 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt-and-Transfer: Dynamic Class-aware Enhancement for Few-shot Segmentation
Sep 16, 2024For more efficient generalization to unseen domains (classes), most Few-shot Segmentation (FSS) would directly exploit pre-trained encoders and only fine-tune the decoder, especially in the current era of large models. However, such fixed feature encoders tend to be class-agnostic, inevitably activating objects that are irrelevant to the target class. In contrast, humans can effortlessly focus on specific objects in the line of sight. This paper mimics the visual perception pattern of human beings and proposes a novel and powerful prompt-driven scheme, called ``Prompt and Transfer" (PAT), which constructs a dynamic class-aware prompting paradigm to tune the encoder for focusing on the interested object (target class) in the current task. Three key points are elaborated to enhance the prompting: 1) Cross-modal linguistic information is introduced to initialize prompts for each task. 2) Semantic Prompt Transfer (SPT) that precisely transfers the class-specific semantics within the images to prompts. 3) Part Mask Generator (PMG) that works in conjunction with SPT to adaptively generate different but complementary part prompts for different individuals. Surprisingly, PAT achieves competitive performance on 4 different tasks including standard FSS, Cross-domain FSS (e.g., CV, medical, and remote sensing domains), Weak-label FSS, and Zero-shot Segmentation, setting new state-of-the-arts on 11 benchmarks.
AeroVerse: UAV-Agent Benchmark Suite for Simulating, Pre-training, Finetuning, and Evaluating Aerospace Embodied World Models
Aug 28, 2024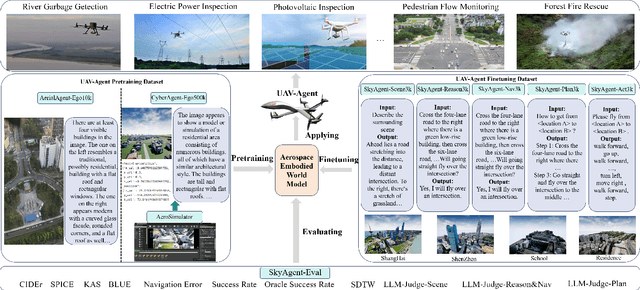
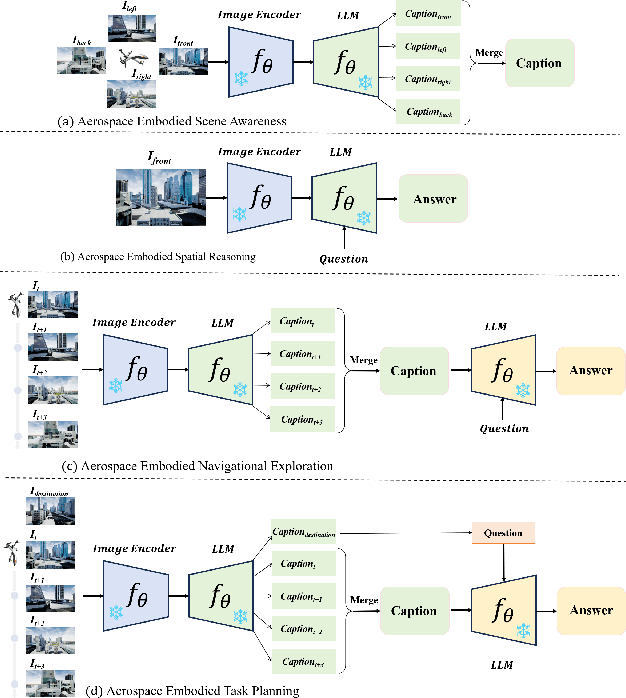

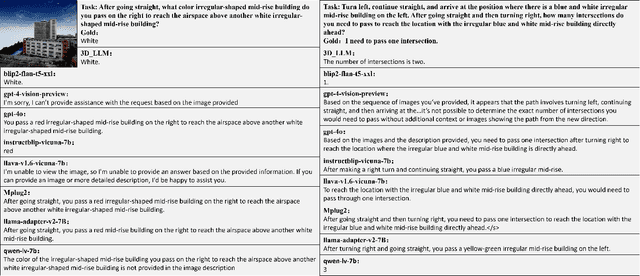
Aerospace embodied intelligence aims to empower unmanned aerial vehicles (UAVs) and other aerospace platforms to achieve autonomous perception, cognition, and action, as well as egocentric active interaction with humans and the environment. The aerospace embodied world model serves as an effective means to realize the autonomous intelligence of UAVs and represents a necessary pathway toward aerospace embodied intelligence. However, existing embodied world models primarily focus on ground-level intelligent agents in indoor scenarios, while research on UAV intelligent agents remains unexplored. To address this gap, we construct the first large-scale real-world image-text pre-training dataset, AerialAgent-Ego10k, featuring urban drones from a first-person perspective. We also create a virtual image-text-pose alignment dataset, CyberAgent Ego500k, to facilitate the pre-training of the aerospace embodied world model. For the first time, we clearly define 5 downstream tasks, i.e., aerospace embodied scene awareness, spatial reasoning, navigational exploration, task planning, and motion decision, and construct corresponding instruction datasets, i.e., SkyAgent-Scene3k, SkyAgent-Reason3k, SkyAgent-Nav3k and SkyAgent-Plan3k, and SkyAgent-Act3k, for fine-tuning the aerospace embodiment world model. Simultaneously, we develop SkyAgentEval, the downstream task evaluation metrics based on GPT-4, to comprehensively, flexibly, and objectively assess the results, revealing the potential and limitations of 2D/3D visual language models in UAV-agent tasks. Furthermore, we integrate over 10 2D/3D visual-language models, 2 pre-training datasets, 5 finetuning datasets, more than 10 evaluation metrics, and a simulator into the benchmark suite, i.e., AeroVerse, which will be released to the community to promote exploration and development of aerospace embodied intelligence.
Twin Deformable Point Convolutions for Point Cloud Semantic Segmentation in Remote Sensing Scenes
May 30, 2024



Thanks to the application of deep learning technology in point cloud processing of the remote sensing field, point cloud segmentation has become a research hotspot in recent years, which can be applied to real-world 3D, smart cities, and other fields. Although existing solutions have made unprecedented progress, they ignore the inherent characteristics of point clouds in remote sensing fields that are strictly arranged according to latitude, longitude, and altitude, which brings great convenience to the segmentation of point clouds in remote sensing fields. To consider this property cleverly, we propose novel convolution operators, termed Twin Deformable point Convolutions (TDConvs), which aim to achieve adaptive feature learning by learning deformable sampling points in the latitude-longitude plane and altitude direction, respectively. First, to model the characteristics of the latitude-longitude plane, we propose a Cylinder-wise Deformable point Convolution (CyDConv) operator, which generates a two-dimensional cylinder map by constructing a cylinder-like grid in the latitude-longitude direction. Furthermore, to better integrate the features of the latitude-longitude plane and the spatial geometric features, we perform a multi-scale fusion of the extracted latitude-longitude features and spatial geometric features, and realize it through the aggregation of adjacent point features of different scales. In addition, a Sphere-wise Deformable point Convolution (SpDConv) operator is introduced to adaptively offset the sampling points in three-dimensional space by constructing a sphere grid structure, aiming at modeling the characteristics in the altitude direction. Experiments on existing popular benchmarks conclude that our TDConvs achieve the best segmentation performance, surpassing the existing state-of-the-art methods.
SDL-MVS: View Space and Depth Deformable Learning Paradigm for Multi-View Stereo Reconstruction in Remote Sensing
May 27, 2024



Research on multi-view stereo based on remote sensing images has promoted the development of large-scale urban 3D reconstruction. However, remote sensing multi-view image data suffers from the problems of occlusion and uneven brightness between views during acquisition, which leads to the problem of blurred details in depth estimation. To solve the above problem, we re-examine the deformable learning method in the Multi-View Stereo task and propose a novel paradigm based on view Space and Depth deformable Learning (SDL-MVS), aiming to learn deformable interactions of features in different view spaces and deformably model the depth ranges and intervals to enable high accurate depth estimation. Specifically, to solve the problem of view noise caused by occlusion and uneven brightness, we propose a Progressive Space deformable Sampling (PSS) mechanism, which performs deformable learning of sampling points in the 3D frustum space and the 2D image space in a progressive manner to embed source features to the reference feature adaptively. To further optimize the depth, we introduce Depth Hypothesis deformable Discretization (DHD), which achieves precise positioning of the depth prior by adaptively adjusting the depth range hypothesis and performing deformable discretization of the depth interval hypothesis. Finally, our SDL-MVS achieves explicit modeling of occlusion and uneven brightness faced in multi-view stereo through the deformable learning paradigm of view space and depth, achieving accurate multi-view depth estimation. Extensive experiments on LuoJia-MVS and WHU datasets show that our SDL-MVS reaches state-of-the-art performance. It is worth noting that our SDL-MVS achieves an MAE error of 0.086, an accuracy of 98.9% for <0.6m, and 98.9% for <3-interval on the LuoJia-MVS dataset under the premise of three views as input.
TAFormer: A Unified Target-Aware Transformer for Video and Motion Joint Prediction in Aerial Scenes
Mar 27, 2024



As drone technology advances, using unmanned aerial vehicles for aerial surveys has become the dominant trend in modern low-altitude remote sensing. The surge in aerial video data necessitates accurate prediction for future scenarios and motion states of the interested target, particularly in applications like traffic management and disaster response. Existing video prediction methods focus solely on predicting future scenes (video frames), suffering from the neglect of explicitly modeling target's motion states, which is crucial for aerial video interpretation. To address this issue, we introduce a novel task called Target-Aware Aerial Video Prediction, aiming to simultaneously predict future scenes and motion states of the target. Further, we design a model specifically for this task, named TAFormer, which provides a unified modeling approach for both video and target motion states. Specifically, we introduce Spatiotemporal Attention (STA), which decouples the learning of video dynamics into spatial static attention and temporal dynamic attention, effectively modeling the scene appearance and motion. Additionally, we design an Information Sharing Mechanism (ISM), which elegantly unifies the modeling of video and target motion by facilitating information interaction through two sets of messenger tokens. Moreover, to alleviate the difficulty of distinguishing targets in blurry predictions, we introduce Target-Sensitive Gaussian Loss (TSGL), enhancing the model's sensitivity to both target's position and content. Extensive experiments on UAV123VP and VisDroneVP (derived from single-object tracking datasets) demonstrate the exceptional performance of TAFormer in target-aware video prediction, showcasing its adaptability to the additional requirements of aerial video interpretation for target awareness.
SFTformer: A Spatial-Frequency-Temporal Correlation-Decoupling Transformer for Radar Echo Extrapolation
Feb 28, 2024



Extrapolating future weather radar echoes from past observations is a complex task vital for precipitation nowcasting. The spatial morphology and temporal evolution of radar echoes exhibit a certain degree of correlation, yet they also possess independent characteristics. {Existing methods learn unified spatial and temporal representations in a highly coupled feature space, emphasizing the correlation between spatial and temporal features but neglecting the explicit modeling of their independent characteristics, which may result in mutual interference between them.} To effectively model the spatiotemporal dynamics of radar echoes, we propose a Spatial-Frequency-Temporal correlation-decoupling Transformer (SFTformer). The model leverages stacked multiple SFT-Blocks to not only mine the correlation of the spatiotemporal dynamics of echo cells but also avoid the mutual interference between the temporal modeling and the spatial morphology refinement by decoupling them. Furthermore, inspired by the practice that weather forecast experts effectively review historical echo evolution to make accurate predictions, SFTfomer incorporates a joint training paradigm for historical echo sequence reconstruction and future echo sequence prediction. Experimental results on the HKO-7 dataset and ChinaNorth-2021 dataset demonstrate the superior performance of SFTfomer in short(1h), mid(2h), and long-term(3h) precipitation nowcasting.
Recognizing Multiple Ingredients in Food Images Using a Single-Ingredient Classification Model
Jan 26, 2024Recognizing food images presents unique challenges due to the variable spatial layout and shape changes of ingredients with different cooking and cutting methods. This study introduces an advanced approach for recognizing ingredients segmented from food images. The method localizes the candidate regions of the ingredients using the locating and sliding window techniques. Then, these regions are assigned into ingredient classes using a CNN (Convolutional Neural Network)-based single-ingredient classification model trained on a dataset of single-ingredient images. To address the challenge of processing speed in multi-ingredient recognition, a novel model pruning method is proposed that enhances the efficiency of the classification model. Subsequently, the multi-ingredient identification is achieved through a decision-making scheme, incorporating two novel algorithms. The single-ingredient image dataset, designed in accordance with the book entitled "New Food Ingredients List FOODS 2021", encompasses 9982 images across 110 diverse categories, emphasizing variety in ingredient shapes. In addition, a multi-ingredient image dataset is developed to rigorously evaluate the performance of our approach. Experimental results validate the effectiveness of our method, particularly highlighting its improved capability in recognizing multiple ingredients. This marks a significant advancement in the field of food image analysis.
SPHR-SAR-Net: Superpixel High-resolution SAR Imaging Network Based on Nonlocal Total Variation
Apr 10, 2023



High-resolution is a key trend in the development of synthetic aperture radar (SAR), which enables the capture of fine details and accurate representation of backscattering properties. However, traditional high-resolution SAR imaging algorithms face several challenges. Firstly, these algorithms tend to focus on local information, neglecting non-local information between different pixel patches. Secondly, speckle is more pronounced and difficult to filter out in high-resolution SAR images. Thirdly, the process of high-resolution SAR imaging generally involves high time and computational complexity, making real-time imaging difficult to achieve. To address these issues, we propose a Superpixel High-Resolution SAR Imaging Network (SPHR-SAR-Net) for rapid despeckling in high-resolution SAR mode. Based on the concept of superpixel techniques, we initially combine non-convex and non-local total variation as compound regularization. This approach more effectively despeckles and manages the relationship between pixels while reducing bias effects caused by convex constraints. Subsequently, we solve the compound regularization model using the Alternating Direction Method of Multipliers (ADMM) algorithm and unfold it into a Deep Unfolded Network (DUN). The network's parameters are adaptively learned in a data-driven manner, and the learned network significantly increases imaging speed. Additionally, the Deep Unfolded Network is compatible with high-resolution imaging modes such as spotlight, staring spotlight, and sliding spotlight. In this paper, we demonstrate the superiority of SPHR-SAR-Net through experiments in both simulated and real SAR scenarios. The results indicate that SPHR-SAR-Net can rapidly perform high-resolution SAR imaging from raw echo data, producing accurate imaging results.
Elevation Estimation-Driven Building 3D Reconstruction from Single-View Remote Sensing Imagery
Jan 11, 2023



Building 3D reconstruction from remote sensing images has a wide range of applications in smart cities, photogrammetry and other fields. Methods for automatic 3D urban building modeling typically employ multi-view images as input to algorithms to recover point clouds and 3D models of buildings. However, such models rely heavily on multi-view images of buildings, which are time-intensive and limit the applicability and practicality of the models. To solve these issues, we focus on designing an efficient DSM estimation-driven reconstruction framework (Building3D), which aims to reconstruct 3D building models from the input single-view remote sensing image. First, we propose a Semantic Flow Field-guided DSM Estimation (SFFDE) network, which utilizes the proposed concept of elevation semantic flow to achieve the registration of local and global features. Specifically, in order to make the network semantics globally aware, we propose an Elevation Semantic Globalization (ESG) module to realize the semantic globalization of instances. Further, in order to alleviate the semantic span of global features and original local features, we propose a Local-to-Global Elevation Semantic Registration (L2G-ESR) module based on elevation semantic flow. Our Building3D is rooted in the SFFDE network for building elevation prediction, synchronized with a building extraction network for building masks, and then sequentially performs point cloud reconstruction, surface reconstruction (or CityGML model reconstruction). On this basis, our Building3D can optionally generate CityGML models or surface mesh models of the buildings. Extensive experiments on ISPRS Vaihingen and DFC2019 datasets on the DSM estimation task show that our SFFDE significantly improves upon state-of-the-arts. Furthermore, our Building3D achieves impressive results in the 3D point cloud and 3D model reconstruction process.
Breaking Immutable: Information-Coupled Prototype Elaboration for Few-Shot Object Detection
Nov 27, 2022



Few-shot object detection, expecting detectors to detect novel classes with a few instances, has made conspicuous progress. However, the prototypes extracted by existing meta-learning based methods still suffer from insufficient representative information and lack awareness of query images, which cannot be adaptively tailored to different query images. Firstly, only the support images are involved for extracting prototypes, resulting in scarce perceptual information of query images. Secondly, all pixels of all support images are treated equally when aggregating features into prototype vectors, thus the salient objects are overwhelmed by the cluttered background. In this paper, we propose an Information-Coupled Prototype Elaboration (ICPE) method to generate specific and representative prototypes for each query image. Concretely, a conditional information coupling module is introduced to couple information from the query branch to the support branch, strengthening the query-perceptual information in support features. Besides, we design a prototype dynamic aggregation module that dynamically adjusts intra-image and inter-image aggregation weights to highlight the salient information useful for detecting query images. Experimental results on both Pascal VOC and MS COCO demonstrate that our method achieves state-of-the-art performance in almost all settings.