 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolyViT: Co-training Vision Transformers on Images, Videos and Audio
Nov 25, 2021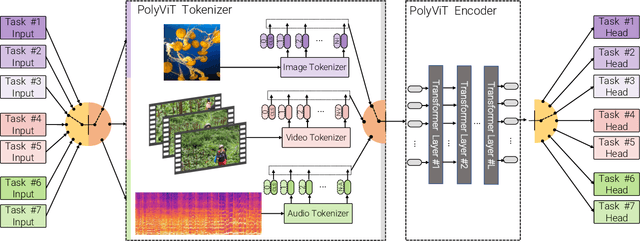
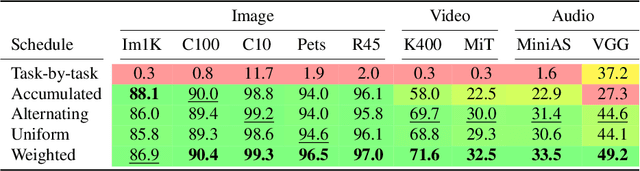
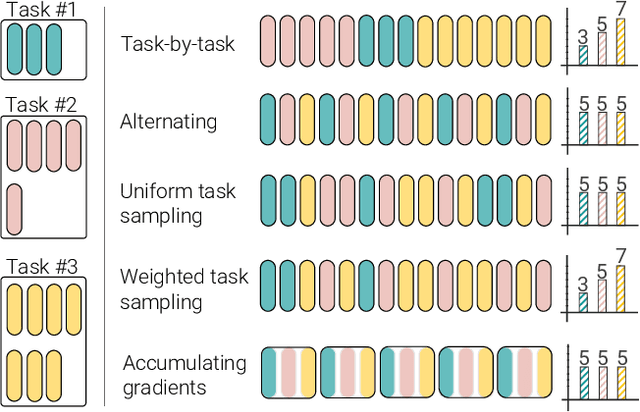
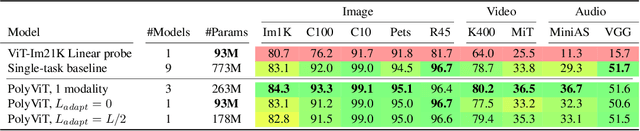
Can we train a single transformer model capable of processing multiple modalities and datasets, whilst sharing almost all of its learnable parameters? We present PolyViT, a model trained on image, audio and video which answers this question. By co-training different tasks on a single modality, we are able to improve the accuracy of each individual task and achieve state-of-the-art results on 5 standard video- and audio-classification datasets. Co-training PolyViT on multiple modalities and tasks leads to a model that is even more parameter-efficient, and learns representations that generalize across multiple domains. Moreover, we show that co-training is simple and practical to implement, as we do not need to tune hyperparameters for each combination of datasets, but can simply adapt those from standard, single-task training.
Hybrid Random Features
Oct 13, 2021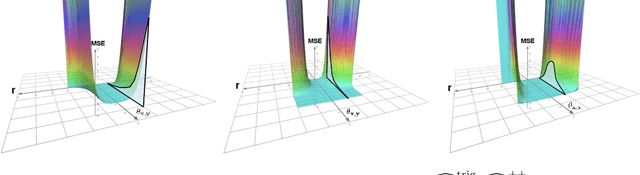
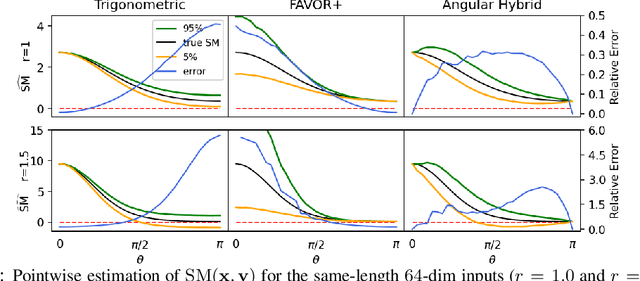
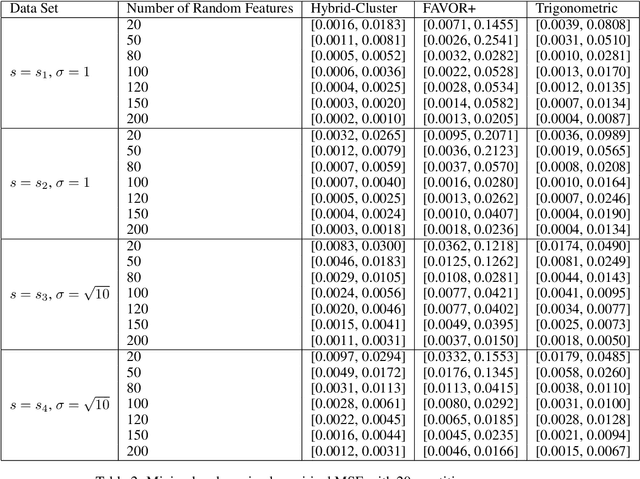
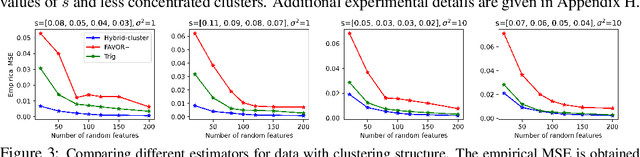
We propose a new class of random feature methods for linearizing softmax and Gaussian kernels called hybrid random features (HRFs) that automatically adapt the quality of kernel estimation to provide most accurate approximation in the defined regions of interest. Special instantiations of HRFs lead to well-known methods such as trigonometric (Rahimi and Recht, 2007) or (recently introduced in the context of linear-attention Transformers) positive random features (Choromanski et al., 2021). By generalizing Bochner's Theorem for softmax/Gaussian kernels and leveraging random features for compositional kernels, the HRF-mechanism provides strong theoretical guarantees - unbiased approximation and strictly smaller worst-case relative errors than its counterparts. We conduct exhaustive empirical evaluation of HRF ranging from pointwise kernel estimation experiments, through tests on data admitting clustering structure to benchmarking implicit-attention Transformers (also for downstream Robotics applications), demonstrating its quality in a wide spectrum of machine learning problems.
Graph Kernel Attention Transformers
Jul 16, 2021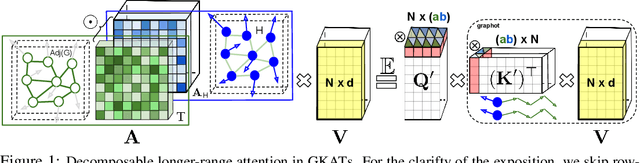
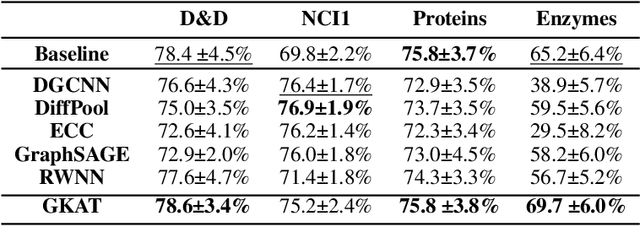
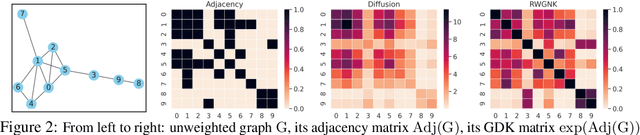

We introduce a new class of graph neural networks (GNNs), by combining several concepts that were so far studied independently - graph kernels, attention-based networks with structural priors and more recently, efficient Transformers architectures applying small memory footprint implicit attention methods via low rank decomposition techniques. The goal of the paper is twofold. Proposed by us Graph Kernel Attention Transformers (or GKATs) are much more expressive than SOTA GNNs as capable of modeling longer-range dependencies within a single layer. Consequently, they can use more shallow architecture design. Furthermore, GKAT attention layers scale linearly rather than quadratically in the number of nodes of the input graphs, even when those graphs are dense, requiring less compute than their regular graph attention counterparts. They achieve it by applying new classes of graph kernels admitting random feature map decomposition via random walks on graphs. As a byproduct of the introduced techniques, we obtain a new class of learnable graph sketches, called graphots, compactly encoding topological graph properties as well as nodes' features. We conducted exhaustive empirical comparison of our method with nine different GNN classes on tasks ranging from motif detection through social network classification to bioinformatics challenges, showing consistent gains coming from GKATs.
Debiasing a First-order Heuristic for Approximate Bi-level Optimization
Jun 08, 2021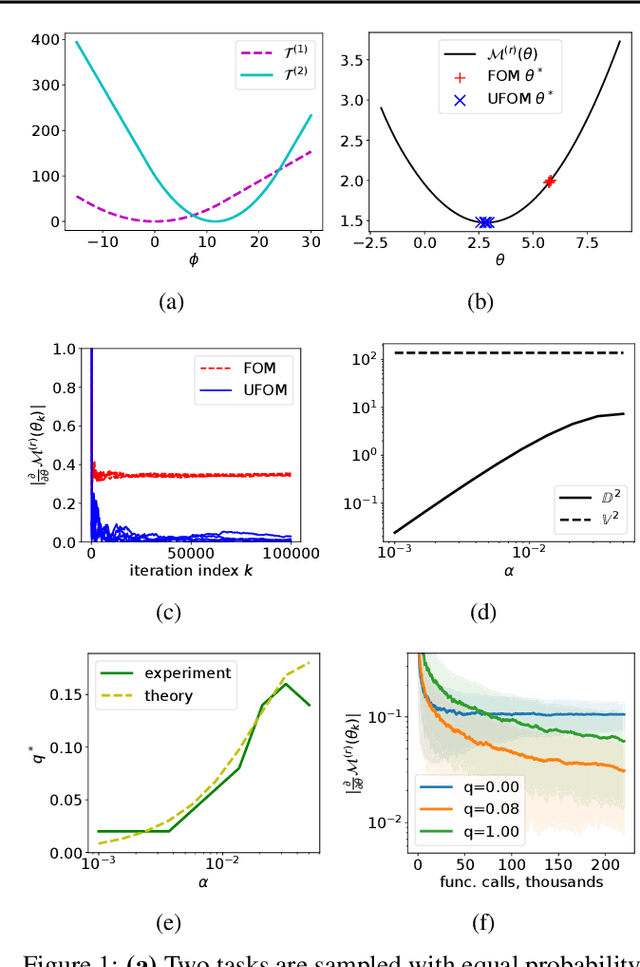
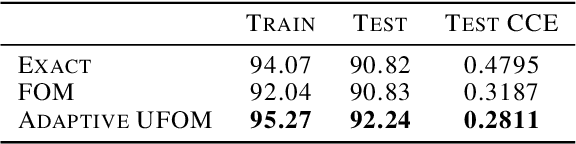
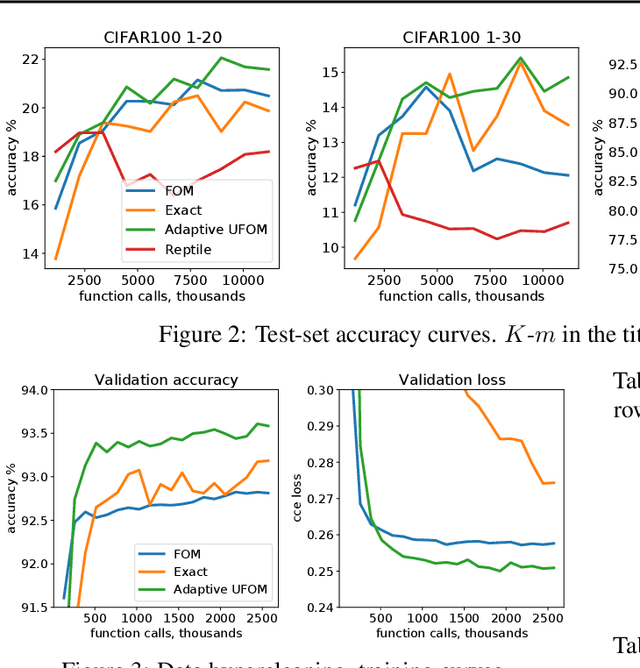
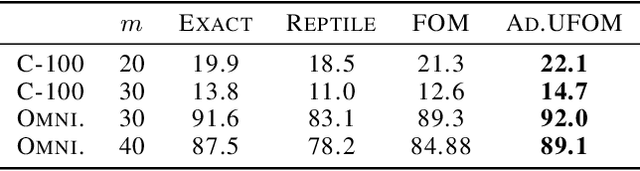
Approximate bi-level optimization (ABLO) consists of (outer-level) optimization problems, involving numerical (inner-level) optimization loops. While ABLO has many applications across deep learning, it suffers from time and memory complexity proportional to the length $r$ of its inner optimization loop. To address this complexity, an earlier first-order method (FOM) was proposed as a heuristic that omits second derivative terms, yielding significant speed gains and requiring only constant memory. Despite FOM's popularity, there is a lack of theoretical understanding of its convergence properties. We contribute by theoretically characterizing FOM's gradient bias under mild assumptions. We further demonstrate a rich family of examples where FOM-based SGD does not converge to a stationary point of the ABLO objective. We address this concern by proposing an unbiased FOM (UFOM) enjoying constant memory complexity as a function of $r$. We characterize the introduced time-variance tradeoff, demonstrate convergence bounds, and find an optimal UFOM for a given ABLO problem. Finally, we propose an efficient adaptive UFOM scheme.
On the Expressive Power of Self-Attention Matrices
Jun 08, 2021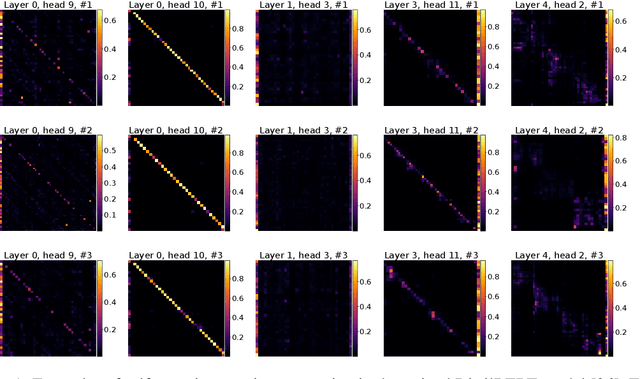
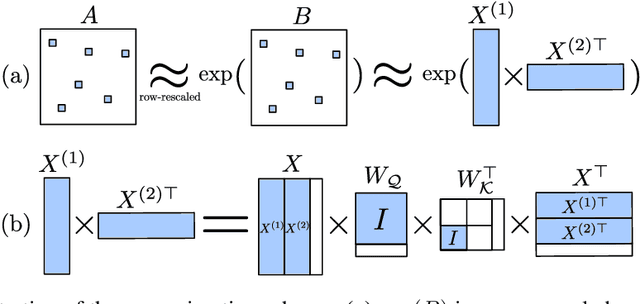
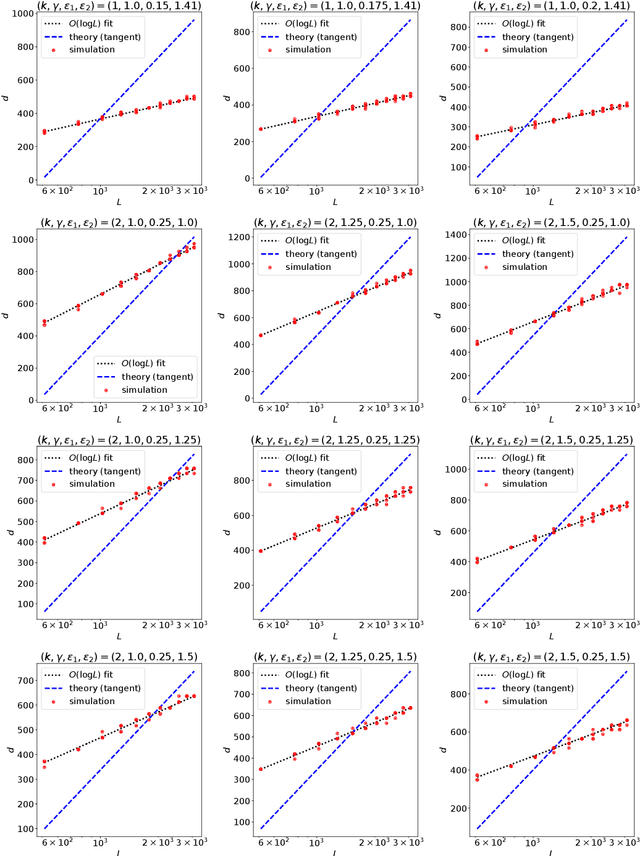
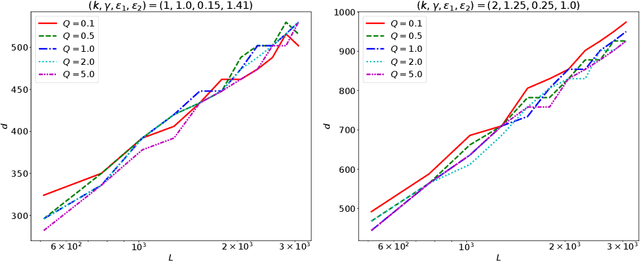
Transformer networks are able to capture patterns in data coming from many domains (text, images, videos, proteins, etc.) with little or no change to architecture components. We perform a theoretical analysis of the core component responsible for signal propagation between elements, i.e. the self-attention matrix. In practice, this matrix typically exhibits two properties: (1) it is sparse, meaning that each token only attends to a small subset of other tokens; and (2) it changes dynamically depending on the input to the module. With these considerations in mind, we ask the following question: Can a fixed self-attention module approximate arbitrary sparse patterns depending on the input? How small is the hidden size $d$ required for such approximation? We make progress in answering this question and show that the self-attention matrix can provably approximate sparse matrices, where sparsity is in terms of a bounded number of nonzero elements in each row and column. While the parameters of self-attention are fixed, various sparse matrices can be approximated by only modifying the inputs. Our proof is based on the random projection technique and uses the seminal Johnson-Lindenstrauss lemma. Our proof is constructive, enabling us to propose an algorithm for finding adaptive inputs and fixed self-attention parameters in order to approximate a given matrix. In particular, we show that, in order to approximate any sparse matrix up to a given precision defined in terms of preserving matrix element ratios, $d$ grows only logarithmically with the sequence length $L$ (i.e. $d = O(\log L)$).
Unlocking Pixels for Reinforcement Learning via Implicit Attention
Mar 04, 2021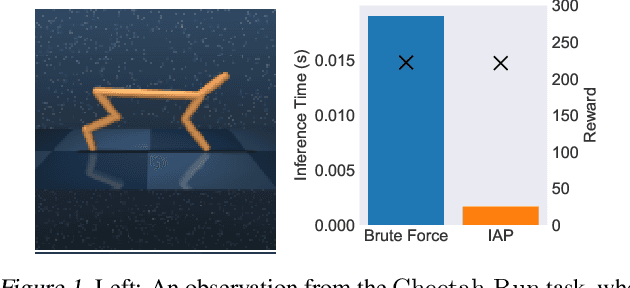
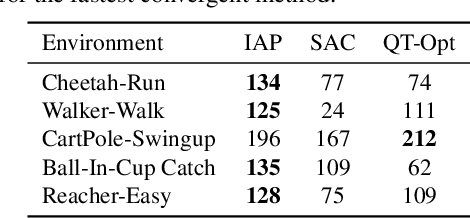
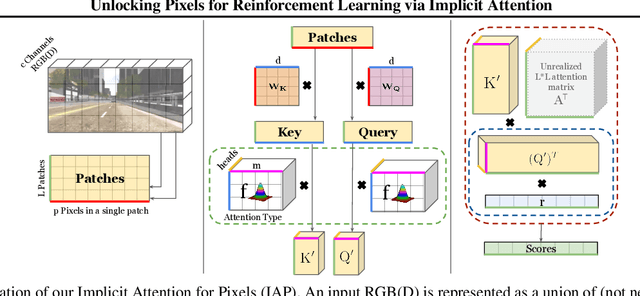

There has recently been significant interest in training reinforcement learning (RL) agents in vision-based environments. This poses many challenges, such as high dimensionality and potential for observational overfitting through spurious correlations. A promising approach to solve both of these problems is a self-attention bottleneck, which provides a simple and effective framework for learning high performing policies, even in the presence of distractions. However, due to poor scalability of attention architectures, these methods do not scale beyond low resolution visual inputs, using large patches (thus small attention matrices). In this paper we make use of new efficient attention algorithms, recently shown to be highly effective for Transformers, and demonstrate that these new techniques can be applied in the RL setting. This allows our attention-based controllers to scale to larger visual inputs, and facilitate the use of smaller patches, even individual pixels, improving generalization. In addition, we propose a new efficient algorithm approximating softmax attention with what we call hybrid random features, leveraging the theory of angular kernels. We show theoretically and empirically that hybrid random features is a promising approach when using attention for vision-based RL.
ES-ENAS: Combining Evolution Strategies with Neural Architecture Search at No Extra Cost for Reinforcement Learning
Jan 19, 2021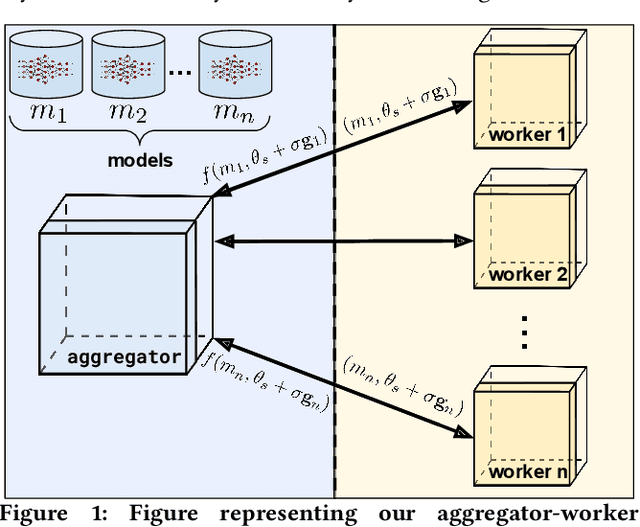

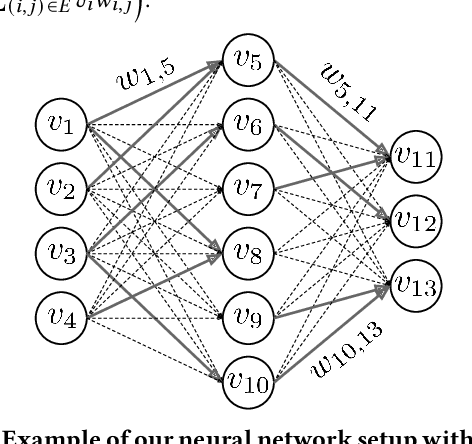
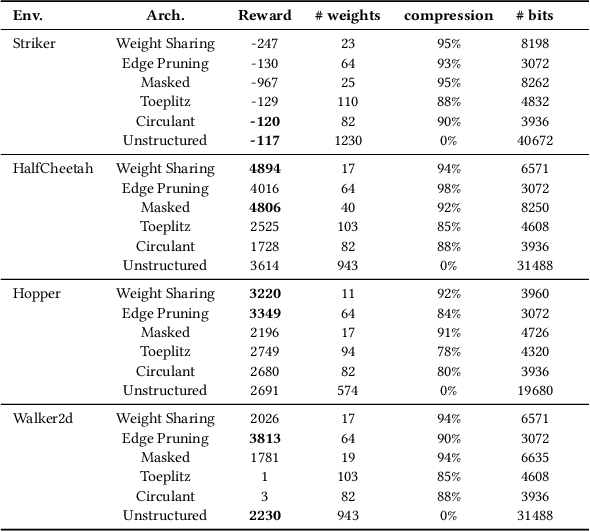
We introduce ES-ENAS, a simple neural architecture search (NAS) algorithm for the purpose of reinforcement learning (RL) policy design, by combining Evolutionary Strategies (ES) and Efficient NAS (ENAS) in a highly scalable and intuitive way. Our main insight is noticing that ES is already a distributed blackbox algorithm, and thus we may simply insert a model controller from ENAS into the central aggregator in ES and obtain weight sharing properties for free. By doing so, we bridge the gap from NAS research in supervised learning settings to the reinforcement learning scenario through this relatively simple marriage between two different lines of research, and are one of the first to apply controller-based NAS techniques to RL. We demonstrate the utility of our method by training combinatorial neural network architectures for RL problems in continuous control, via edge pruning and weight sharing. We also incorporate a wide variety of popular techniques from modern NAS literature, including multiobjective optimization and varying controller methods, to showcase their promise in the RL field and discuss possible extensions. We achieve >90% network compression for multiple tasks, which may be special interest in mobile robotics with limited storage and computational resources.
MLGO: a Machine Learning Guided Compiler Optimizations Framework
Jan 13, 2021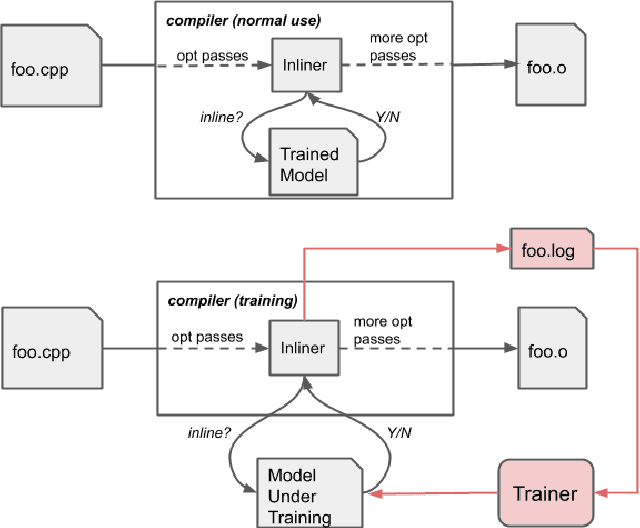
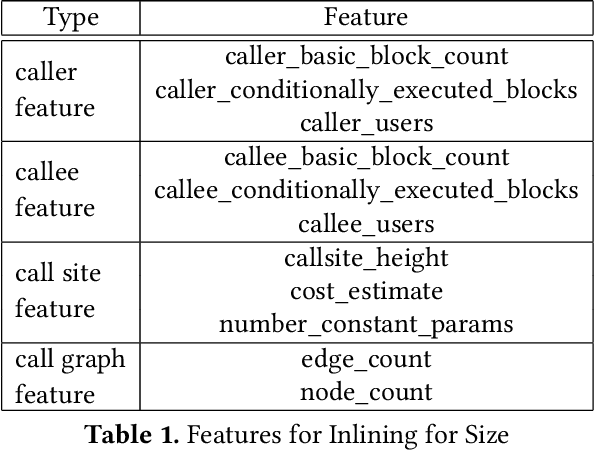
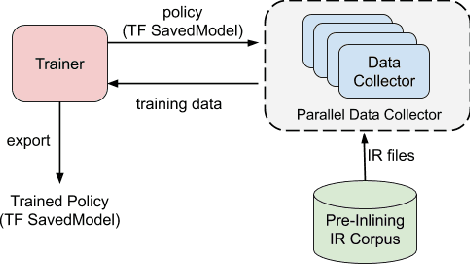
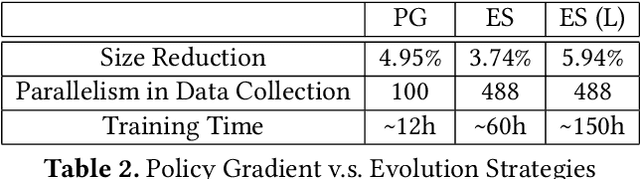
Leveraging machine-learning (ML) techniques for compiler optimizations has been widely studied and explored in academia. However, the adoption of ML in general-purpose, industry strength compilers has yet to happen. We propose MLGO, a framework for integrating ML techniques systematically in an industrial compiler -- LLVM. As a case study, we present the details and results of replacing the heuristics-based inlining-for-size optimization in LLVM with machine learned models. To the best of our knowledge, this work is the first full integration of ML in a complex compiler pass in a real-world setting. It is available in the main LLVM repository. We use two different ML algorithms: Policy Gradient and Evolution Strategies, to train the inlining-for-size model, and achieve up to 7\% size reduction, when compared to state of the art LLVM -Oz. The same model, trained on one corpus, generalizes well to a diversity of real-world targets, as well as to the same set of targets after months of active development. This property of the trained models is beneficial to deploy ML techniques in real-world settings.
Sub-Linear Memory: How to Make Performers SLiM
Dec 21, 2020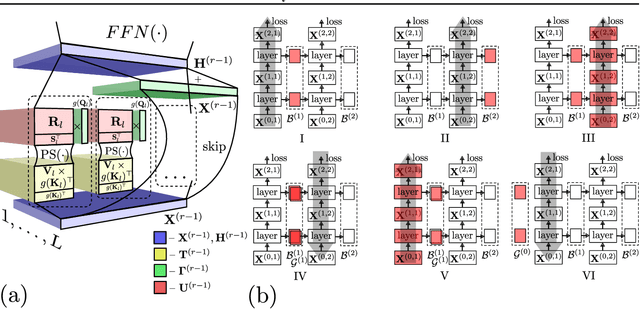

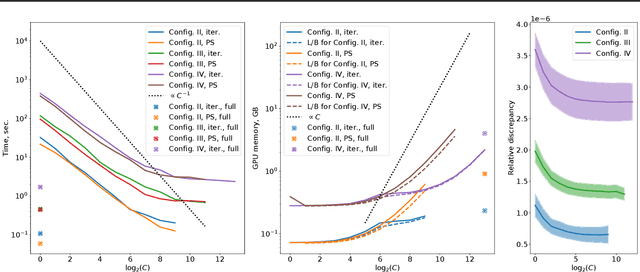
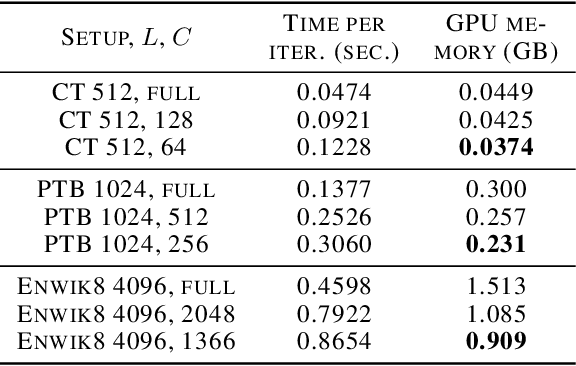
The Transformer architecture has revolutionized deep learning on sequential data, becoming ubiquitous in state-of-the-art solutions for a wide variety of applications. Yet vanilla Transformers are notoriously resource-expensive, requiring $O(L^2)$ in serial time and memory as functions of input length $L$. Recent works proposed various linear self-attention mechanisms, scaling only as $O(L)$ for serial computation. We perform a thorough analysis of recent Transformer mechanisms with linear self-attention, Performers, in terms of overall computational complexity. We observe a remarkable computational flexibility: forward and backward propagation can be performed with no approximations using sublinear memory as a function of $L$ (in addition to negligible storage for the input sequence), at a cost of greater time complexity in the parallel setting. In the extreme case, a Performer consumes only $O(1)$ memory during training, and still requires $O(L)$ time. This discovered time-memory tradeoff can be used for training or, due to complete backward-compatibility, for fine-tuning on a low-memory device, e.g. a smartphone or an earlier-generation GPU, thus contributing towards decentralized and democratized deep learning.
Rethinking Attention with Performers
Sep 30, 2020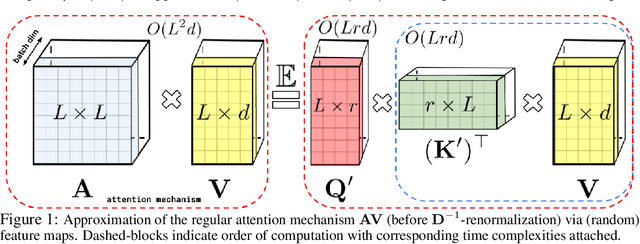
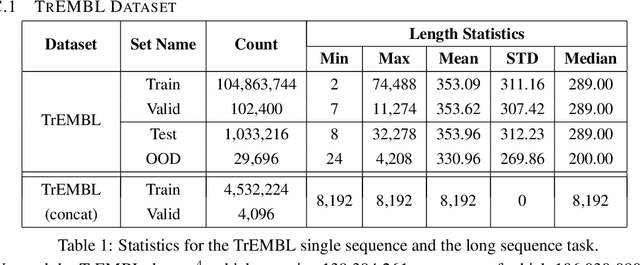
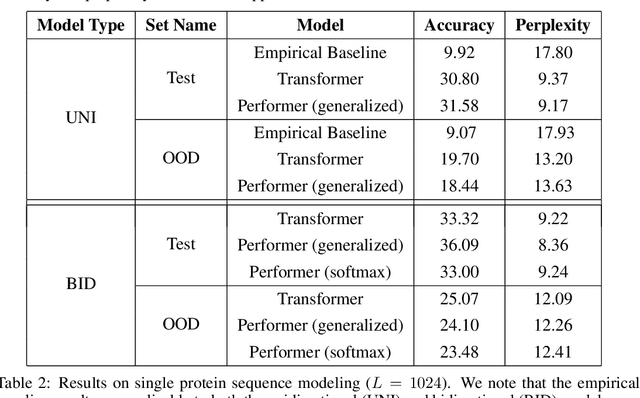
We introduce Performers, Transformer architectures which can estimate regular (softmax) full-rank-attention Transformers with provable accuracy, but using only linear (as opposed to quadratic) space and time complexity, without relying on any priors such as sparsity or low-rankness. To approximate softmax attention-kernels, Performers use a novel Fast Attention Via positive Orthogonal Random features approach (FAVOR+), which may be of independent interest for scalable kernel methods. FAVOR+ can be also used to efficiently model kernelizable attention mechanisms beyond softmax. This representational power is crucial to accurately compare softmax with other kernels for the first time on large-scale tasks, beyond the reach of regular Transformers, and investigate optimal attention-kernels. Performers are linear architectures fully compatible with regular Transformers and with strong theoretical guarantees: unbiased or nearly-unbiased estimation of the attention matrix, uniform convergence and low estimation variance. We tested Performers on a rich set of tasks stretching from pixel-prediction through text models to protein sequence modeling. We demonstrate competitive results with other examined efficient sparse and dense attention methods, showcasing effectiveness of the novel attention-learning paradigm leveraged by Performers.