 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Khmer Scene Document Layout Detection
Feb 28, 2026While document layout analysis for Latin scripts has advanced significantly, driven by the advent of large multimodal models (LMMs), progress for the Khmer language remains constrained because of the scarcity of annotated training data. This gap is particularly acute for scene documents, where perspective distortions and complex backgrounds challenge traditional methods. Given the structural complexities of Khmer script, such as diacritics and multi-layer character stacking, existing Latin-based layout analysis models fail to accurately delineate semantic layout units, particularly for dense text regions (e.g., list items). In this paper, we present the first comprehensive study on Khmer scene document layout detection. We contribute a novel framework comprising three key elements: (1) a robust training and benchmarking dataset specifically for Khmer scene layouts; (2) an open-source document augmentation tool capable of synthesizing realistic scene documents to scale training data; and (3) layout detection baselines utilizing YOLO-based architectures with oriented bounding boxes (OBB) to handle geometric distortions. To foster further research in the Khmer document analysis and recognition (DAR) community, we release our models, code, and datasets in this gated repository (in review).
Towards Universal Khmer Text Recognition
Feb 28, 2026Khmer is a low-resource language characterized by a complex script, presenting significant challenges for optical character recognition (OCR). While document printed text recognition has advanced because of available datasets, performance on other modalities, such as handwritten and scene text, remains limited by data scarcity. Training modality-specific models for each modality does not allow cross-modality transfer learning, from which modalities with limited data could otherwise benefit. Moreover, deploying many modality-specific models results in significant memory overhead and requires error-prone routing each input image to the appropriate model. On the other hand, simply training on a combined dataset with a non-uniform data distribution across different modalities often leads to degraded performance on underrepresented modalities. To address these, we propose a universal Khmer text recognition (UKTR) framework capable of handling diverse text modalities. Central to our method is a novel modality-aware adaptive feature selection (MAFS) technique designed to adapt visual features according to a particular input image modality and enhance recognition robustness across modalities. Extensive experiments demonstrate that our model achieves state-of-the-art (SoTA) performance. Furthermore, we introduce the first comprehensive benchmark for universal Khmer text recognition, which we release to the community to facilitate future research. Our datasets and models can be accessible via this gated repository\footnote{in review}.
Towards Explainable Khmer Polarity Classification
Nov 12, 2025Khmer polarity classification is a fundamental natural language processing task that assigns a positive, negative, or neutral label to a given Khmer text input. Existing Khmer models typically predict the label without explaining the rationale behind the prediction. This paper proposes an explainable Khmer polarity classifier by fine-tuning an instruction-based reasoning Qwen-3 model. The notion of explainability in this paper is limited to self-explanations, which the model uses to rationalize its predictions. Experimental results show that the fine-tuned model not only predicts labels accurately but also provides reasoning by identifying polarity-related keywords or phrases to support its predictions. In addition, we contribute a new Khmer polarity dataset consisting of short- to medium-length casual, romanized, and mixed-code Khmer expressions. This dataset was constructed using both heuristic rules and human curation and is publicly available through a gated Hugging Face repository (rinabuoy/khmerpolarity_nonreasoning). The fine-tuned Qwen-3 models are also made available in the same Hugging Face account.
Khmer Spellchecking: A Holistic Approach
Nov 12, 2025Compared to English and other high-resource languages, spellchecking for Khmer remains an unresolved problem due to several challenges. First, there are misalignments between words in the lexicon and the word segmentation model. Second, a Khmer word can be written in different forms. Third, Khmer compound words are often loosely and easily formed, and these compound words are not always found in the lexicon. Fourth, some proper nouns may be flagged as misspellings due to the absence of a Khmer named-entity recognition (NER) model. Unfortunately, existing solutions do not adequately address these challenges. This paper proposes a holistic approach to the Khmer spellchecking problem by integrating Khmer subword segmentation, Khmer NER, Khmer grapheme-to-phoneme (G2P) conversion, and a Khmer language model to tackle these challenges, identify potential correction candidates, and rank the most suitable candidate. Experimental results show that the proposed approach achieves a state-of-the-art Khmer spellchecking accuracy of up to 94.4%, compared to existing solutions. The benchmark datasets for Khmer spellchecking and NER tasks in this study will be made publicly available.
Khmer Word Search: Challenges, Solutions, and Semantic-Aware Search
Dec 16, 2021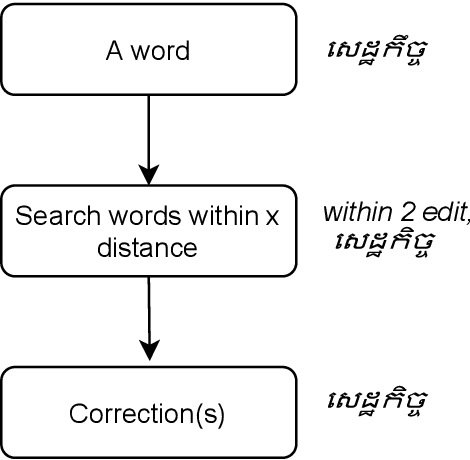

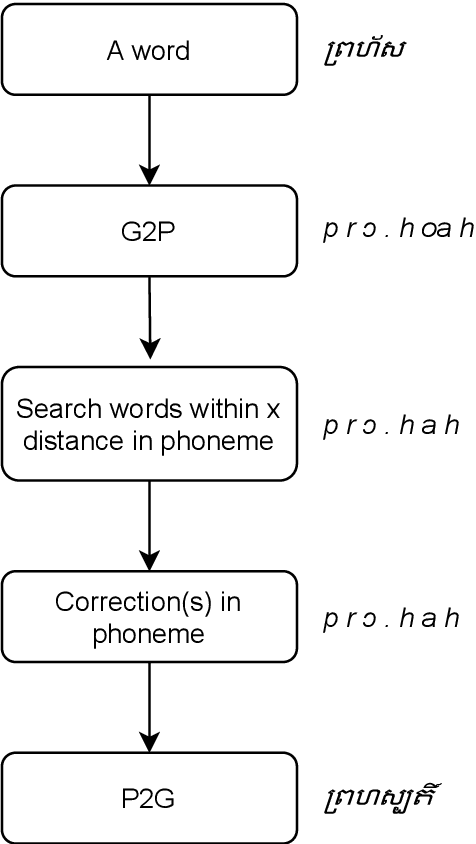

Search is one of the key functionalities in digital platforms and applications such as an electronic dictionary, a search engine, and an e-commerce platform. While the search function in some languages is trivial, Khmer word search is challenging given its complex writing system. Multiple orders of characters and different spelling realizations of words impose a constraint on Khmer word search functionality. Additionally, spelling mistakes are common since robust spellcheckers are not commonly available across the input device platforms. These challenges hinder the use of Khmer language in search-embedded applications. Moreover, due to the absence of WordNet-like lexical databases for Khmer language, it is impossible to establish semantic relation between words, enabling semantic search. In this paper, we propose a set of robust solutions to the above challenges associated with Khmer word search. The proposed solutions include character order normalization, grapheme and phoneme-based spellcheckers, and Khmer word semantic model. The semantic model is based on the word embedding model that is trained on a 30-million-word corpus and is used to capture the semantic similarities between words.
Khmer Text Classification Using Word Embedding and Neural Networks
Dec 13, 2021
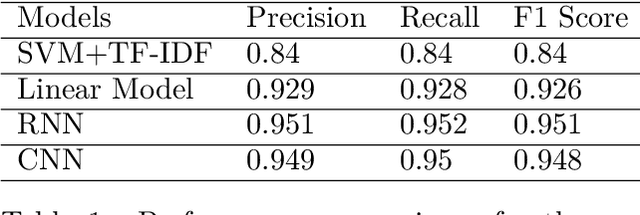
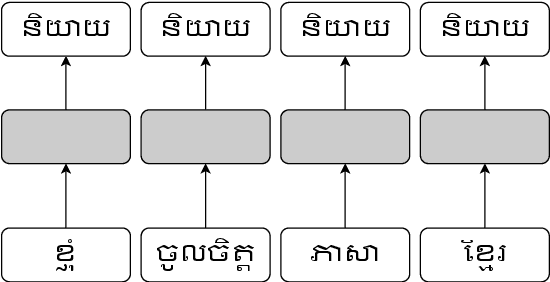
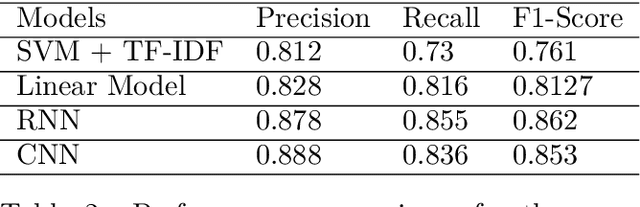
Text classification is one of the fundamental tasks in natural language processing to label an open-ended text and is useful for various applications such as sentiment analysis. In this paper, we discuss various classification approaches for Khmer text, ranging from a classical TF-IDF algorithm with support vector machine classifier to modern word embedding-based neural network classifiers including linear layer model, recurrent neural network and convolutional neural network. A Khmer word embedding model is trained on a 30-million-Khmer-word corpus to construct word vector representations that are used to train three different neural network classifiers. We evaluate the performance of different approaches on a news article dataset for both multi-class and multi-label text classification tasks. The result suggests that neural network classifiers using a word embedding model consistently outperform the traditional classifier using TF-IDF. The recurrent neural network classifier provides a slightly better result compared to the convolutional network and the linear layer network.
An End-to-End Khmer Optical Character Recognition using Sequence-to-Sequence with Attention
Jun 21, 2021
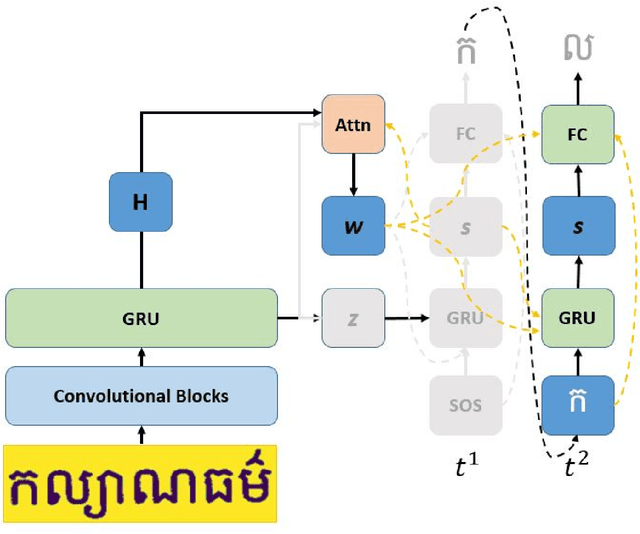
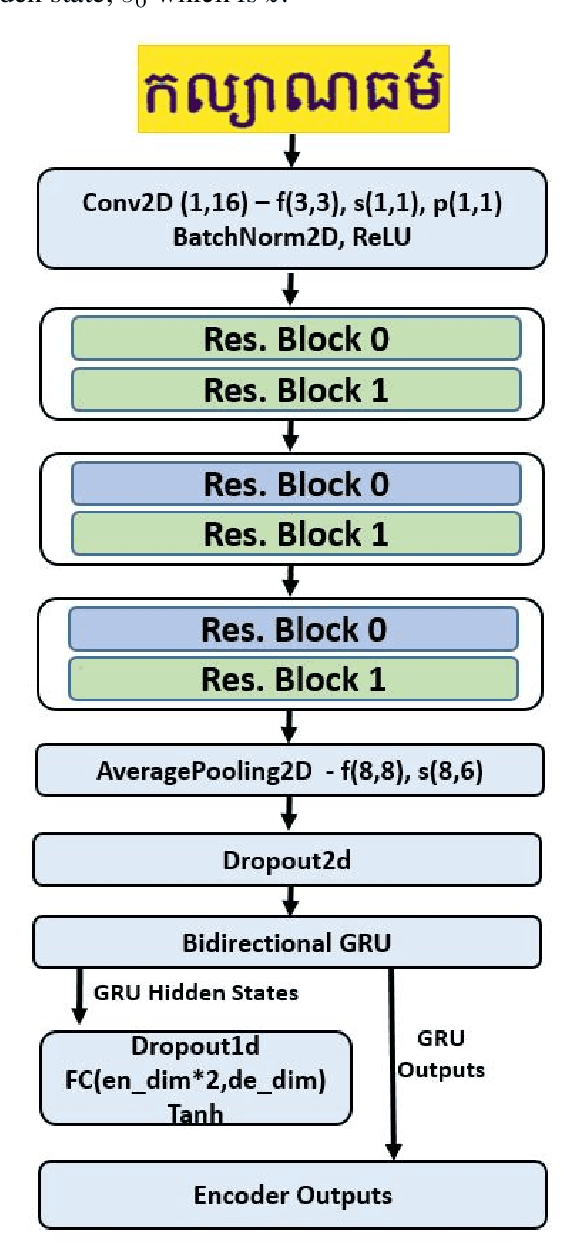
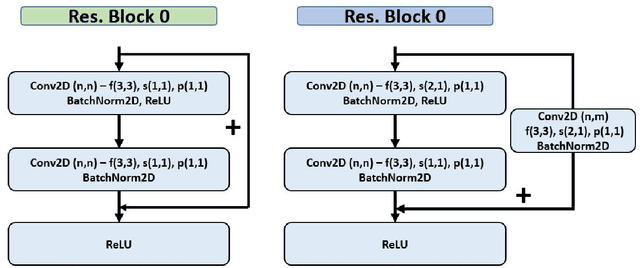
This paper presents an end-to-end deep convolutional recurrent neural network solution for Khmer optical character recognition (OCR) task. The proposed solution uses a sequence-to-sequence (Seq2Seq) architecture with attention mechanism. The encoder extracts visual features from an input text-line image via layers of residual convolutional blocks and a layer of gated recurrent units (GRU). The features are encoded in a single context vector and a sequence of hidden states which are fed to the decoder for decoding one character at a time until a special end-of-sentence (EOS) token is reached. The attention mechanism allows the decoder network to adaptively select parts of the input image while predicting a target character. The Seq2Seq Khmer OCR network was trained on a large collection of computer-generated text-line images for seven common Khmer fonts. The proposed model's performance outperformed the state-of-art Tesseract OCR engine for Khmer language on the 3000-images test set by achieving a character error rate (CER) of 1% vs 3%.
Joint Khmer Word Segmentation and Part-of-Speech Tagging Using Deep Learning
Mar 31, 2021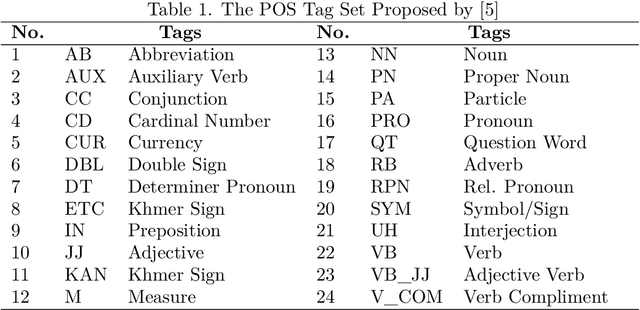
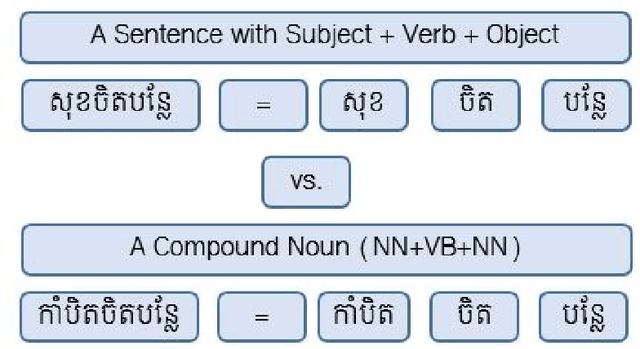
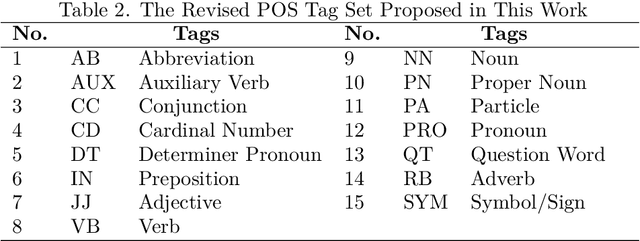
Khmer text is written from left to right with optional space. Space is not served as a word boundary but instead, it is used for readability or other functional purposes. Word segmentation is a prior step for downstream tasks such as part-of-speech (POS) tagging and thus, the robustness of POS tagging highly depends on word segmentation. The conventional Khmer POS tagging is a two-stage process that begins with word segmentation and then actual tagging of each word, afterward. In this work, a joint word segmentation and POS tagging approach using a single deep learning model is proposed so that word segmentation and POS tagging can be performed spontaneously. The proposed model was trained and tested using the publicly available Khmer POS dataset. The validation suggested that the performance of the joint model is on par with the conventional two-stage POS tagging.