 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCDMT-EHR: A Continuous-Time Diffusion Framework for Generating Mixed-Type Time-Series Electronic Health Records
Mar 24, 2026Electronic health records (EHRs) are invaluable for clinical research, yet privacy concerns severely restrict data sharing. Synthetic data generation offers a promising solution, but EHRs present unique challenges: they contain both numerical and categorical features that evolve over time. While diffusion models have demonstrated strong performance in EHR synthesis, existing approaches predominantly rely on discrete-time formulations, which suffer from finite-step approximation errors and coupled training-sampling step counts. We propose a continuous-time diffusion framework for generating mixed-type time-series EHRs with three contributions: (1) continuous-time diffusion with a bidirectional gated recurrent unit backbone for capturing temporal dependencies, (2) unified Gaussian diffusion via learnable continuous embeddings for categorical variables, enabling joint cross-feature modeling, and (3) a factorized learnable noise schedule that adapts to per-feature-per-timestep learning difficulties. Experiments on two large-scale intensive care unit datasets demonstrate that our method outperforms existing approaches in downstream task performance, distribution fidelity, and discriminability, while requiring only 50 sampling steps compared to 1,000 for baseline methods. Classifier-free guidance further enables effective conditional generation for class-imbalanced clinical scenarios.
From Pen Strokes to Sleep States: Detecting Low-Recovery Days Using Sigma-Lognormal Handwriting Features
Mar 12, 2026While handwriting has traditionally been studied for character recognition and disease classification, its potential to reflect day-to-day physiological fluctuations in healthy individuals remains unexplored. This study examines whether daily variations in sleep-related recovery states can be inferred from online handwriting dynamics. % We propose a personalized binary classification framework that detects low-recovery days using features derived from the Sigma-Lognormal model, which captures the neuromotor generation process of pen strokes. In a 28-day in-the-wild study involving 13 university students, handwriting was recorded three times daily, and nocturnal cardiac indicators were measured using a wearable ring. For each participant, the lowest (or highest) quartile of four sleep-related metrics -- HRV, lowest heart rate, average heart rate, and total sleep duration -- defined the positive class. Leave-One-Day-Out cross-validation showed that PR-AUC significantly exceeded the baseline (0.25) for all four variables after FDR correction, with the strongest performance observed for cardiac-related variables. Importantly, classification performance did not differ significantly across task types or recording timings, indicating that recovery-related signals are embedded in general movement dynamics. These results demonstrate that subtle within-person autonomic recovery fluctuations can be detected from everyday handwriting, opening a new direction for non-invasive, device-independent health monitoring.
Prediction of Grade, Gender, and Academic Performance of Children and Teenagers from Handwriting Using the Sigma-Lognormal Model
Mar 12, 2026Digital handwriting acquisition enables the capture of detailed temporal and kinematic signals reflecting the motor processes underlying writing behavior. While handwriting analysis has been extensively explored in clinical or adult populations, its potential for studying developmental and educational characteristics in children remains less investigated. In this work, we examine whether handwriting dynamics encode information related to student characteristics using a large-scale online dataset collected from Japanese students from elementary school to junior high school. We systematically compare three families of handwriting-derived features: basic statistical descriptors of kinematic signals, entropy-based measures of variability, and parameters obtained from the sigma-lognormal model. Although the dataset contains dense stroke-level recordings, features are aggregated at the student level to enable a controlled comparison between representations. These features are evaluated across three prediction tasks: grade prediction, gender classification, and academic performance classification, using Linear or Logistic Regression and Random Forest models under consistent experimental settings. The results show that handwriting dynamics contain measurable signals related to developmental stage and individual differences, especially for the grade prediction task. These findings highlight the potential of kinematic handwriting analysis and confirm that through their development, children's handwriting evolves toward a lognormal motor organization.
Towards Khmer Scene Document Layout Detection
Feb 28, 2026While document layout analysis for Latin scripts has advanced significantly, driven by the advent of large multimodal models (LMMs), progress for the Khmer language remains constrained because of the scarcity of annotated training data. This gap is particularly acute for scene documents, where perspective distortions and complex backgrounds challenge traditional methods. Given the structural complexities of Khmer script, such as diacritics and multi-layer character stacking, existing Latin-based layout analysis models fail to accurately delineate semantic layout units, particularly for dense text regions (e.g., list items). In this paper, we present the first comprehensive study on Khmer scene document layout detection. We contribute a novel framework comprising three key elements: (1) a robust training and benchmarking dataset specifically for Khmer scene layouts; (2) an open-source document augmentation tool capable of synthesizing realistic scene documents to scale training data; and (3) layout detection baselines utilizing YOLO-based architectures with oriented bounding boxes (OBB) to handle geometric distortions. To foster further research in the Khmer document analysis and recognition (DAR) community, we release our models, code, and datasets in this gated repository (in review).
Towards Universal Khmer Text Recognition
Feb 28, 2026Khmer is a low-resource language characterized by a complex script, presenting significant challenges for optical character recognition (OCR). While document printed text recognition has advanced because of available datasets, performance on other modalities, such as handwritten and scene text, remains limited by data scarcity. Training modality-specific models for each modality does not allow cross-modality transfer learning, from which modalities with limited data could otherwise benefit. Moreover, deploying many modality-specific models results in significant memory overhead and requires error-prone routing each input image to the appropriate model. On the other hand, simply training on a combined dataset with a non-uniform data distribution across different modalities often leads to degraded performance on underrepresented modalities. To address these, we propose a universal Khmer text recognition (UKTR) framework capable of handling diverse text modalities. Central to our method is a novel modality-aware adaptive feature selection (MAFS) technique designed to adapt visual features according to a particular input image modality and enhance recognition robustness across modalities. Extensive experiments demonstrate that our model achieves state-of-the-art (SoTA) performance. Furthermore, we introduce the first comprehensive benchmark for universal Khmer text recognition, which we release to the community to facilitate future research. Our datasets and models can be accessible via this gated repository\footnote{in review}.
CBEN -- A Multimodal Machine Learning Dataset for Cloud Robust Remote Sensing Image Understanding
Feb 13, 2026Clouds are a common phenomenon that distorts optical satellite imagery, which poses a challenge for remote sensing. However, in the literature cloudless analysis is often performed where cloudy images are excluded from machine learning datasets and methods. Such an approach cannot be applied to time sensitive applications, e.g., during natural disasters. A possible solution is to apply cloud removal as a preprocessing step to ensure that cloudfree solutions are not failing under such conditions. But cloud removal methods are still actively researched and suffer from drawbacks, such as generated visual artifacts. Therefore, it is desirable to develop cloud robust methods that are less affected by cloudy weather. Cloud robust methods can be achieved by combining optical data with radar, a modality unaffected by clouds. While many datasets for machine learning combine optical and radar data, most researchers exclude cloudy images. We identify this exclusion from machine learning training and evaluation as a limitation that reduces applicability to cloudy scenarios. To investigate this, we assembled a dataset, named CloudyBigEarthNet (CBEN), of paired optical and radar images with cloud occlusion for training and evaluation. Using average precision (AP) as the evaluation metric, we show that state-of-the-art methods trained on combined clear-sky optical and radar imagery suffer performance drops of 23-33 percentage points when evaluated on cloudy images. We then adapt these methods to cloudy optical data during training, achieving relative improvement of 17.2-28.7 percentage points on cloudy test cases compared with the original approaches. Code and dataset are publicly available at: https://github.com/mstricker13/CBEN
Quantitative knowledge retrieval from large language models
Feb 12, 2024Large language models (LLMs) have been extensively studied for their abilities to generate convincing natural language sequences, however their utility for quantitative information retrieval is less well understood. In this paper we explore the feasibility of LLMs as a mechanism for quantitative knowledge retrieval to aid data analysis tasks such as elicitation of prior distributions for Bayesian models and imputation of missing data. We present a prompt engineering framework, treating an LLM as an interface to a latent space of scientific literature, comparing responses in different contexts and domains against more established approaches. Implications and challenges of using LLMs as 'experts' are discussed.
Confidence-Aware Learning Assistant
Feb 15, 2021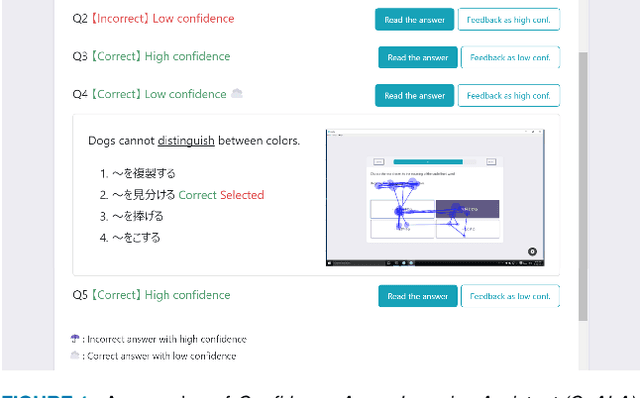

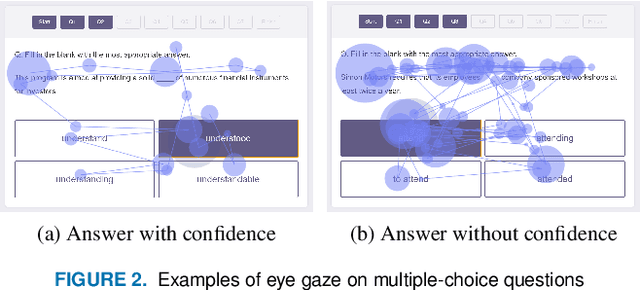
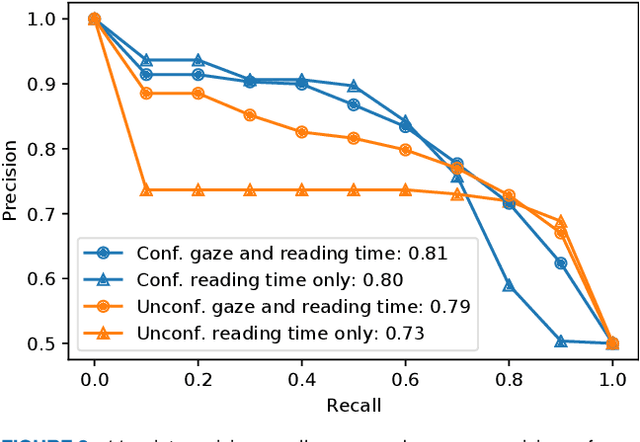
Not only correctness but also self-confidence play an important role in improving the quality of knowledge. Undesirable situations such as confident incorrect and unconfident correct knowledge prevent learners from revising their knowledge because it is not always easy for them to perceive the situations. To solve this problem, we propose a system that estimates self-confidence while solving multiple-choice questions by eye tracking and gives feedback about which question should be reviewed carefully. We report the results of three studies measuring its effectiveness. (1) On a well-controlled dataset with 10 participants, our approach detected confidence and unconfidence with 81% and 79% average precision. (2) With the help of 20 participants, we observed that correct answer rates of questions were increased by 14% and 17% by giving feedback about correct answers without confidence and incorrect answers with confidence, respectively. (3) We conducted a large-scale data recording in a private school (72 high school students solved 14,302 questions) to investigate effective features and the number of required training samples.
Distortion-Adaptive Grape Bunch Counting for Omnidirectional Images
Aug 28, 2020

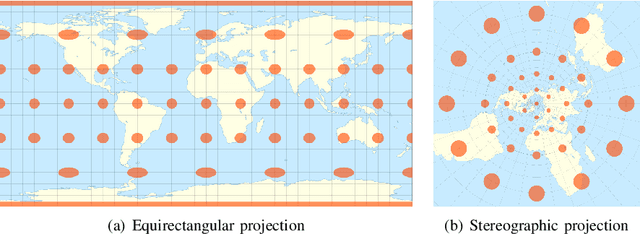
This paper proposes the first object counting method for omnidirectional images. Because conventional object counting methods cannot handle the distortion of omnidirectional images, we propose to process them using stereographic projection, which enables conventional methods to obtain a good approximation of the density function. However, the images obtained by stereographic projection are still distorted. Hence, to manage this distortion, we propose two methods. One is a new data augmentation method designed for the stereographic projection of omnidirectional images. The other is a distortion-adaptive Gaussian kernel that generates a density map ground truth while taking into account the distortion of stereographic projection. Using the counting of grape bunches as a case study, we constructed an original grape-bunch image dataset consisting of omnidirectional images and conducted experiments to evaluate the proposed method. The results show that the proposed method performs better than a direct application of the conventional method, improving mean absolute error by 14.7% and mean squared error by 10.5%.
Facial Landmark Detection for Manga Images
Nov 08, 2018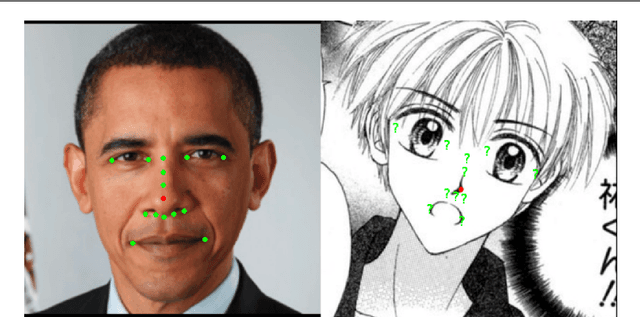



The topic of facial landmark detection has been widely covered for pictures of human faces, but it is still a challenge for drawings. Indeed, the proportions and symmetry of standard human faces are not always used for comics or mangas. The personal style of the author, the limitation of colors, etc. makes the landmark detection on faces in drawings a difficult task. Detecting the landmarks on manga images will be useful to provide new services for easily editing the character faces, estimating the character emotions, or generating automatically some animations such as lip or eye movements. This paper contains two main contributions: 1) a new landmark annotation model for manga faces, and 2) a deep learning approach to detect these landmarks. We use the "Deep Alignment Network", a multi stage architecture where the first stage makes an initial estimation which gets refined in further stages. The first results show that the proposed method succeed to accurately find the landmarks in more than 80% of the cases.