior and propagated through the decoder to manifest data. Lower bounds are learned for marginal log-likelihood fits observed data and latent codes. When learning with the variational bound, one seeks to minimize the symmetric Kullback-Leibler divergence of joint density functions from ($i$) and ($ii$), while simultaneously seeking to maximize the two marginal log-likelihoods. To facilitate learning, a new form of adversarial training is developed. An extensive set of experiments is performed, in which we demonstrate state-of-the-art data reconstruction and generation on several image benchmark datasets.
VAE Learning via Stein Variational Gradient Descent
Nov 17, 2017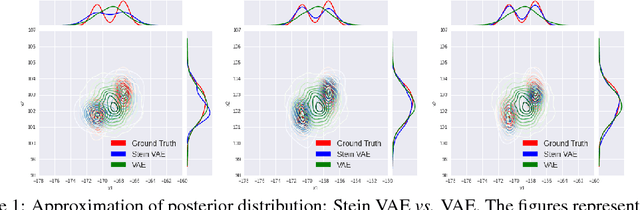

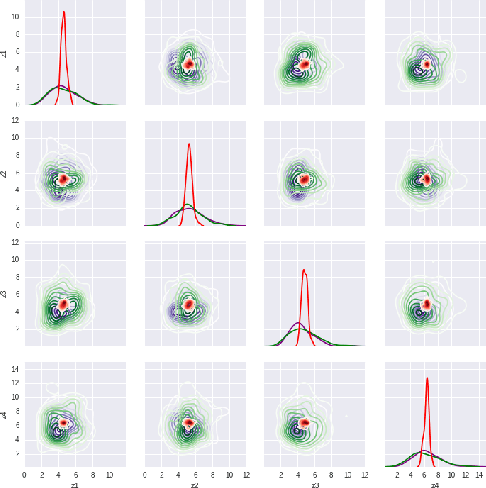
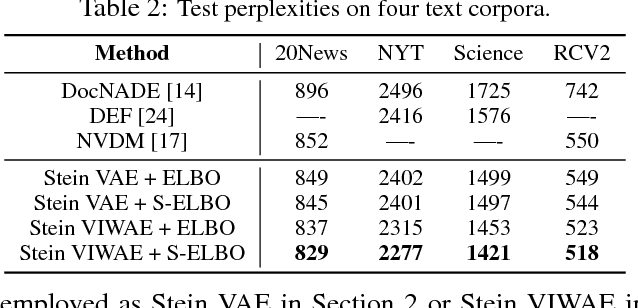
A new method for learning variational autoencoders (VAEs) is developed, based on Stein variational gradient descent. A key advantage of this approach is that one need not make parametric assumptions about the form of the encoder distribution. Performance is further enhanced by integrating the proposed encoder with importance sampling. Excellent performance is demonstrated across multiple unsupervised and semi-supervised problems, including semi-supervised analysis of the ImageNet data, demonstrating the scalability of the model to large datasets.
Adaptive Feature Abstraction for Translating Video to Text
Nov 17, 2017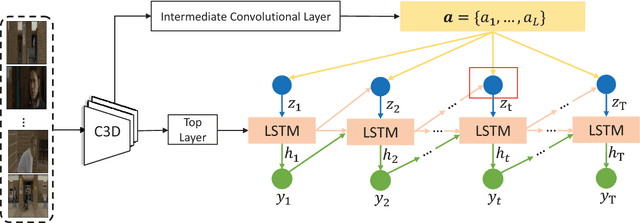
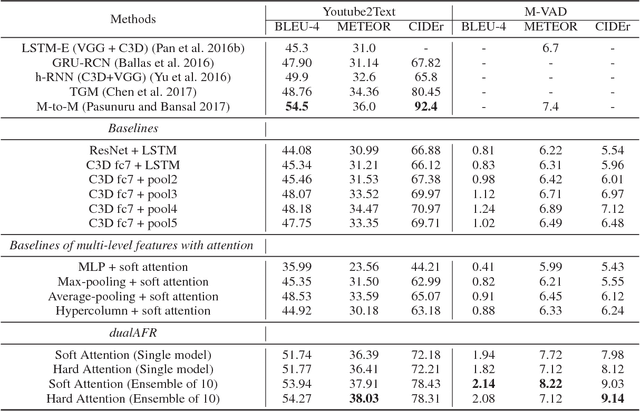
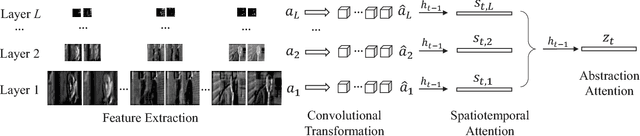
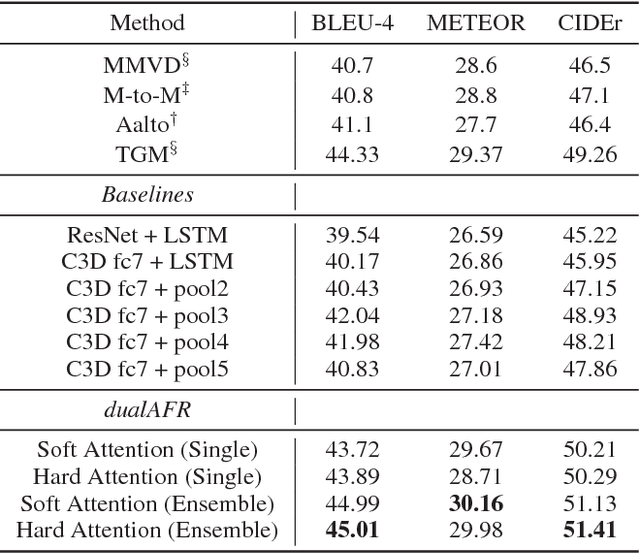
Previous models for video captioning often use the output from a specific layer of a Convolutional Neural Network (CNN) as video features. However, the variable context-dependent semantics in the video may make it more appropriate to adaptively select features from the multiple CNN layers. We propose a new approach for generating adaptive spatiotemporal representations of videos for the captioning task. A novel attention mechanism is developed, that adaptively and sequentially focuses on different layers of CNN features (levels of feature "abstraction"), as well as local spatiotemporal regions of the feature maps at each layer. The proposed approach is evaluated on three benchmark datasets: YouTube2Text, M-VAD and MSR-VTT. Along with visualizing the results and how the model works, these experiments quantitatively demonstrate the effectiveness of the proposed adaptive spatiotemporal feature abstraction for translating videos to sentences with rich semantics.
An inner-loop free solution to inverse problems using deep neural networks
Nov 14, 2017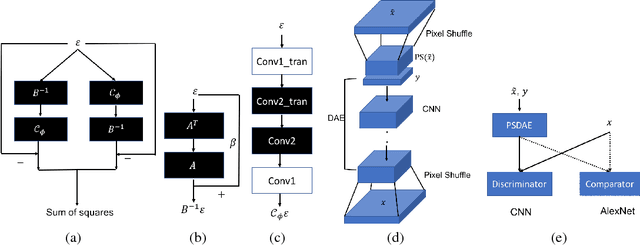
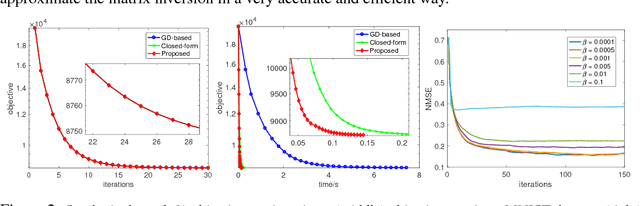


We propose a new method that uses deep learning techniques to accelerate the popular alternating direction method of multipliers (ADMM) solution for inverse problems. The ADMM updates consist of a proximity operator, a least squares regression that includes a big matrix inversion, and an explicit solution for updating the dual variables. Typically, inner loops are required to solve the first two sub-minimization problems due to the intractability of the prior and the matrix inversion. To avoid such drawbacks or limitations, we propose an inner-loop free update rule with two pre-trained deep convolutional architectures. More specifically, we learn a conditional denoising auto-encoder which imposes an implicit data-dependent prior/regularization on ground-truth in the first sub-minimization problem. This design follows an empirical Bayesian strategy, leading to so-called amortized inference. For matrix inversion in the second sub-problem, we learn a convolutional neural network to approximate the matrix inversion, i.e., the inverse mapping is learned by feeding the input through the learned forward network. Note that training this neural network does not require ground-truth or measurements, i.e., it is data-independent. Extensive experiments on both synthetic data and real datasets demonstrate the efficiency and accuracy of the proposed method compared with the conventional ADMM solution using inner loops for solving inverse problems.