 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Aggregation then Local Distribution in Fully Convolutional Networks
Sep 16, 2019
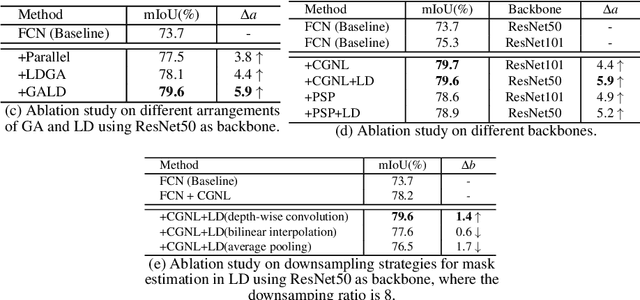
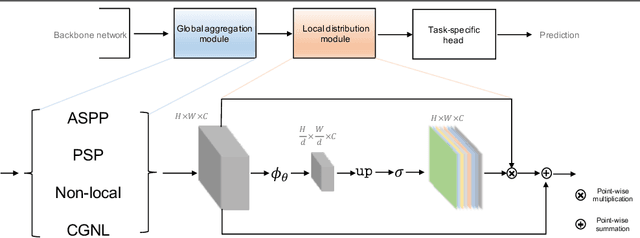

It has been widely proven that modelling long-range dependencies in fully convolutional networks (FCNs) via global aggregation modules is critical for complex scene understanding tasks such as semantic segmentation and object detection. However, global aggregation is often dominated by features of large patterns and tends to oversmooth regions that contain small patterns (e.g., boundaries and small objects). To resolve this problem, we propose to first use \emph{Global Aggregation} and then \emph{Local Distribution}, which is called GALD, where long-range dependencies are more confidently used inside large pattern regions and vice versa. The size of each pattern at each position is estimated in the network as a per-channel mask map. GALD is end-to-end trainable and can be easily plugged into existing FCNs with various global aggregation modules for a wide range of vision tasks, and consistently improves the performance of state-of-the-art object detection and instance segmentation approaches. In particular, GALD used in semantic segmentation achieves new state-of-the-art performance on Cityscapes test set with mIoU 83.3\%. Code is available at: \url{https://github.com/lxtGH/GALD-Net}
Dual Graph Convolutional Network for Semantic Segmentation
Sep 13, 2019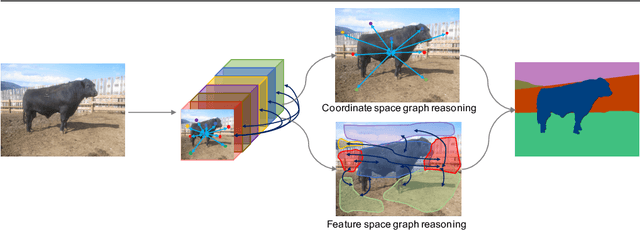

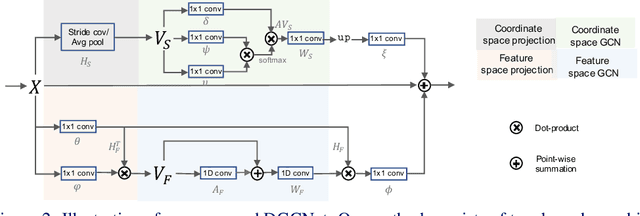

Exploiting long-range contextual information is key for pixel-wise prediction tasks such as semantic segmentation. In contrast to previous work that uses multi-scale feature fusion or dilated convolutions, we propose a novel graph-convolutional network (GCN) to address this problem. Our Dual Graph Convolutional Network (DGCNet) models the global context of the input feature by modelling two orthogonal graphs in a single framework. The first component models spatial relationships between pixels in the image, whilst the second models interdependencies along the channel dimensions of the network's feature map. This is done efficiently by projecting the feature into a new, lower-dimensional space where all pairwise interactions can be modelled, before reprojecting into the original space. Our simple method provides substantial benefits over a strong baseline and achieves state-of-the-art results on both Cityscapes (82.0\% mean IoU) and Pascal Context (53.7\% mean IoU) datasets.
Adaptive Unimodal Cost Volume Filtering for Deep Stereo Matching
Sep 09, 2019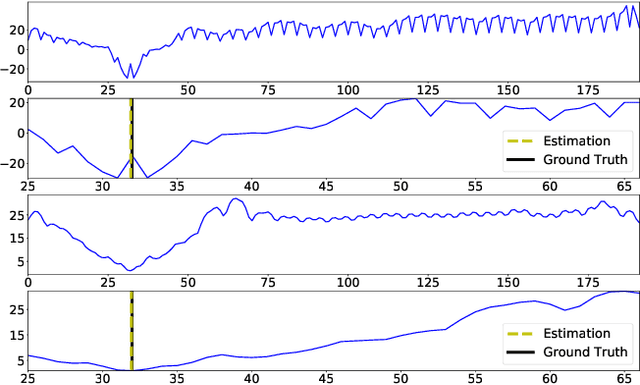
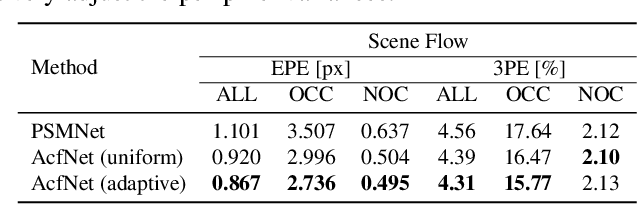
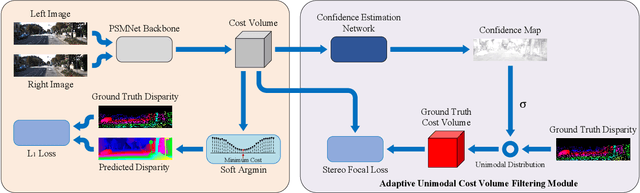
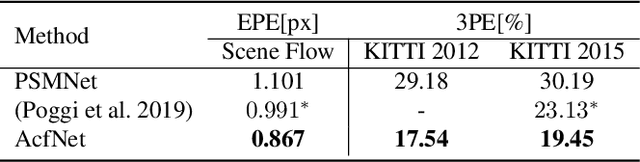
State-of-the-art deep learning based stereo matching approaches treat disparity estimation as a regression problem, where loss function is directly defined on true disparities and their estimated ones. However, disparity is just a byproduct of a matching process modeled by cost volume, while indirectly learning cost volume driven by disparity regression is prone to overfitting since cost volume is under constrained. In this paper, we propose to directly add constraints to the cost volume by filtering cost volume with unimodal distribution peaked at true disparities. In addition, variances of the unimodal distributions for each pixel are estimated to explicitly model matching uncertainty under different contexts. The proposed architecture achieves state-of-the-art performance on Scene Flow and two KITTI stereo benchmarks. In particular, our method ranked the $1^{st}$ place of KITTI 2012 evaluation and the $4^{th}$ place of KITTI 2015 evaluation (recorded on 2019.8.20).
GFF: Gated Fully Fusion for Semantic Segmentation
Apr 03, 2019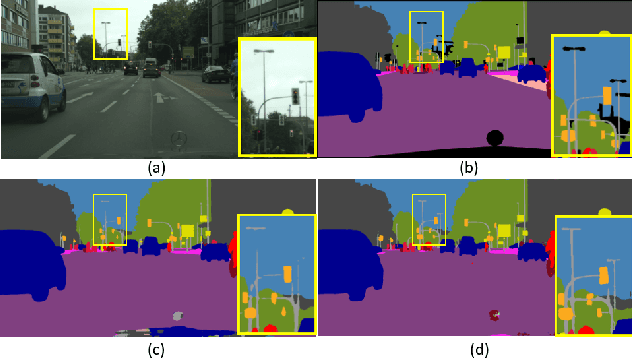
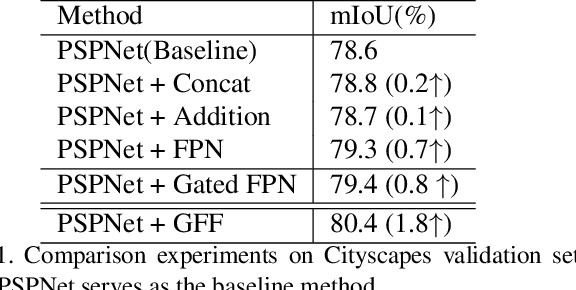
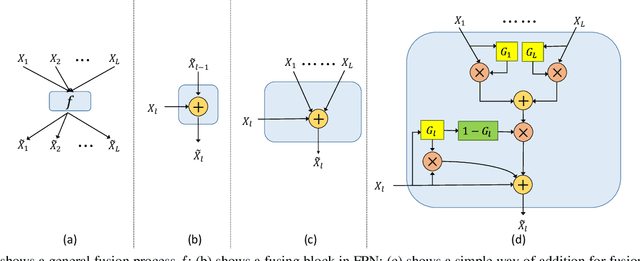
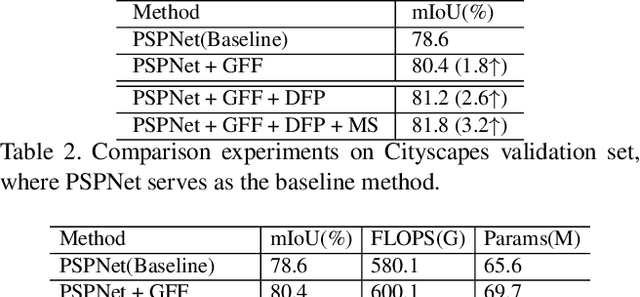
Semantic segmentation generates comprehensive understanding of scenes at a semantic level through densely predicting the category for each pixel. High-level features from Deep Convolutional Neural Networks already demonstrate their effectiveness in semantic segmentation tasks, however the coarse resolution of high-level features often leads to inferior results for small/thin objects where detailed information is important but missing. It is natural to consider importing low level features to compensate the lost detailed information in high level representations. Unfortunately, simply combining multi-level features is less effective due to the semantic gap existing among them. In this paper, we propose a new architecture, named Gated Fully Fusion(GFF), to selectively fuse features from multiple levels using gates in a fully connected way. Specifically, features at each level are enhanced by higher-level features with stronger semantics and lower-level features with more details, and gates are used to control the propagation of useful information which significantly reduces the noises during fusion. We achieve the state of the art results on two challenging scene understanding datasets, i.e., 82.3% mIoU on Cityscapes test set and 45.3% mIoU on ADE20K validation set. Codes and the trained models will be made publicly available.
Automatic Dataset Augmentation
Apr 16, 2018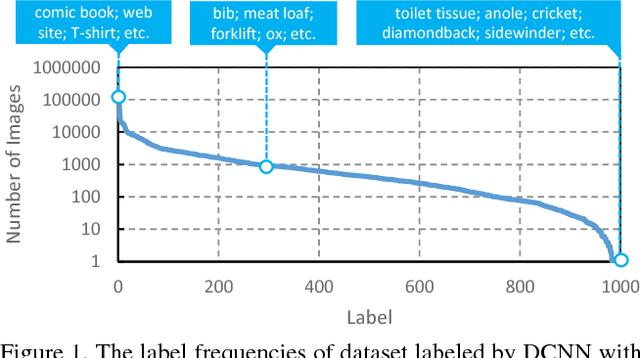
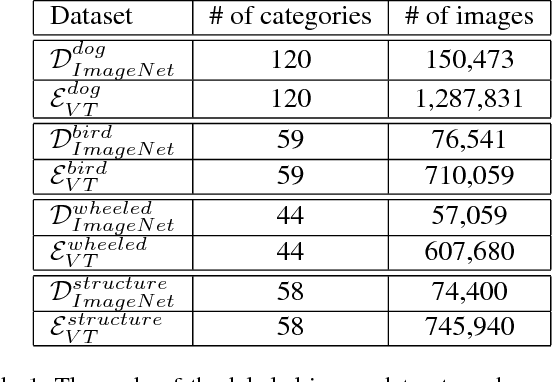
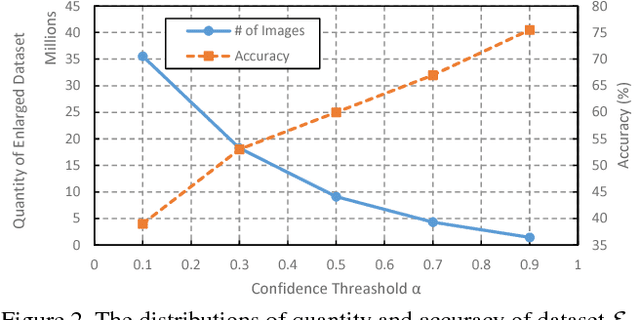
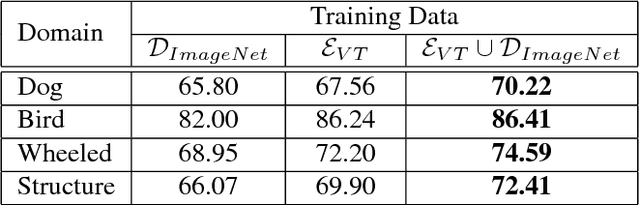
Large scale image dataset and deep convolutional neural network (DCNN) are two primary driving forces for the rapid progress made in generic object recognition tasks in recent years. While lots of network architectures have been continuously designed to pursue lower error rates, few efforts are devoted to enlarge existing datasets due to high labeling cost and unfair comparison issues. In this paper, we aim to achieve lower error rate by augmenting existing datasets in an automatic manner. Our method leverages both Web and DCNN, where Web provides massive images with rich contextual information, and DCNN replaces human to automatically label images under guidance of Web contextual information. Experiments show our method can automatically scale up existing datasets significantly from billions web pages with high accuracy, and significantly improve the performance on object recognition tasks by using the automatically augmented datasets, which demonstrates that more supervisory information has been automatically gathered from the Web. Both the dataset and models trained on the dataset are made publicly available.
Hard-Aware Deeply Cascaded Embedding
Aug 01, 2017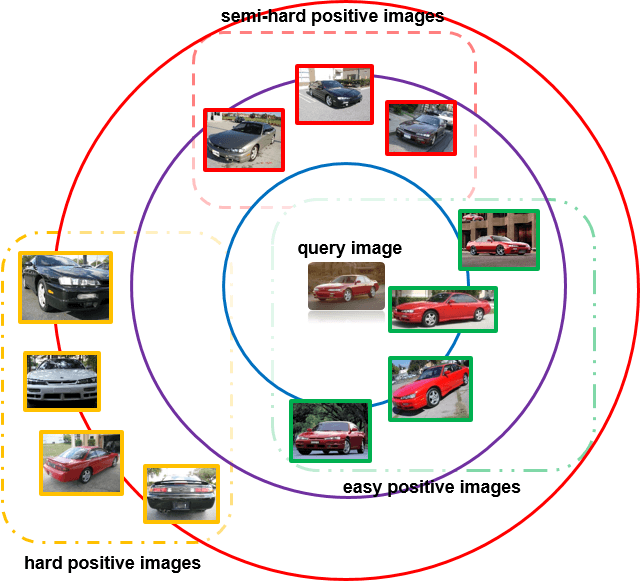
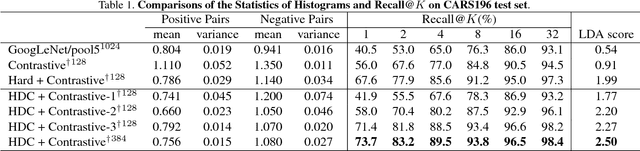


Riding on the waves of deep neural networks, deep metric learning has also achieved promising results in various tasks using triplet network or Siamese network. Though the basic goal of making images from the same category closer than the ones from different categories is intuitive, it is hard to directly optimize due to the quadratic or cubic sample size. To solve the problem, hard example mining which only focuses on a subset of samples that are considered hard is widely used. However, hard is defined relative to a model, where complex models treat most samples as easy ones and vice versa for simple models, and both are not good for training. Samples are also with different hard levels, it is hard to define a model with the just right complexity and choose hard examples adequately. This motivates us to ensemble a set of models with different complexities in cascaded manner and mine hard examples adaptively, a sample is judged by a series of models with increasing complexities and only updates models that consider the sample as a hard case. We evaluate our method on CARS196, CUB-200-2011, Stanford Online Products, VehicleID and DeepFashion datasets. Our method outperforms state-of-the-art methods by a large margin.
Feature Incay for Representation Regularization
May 29, 2017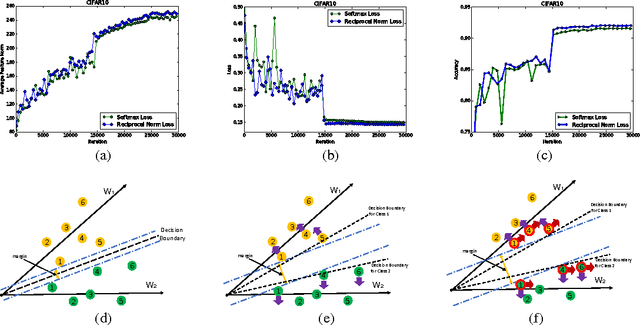
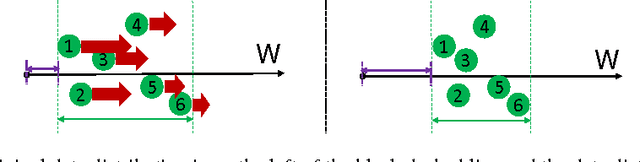
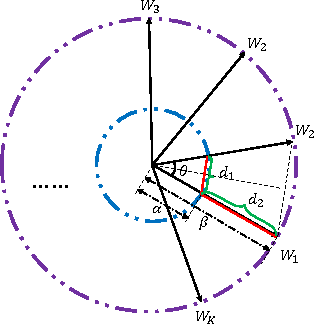
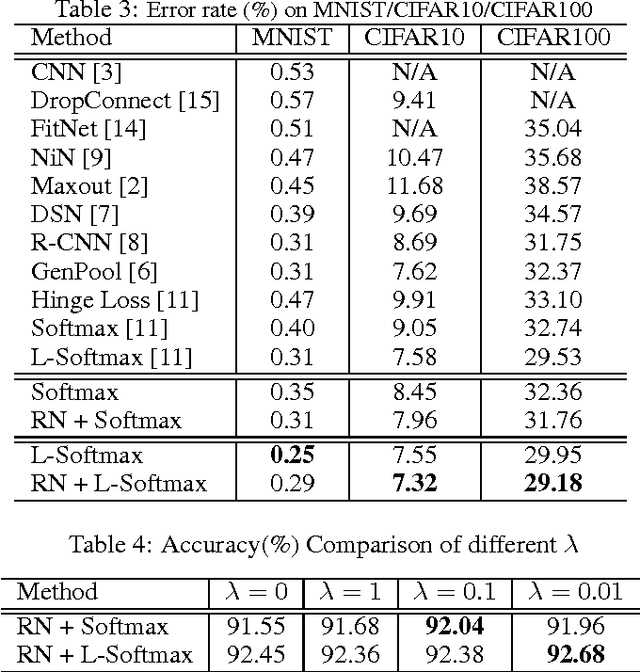
Softmax loss is widely used in deep neural networks for multi-class classification, where each class is represented by a weight vector, a sample is represented as a feature vector, and the feature vector has the largest projection on the weight vector of the correct category when the model correctly classifies a sample. To ensure generalization, weight decay that shrinks the weight norm is often used as regularizer. Different from traditional learning algorithms where features are fixed and only weights are tunable, features are also tunable as representation learning in deep learning. Thus, we propose feature incay to also regularize representation learning, which favors feature vectors with large norm when the samples can be correctly classified. With the feature incay, feature vectors are further pushed away from the origin along the direction of their corresponding weight vectors, which achieves better inter-class separability. In addition, the proposed feature incay encourages intra-class compactness along the directions of weight vectors by increasing the small feature norm faster than the large ones. Empirical results on MNIST, CIFAR10 and CIFAR100 demonstrate feature incay can improve the generalization ability.
Visualizing and Comparing Convolutional Neural Networks
Dec 26, 2014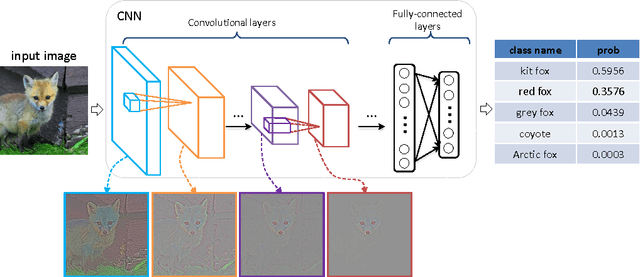
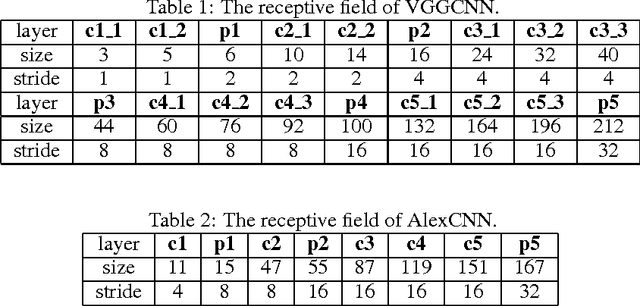
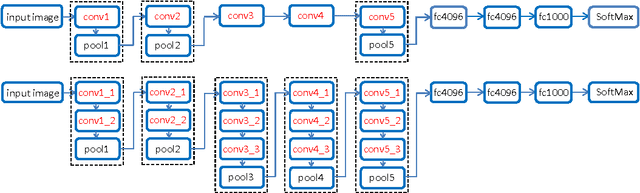

Convolutional Neural Networks (CNNs) have achieved comparable error rates to well-trained human on ILSVRC2014 image classification task. To achieve better performance, the complexity of CNNs is continually increasing with deeper and bigger architectures. Though CNNs achieved promising external classification behavior, understanding of their internal work mechanism is still limited. In this work, we attempt to understand the internal work mechanism of CNNs by probing the internal representations in two comprehensive aspects, i.e., visualizing patches in the representation spaces constructed by different layers, and visualizing visual information kept in each layer. We further compare CNNs with different depths and show the advantages brought by deeper architecture.
The Application of Two-level Attention Models in Deep Convolutional Neural Network for Fine-grained Image Classification
Nov 24, 2014
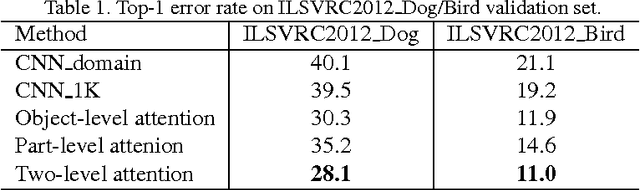
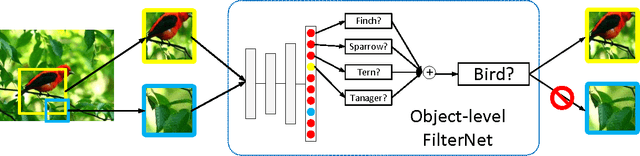
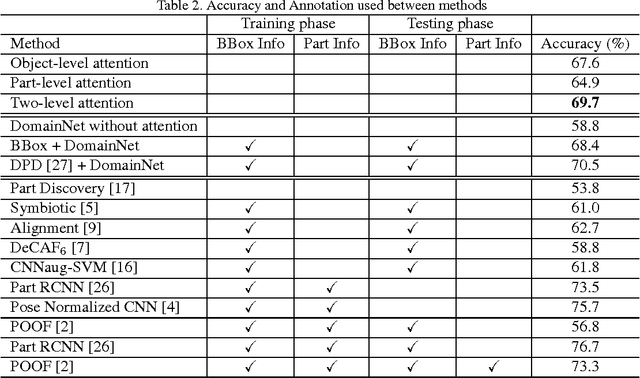
Fine-grained classification is challenging because categories can only be discriminated by subtle and local differences. Variances in the pose, scale or rotation usually make the problem more difficult. Most fine-grained classification systems follow the pipeline of finding foreground object or object parts (where) to extract discriminative features (what). In this paper, we propose to apply visual attention to fine-grained classification task using deep neural network. Our pipeline integrates three types of attention: the bottom-up attention that propose candidate patches, the object-level top-down attention that selects relevant patches to a certain object, and the part-level top-down attention that localizes discriminative parts. We combine these attentions to train domain-specific deep nets, then use it to improve both the what and where aspects. Importantly, we avoid using expensive annotations like bounding box or part information from end-to-end. The weak supervision constraint makes our work easier to generalize. We have verified the effectiveness of the method on the subsets of ILSVRC2012 dataset and CUB200_2011 dataset. Our pipeline delivered significant improvements and achieved the best accuracy under the weakest supervision condition. The performance is competitive against other methods that rely on additional annotations.
Scale-Invariant Convolutional Neural Networks
Nov 24, 2014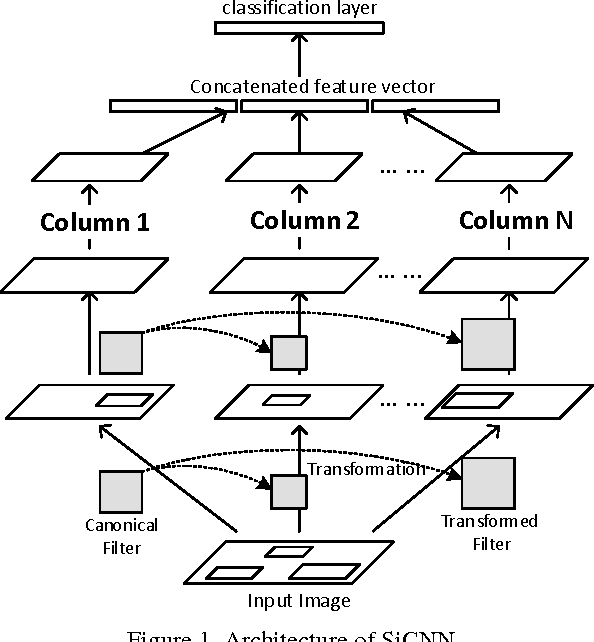

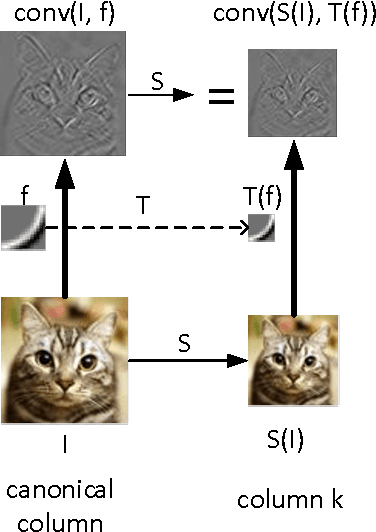
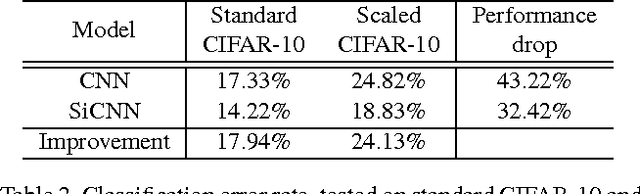
Even though convolutional neural networks (CNN) has achieved near-human performance in various computer vision tasks, its ability to tolerate scale variations is limited. The popular practise is making the model bigger first, and then train it with data augmentation using extensive scale-jittering. In this paper, we propose a scaleinvariant convolutional neural network (SiCNN), a modeldesigned to incorporate multi-scale feature exaction and classification into the network structure. SiCNN uses a multi-column architecture, with each column focusing on a particular scale. Unlike previous multi-column strategies, these columns share the same set of filter parameters by a scale transformation among them. This design deals with scale variation without blowing up the model size. Experimental results show that SiCNN detects features at various scales, and the classification result exhibits strong robustness against object scale variations.