 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Smoking Events with a Time-Varying Semi-Parametric Hawkes Process Model
Sep 05, 2018
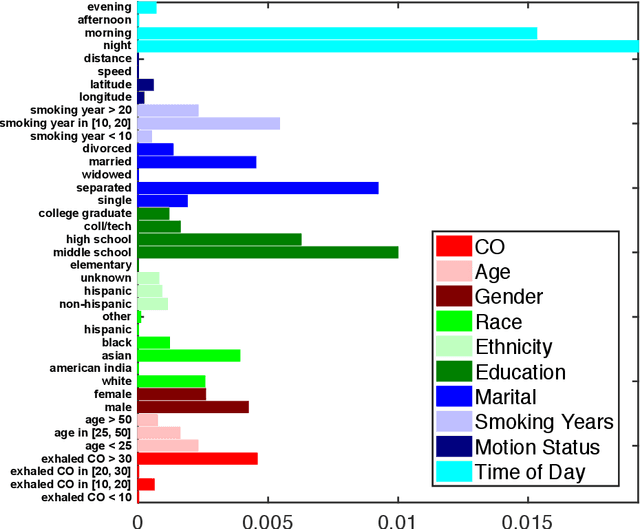
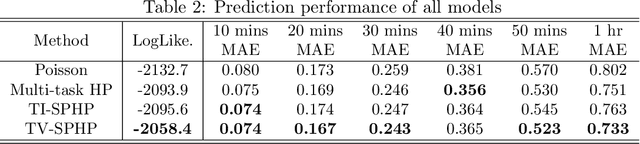
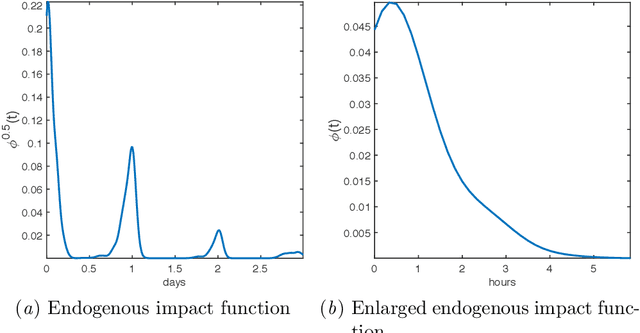
Health risks from cigarette smoking -- the leading cause of preventable death in the United States -- can be substantially reduced by quitting. Although most smokers are motivated to quit, the majority of quit attempts fail. A number of studies have explored the role of self-reported symptoms, physiologic measurements, and environmental context on smoking risk, but less work has focused on the temporal dynamics of smoking events, including daily patterns and related nicotine effects. In this work, we examine these dynamics and improve risk prediction by modeling smoking as a self-triggering process, in which previous smoking events modify current risk. Specifically, we fit smoking events self-reported by 42 smokers to a time-varying semi-parametric Hawkes process (TV-SPHP) developed for this purpose. Results show that the TV-SPHP achieves superior prediction performance compared to related and existing models, with the incorporation of time-varying predictors having greatest benefit over longer prediction windows. Moreover, the impact function illustrates previously unknown temporal dynamics of smoking, with possible connections to nicotine metabolism to be explored in future work through a randomized study design. By more effectively predicting smoking events and exploring a self-triggering component of smoking risk, this work supports development of novel or improved cessation interventions that aim to reduce death from smoking.
Learning Context-Sensitive Convolutional Filters for Text Processing
Aug 30, 2018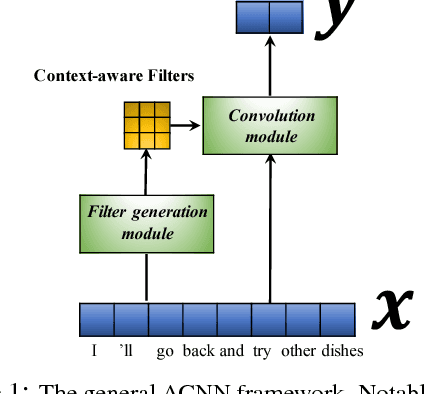
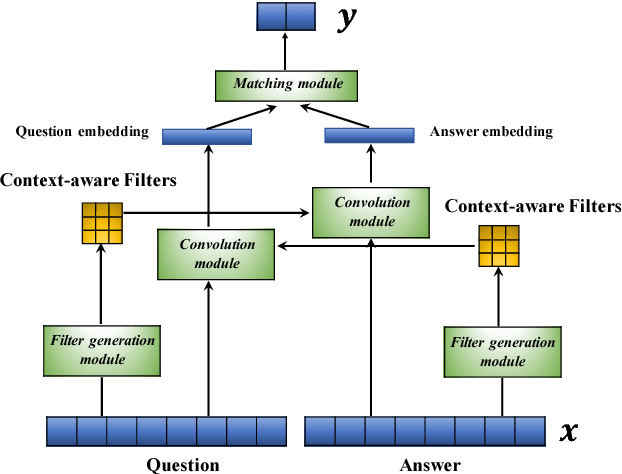
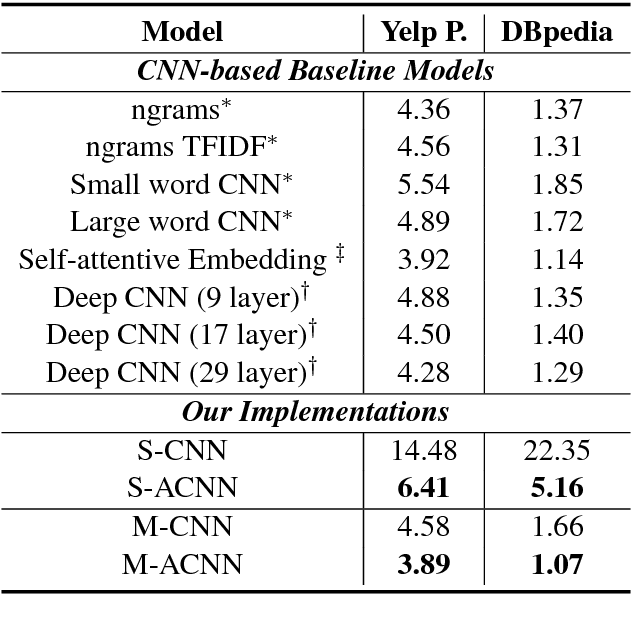
Convolutional neural networks (CNNs) have recently emerged as a popular building block for natural language processing (NLP). Despite their success, most existing CNN models employed in NLP share the same learned (and static) set of filters for all input sentences. In this paper, we consider an approach of using a small meta network to learn context-sensitive convolutional filters for text processing. The role of meta network is to abstract the contextual information of a sentence or document into a set of input-aware filters. We further generalize this framework to model sentence pairs, where a bidirectional filter generation mechanism is introduced to encapsulate co-dependent sentence representations. In our benchmarks on four different tasks, including ontology classification, sentiment analysis, answer sentence selection, and paraphrase identification, our proposed model, a modified CNN with context-sensitive filters, consistently outperforms the standard CNN and attention-based CNN baselines. By visualizing the learned context-sensitive filters, we further validate and rationalize the effectiveness of proposed framework.
Improved Semantic-Aware Network Embedding with Fine-Grained Word Alignment
Aug 29, 2018
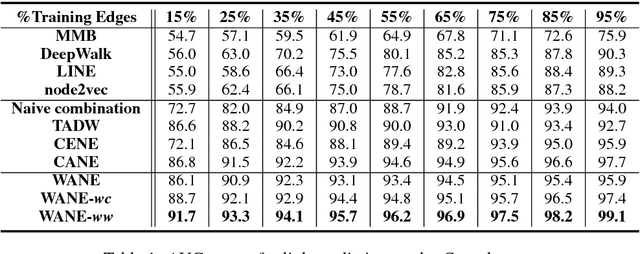
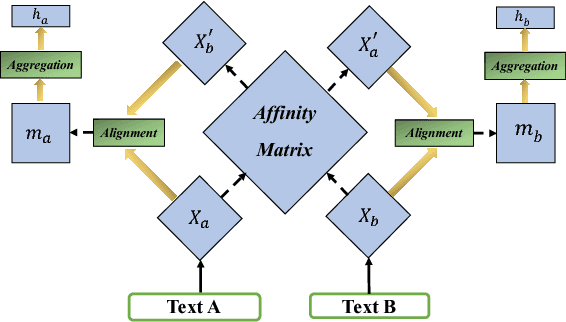
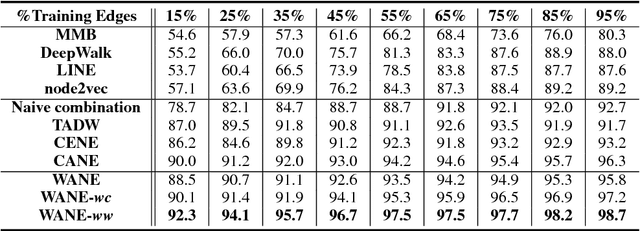
Network embeddings, which learn low-dimensional representations for each vertex in a large-scale network, have received considerable attention in recent years. For a wide range of applications, vertices in a network are typically accompanied by rich textual information such as user profiles, paper abstracts, etc. We propose to incorporate semantic features into network embeddings by matching important words between text sequences for all pairs of vertices. We introduce a word-by-word alignment framework that measures the compatibility of embeddings between word pairs, and then adaptively accumulates these alignment features with a simple yet effective aggregation function. In experiments, we evaluate the proposed framework on three real-world benchmarks for downstream tasks, including link prediction and multi-label vertex classification. Results demonstrate that our model outperforms state-of-the-art network embedding methods by a large margin.
Policy Optimization as Wasserstein Gradient Flows
Aug 09, 2018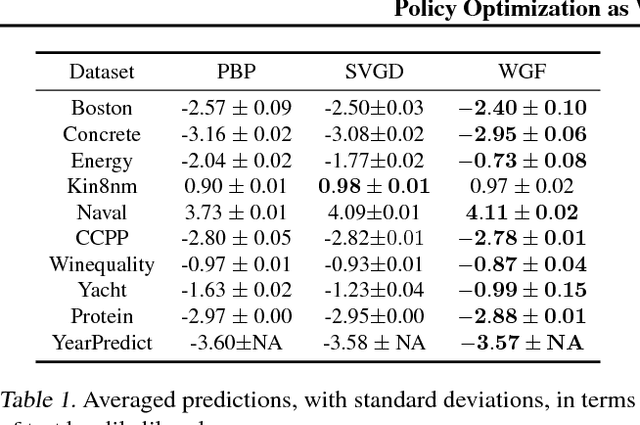
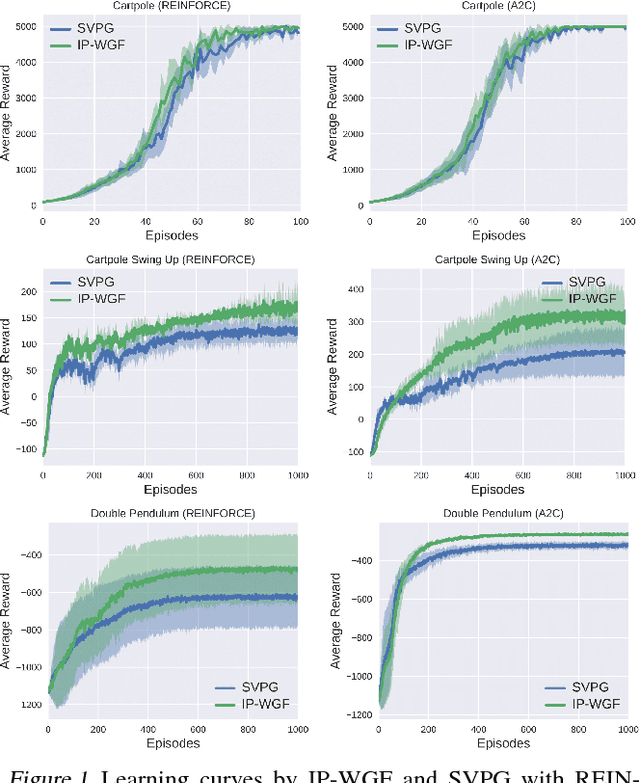
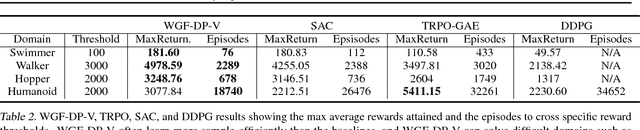
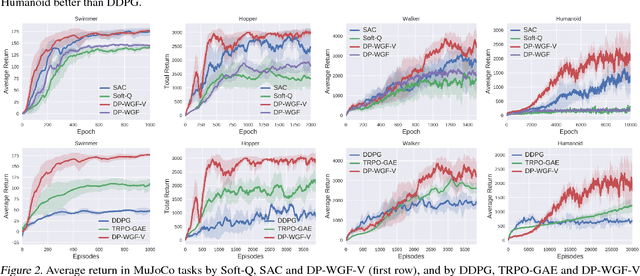
Policy optimization is a core component of reinforcement learning (RL), and most existing RL methods directly optimize parameters of a policy based on maximizing the expected total reward, or its surrogate. Though often achieving encouraging empirical success, its underlying mathematical principle on {\em policy-distribution} optimization is unclear. We place policy optimization into the space of probability measures, and interpret it as Wasserstein gradient flows. On the probability-measure space, under specified circumstances, policy optimization becomes a convex problem in terms of distribution optimization. To make optimization feasible, we develop efficient algorithms by numerically solving the corresponding discrete gradient flows. Our technique is applicable to several RL settings, and is related to many state-of-the-art policy-optimization algorithms. Empirical results verify the effectiveness of our framework, often obtaining better performance compared to related algorithms.
Multi-Label Learning from Medical Plain Text with Convolutional Residual Models
Aug 08, 2018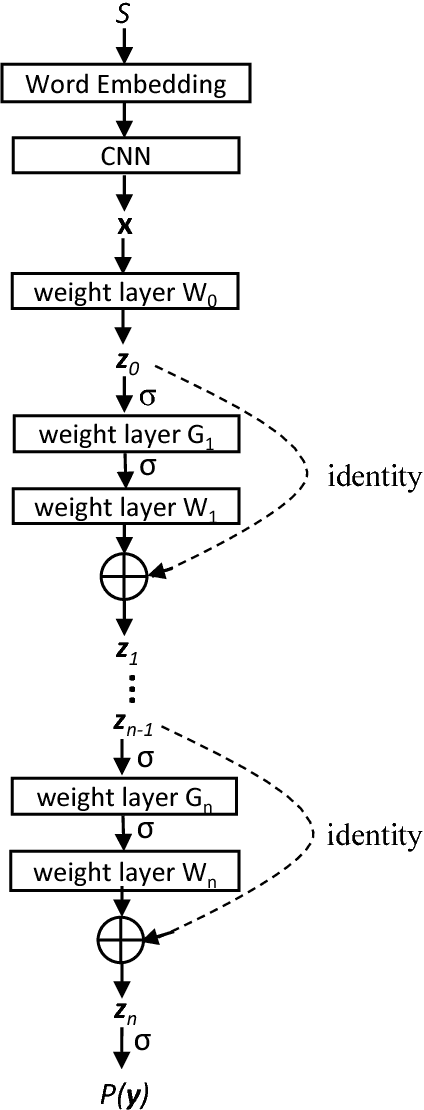

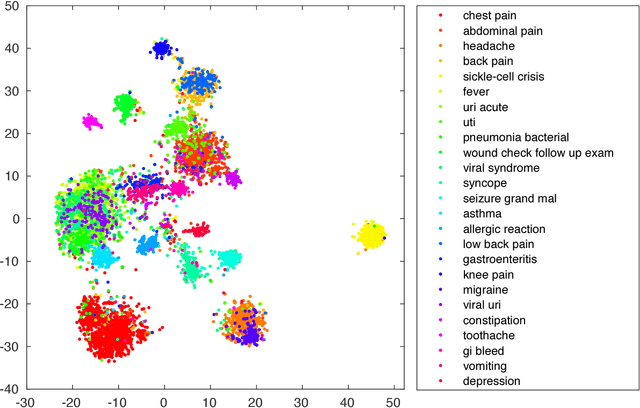
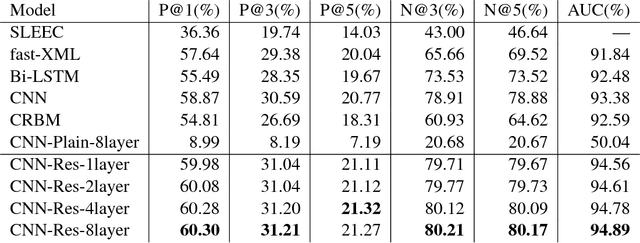
Predicting diagnoses from Electronic Health Records (EHRs) is an important medical application of multi-label learning. We propose a convolutional residual model for multi-label classification from doctor notes in EHR data. A given patient may have multiple diagnoses, and therefore multi-label learning is required. We employ a Convolutional Neural Network (CNN) to encode plain text into a fixed-length sentence embedding vector. Since diagnoses are typically correlated, a deep residual network is employed on top of the CNN encoder, to capture label (diagnosis) dependencies and incorporate information directly from the encoded sentence vector. A real EHR dataset is considered, and we compare the proposed model with several well-known baselines, to predict diagnoses based on doctor notes. Experimental results demonstrate the superiority of the proposed convolutional residual model.
Continuous-Time Flows for Efficient Inference and Density Estimation
Aug 01, 2018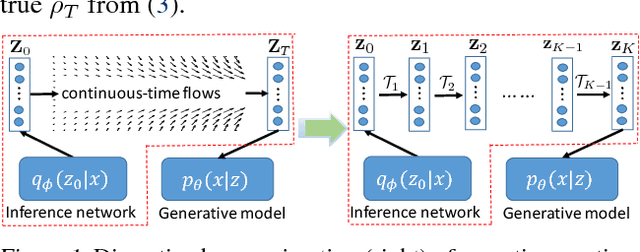

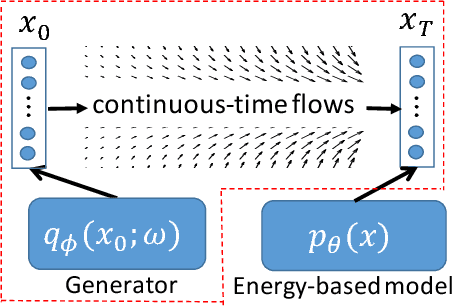
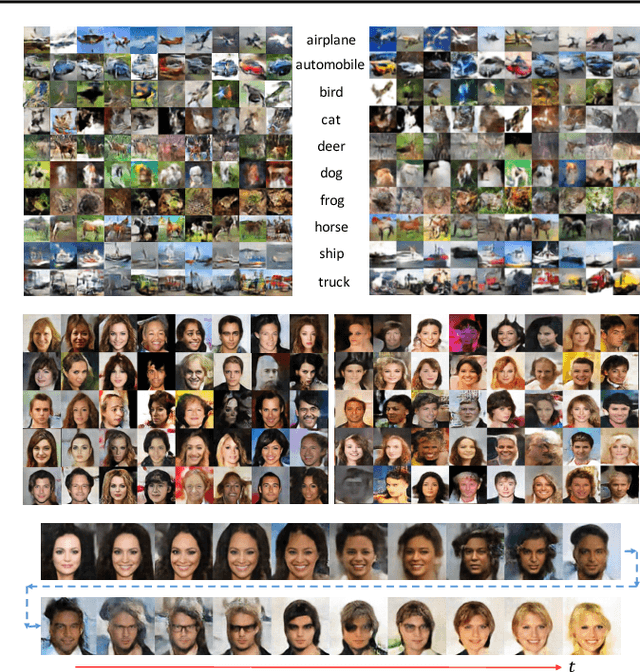
Two fundamental problems in unsupervised learning are efficient inference for latent-variable models and robust density estimation based on large amounts of unlabeled data. Algorithms for the two tasks, such as normalizing flows and generative adversarial networks (GANs), are often developed independently. In this paper, we propose the concept of {\em continuous-time flows} (CTFs), a family of diffusion-based methods that are able to asymptotically approach a target distribution. Distinct from normalizing flows and GANs, CTFs can be adopted to achieve the above two goals in one framework, with theoretical guarantees. Our framework includes distilling knowledge from a CTF for efficient inference, and learning an explicit energy-based distribution with CTFs for density estimation. Both tasks rely on a new technique for distribution matching within amortized learning. Experiments on various tasks demonstrate promising performance of the proposed CTF framework, compared to related techniques.
Accelerated First-order Methods on the Wasserstein Space for Bayesian Inference
Jul 04, 2018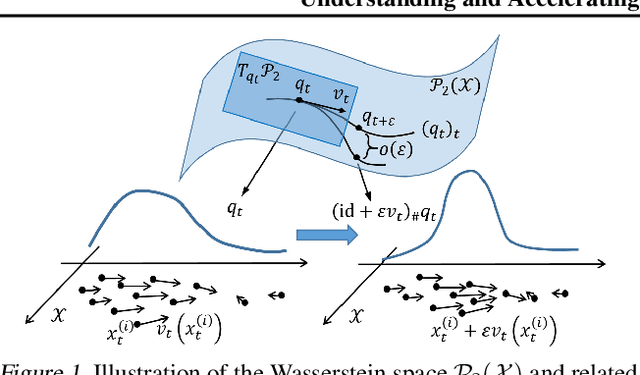

We consider doing Bayesian inference by minimizing the KL divergence on the 2-Wasserstein space $\mathcal{P}_2$. By exploring the Riemannian structure of $\mathcal{P}_2$, we develop two inference methods by simulating the gradient flow on $\mathcal{P}_2$ via updating particles, and an acceleration method that speeds up all such particle-simulation-based inference methods. Moreover we analyze the approximation flexibility of such methods, and conceive a novel bandwidth selection method for the kernel that they use. We note that $\mathcal{P}_2$ is quite abstract and general so that our methods can make closer approximation, while it still has a rich structure that enables practical implementation. Experiments show the effectiveness of the two proposed methods and the improvement of convergence by the acceleration method.
JointGAN: Multi-Domain Joint Distribution Learning with Generative Adversarial Nets
Jun 08, 2018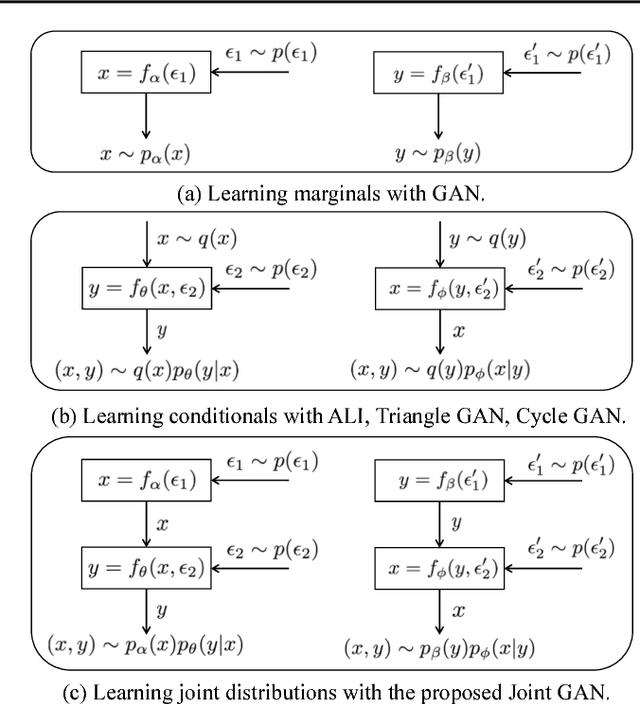
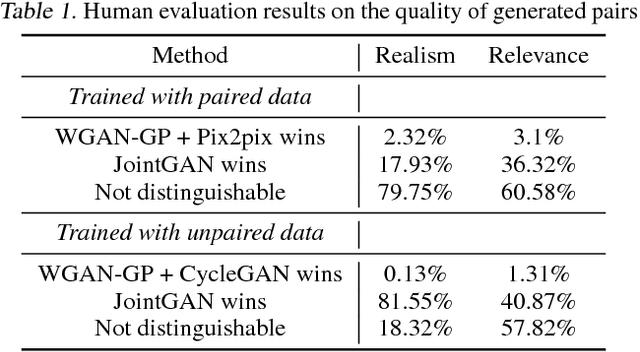
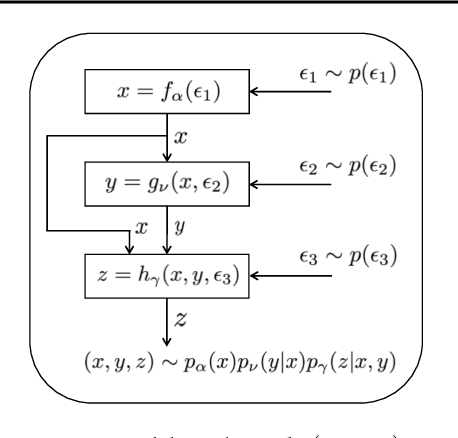
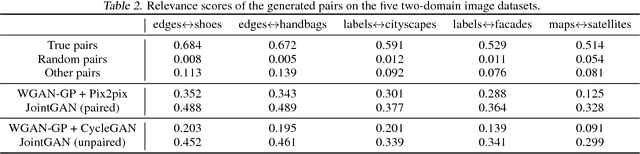
A new generative adversarial network is developed for joint distribution matching. Distinct from most existing approaches, that only learn conditional distributions, the proposed model aims to learn a joint distribution of multiple random variables (domains). This is achieved by learning to sample from conditional distributions between the domains, while simultaneously learning to sample from the marginals of each individual domain. The proposed framework consists of multiple generators and a single softmax-based critic, all jointly trained via adversarial learning. From a simple noise source, the proposed framework allows synthesis of draws from the marginals, conditional draws given observations from a subset of random variables, or complete draws from the full joint distribution. Most examples considered are for joint analysis of two domains, with examples for three domains also presented.
Adversarial Time-to-Event Modeling
Jun 07, 2018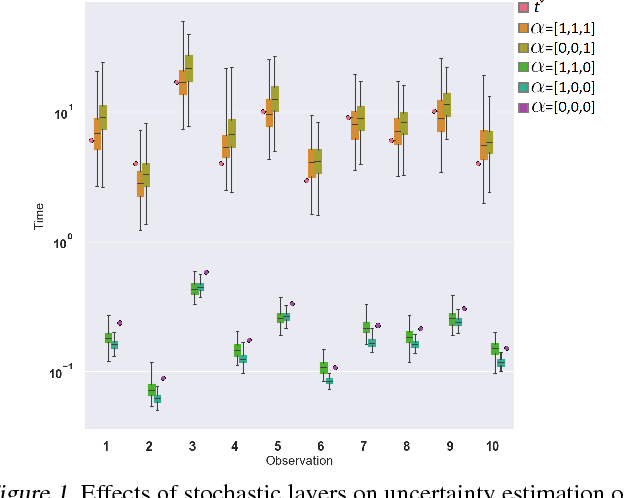
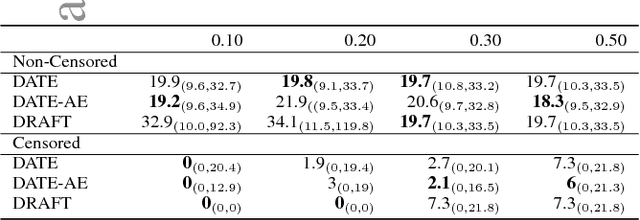
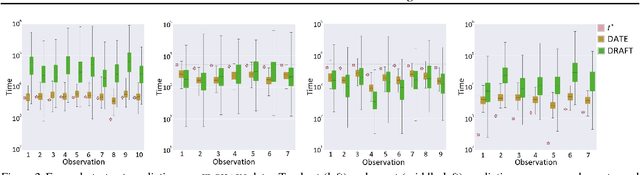

Modern health data science applications leverage abundant molecular and electronic health data, providing opportunities for machine learning to build statistical models to support clinical practice. Time-to-event analysis, also called survival analysis, stands as one of the most representative examples of such statistical models. We present a deep-network-based approach that leverages adversarial learning to address a key challenge in modern time-to-event modeling: nonparametric estimation of event-time distributions. We also introduce a principled cost function to exploit information from censored events (events that occur subsequent to the observation window). Unlike most time-to-event models, we focus on the estimation of time-to-event distributions, rather than time ordering. We validate our model on both benchmark and real datasets, demonstrating that the proposed formulation yields significant performance gains relative to a parametric alternative, which we also propose.
Diffusion Maps for Textual Network Embedding
May 24, 2018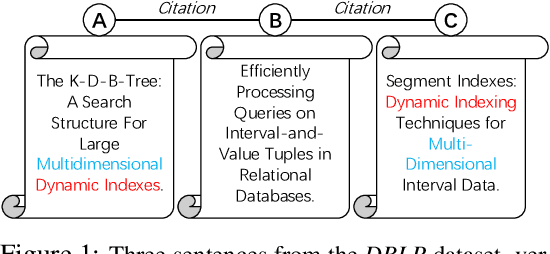
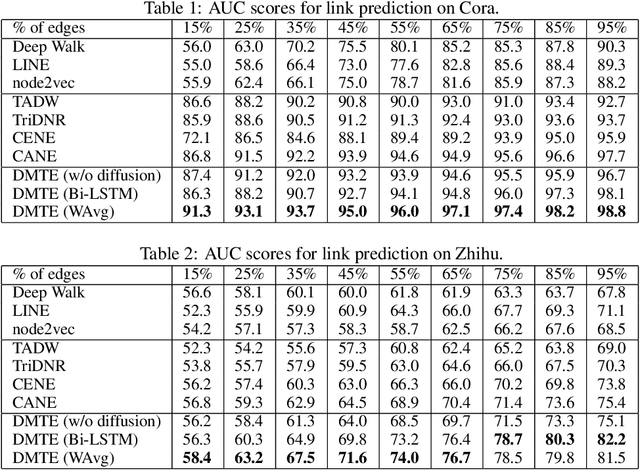
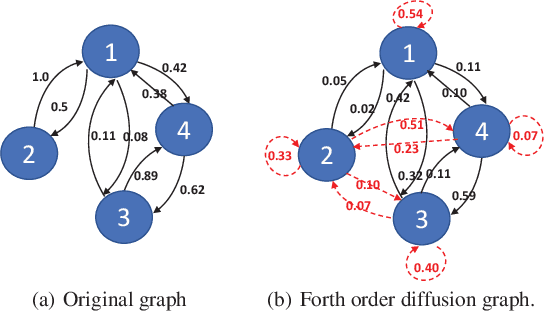
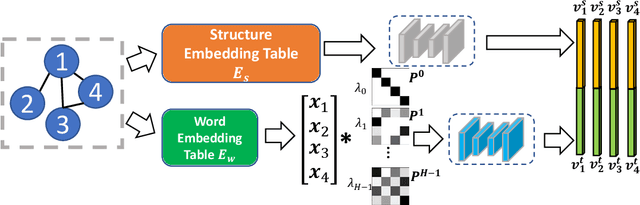
Textual network embedding leverages rich text information associated with the network to learn low-dimensional vectorial representations of vertices. Rather than using typical natural language processing (NLP) approaches, recent research exploits the relationship of texts on the same edge to graphically embed text. However, these models neglect to measure the complete level of connectivity between any two texts in the graph. We present diffusion maps for textual network embedding (DMTE), integrating global structural information of the graph to capture the semantic relatedness between texts, with a diffusion-convolution operation applied on the text inputs. In addition, a new objective function is designed to efficiently preserve the high-order proximity using the graph diffusion. Experimental results show that the proposed approach outperforms state-of-the-art methods on the vertex-classification and link-prediction tasks.