 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlling Assistive Robots with Learned Latent Actions
Oct 16, 2019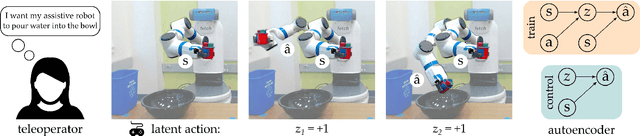
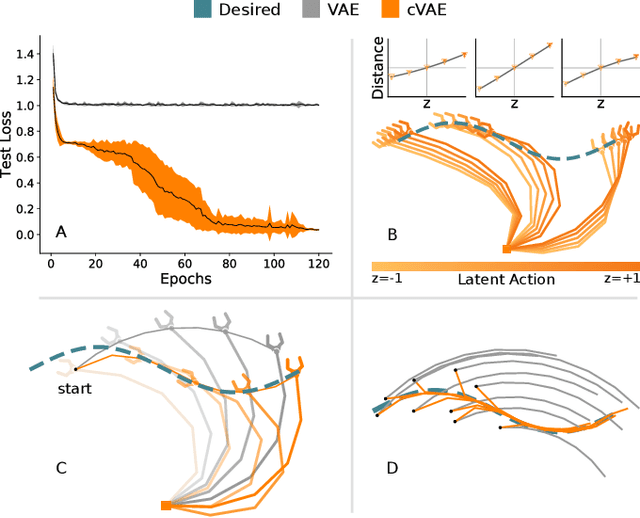
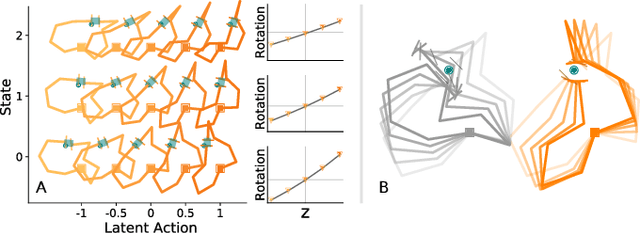
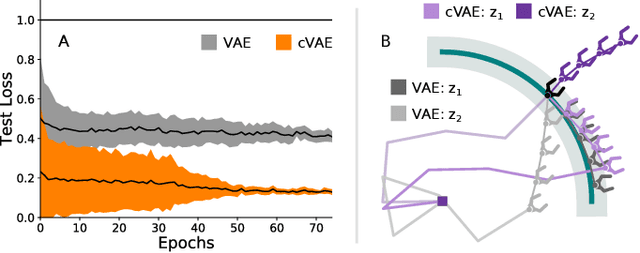
Assistive robots enable users with disabilities to perform everyday tasks without relying on a caregiver. Unfortunately, the very dexterity that makes these arms useful also makes them challenging to control: the robot has more degrees-of-freedom (DoFs) than the human can directly coordinate with a handheld joystick. Our insight is that we can make assistive robots easier for humans to control by learning latent actions. Latent actions provide a low-DoF embedding of high-DoF robot behavior: for example, one latent dimension might guide the robot arm along a pouring motion. Because these latent actions are low-dimensional, they can be controlled by the human end-user to fluidly teleoperate the robot. In this paper, we design a teleoperation algorithm for assistive robots that learns intuitive latent dimensions from task demonstrations. We formulate the controllability, consistency, and scaling properties that intuitive latent actions should have, and evaluate how different low-dimensional embeddings capture these properties. Finally, we conduct two user studies on a robotic arm to compare our latent action approach to state-of-the-art shared autonomy baselines and direct end-effector teleoperation. Participants completed the assistive feeding and cooking tasks more quickly and efficiently when leveraging our latent actions, and also reported that latent actions made the task easier to perform. The video accompanying this paper can be found at: https://youtu.be/wjnhrzugBj4.
Making Sense of Vision and Touch: Learning Multimodal Representations for Contact-Rich Tasks
Jul 28, 2019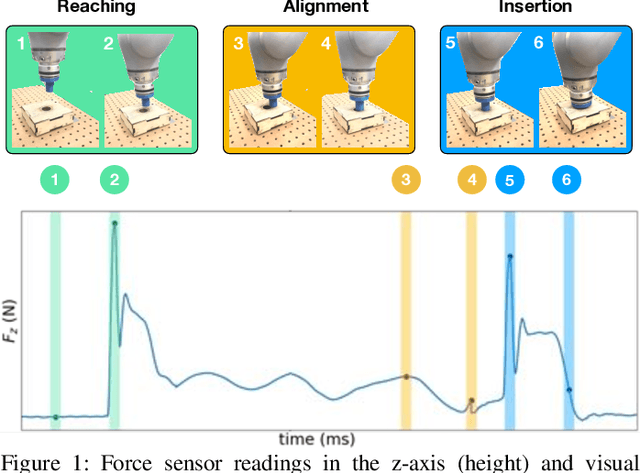
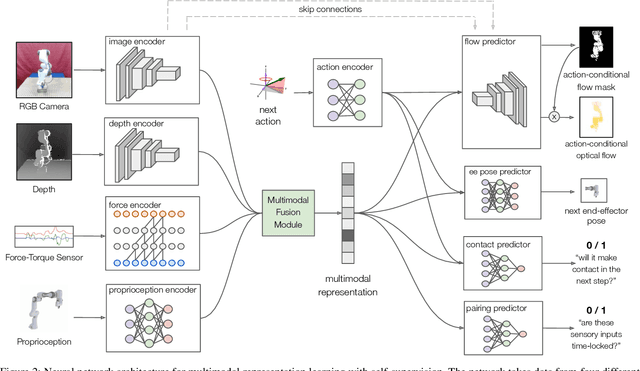
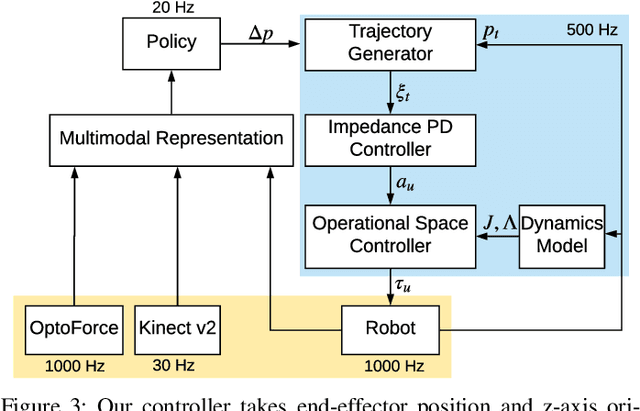

Contact-rich manipulation tasks in unstructured environments often require both haptic and visual feedback. It is non-trivial to manually design a robot controller that combines these modalities which have very different characteristics. While deep reinforcement learning has shown success in learning control policies for high-dimensional inputs, these algorithms are generally intractable to deploy on real robots due to sample complexity. In this work, we use self-supervision to learn a compact and multimodal representation of our sensory inputs, which can then be used to improve the sample efficiency of our policy learning. Evaluating our method on a peg insertion task, we show that it generalizes over varying geometries, configurations, and clearances, while being robust to external perturbations. We also systematically study different self-supervised learning objectives and representation learning architectures. Results are presented in simulation and on a physical robot.
Making Sense of Vision and Touch: Self-Supervised Learning of Multimodal Representations for Contact-Rich Tasks
Mar 08, 2019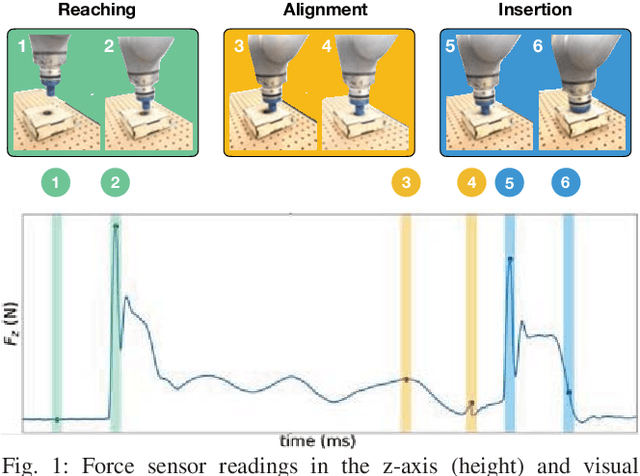
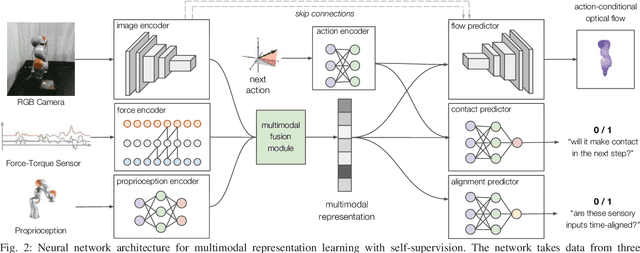
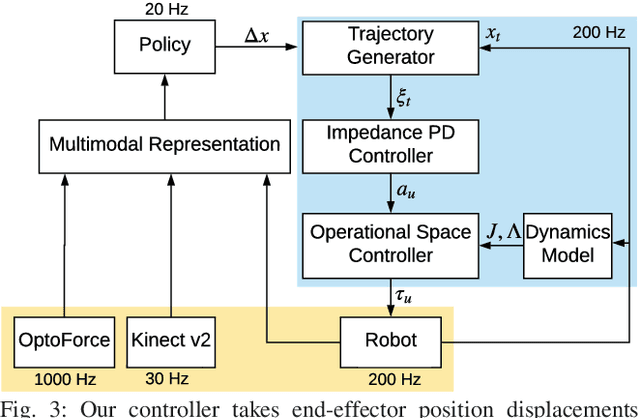
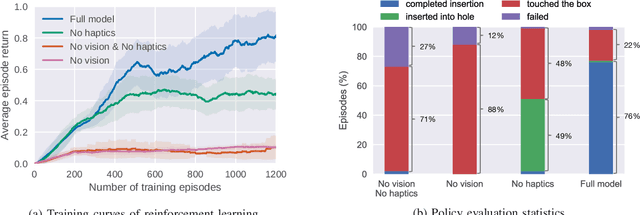
Contact-rich manipulation tasks in unstructured environments often require both haptic and visual feedback. However, it is non-trivial to manually design a robot controller that combines modalities with very different characteristics. While deep reinforcement learning has shown success in learning control policies for high-dimensional inputs, these algorithms are generally intractable to deploy on real robots due to sample complexity. We use self-supervision to learn a compact and multimodal representation of our sensory inputs, which can then be used to improve the sample efficiency of our policy learning. We evaluate our method on a peg insertion task, generalizing over different geometry, configurations, and clearances, while being robust to external perturbations. Results for simulated and real robot experiments are presented.
Graph-based Neural Multi-Document Summarization
Aug 23, 2017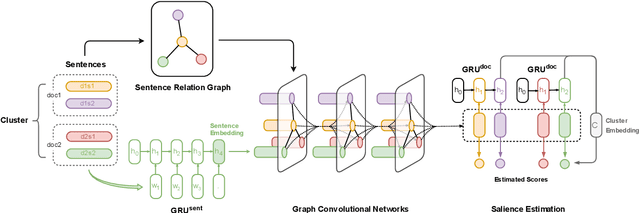
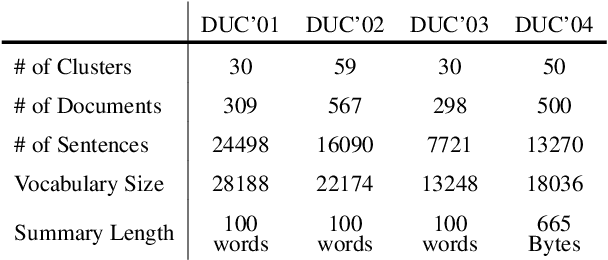
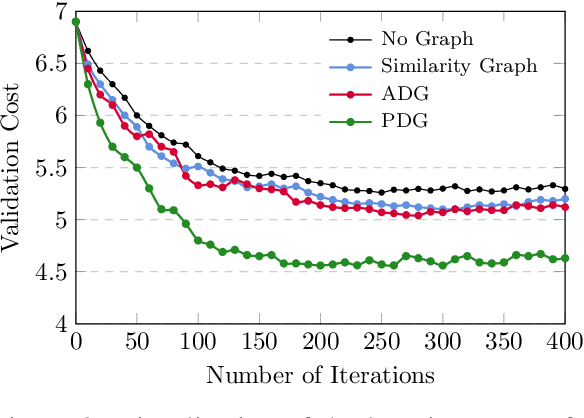
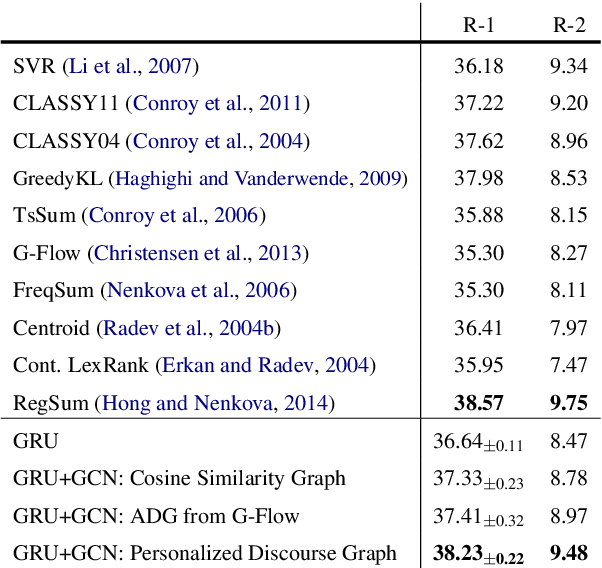
We propose a neural multi-document summarization (MDS) system that incorporates sentence relation graphs. We employ a Graph Convolutional Network (GCN) on the relation graphs, with sentence embeddings obtained from Recurrent Neural Networks as input node features. Through multiple layer-wise propagation, the GCN generates high-level hidden sentence features for salience estimation. We then use a greedy heuristic to extract salient sentences while avoiding redundancy. In our experiments on DUC 2004, we consider three types of sentence relation graphs and demonstrate the advantage of combining sentence relations in graphs with the representation power of deep neural networks. Our model improves upon traditional graph-based extractive approaches and the vanilla GRU sequence model with no graph, and it achieves competitive results against other state-of-the-art multi-document summarization systems.