 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCDMT-EHR: A Continuous-Time Diffusion Framework for Generating Mixed-Type Time-Series Electronic Health Records
Mar 24, 2026Electronic health records (EHRs) are invaluable for clinical research, yet privacy concerns severely restrict data sharing. Synthetic data generation offers a promising solution, but EHRs present unique challenges: they contain both numerical and categorical features that evolve over time. While diffusion models have demonstrated strong performance in EHR synthesis, existing approaches predominantly rely on discrete-time formulations, which suffer from finite-step approximation errors and coupled training-sampling step counts. We propose a continuous-time diffusion framework for generating mixed-type time-series EHRs with three contributions: (1) continuous-time diffusion with a bidirectional gated recurrent unit backbone for capturing temporal dependencies, (2) unified Gaussian diffusion via learnable continuous embeddings for categorical variables, enabling joint cross-feature modeling, and (3) a factorized learnable noise schedule that adapts to per-feature-per-timestep learning difficulties. Experiments on two large-scale intensive care unit datasets demonstrate that our method outperforms existing approaches in downstream task performance, distribution fidelity, and discriminability, while requiring only 50 sampling steps compared to 1,000 for baseline methods. Classifier-free guidance further enables effective conditional generation for class-imbalanced clinical scenarios.
Towards Khmer Scene Document Layout Detection
Feb 28, 2026While document layout analysis for Latin scripts has advanced significantly, driven by the advent of large multimodal models (LMMs), progress for the Khmer language remains constrained because of the scarcity of annotated training data. This gap is particularly acute for scene documents, where perspective distortions and complex backgrounds challenge traditional methods. Given the structural complexities of Khmer script, such as diacritics and multi-layer character stacking, existing Latin-based layout analysis models fail to accurately delineate semantic layout units, particularly for dense text regions (e.g., list items). In this paper, we present the first comprehensive study on Khmer scene document layout detection. We contribute a novel framework comprising three key elements: (1) a robust training and benchmarking dataset specifically for Khmer scene layouts; (2) an open-source document augmentation tool capable of synthesizing realistic scene documents to scale training data; and (3) layout detection baselines utilizing YOLO-based architectures with oriented bounding boxes (OBB) to handle geometric distortions. To foster further research in the Khmer document analysis and recognition (DAR) community, we release our models, code, and datasets in this gated repository (in review).
Towards Universal Khmer Text Recognition
Feb 28, 2026Khmer is a low-resource language characterized by a complex script, presenting significant challenges for optical character recognition (OCR). While document printed text recognition has advanced because of available datasets, performance on other modalities, such as handwritten and scene text, remains limited by data scarcity. Training modality-specific models for each modality does not allow cross-modality transfer learning, from which modalities with limited data could otherwise benefit. Moreover, deploying many modality-specific models results in significant memory overhead and requires error-prone routing each input image to the appropriate model. On the other hand, simply training on a combined dataset with a non-uniform data distribution across different modalities often leads to degraded performance on underrepresented modalities. To address these, we propose a universal Khmer text recognition (UKTR) framework capable of handling diverse text modalities. Central to our method is a novel modality-aware adaptive feature selection (MAFS) technique designed to adapt visual features according to a particular input image modality and enhance recognition robustness across modalities. Extensive experiments demonstrate that our model achieves state-of-the-art (SoTA) performance. Furthermore, we introduce the first comprehensive benchmark for universal Khmer text recognition, which we release to the community to facilitate future research. Our datasets and models can be accessible via this gated repository\footnote{in review}.
CBEN -- A Multimodal Machine Learning Dataset for Cloud Robust Remote Sensing Image Understanding
Feb 13, 2026Clouds are a common phenomenon that distorts optical satellite imagery, which poses a challenge for remote sensing. However, in the literature cloudless analysis is often performed where cloudy images are excluded from machine learning datasets and methods. Such an approach cannot be applied to time sensitive applications, e.g., during natural disasters. A possible solution is to apply cloud removal as a preprocessing step to ensure that cloudfree solutions are not failing under such conditions. But cloud removal methods are still actively researched and suffer from drawbacks, such as generated visual artifacts. Therefore, it is desirable to develop cloud robust methods that are less affected by cloudy weather. Cloud robust methods can be achieved by combining optical data with radar, a modality unaffected by clouds. While many datasets for machine learning combine optical and radar data, most researchers exclude cloudy images. We identify this exclusion from machine learning training and evaluation as a limitation that reduces applicability to cloudy scenarios. To investigate this, we assembled a dataset, named CloudyBigEarthNet (CBEN), of paired optical and radar images with cloud occlusion for training and evaluation. Using average precision (AP) as the evaluation metric, we show that state-of-the-art methods trained on combined clear-sky optical and radar imagery suffer performance drops of 23-33 percentage points when evaluated on cloudy images. We then adapt these methods to cloudy optical data during training, achieving relative improvement of 17.2-28.7 percentage points on cloudy test cases compared with the original approaches. Code and dataset are publicly available at: https://github.com/mstricker13/CBEN
Word-level Sign Language Recognition with Multi-stream Neural Networks Focusing on Local Regions
Jun 30, 2021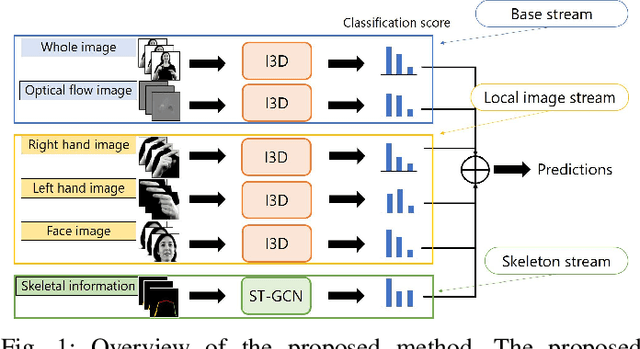
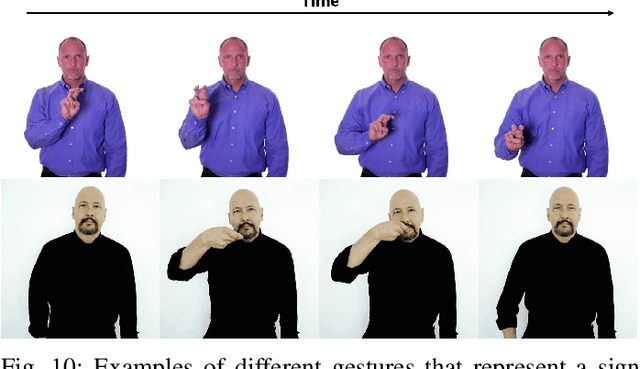
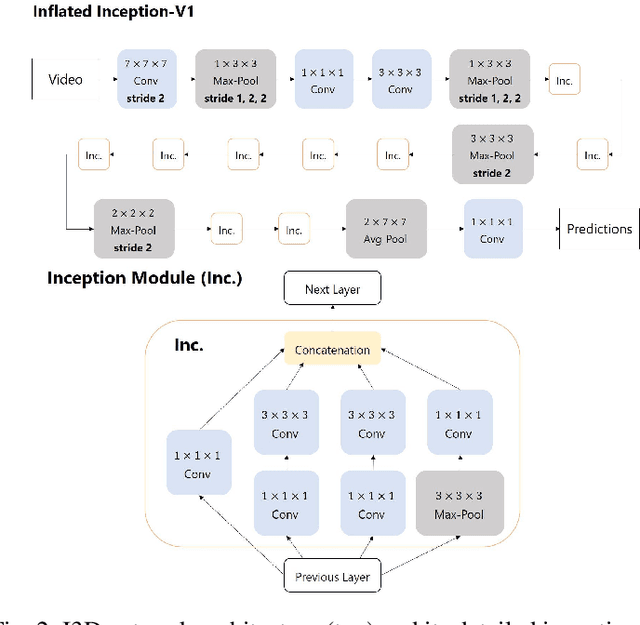
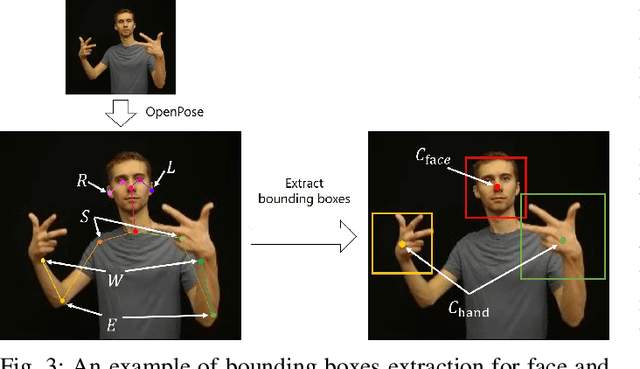
In recent years, Word-level Sign Language Recognition (WSLR) research has gained popularity in the computer vision community, and thus various approaches have been proposed. Among these approaches, the method using I3D network achieves the highest recognition accuracy on large public datasets for WSLR. However, the method with I3D only utilizes appearance information of the upper body of the signers to recognize sign language words. On the other hand, in WSLR, the information of local regions, such as the hand shape and facial expression, and the positional relationship among the body and both hands are important. Thus in this work, we utilized local region images of both hands and face, along with skeletal information to capture local information and the positions of both hands relative to the body, respectively. In other words, we propose a novel multi-stream WSLR framework, in which a stream with local region images and a stream with skeletal information are introduced by extending I3D network to improve the recognition accuracy of WSLR. From the experimental results on WLASL dataset, it is evident that the proposed method has achieved about 15% improvement in the Top-1 accuracy than the existing conventional methods.
Distortion-Adaptive Grape Bunch Counting for Omnidirectional Images
Aug 28, 2020

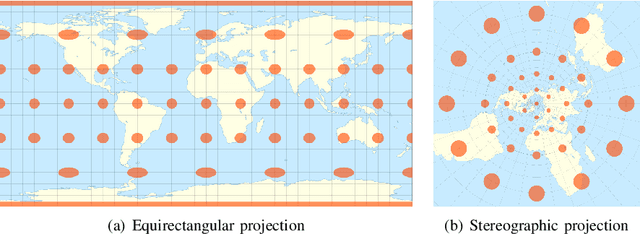
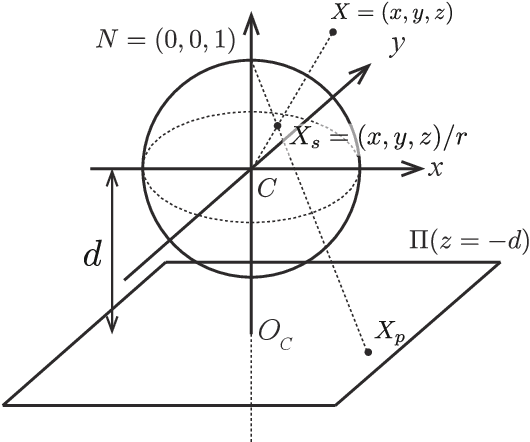
This paper proposes the first object counting method for omnidirectional images. Because conventional object counting methods cannot handle the distortion of omnidirectional images, we propose to process them using stereographic projection, which enables conventional methods to obtain a good approximation of the density function. However, the images obtained by stereographic projection are still distorted. Hence, to manage this distortion, we propose two methods. One is a new data augmentation method designed for the stereographic projection of omnidirectional images. The other is a distortion-adaptive Gaussian kernel that generates a density map ground truth while taking into account the distortion of stereographic projection. Using the counting of grape bunches as a case study, we constructed an original grape-bunch image dataset consisting of omnidirectional images and conducted experiments to evaluate the proposed method. The results show that the proposed method performs better than a direct application of the conventional method, improving mean absolute error by 14.7% and mean squared error by 10.5%.
Advances of Scene Text Datasets
Dec 13, 2018



This article introduces publicly available datasets in scene text detection and recognition. The information is as of 2017.
ShakeDrop regularization
Feb 07, 2018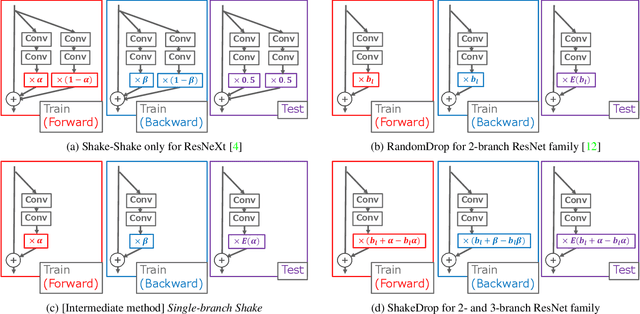
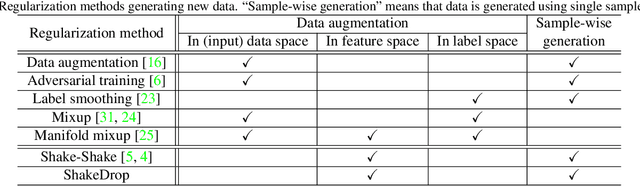
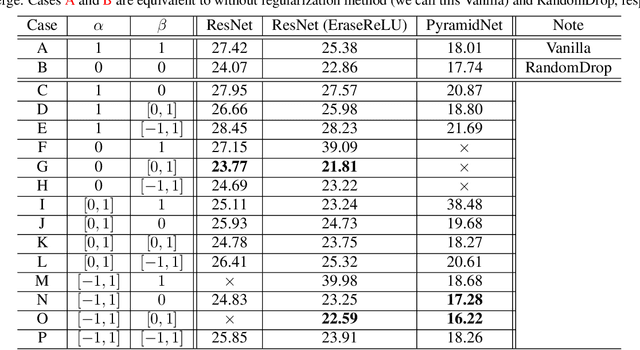
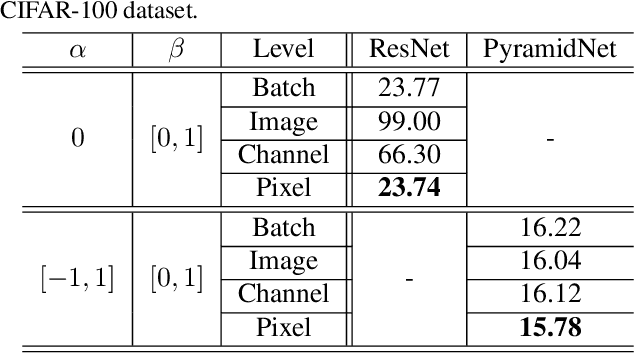
This paper proposes a powerful regularization method named ShakeDrop regularization. ShakeDrop is inspired by Shake-Shake regularization that decreases error rates by disturbing learning. While Shake-Shake can be applied to only ResNeXt which has multiple branches, ShakeDrop can be applied to not only ResNeXt but also ResNet, Wide ResNet and PyramidNet in a memory efficient way. Important and interesting feature of ShakeDrop is that it strongly disturbs learning by multiplying even a negative factor to the output of a convolutional layer in the forward training pass. The effectiveness of ShakeDrop is confirmed by experiments on CIFAR-10/100 and Tiny ImageNet datasets.
Automatic Generation of Typographic Font from a Small Font Subset
Jan 20, 2017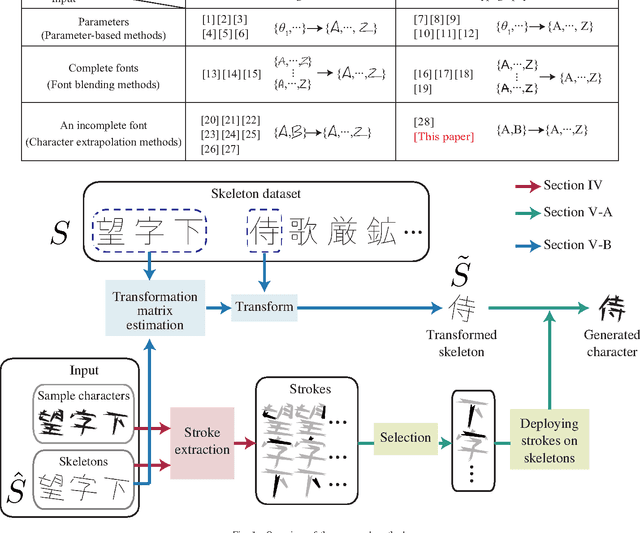
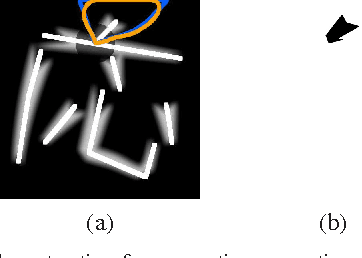
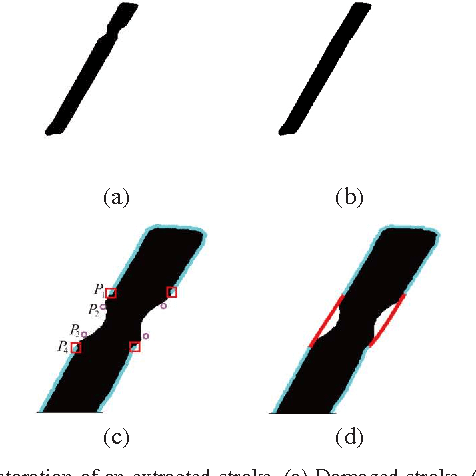
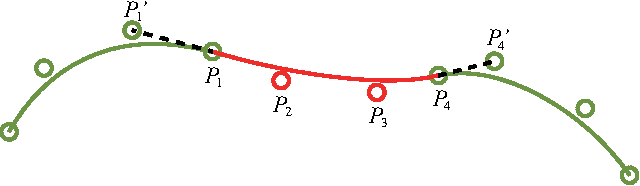
This paper addresses the automatic generation of a typographic font from a subset of characters. Specifically, we use a subset of a typographic font to extrapolate additional characters. Consequently, we obtain a complete font containing a number of characters sufficient for daily use. The automated generation of Japanese fonts is in high demand because a Japanese font requires over 1,000 characters. Unfortunately, professional typographers create most fonts, resulting in significant financial and time investments for font generation. The proposed method can be a great aid for font creation because designers do not need to create the majority of the characters for a new font. The proposed method uses strokes from given samples for font generation. The strokes, from which we construct characters, are extracted by exploiting a character skeleton dataset. This study makes three main contributions: a novel method of extracting strokes from characters, which is applicable to both standard fonts and their variations; a fully automated approach for constructing characters; and a selection method for sample characters. We demonstrate our proposed method by generating 2,965 characters in 47 fonts. Objective and subjective evaluations verify that the generated characters are similar to handmade characters.
Deep Pyramidal Residual Networks with Separated Stochastic Depth
Dec 05, 2016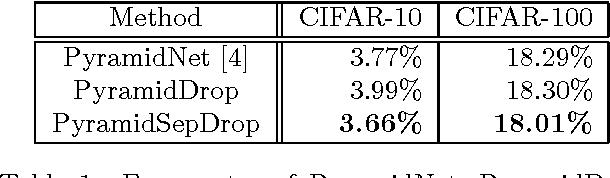
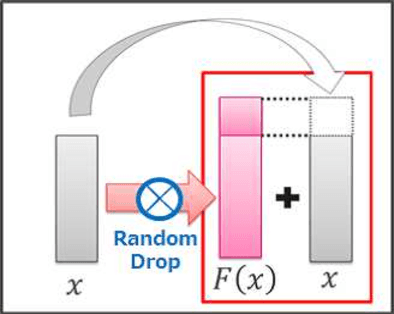
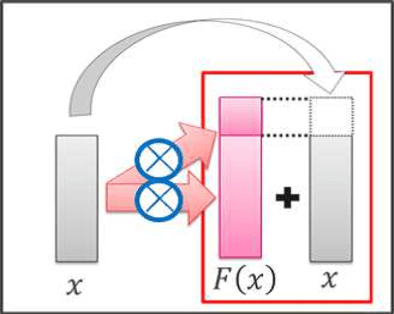
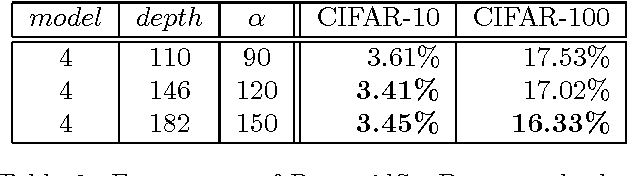
On general object recognition, Deep Convolutional Neural Networks (DCNNs) achieve high accuracy. In particular, ResNet and its improvements have broken the lowest error rate records. In this paper, we propose a method to successfully combine two ResNet improvements, ResDrop and PyramidNet. We confirmed that the proposed network outperformed the conventional methods; on CIFAR-100, the proposed network achieved an error rate of 16.18% in contrast to PiramidNet achieving that of 18.29% and ResNeXt 17.31%.