 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizable Neural Fields as Partially Observed Neural Processes
Sep 13, 2023Neural fields, which represent signals as a function parameterized by a neural network, are a promising alternative to traditional discrete vector or grid-based representations. Compared to discrete representations, neural representations both scale well with increasing resolution, are continuous, and can be many-times differentiable. However, given a dataset of signals that we would like to represent, having to optimize a separate neural field for each signal is inefficient, and cannot capitalize on shared information or structures among signals. Existing generalization methods view this as a meta-learning problem and employ gradient-based meta-learning to learn an initialization which is then fine-tuned with test-time optimization, or learn hypernetworks to produce the weights of a neural field. We instead propose a new paradigm that views the large-scale training of neural representations as a part of a partially-observed neural process framework, and leverage neural process algorithms to solve this task. We demonstrate that this approach outperforms both state-of-the-art gradient-based meta-learning approaches and hypernetwork approaches.
LOVM: Language-Only Vision Model Selection
Jun 15, 2023Pre-trained multi-modal vision-language models (VLMs) are becoming increasingly popular due to their exceptional performance on downstream vision applications, particularly in the few- and zero-shot settings. However, selecting the best-performing VLM for some downstream applications is non-trivial, as it is dataset and task-dependent. Meanwhile, the exhaustive evaluation of all available VLMs on a novel application is not only time and computationally demanding but also necessitates the collection of a labeled dataset for evaluation. As the number of open-source VLM variants increases, there is a need for an efficient model selection strategy that does not require access to a curated evaluation dataset. This paper proposes a novel task and benchmark for efficiently evaluating VLMs' zero-shot performance on downstream applications without access to the downstream task dataset. Specifically, we introduce a new task LOVM: Language-Only Vision Model Selection, where methods are expected to perform both model selection and performance prediction based solely on a text description of the desired downstream application. We then introduced an extensive LOVM benchmark consisting of ground-truth evaluations of 35 pre-trained VLMs and 23 datasets, where methods are expected to rank the pre-trained VLMs and predict their zero-shot performance.
Diagnosing and Rectifying Vision Models using Language
Feb 08, 2023



Recent multi-modal contrastive learning models have demonstrated the ability to learn an embedding space suitable for building strong vision classifiers, by leveraging the rich information in large-scale image-caption datasets. Our work highlights a distinct advantage of this multi-modal embedding space: the ability to diagnose vision classifiers through natural language. The traditional process of diagnosing model behaviors in deployment settings involves labor-intensive data acquisition and annotation. Our proposed method can discover high-error data slices, identify influential attributes and further rectify undesirable model behaviors, without requiring any visual data. Through a combination of theoretical explanation and empirical verification, we present conditions under which classifiers trained on embeddings from one modality can be equivalently applied to embeddings from another modality. On a range of image datasets with known error slices, we demonstrate that our method can effectively identify the error slices and influential attributes, and can further use language to rectify failure modes of the classifier.
NeMo: 3D Neural Motion Fields from Multiple Video Instances of the Same Action
Dec 28, 2022The task of reconstructing 3D human motion has wideranging applications. The gold standard Motion capture (MoCap) systems are accurate but inaccessible to the general public due to their cost, hardware and space constraints. In contrast, monocular human mesh recovery (HMR) methods are much more accessible than MoCap as they take single-view videos as inputs. Replacing the multi-view Mo- Cap systems with a monocular HMR method would break the current barriers to collecting accurate 3D motion thus making exciting applications like motion analysis and motiondriven animation accessible to the general public. However, performance of existing HMR methods degrade when the video contains challenging and dynamic motion that is not in existing MoCap datasets used for training. This reduces its appeal as dynamic motion is frequently the target in 3D motion recovery in the aforementioned applications. Our study aims to bridge the gap between monocular HMR and multi-view MoCap systems by leveraging information shared across multiple video instances of the same action. We introduce the Neural Motion (NeMo) field. It is optimized to represent the underlying 3D motions across a set of videos of the same action. Empirically, we show that NeMo can recover 3D motion in sports using videos from the Penn Action dataset, where NeMo outperforms existing HMR methods in terms of 2D keypoint detection. To further validate NeMo using 3D metrics, we collected a small MoCap dataset mimicking actions in Penn Action,and show that NeMo achieves better 3D reconstruction compared to various baselines.
PROB: Probabilistic Objectness for Open World Object Detection
Dec 02, 2022



Open World Object Detection (OWOD) is a new and challenging computer vision task that bridges the gap between classic object detection (OD) benchmarks and object detection in the real world. In addition to detecting and classifying seen/labeled objects, OWOD algorithms are expected to detect novel/unknown objects - which can be classified and incrementally learned. In standard OD, object proposals not overlapping with a labeled object are automatically classified as background. Therefore, simply applying OD methods to OWOD fails as unknown objects would be predicted as background. The challenge of detecting unknown objects stems from the lack of supervision in distinguishing unknown objects and background object proposals. Previous OWOD methods have attempted to overcome this issue by generating supervision using pseudo-labeling - however, unknown object detection has remained low. Probabilistic/generative models may provide a solution for this challenge. Herein, we introduce a novel probabilistic framework for objectness estimation, where we alternate between probability distribution estimation and objectness likelihood maximization of known objects in the embedded feature space - ultimately allowing us to estimate the objectness probability of different proposals. The resulting Probabilistic Objectness transformer-based open-world detector, PROB, integrates our framework into traditional object detection models, adapting them for the open-world setting. Comprehensive experiments on OWOD benchmarks show that PROB outperforms all existing OWOD methods in both unknown object detection ($\sim 2\times$ unknown recall) and known object detection ($\sim 10\%$ mAP). Our code will be made available upon publication at https://github.com/orrzohar/PROB.
Domain Adaptive 3D Pose Augmentation for In-the-wild Human Mesh Recovery
Jun 21, 2022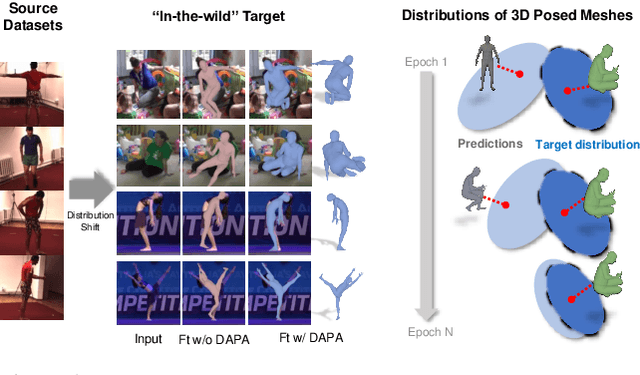
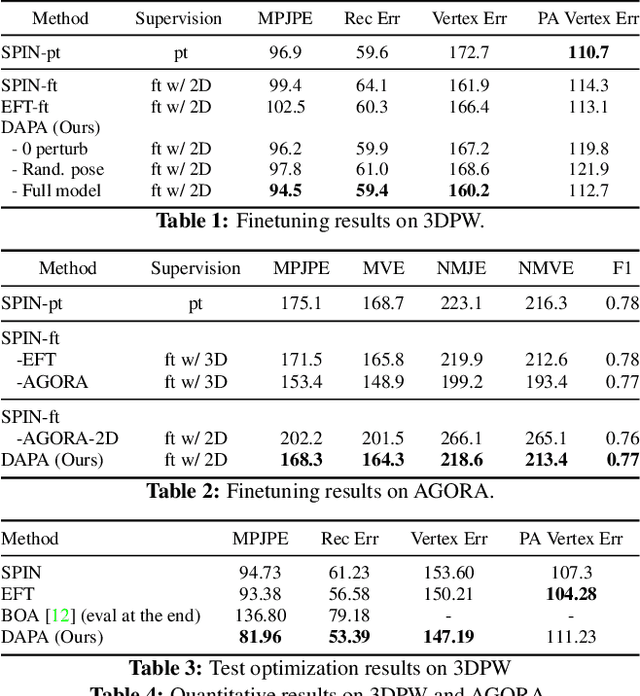
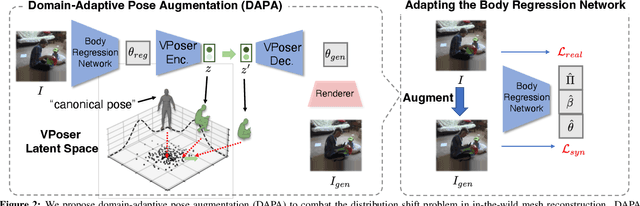

The ability to perceive 3D human bodies from a single image has a multitude of applications ranging from entertainment and robotics to neuroscience and healthcare. A fundamental challenge in human mesh recovery is in collecting the ground truth 3D mesh targets required for training, which requires burdensome motion capturing systems and is often limited to indoor laboratories. As a result, while progress is made on benchmark datasets collected in these restrictive settings, models fail to generalize to real-world ``in-the-wild'' scenarios due to distribution shifts. We propose Domain Adaptive 3D Pose Augmentation (DAPA), a data augmentation method that enhances the model's generalization ability in in-the-wild scenarios. DAPA combines the strength of methods based on synthetic datasets by getting direct supervision from the synthesized meshes, and domain adaptation methods by using ground truth 2D keypoints from the target dataset. We show quantitatively that finetuning with DAPA effectively improves results on benchmarks 3DPW and AGORA. We further demonstrate the utility of DAPA on a challenging dataset curated from videos of real-world parent-child interaction.
Grad2Task: Improved Few-shot Text Classification Using Gradients for Task Representation
Jan 27, 2022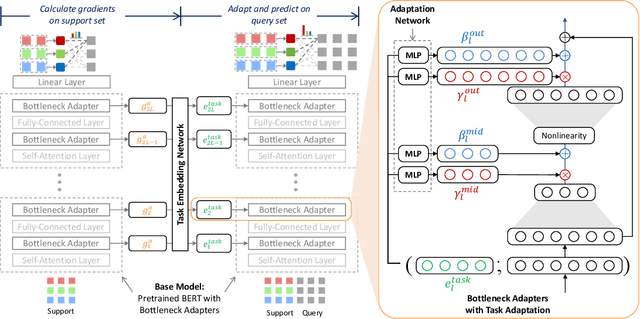
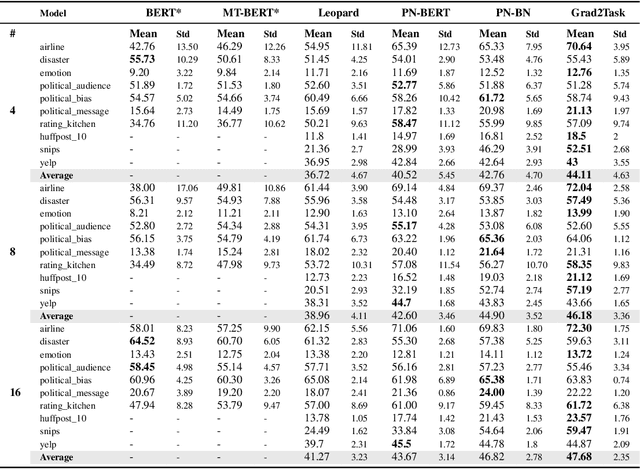
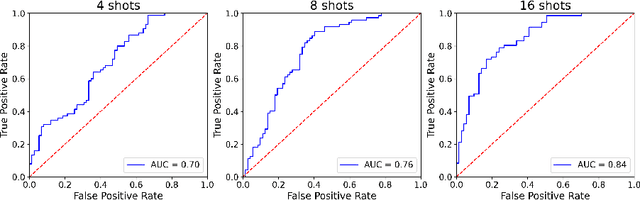
Large pretrained language models (LMs) like BERT have improved performance in many disparate natural language processing (NLP) tasks. However, fine tuning such models requires a large number of training examples for each target task. Simultaneously, many realistic NLP problems are "few shot", without a sufficiently large training set. In this work, we propose a novel conditional neural process-based approach for few-shot text classification that learns to transfer from other diverse tasks with rich annotation. Our key idea is to represent each task using gradient information from a base model and to train an adaptation network that modulates a text classifier conditioned on the task representation. While previous task-aware few-shot learners represent tasks by input encoding, our novel task representation is more powerful, as the gradient captures input-output relationships of a task. Experimental results show that our approach outperforms traditional fine-tuning, sequential transfer learning, and state-of-the-art meta learning approaches on a collection of diverse few-shot tasks. We further conducted analysis and ablations to justify our design choices.
Variational Model Inversion Attacks
Jan 26, 2022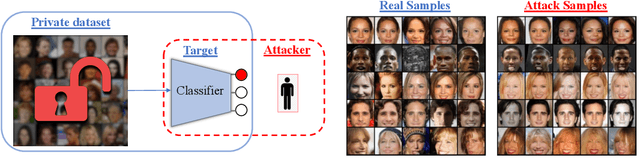
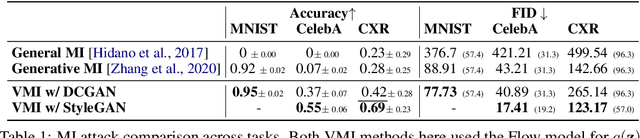

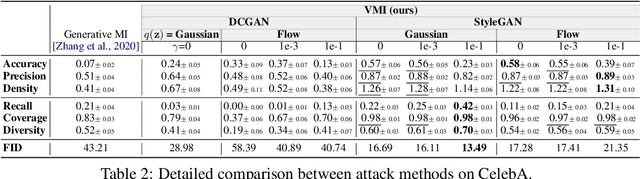
Given the ubiquity of deep neural networks, it is important that these models do not reveal information about sensitive data that they have been trained on. In model inversion attacks, a malicious user attempts to recover the private dataset used to train a supervised neural network. A successful model inversion attack should generate realistic and diverse samples that accurately describe each of the classes in the private dataset. In this work, we provide a probabilistic interpretation of model inversion attacks, and formulate a variational objective that accounts for both diversity and accuracy. In order to optimize this variational objective, we choose a variational family defined in the code space of a deep generative model, trained on a public auxiliary dataset that shares some structural similarity with the target dataset. Empirically, our method substantially improves performance in terms of target attack accuracy, sample realism, and diversity on datasets of faces and chest X-ray images.
Disentanglement and Generalization Under Correlation Shifts
Dec 29, 2021
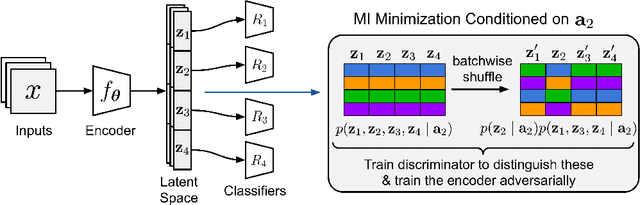
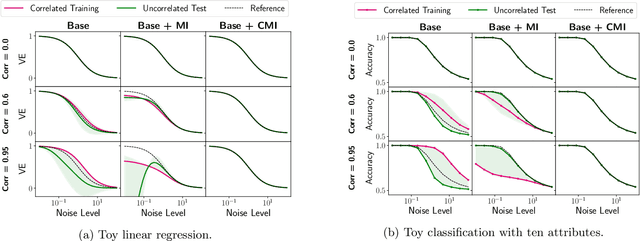

Correlations between factors of variation are prevalent in real-world data. Machine learning algorithms may benefit from exploiting such correlations, as they can increase predictive performance on noisy data. However, often such correlations are not robust (e.g., they may change between domains, datasets, or applications) and we wish to avoid exploiting them. Disentanglement methods aim to learn representations which capture different factors of variation in latent subspaces. A common approach involves minimizing the mutual information between latent subspaces, such that each encodes a single underlying attribute. However, this fails when attributes are correlated. We solve this problem by enforcing independence between subspaces conditioned on the available attributes, which allows us to remove only dependencies that are not due to the correlation structure present in the training data. We achieve this via an adversarial approach to minimize the conditional mutual information (CMI) between subspaces with respect to categorical variables. We first show theoretically that CMI minimization is a good objective for robust disentanglement on linear problems with Gaussian data. We then apply our method on real-world datasets based on MNIST and CelebA, and show that it yields models that are disentangled and robust under correlation shift, including in weakly supervised settings.
Flexible Few-Shot Learning with Contextual Similarity
Dec 10, 2020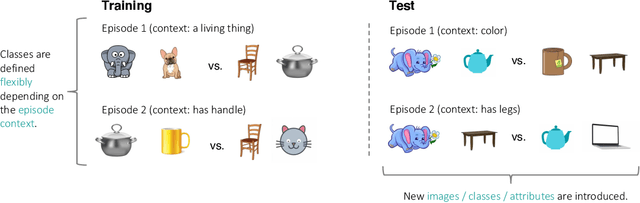


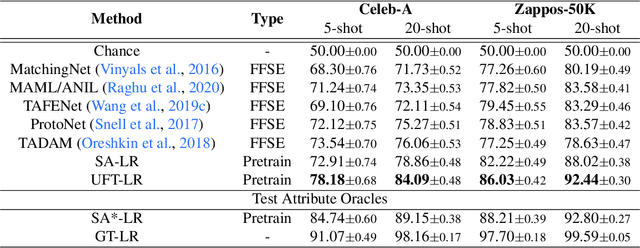
Existing approaches to few-shot learning deal with tasks that have persistent, rigid notions of classes. Typically, the learner observes data only from a fixed number of classes at training time and is asked to generalize to a new set of classes at test time. Two examples from the same class would always be assigned the same labels in any episode. In this work, we consider a realistic setting where the similarities between examples can change from episode to episode depending on the task context, which is not given to the learner. We define new benchmark datasets for this flexible few-shot scenario, where the tasks are based on images of faces (Celeb-A), shoes (Zappos50K), and general objects (ImageNet-with-Attributes). While classification baselines and episodic approaches learn representations that work well for standard few-shot learning, they suffer in our flexible tasks as novel similarity definitions arise during testing. We propose to build upon recent contrastive unsupervised learning techniques and use a combination of instance and class invariance learning, aiming to obtain general and flexible features. We find that our approach performs strongly on our new flexible few-shot learning benchmarks, demonstrating that unsupervised learning obtains more generalizable representations.