 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombating False Negatives in Adversarial Imitation Learning
Feb 02, 2020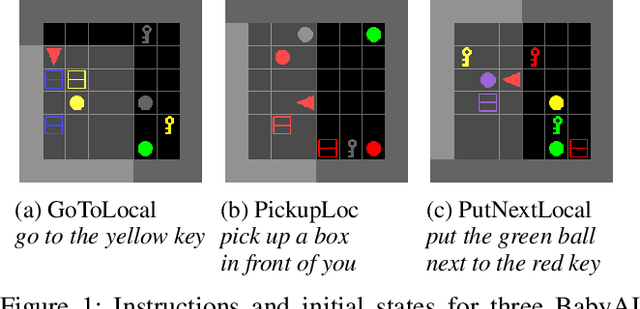

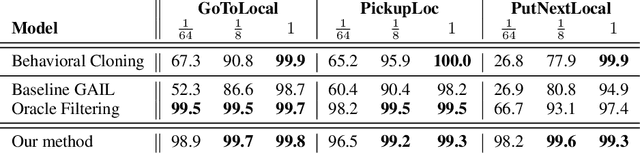
In adversarial imitation learning, a discriminator is trained to differentiate agent episodes from expert demonstrations representing the desired behavior. However, as the trained policy learns to be more successful, the negative examples (the ones produced by the agent) become increasingly similar to expert ones. Despite the fact that the task is successfully accomplished in some of the agent's trajectories, the discriminator is trained to output low values for them. We hypothesize that this inconsistent training signal for the discriminator can impede its learning, and consequently leads to worse overall performance of the agent. We show experimental evidence for this hypothesis and that the 'False Negatives' (i.e. successful agent episodes) significantly hinder adversarial imitation learning, which is the first contribution of this paper. Then, we propose a method to alleviate the impact of false negatives and test it on the BabyAI environment. This method consistently improves sample efficiency over the baselines by at least an order of magnitude.
Task-Relevant Adversarial Imitation Learning
Oct 02, 2019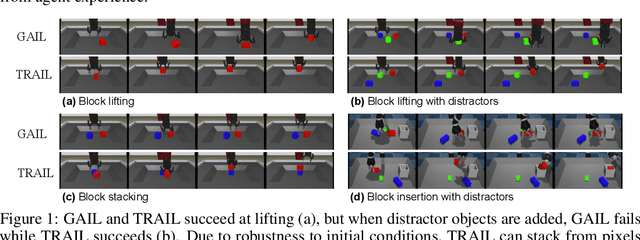
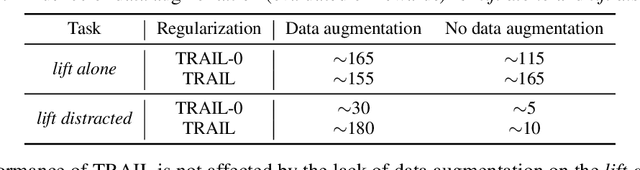


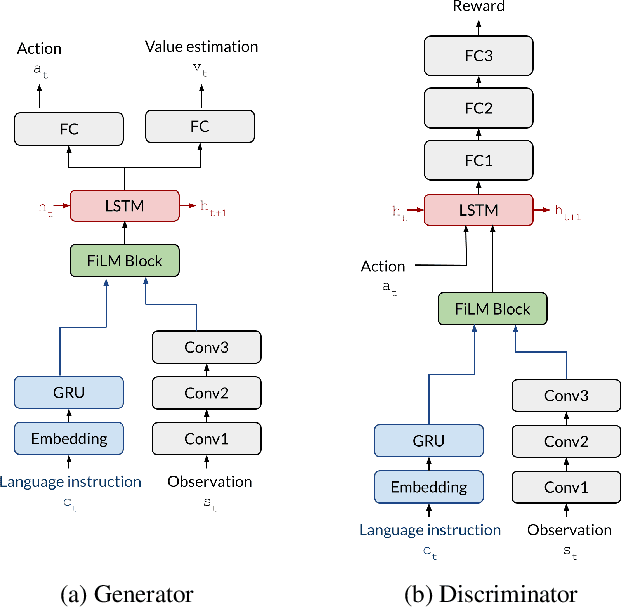
We show that a critical problem in adversarial imitation from high-dimensional sensory data is the tendency of discriminator networks to distinguish agent and expert behaviour using task-irrelevant features beyond the control of the agent. We analyze this problem in detail and propose a solution as well as several baselines that outperform standard Generative Adversarial Imitation Learning (GAIL). Our proposed solution, Task-Relevant Adversarial Imitation Learning (TRAIL), uses a constrained optimization objective to overcome task-irrelevant features. Comprehensive experiments show that TRAIL can solve challenging manipulation tasks from pixels by imitating human operators, where other agents such as behaviour cloning (BC), standard GAIL, improved GAIL variants including our newly proposed baselines, and Deterministic Policy Gradients from Demonstrations (DPGfD) fail to find solutions, even when the other agents have access to task reward.
The Dynamics of Handwriting Improves the Automated Diagnosis of Dysgraphia
Jun 12, 2019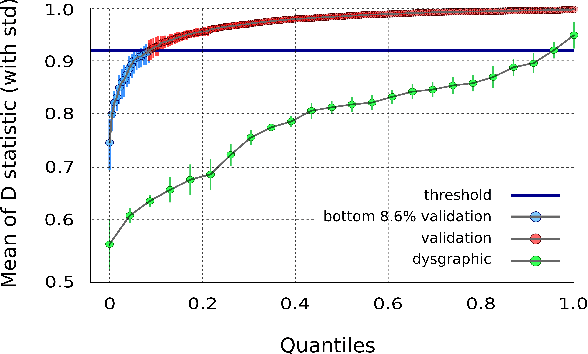
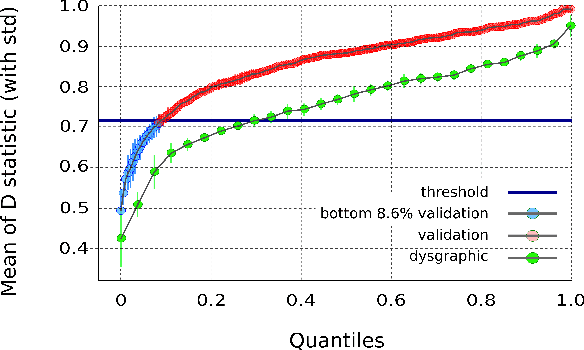
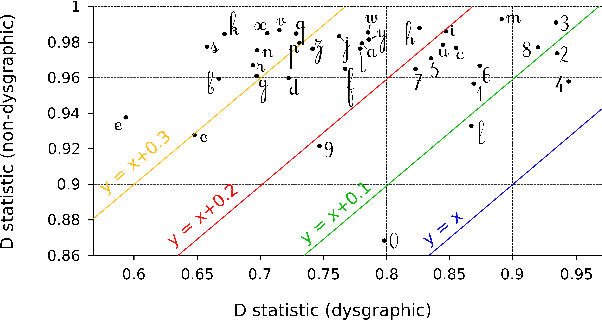
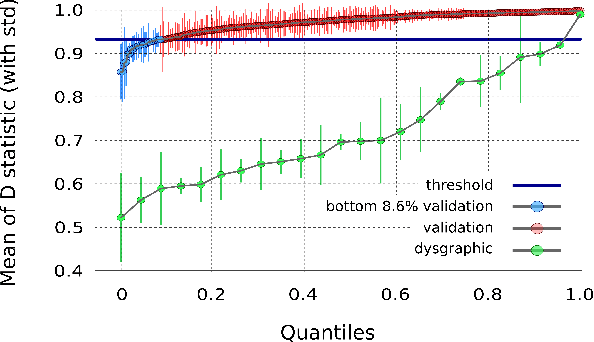
Handwriting disorder (termed dysgraphia) is a far from a singular problem as nearly 8.6% of the population in France is considered dysgraphic. Moreover, research highlights the fundamental importance to detect and remediate these handwriting difficulties as soon as possible as they may affect a child's entire life, undermining performance and self-confidence in a wide variety of school activities. At the moment, the detection of handwriting difficulties is performed through a standard test called BHK. This detection, performed by therapists, is laborious because of its high cost and subjectivity. We present a digital approach to identify and characterize handwriting difficulties via a Recurrent Neural Network model (RNN). The child under investigation is asked to write on a graphics tablet all the letters of the alphabet as well as the ten digits. Once complete, the RNN delivers a diagnosis in a few milliseconds and demonstrates remarkable efficiency as it correctly identifies more than 90% of children diagnosed as dysgraphic using the BHK test. The main advantage of our tablet-based system is that it captures the dynamic features of writing -- something a human expert, such as a teacher, is unable to do. We show that incorporating the dynamic information available by the use of tablet is highly beneficial to our digital test to discriminate between typically-developing and dysgraphic children.
Reinforced Imitation in Heterogeneous Action Space
Apr 06, 2019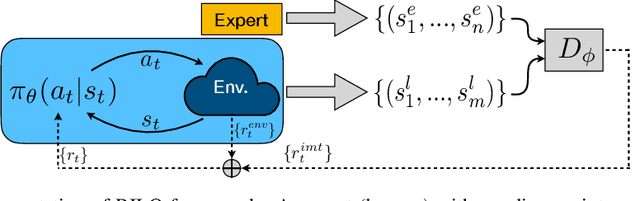

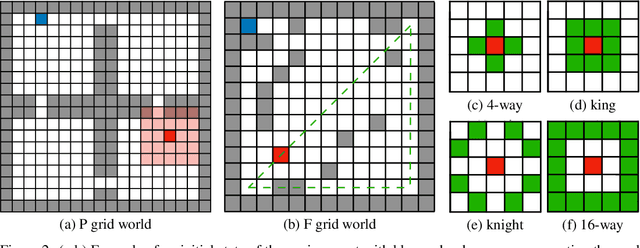
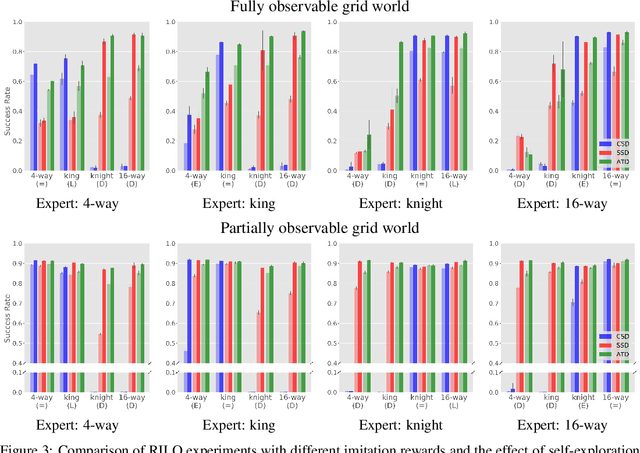
Imitation learning is an effective alternative approach to learn a policy when the reward function is sparse. In this paper, we consider a challenging setting where an agent and an expert use different actions from each other. We assume that the agent has access to a sparse reward function and state-only expert observations. We propose a method which gradually balances between the imitation learning cost and the reinforcement learning objective. In addition, this method adapts the agent's policy based on either mimicking expert behavior or maximizing sparse reward. We show, through navigation scenarios, that (i) an agent is able to efficiently leverage sparse rewards to outperform standard state-only imitation learning, (ii) it can learn a policy even when its actions are different from the expert, and (iii) the performance of the agent is not bounded by that of the expert, due to the optimized usage of sparse rewards.
Classifier-agnostic saliency map extraction
Oct 02, 2018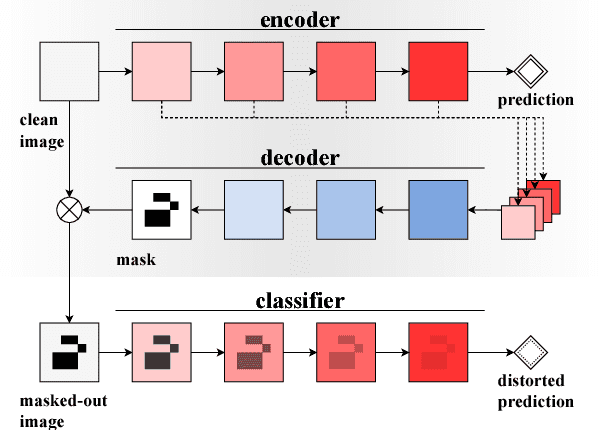
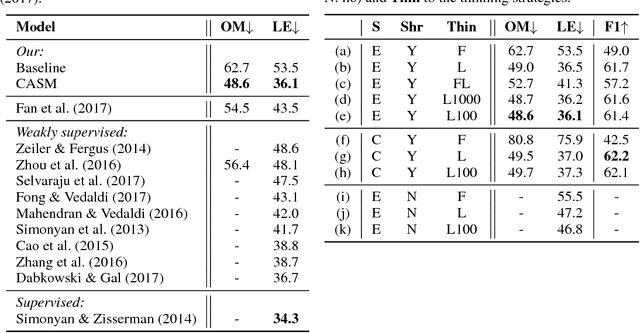

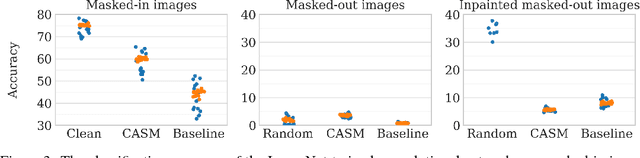
Extracting saliency maps, which indicate parts of the image important to classification, requires many tricks to achieve satisfactory performance when using classifier-dependent methods. Instead, we propose classifier-agnostic saliency map extraction, which finds all parts of the image that any classifier could use, not just one given in advance. We observe that the proposed approach extracts higher quality saliency maps and outperforms existing weakly-supervised localization techniques, setting the new state of the art result on the ImageNet dataset. We made our code publicly available at https://github.com/kondiz/casme .
Focused Hierarchical RNNs for Conditional Sequence Processing
Jun 12, 2018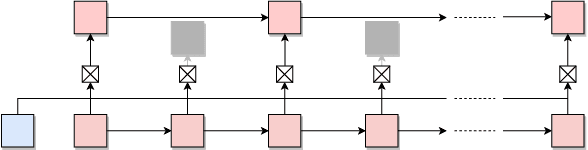
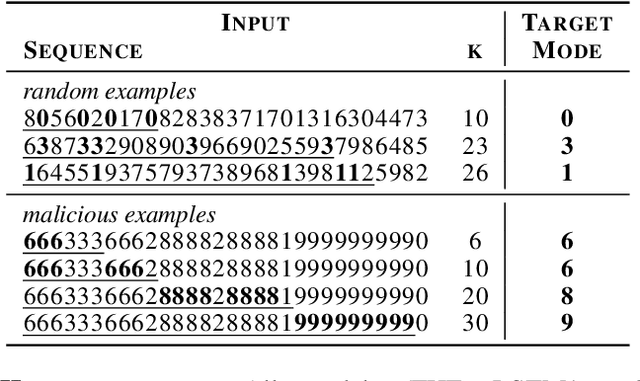
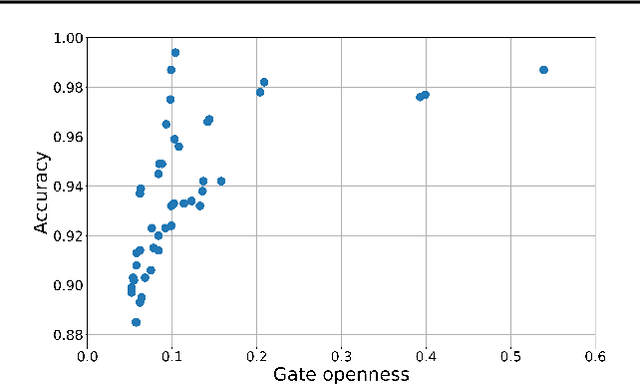
Recurrent Neural Networks (RNNs) with attention mechanisms have obtained state-of-the-art results for many sequence processing tasks. Most of these models use a simple form of encoder with attention that looks over the entire sequence and assigns a weight to each token independently. We present a mechanism for focusing RNN encoders for sequence modelling tasks which allows them to attend to key parts of the input as needed. We formulate this using a multi-layer conditional sequence encoder that reads in one token at a time and makes a discrete decision on whether the token is relevant to the context or question being asked. The discrete gating mechanism takes in the context embedding and the current hidden state as inputs and controls information flow into the layer above. We train it using policy gradient methods. We evaluate this method on several types of tasks with different attributes. First, we evaluate the method on synthetic tasks which allow us to evaluate the model for its generalization ability and probe the behavior of the gates in more controlled settings. We then evaluate this approach on large scale Question Answering tasks including the challenging MS MARCO and SearchQA tasks. Our models shows consistent improvements for both tasks over prior work and our baselines. It has also shown to generalize significantly better on synthetic tasks as compared to the baselines.
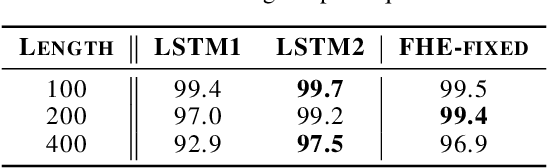
Fraternal Dropout
Mar 28, 2018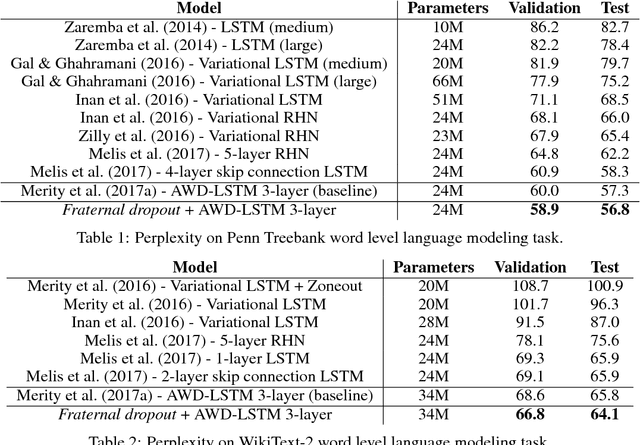
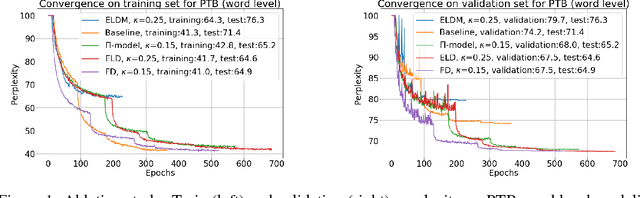
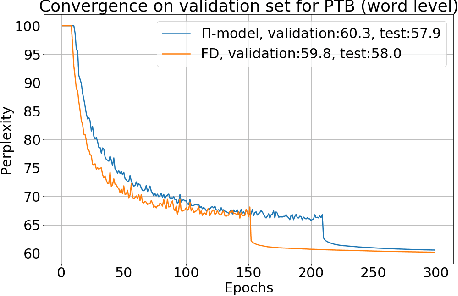

Recurrent neural networks (RNNs) are important class of architectures among neural networks useful for language modeling and sequential prediction. However, optimizing RNNs is known to be harder compared to feed-forward neural networks. A number of techniques have been proposed in literature to address this problem. In this paper we propose a simple technique called fraternal dropout that takes advantage of dropout to achieve this goal. Specifically, we propose to train two identical copies of an RNN (that share parameters) with different dropout masks while minimizing the difference between their (pre-softmax) predictions. In this way our regularization encourages the representations of RNNs to be invariant to dropout mask, thus being robust. We show that our regularization term is upper bounded by the expectation-linear dropout objective which has been shown to address the gap due to the difference between the train and inference phases of dropout. We evaluate our model and achieve state-of-the-art results in sequence modeling tasks on two benchmark datasets - Penn Treebank and Wikitext-2. We also show that our approach leads to performance improvement by a significant margin in image captioning (Microsoft COCO) and semi-supervised (CIFAR-10) tasks.
Improving the Performance of Neural Networks in Regression Tasks Using Drawering
Dec 05, 2016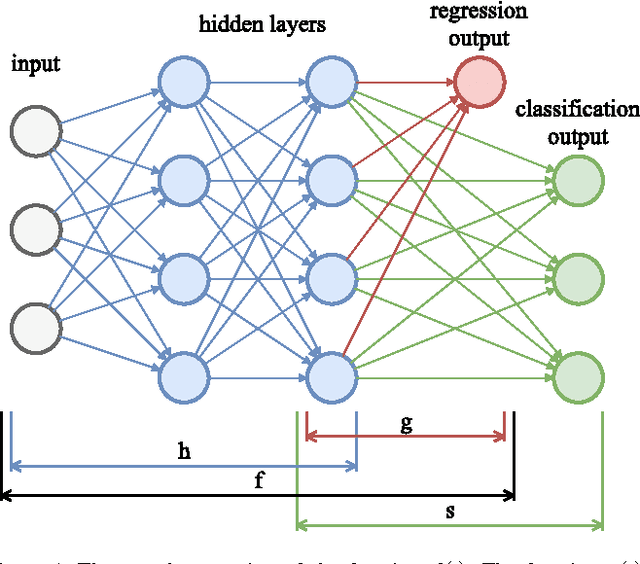
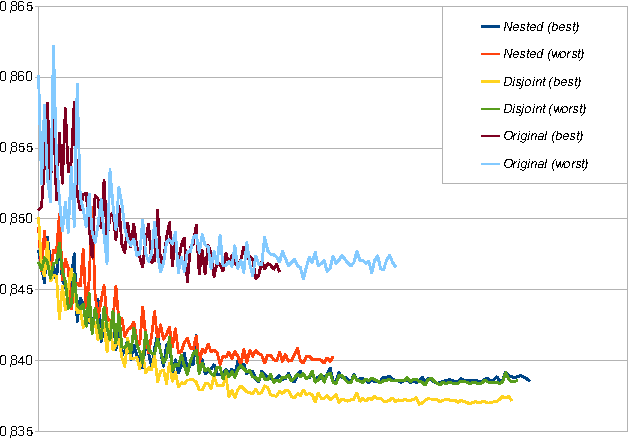

The method presented extends a given regression neural network to make its performance improve. The modification affects the learning procedure only, hence the extension may be easily omitted during evaluation without any change in prediction. It means that the modified model may be evaluated as quickly as the original one but tends to perform better. This improvement is possible because the modification gives better expressive power, provides better behaved gradients and works as a regularization. The knowledge gained by the temporarily extended neural network is contained in the parameters shared with the original neural network. The only cost is an increase in learning time.