 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvival Function Matching for Calibrated Time-to-Event Predictions
May 21, 2019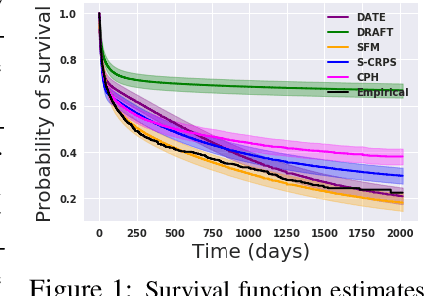
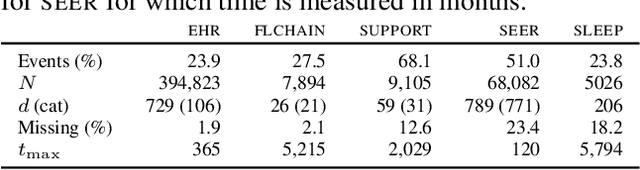
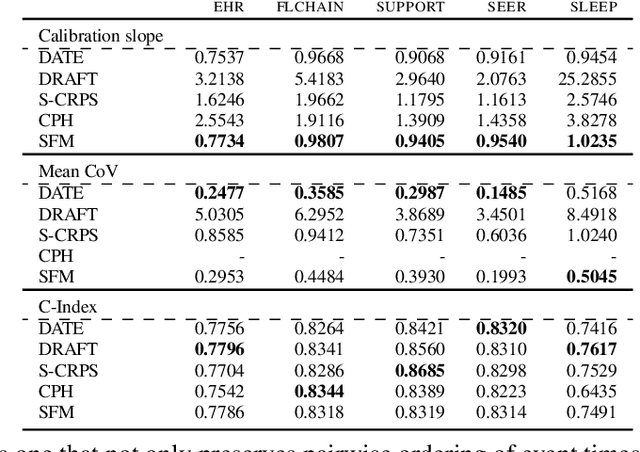
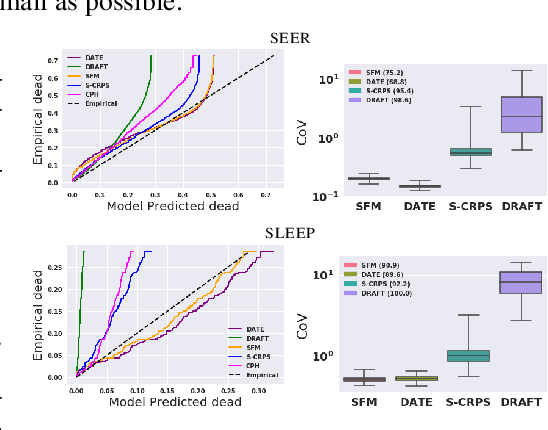
Models for predicting the time of a future event are crucial for risk assessment, across a diverse range of applications. Existing time-to-event (survival) models have focused primarily on preserving pairwise ordering of estimated event times, or relative risk. Model calibration is relatively under explored, despite its critical importance in time-to-event applications. We present a survival function estimator for probabilistic predictions in time-to-event models, based on a neural network model for draws from the distribution of event times, without explicit assumptions on the form of the distribution. This is done like in adversarial learning, but we achieve learning without a discriminator or adversarial objective. The proposed estimator can be used in practice as a means of estimating and comparing conditional survival distributions, while accounting for the predictive uncertainty of probabilistic models. Extensive experiments show that the proposed model outperforms existing approaches, trained both with and without adversarial learning, in terms of both calibration and concentration of time-to-event distributions.
On Norm-Agnostic Robustness of Adversarial Training
May 15, 2019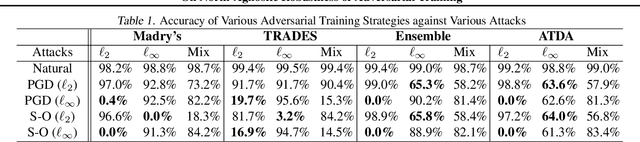
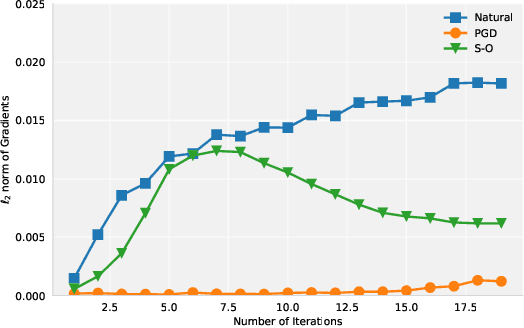
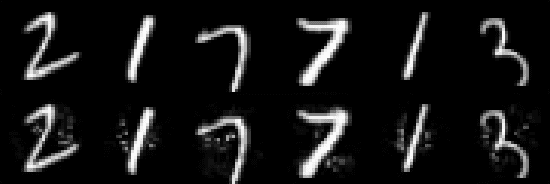
Adversarial examples are carefully perturbed in-puts for fooling machine learning models. A well-acknowledged defense method against such examples is adversarial training, where adversarial examples are injected into training data to increase robustness. In this paper, we propose a new attack to unveil an undesired property of the state-of-the-art adversarial training, that is it fails to obtain robustness against perturbations in $\ell_2$ and $\ell_\infty$ norms simultaneously. We discuss a possible solution to this issue and its limitations as well.
Stochastic Blockmodels meet Graph Neural Networks
May 14, 2019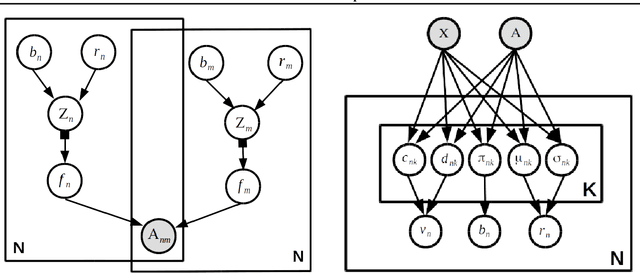
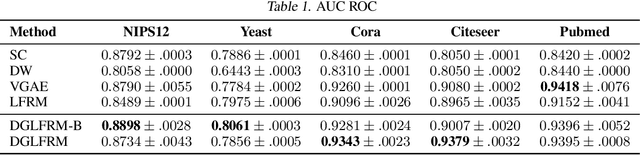
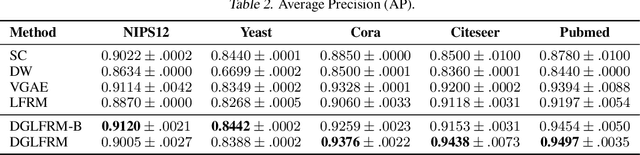
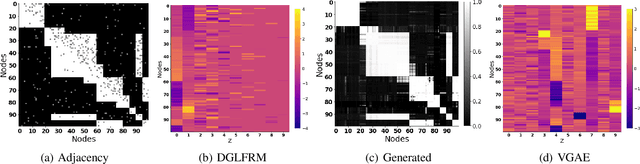
Stochastic blockmodels (SBM) and their variants, $e.g.$, mixed-membership and overlapping stochastic blockmodels, are latent variable based generative models for graphs. They have proven to be successful for various tasks, such as discovering the community structure and link prediction on graph-structured data. Recently, graph neural networks, $e.g.$, graph convolutional networks, have also emerged as a promising approach to learn powerful representations (embeddings) for the nodes in the graph, by exploiting graph properties such as locality and invariance. In this work, we unify these two directions by developing a \emph{sparse} variational autoencoder for graphs, that retains the interpretability of SBMs, while also enjoying the excellent predictive performance of graph neural nets. Moreover, our framework is accompanied by a fast recognition model that enables fast inference of the node embeddings (which are of independent interest for inference in SBM and its variants). Although we develop this framework for a particular type of SBM, namely the \emph{overlapping} stochastic blockmodel, the proposed framework can be adapted readily for other types of SBMs. Experimental results on several benchmarks demonstrate encouraging results on link prediction while learning an interpretable latent structure that can be used for community discovery.
A Deep-Learning Algorithm for Thyroid Malignancy Prediction From Whole Slide Cytopathology Images
Apr 26, 2019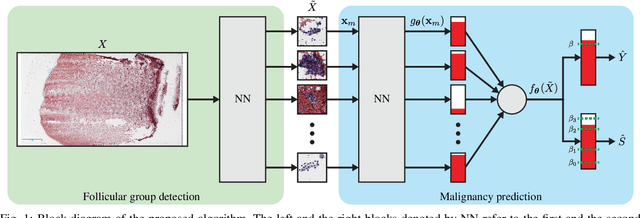
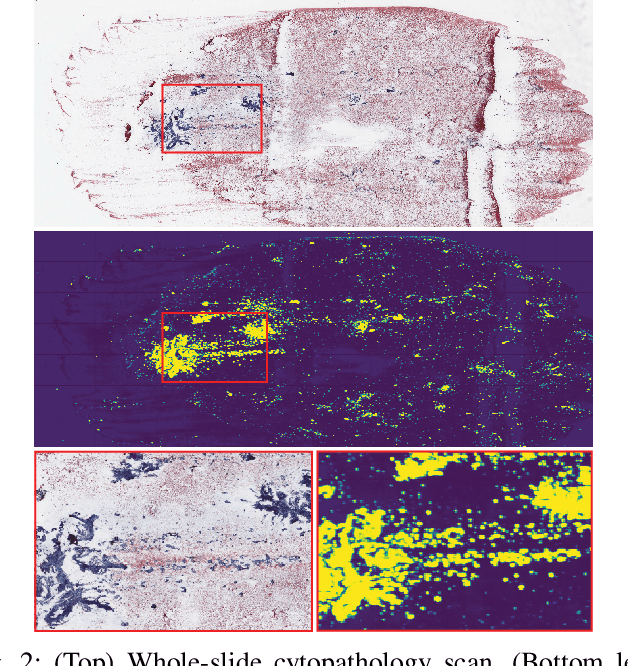
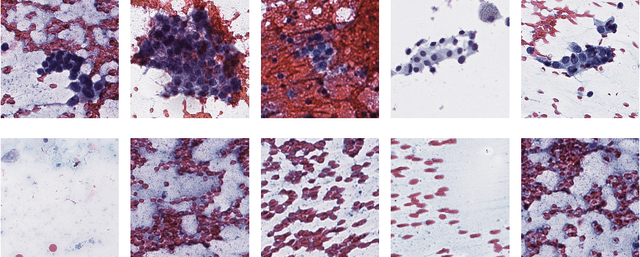
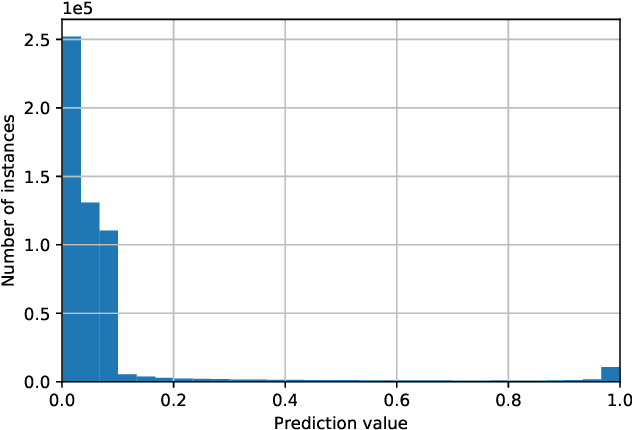
We consider thyroid-malignancy prediction from ultra-high-resolution whole-slide cytopathology images. We propose a deep-learning-based algorithm that is inspired by the way a cytopathologist diagnoses the slides. The algorithm identifies diagnostically relevant image regions and assigns them local malignancy scores, that in turn are incorporated into a global malignancy prediction. We discuss the relation of our deep-learning-based approach to multiple-instance learning (MIL) and describe how it deviates from classical MIL methods by the use of a supervised procedure to extract relevant regions from the whole-slide. The analysis of our algorithm further reveals a close relation to hypothesis testing, which, along with unique characteristics of thyroid cytopathology, allows us to devise an improved training strategy. We further propose an ordinal regression framework for the simultaneous prediction of thyroid malignancy and an ordered diagnostic score acting as a regularizer, which further improves the predictions of the network. Experimental results demonstrate that the proposed algorithm outperforms several competing methods, achieving performance comparable to human experts.
Thyroid Cancer Malignancy Prediction From Whole Slide Cytopathology Images
Mar 29, 2019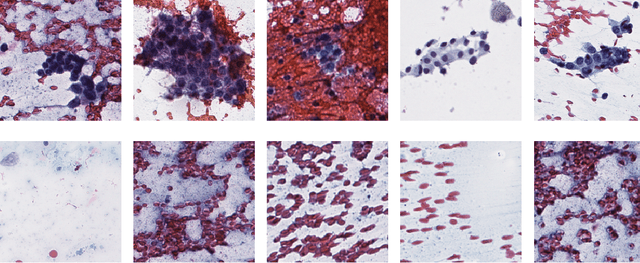
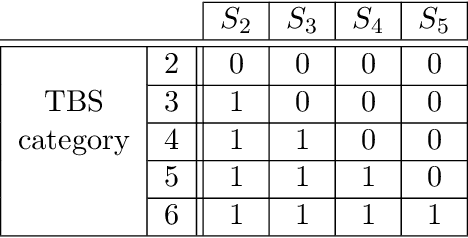
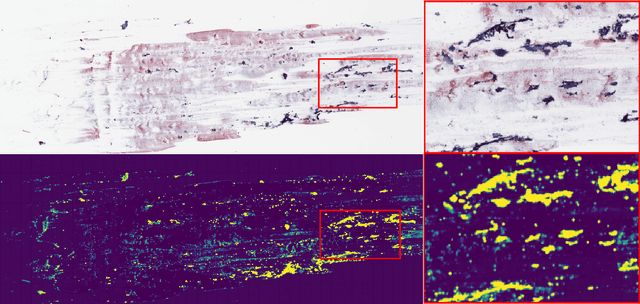
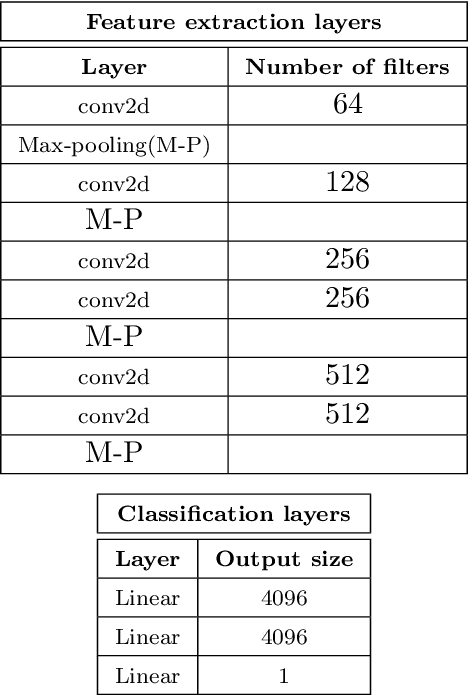
We consider preoperative prediction of thyroid cancer based on ultra-high-resolution whole-slide cytopathology images. Inspired by how human experts perform diagnosis, our approach first identifies and classifies diagnostic image regions containing informative thyroid cells, which only comprise a tiny fraction of the entire image. These local estimates are then aggregated into a single prediction of thyroid malignancy. Several unique characteristics of thyroid cytopathology guide our deep-learning-based approach. While our method is closely related to multiple-instance learning, it deviates from these methods by using a supervised procedure to extract diagnostically relevant regions. Moreover, we propose to simultaneously predict thyroid malignancy, as well as a diagnostic score assigned by a human expert, which further allows us to devise an improved training strategy. Experimental results show that the proposed algorithm achieves performance comparable to human experts, and demonstrate the potential of using the algorithm for screening and as an assistive tool for the improved diagnosis of indeterminate cases.
Cyclical Annealing Schedule: A Simple Approach to Mitigating KL Vanishing
Mar 25, 2019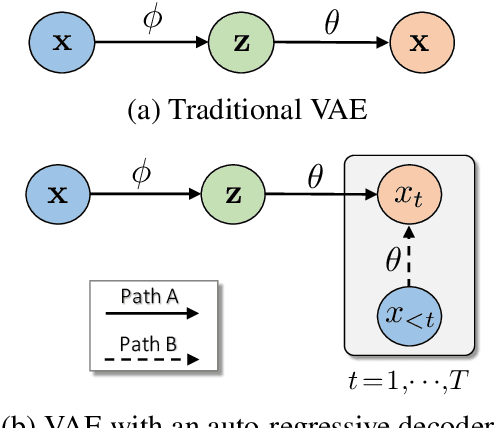
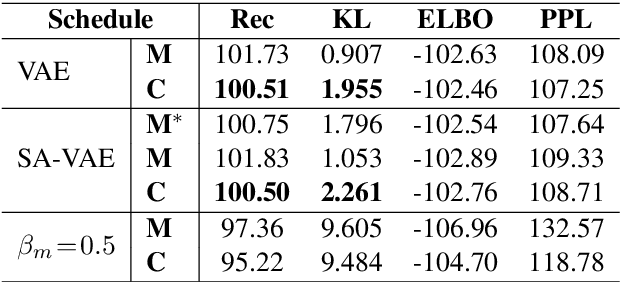
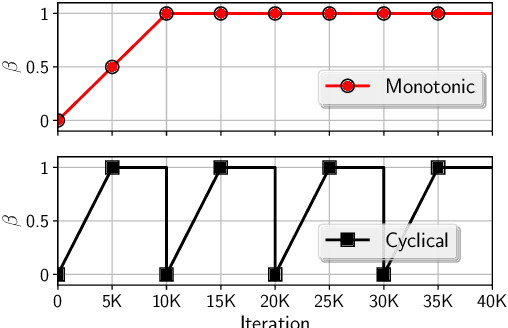

Variational autoencoders (VAEs) with an auto-regressive decoder have been applied for many natural language processing (NLP) tasks. The VAE objective consists of two terms, (i) reconstruction and (ii) KL regularization, balanced by a weighting hyper-parameter \beta. One notorious training difficulty is that the KL term tends to vanish. In this paper we study scheduling schemes for \beta, and show that KL vanishing is caused by the lack of good latent codes in training the decoder at the beginning of optimization. To remedy this, we propose a cyclical annealing schedule, which repeats the process of increasing \beta multiple times. This new procedure allows the progressive learning of more meaningful latent codes, by leveraging the informative representations of previous cycles as warm re-starts. The effectiveness of cyclical annealing is validated on a broad range of NLP tasks, including language modeling, dialog response generation and unsupervised language pre-training.
Topic-Guided Variational Autoencoders for Text Generation
Mar 17, 2019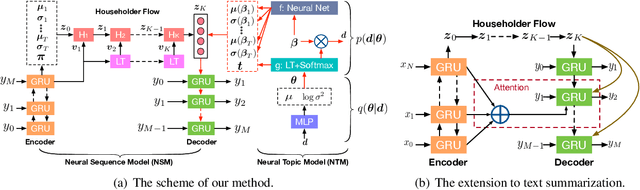

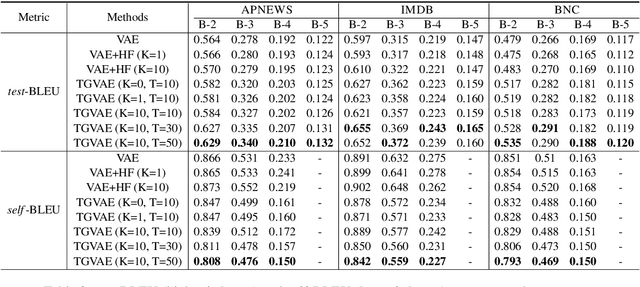
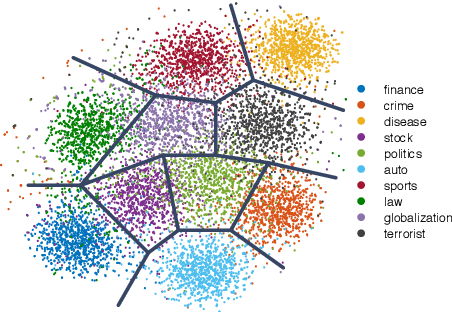
We propose a topic-guided variational autoencoder (TGVAE) model for text generation. Distinct from existing variational autoencoder (VAE) based approaches, which assume a simple Gaussian prior for the latent code, our model specifies the prior as a Gaussian mixture model (GMM) parametrized by a neural topic module. Each mixture component corresponds to a latent topic, which provides guidance to generate sentences under the topic. The neural topic module and the VAE-based neural sequence module in our model are learned jointly. In particular, a sequence of invertible Householder transformations is applied to endow the approximate posterior of the latent code with high flexibility during model inference. Experimental results show that our TGVAE outperforms alternative approaches on both unconditional and conditional text generation, which can generate semantically-meaningful sentences with various topics.
Scalable Thompson Sampling via Optimal Transport
Feb 19, 2019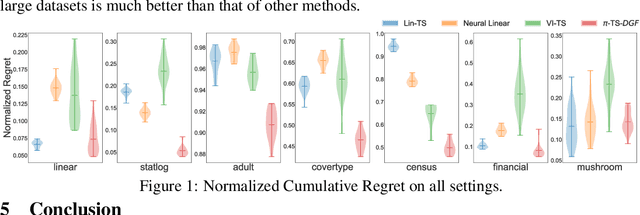
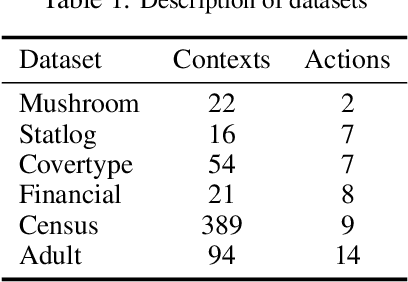
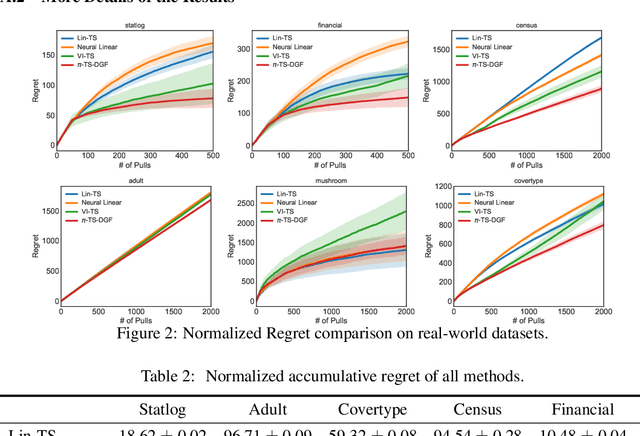

Thompson sampling (TS) is a class of algorithms for sequential decision-making, which requires maintaining a posterior distribution over a model. However, calculating exact posterior distributions is intractable for all but the simplest models. Consequently, efficient computation of an approximate posterior distribution is a crucial problem for scalable TS with complex models, such as neural networks. In this paper, we use distribution optimization techniques to approximate the posterior distribution, solved via Wasserstein gradient flows. Based on the framework, a principled particle-optimization algorithm is developed for TS to approximate the posterior efficiently. Our approach is scalable and does not make explicit distribution assumptions on posterior approximations. Extensive experiments on both synthetic data and real large-scale data demonstrate the superior performance of the proposed methods.
Towards Generating Long and Coherent Text with Multi-Level Latent Variable Models
Feb 01, 2019
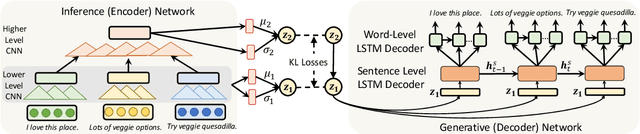
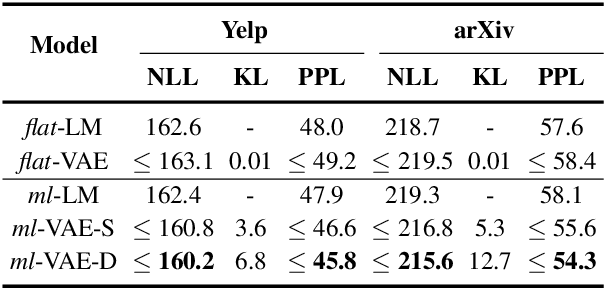
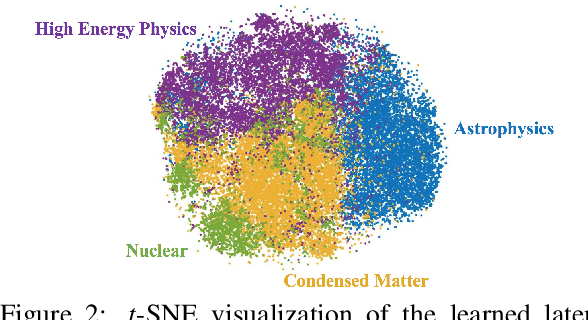
Variational autoencoders (VAEs) have received much attention recently as an end-to-end architecture for text generation with latent variables. In this paper, we investigate several multi-level structures to learn a VAE model to generate long, and coherent text. In particular, we use a hierarchy of stochastic layers between the encoder and decoder networks to generate more informative latent codes. We also investigate a multi-level decoder structure to learn a coherent long-term structure by generating intermediate sentence representations as high-level plan vectors. Empirical results demonstrate that a multi-level VAE model produces more coherent and less repetitive long text compared to the standard VAE models and can further mitigate the posterior-collapse issue.
Improving Sequence-to-Sequence Learning via Optimal Transport
Jan 18, 2019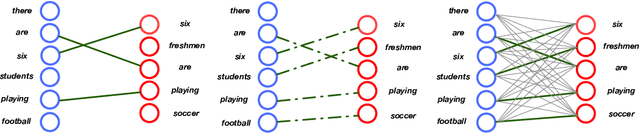
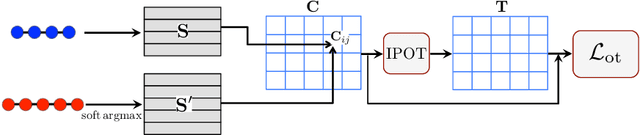
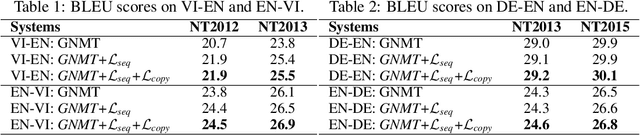
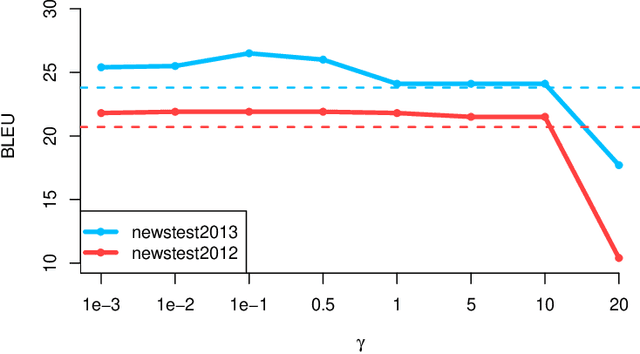
Sequence-to-sequence models are commonly trained via maximum likelihood estimation (MLE). However, standard MLE training considers a word-level objective, predicting the next word given the previous ground-truth partial sentence. This procedure focuses on modeling local syntactic patterns, and may fail to capture long-range semantic structure. We present a novel solution to alleviate these issues. Our approach imposes global sequence-level guidance via new supervision based on optimal transport, enabling the overall characterization and preservation of semantic features. We further show that this method can be understood as a Wasserstein gradient flow trying to match our model to the ground truth sequence distribution. Extensive experiments are conducted to validate the utility of the proposed approach, showing consistent improvements over a wide variety of NLP tasks, including machine translation, abstractive text summarization, and image captioning.